How can we see what a vision encoder sees?

Think of your favorite pre-trained vision encoder. I’m going to assume you’ve chosen some variant of a CNN (Convolutional Neural Network) or a ViT (Visual Transformer). The encoder is a function that maps an image into a d-dimensional vector space. In the process, the image is transformed into a sequence of feature maps:

A feature map (w × h × k) can be thought of as a collected 2D array of k-dimensional patch embeddings, or, equivalently, a coarse image (w × h) with k channels f₁, … fₖ. Both CNNs and ViTs, in their respective ways, are in the business of transforming an input image into a sequence of feature maps.
How can we see what a vision encoder sees as an image make its way through its layers? Zero-shot localization methods are designed to generate human-interpretable visualizations from an encoder’s feature maps. These visualizations, which can look like heatmaps or coarse segmentation masks, discriminate between semantically related regions in the input image. The term “zero-shot” refers to the fact that the model has not explicitly been trained on mask annotations for the semantic categories of interest. A vision encoder like CLIP, for instance, has only been trained on image-level text captions.
In this article, we begin with an overview of some early techniques for generating interpretable heatmaps from supervised CNN classifiers, with no additional training required. We then explore the challenges around achieving zero-shot localization with CLIP-style encoders. Finally, we touch on the key ideas behind GEM (Grounding Everything Module) [1], a recently proposed approach to training-free, open-vocabulary localization for the CLIP ViT.
1. Localization with supervised CNN classifiers
Class Activation Maps (2016)
Let’s build some intuition around the concept of localization by considering a simple vision encoder trained for image classification in a supervised way. Assume the CNN uses:
- Global average pooling (GAP) to transform the final feature map channels f₁(x, y), …, fₖ(x, y) into a k-dimensional vector. In other words, each fᵢ is averaged along the width and height dimensions.
- A single linear layer W to map this k-dimensional vector into a vector of class logits.
The logit for a given class c can then be written as:
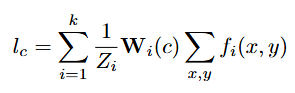
where Wᵢ(c) denotes the (scalar) weight of feature channel i on logit c, and Zᵢ is a normalizing constant for the average pooling.
The key observation behind Class Activation Maps [2] is that the above summation can be re-written as:

In other words, the logit can be expressed as a weighted average of the final feature channels which is then averaged across the width and height dimensions.
It turns out that the weighted average of the fᵢ ’s alone gives an interpretable heatmap for class c, where larger values match regions in the image that are more semantically related to the class. This coarse heatmap, which can be up-sampled to match the dimensions of the input image, is called a Class Activation Map (CAM):

Intuitively, each fᵢ is already a heatmap for some latent concept (or “feature”) in the image — though these do not necessarily discriminate between human-interpretable classes in any obvious way. The weight Wᵢ(c) captures the importance of fᵢ in predicting class c. The weighted average thus highlights which image features are most relevant to class c. In this way, we can achieve discriminative localization of the class c without any additional training.
Grad-CAM (2017)
The challenge with class activation maps is that they are only meaningful under certain assumptions about the architecture of the CNN encoder. Grad-CAM [3], proposed in 2019, is an elegant generalization of class activation maps that can be applied to any CNN architecture, as long as the mapping of the final feature map channels f₁, …, fₖ to the logit vector is differentiable.
As in the CAM approach, Grad-CAM computes a weighted sum of feature channels fᵢ to generate an interpretable heatmap for a class c, but the weight for each fᵢ is computed as:
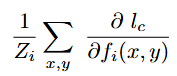
Grad-CAM generalizes the idea of weighing each fᵢ proportionally to its importance for predicting the logit for class c, as measured by the average-pooled gradients of the logit with respect to elements fᵢ(x, y). Indeed, it can be shown that computing the Grad-CAM weights for a CNN that obeys assumptions 1–2 from the previous section results in the same expression for CAM(c) we saw earlier, up to a normalizing constant (see [3] for a proof).
Grad-CAM also goes a step further by applying ReLU on top of the weighted average of the feature channels fᵢ. The idea is to only visualize features which would strengthen the confidence in the prediction of class c should their intensity be increased. Once again, the output can then be up-sampled to give a heatmap that matches the dimensions of the original input image.
2. Localization with CLIP
Do these early approaches generalize to CLIP-style encoders? There are two additional complexities to consider with CLIP:
- CLIP is trained on a large, open vocabulary using contrastive learning, so there is no fixed set of classes.
- The CLIP image encoder can be a ViT or a CNN.
That said, if we could somehow achieve zero-shot localization with CLIP, then we would unlock the ability to perform zero-shot, open-vocabulary localization: in other words, we could generate heatmaps for arbitrary semantic classes. This is the motivation for developing localization methods for CLIP-style encoders.
Let’s first attempt some seemingly reasonable approaches to this problem given our knowledge of localization using supervised CNNs.
For a given input image, the logit for a class c can be computed as the cosine similarity between the CLIP text embedding of the class name and the CLIP image embedding. The gradient of this logit with respect to the image encoder’s final feature map is tractable. Hence, one possible approach would be to directly apply Grad-CAM — and this could work regardless of whether the image encoder is a ViT or a CNN.

