

Testing major LLMs on how well they conduct numeric evaluations
In addition to generating text for a growing number of industry applications, LLMs are now widely being used as evaluation tools. Models quantify the relevance of retrieved documents in retrieval systems, gauge the sentiment of comments and posts, and more — evaluating both human and AI-generated text. These evaluations are often either numeric or categorical.

Numeric evaluations involve an LLM returning a number based on a set of evaluation criteria. For example, a model might be tasked with how relevant a document is to a user query on a scale of one to ten.
A categorical evaluation is different in that it allows an LLM to choose from a set of predefined, often text-based options to choose from in its evaluation. For example, a prompt might ask if a passage is “happy,” “sad,” or “neutral” rather than trying to quantify the passage’s happiness level.
This piece features results from testing of several major LLMs — OpenAI’s GPT-4, Anthropic’s Claude, and Mistral AI’s Mixtral-8x7b — on how well they conduct numeric evaluations. All code run to complete these tests can be found in this GitHub repository.
Takeaways
- Numeric score evaluations across LLMs are not consistent, and small differences in prompt templates can lead to massive discrepancies in results.
- Even holding all independent variables (model, prompt template, context) constant can lead to varying results across multiple rounds of testing. LLMs are not deterministic, and some are not at all consistent in their numeric judgements.
- There are good reasons to doubt that GPT-4, Claude, or Mixtral can handle continuous ranges well enough to use them for numeric score evals for real-world use cases yet.
Research
Spelling Corruption Experiment
The first experiment was designed to assess an LLM’s ability to assign scores between 0 and 10 to documents based on the percentage of words containing spelling errors.
We took a passage of correctly spelled words, edited the text to include misspelled words at varying frequencies, and then fed this corrupted text to an LLM using this prompt template:
SIMPLE_TEMPLATE_SPELLING = """
You are a helpful AI bot that checks for grammatic, spelling and typing errors in a document context.
You are going to score the document based on the percent of grammatical and typing errors. The score should be between {templ_high} and {templ_low}.
A {templ_low} score will be no grammatical errors in any word, a score of {templ_20_perc} will be 20% of words have errors, a {templ_50_perc} score will be 50% errors, a score of {templ_70_perc} is 70%, and a {templ_high} will be all words in context have grammatical errors.
The following is the document context.
#CONTEXT
{context}
#ENDCONTEXT
#QUESTION
Please return a score between {templ_high} and {templ_low}, with a case of {templ_high} being all words have a grammatical error and {templ_low} being no words have grammatical or spelling errors.
You will return no other text or language besides the score. Only return the score.
Please
We then asked the model to return a numeric eval corresponding to the percentage of words in the passage that were misspelled (3 → 30% misspelled, 8 → 80%, etc.). Ideally, a score of 10 would indicate that every word in a document is misspelled, while a score of 0 would mean there are no spelling errors at all. The results of the experiment across three LLMs — GPT-4, Claude, and Mixtral — were less than stellar.

Observed results were far from the expected perfect linear range; the scoring system did not consistently reflect the proportion of spelling errors in the documents. In fact, GPT-4 (above) returned 10 (which represents a 100% error rate) for every document with percent of density of corruption at or above 10%. The reported scores were the median of multiple trials conducted at each specified level of error.
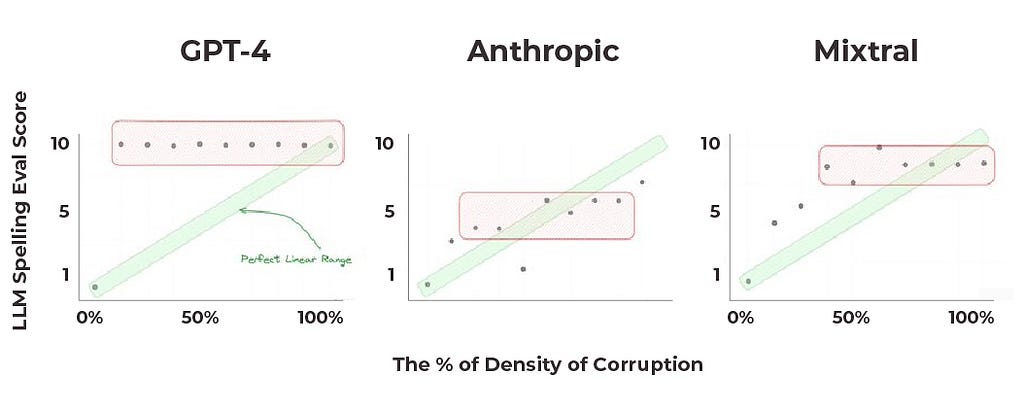
The results from Claude were slightly better, but still not perfect or at a level likely acceptable for deployment. Mixtral, the smallest of these three models, performed best.
So why does this matter? Given interest in using LLMs numeric evaluators in a variety of settings, there are good reasons to believe that use LLMs in this way may run into roadblocks with performance and customer satisfaction.
Emotional Qualifier Experiments
The second and third experiments conducted were designed to assess an LLM’s ability to assign scores between 0 and 10 to documents based on the amount of sentences within the text that contained words that indicated sadness or frustration.
In these tests we embedded phrases and words into text that imparted a sense of sadness/frustration within the passage. The model was asked to quantify how prevalent the emotion was in the text, with 1 corresponding to no sentences conveying the emotion and 10 corresponding to 100% of sentences conveying the emotion.
These experiments were conducted alongside the spelling test to determine if shifting the model’s focus from word count to sentence count would impact the results. While the spelling test scored based on the percentage of misspelled words, the sadness/frustration tests scored based on the percentage of emotional sentences.
The instruction at the beginning of the prompt template varied between tests while everything beginning with the context remained the same, indicated by the ellipses:
SIMPLE_TEMPLATE_FRUSTRATION = """
You are a helpful AI bot that detects frustrated conversations. You are going to score the document based on the percent of sentences where the writer expresses frustration.
The score should be between {templ_high} and {templ_low}.
A {templ_low} will indicate almost no frustrated sentences, a score of {templ_20_perc} will be 20% of sentences express frustration, a {templ_50_perc} will be 50% of sentences express frustration, a score of {templ_70_perc} is 70%, and a {templ_high} score will be all the sentences express frustration.
...
"""
SIMPLE_TEMPLATE_SADNESS = """
You are a helpful AI bot that detects sadness and sorrow in writing. You are going to score the document based on the percent of sentences where the writer expresses sadness or sorrow.
The score should be between {templ_high} and {templ_low}.
A {templ_low} will indicate almost no sentences that have sadness or sorrow, a score of {templ_20_perc} will be 20% of sentences express sadness or sorrow, a {templ_50_perc} will be 50% of sentences express sadness or sorrow, a score of {templ_70_perc} is 70%, and a {templ_high} score will be all the sentences express sadness or sorrow.
...
"""
Again, a score of 10 should indicate that every sentence in a document contains sadness or frustration qualifiers, while a score of 0 would mean there are none present. Scores in between correspond to varying degrees of the emotion frequency, with higher scores representing a greater proportion of emotional sentences.