Another seemingly reasonable approach might be to consider alignment between image patch embeddings and class text embeddings. Recall that CLIP is trained to maximize alignment between an image-level embedding (specifically, the CLS token embedding) and a corresponding text embedding. Is it possible that this objective implicitly aligns a patch in embedding space more closely to text that is more relevant to it? If this were the case, we could expect to generate a discriminative heatmap for a given class by simply visualizing the similarity between its text embedding and each patch embedding:

Opposite Visualizations
Interestingly, not only do both these approaches fail, but the resulting heatmaps turn out to be the opposite of what we would expect. This phenomenon, first described in the paper “Exploring Visual Explanations for Contrastive Language-Image Pre-training” [4], has been observed consistently across different CLIP architectures and across different classes. To see examples of these “opposite visualization” with both patch-text similarity maps and Grad-CAM, take a look at page 19 in the pre-print “A Closer Look at the Explainability of Contrastive Language-Image Pre-training” [5]. As of today, there is no single, complete explanation for this phenomenon, though some partial hypotheses have been proposed.
Self-Attention Maps
One such hypothesis is detailed in the aforementioned paper [5]. This work restricts its scope to the ViT architecture and examines attention maps in the final self-attention block of the CLIP ViT. For a given input image and text class, these attention maps (w × h) are computed as follows:
- The patch embedding (a d-dimensional vector — the same as the output dimension of the image-level embedding) with highest cosine similarity to the class text embedding is selected as an anchor patch.
- The attention map is obtained by computing the query-key attention weights for the anchor patch query embedding Q and all key embeddings K, which can be reshaped into a heatmap of size w × h. The attention weights are computed as:
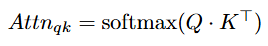
You might expect the anchor patch to be attending mostly to other patches in the image that are semantically related to the class of interest. Instead, these query-key attention maps reveal that anchor patches consistently attend to unrelated patches just as much. As a result, query-key attention maps are blotchy and difficult to interpret (see the paper [5] for some examples). This, the authors suggest, could explain the noisy patch-text similarity maps observed in the CLIP ViT.
On the other hand, the authors find that value-value attention maps are more promising. Empirically, they show that value-value attention weights are larger exclusively for patches near the anchor that are semantically related to it. Value-value attention maps are not complete discriminative heatmaps, but they are a more promising starting point.
3. Grounding Everything Module (2024)
Hopefully, you can now see why training-free localization is not as straightforward for CLIP as it was for supervised CNNs — and it is not well-understood why. That said, a recent localization method for the CLIP ViT called the Grounding Everything Module (GEM) [1], proposed in 2024, achieves remarkable success. GEM is essentially a training-free method to correct the noisy query-key attention maps we saw in the previous section. In doing so, the GEM-modified CLIP encoder can be used for zero-shot, open-vocabulary localization. Let’s explore how it works.
Self-Self Attention
The main idea behind GEM is called self-self attention, which is a generalization of the concept of value-value attention.
Given queries Q, keys K and values V, the output of a self-self attention block is computed by applying query-query, key-key, and value-value attention iteratively for t = 0, …, n:
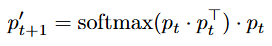

where p₀ ∈ {Q, K, V} and n, the number of iterations, is a hyperparameter. This iterative process can be thought of as clustering the initial tokens p₀ based on dot-product similarity. By the end of this process, the resulting tokens pₙ is a set of cluster “centers” for the initial tokens p₀.
The resulting self-self attention weights are then ensembled to produce the output of the self-self attention block:

where:
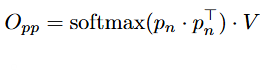
This is in contrast to a traditional query-key attention block, whose output is computed simply as:

Grounding Everything Module
Now consider our method for generating value-value attention maps in the previous section, where we first chose an anchor patch based on similarity to a class text embedding, then computed value-value attention map. GEM can be thought of as the reverse of this process, where:
- The first step is to apply qkv-ensembled self self-attention instead of regular attention for the last m attention blocks in the ViT (m is another hyperparameter). Intuitively, this is a way to compute ensembled cluster assignments for value embeddings V, thereby correcting the original query-key attention maps.
- The second step is to generate a heatmap by computing the cosine similarity between patch embeddings output from the modified ViT and the class text embedding. This effectively gives a class logit for each cluster.
This set of logits can then be reshaped to produce a discriminative heatmap for the chosen class, which can take the form of any arbitrary text! Below are some examples of GEM heatmaps for various class prompts (red indicates higher similarity to the class prompt):

Discriminative localization can transform an image-level encoder into a model that can be used for semantic segmentation, without the need for notoriously expensive mask annotations. Moreover, training-free localization is a powerful approach to making vision encoders more explainable, allowing us to see what they see.
For supervised vision models, zero-shot localization began with class activation maps, a technique for a specific kind of CNN architecture. Later, a generalization of this approach, applicable to any supervised CNN architecture, was proposed. When it comes to CLIP-style encoders, however, training-free localization is less straightforward: the phenomenon of opposite visualizations remains largely unexplained and exists across different CLIP encoder architectures. As of today, some localization techniques for the CLIP ViT such as GEM have proven successful. Is there a more generalized approach waiting to be discovered?
References
- W. Bousselham, F. Petersen, V. Ferrari, H. Kuehne, Grounding Everything: Emerging Localization Properties in Vision-Language Transformers (2024), 2024 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
- B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, A. Torralba, Learning Deep Features for Discriminative Localization (2016), 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
- R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, D. Batra, Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization (2017), 2017 IEEE International Conference on Computer Vision (ICCV)
- Y. Li, H. Wang, Y. Duan, H. Xu, X. Li, Exploring Visual Explanations for Contrastive Language-Image Pre-training (2022)
- Y. Li, H. Wang, Y. Duan, J. Zhang, X. Li, A Closer Look at the Explainability of Contrastive Language-Image Pre-training (2024)
Zero-Shot Localization with CLIP-Style Encoders was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Zero-Shot Localization with CLIP-Style Encoders
Go Here to Read this Fast! Zero-Shot Localization with CLIP-Style Encoders