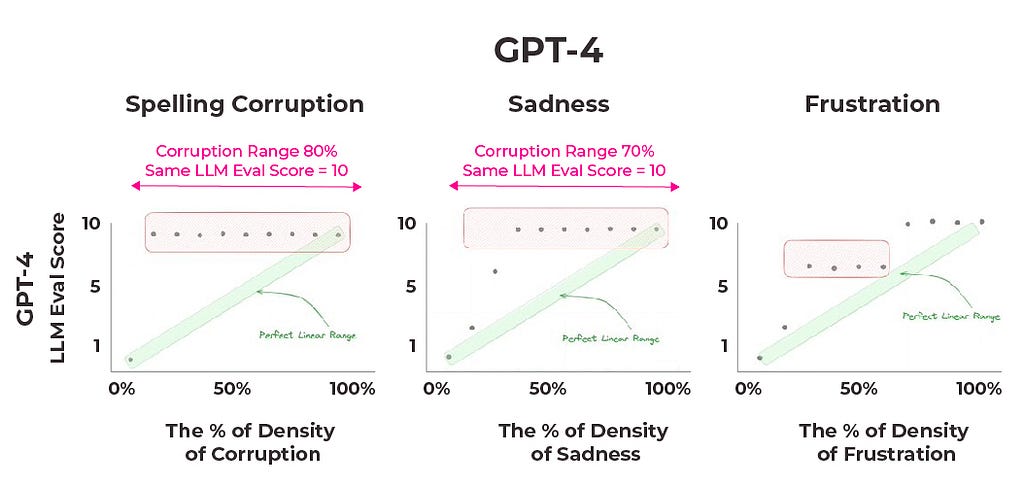
Similar to the spelling corruption experiment, results show a significant discrepancy from the expected outcomes. GPT-4 gives every document with sadness rates above 30% or frustration rates about 70% a score of 10. Remarkably, out of all of the tests run with GPT-4, the only times the median answer satisfies a perfect linear range is when there are no qualifiers or misspelled words present at all.
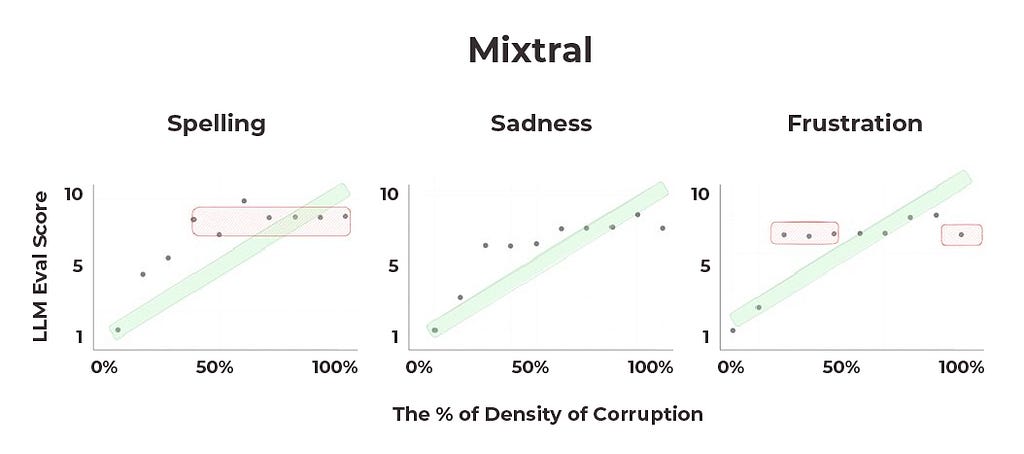
Mixtral performs relatively well across the emotional qualifier experiments. While there are good reasons to doubt that these models currently handle continuous ranges well enough to use them for numeric score evals, Mixtral is the closest to accomplishing that feat.
Based on these results, we do not recommend score evals in production code.
Variance in Results
It is worth noting that we ran these tests several times for each model and charted the distribution of their responses.
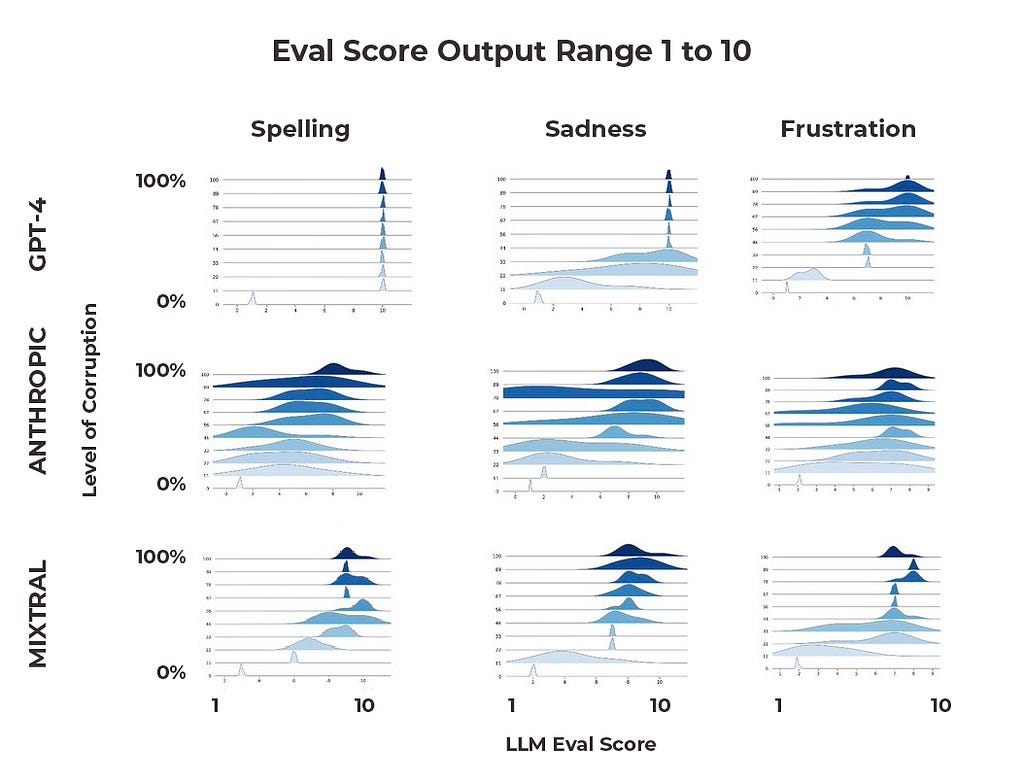
An ideal distribution would be tight around the low and high ends (high confidence if all or none of the words/sentences were counted) and perhaps a longer transition region in the middle (e.g. lower confidence differentiating between 4 and 5).
Two things stand out here. First, the tightness of distributions is quite different across models and tasks. Claude’s distributions range considerably over our trials; we have examples of the model consistently assigning 1–4 at 80% corruption, for example. On the other hand, GPT-4 has much tighter distributions — albeit at values that for the most part did not satisfy reasonable expectations.
Second, some models are better at handling transitions in continuous ranges than others. Mixtral’s distributions look like they are getting close to where an acceptable performance might be, but all three models seem to have a ways to go before they are ready for production.
Implications for LLM Evals
There is currently a lot of research currently being done on LLM evaluations. Microsoft’s GPT Estimation Metric Based Assessment (GEMBA), for example, examines the ability of different large language models to evaluate the quality of different translation segments. While some research papers use probabilities and numeric scores as part of evaluation output — with GEMBA and others even reporting promising results — the way we see customers applying score evals in the real world is often much different from current research.
With that in mind, we attempted to tailor our research to these more practical, real-word applications — and the results highlight why the use of scores directly for decisions can be problematic. Considering GPT-4’s responses in our score evals research, it seems as though the model wants to choose one of two options: 1 or 10, all or nothing.
Ultimately, categorical evaluation (either binary or multi-class) likely has a lot of promise and it will be interesting to watch this space.
Conclusion
Using LLMs to conduct numeric evals is finicky and unreliable. Switching between models and making small changes in prompt templates can lead to vastly different results, making it hard to endorse LLMs as consistently reliable arbiters of numeric evaluation criteria. Furthermore, large distributions of results across continued testing showcase that these models are often not consistent in their responses, even when independent variables remain unchanged. Readers building with LLM evals would be wise to avoid using numeric evaluations in the manner outlined in this piece.
Why You Should Not Use Numeric Evals For LLM As a Judge was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Why You Should Not Use Numeric Evals For LLM As a Judge
Go Here to Read this Fast! Why You Should Not Use Numeric Evals For LLM As a Judge