SQL INTERMEDIATE
Intermediate SQL for ETL dev to Data Engineer Transition

There is nothing called Self join in SQL. Hear me out.
Often Data Analysts ad Data Engineers need to find patterns in data that are not obvious. Howevre the insights can be generated and patterns identified by using common SQL practices, like Self Join.
many beginners often struggle to understand Self Join. They confuse Self Join in SQL as another command like the Inner or Left Join. But Self Join is not a key word in SQL. Neighter is it a command in SQL.
Self-join is just like a normal Join(Inner/Left/Right/Outer), between two tables. However, in a self-join, the two tables are the same but act as different tables via their aliases.
Self Join is often considered a bad practice in Data Engineering. They say it’s risky to use. However, there are scenarios when using a self-join is practical and the best way to tackle the issue.
Let’s see a few examples:
Hierarchical Data:
Self-joins are useful for working with hierarchical data. In an organisational chart, we can join a table to itself based on manager-employee relationships to find employee reports, department heads, etc.
Let’s generate some free data to test this.
create table employee
(
employee_id int,
employee_name varchar(10),
EmpSSN varchar(11),
manager_id int null,
city varchar(20)
);
--Correct data
insert into employee values(1, 'Jack', '555-55-5555','','Kolkata');
insert into employee values (2, 'Joe', '555-56-5555',1,'Kolkata');
insert into employee values (3, 'Fred', '555-57-5555',2,'Dehli');
insert into employee values (4, 'Mike', '555-58-5555',2,'Kolkata');
insert into employee values (5, 'Cathy', '555-59-5555',2,'Dehli');
insert into employee values (6, 'Lisa', '555-70-5555',3,'Bangalore');
Here the employee details of an organisation are stored along with their manager ID. We can use Self join to identify the manager of all distinct employees.
select emp.*,isnull(mgr.employee_name,'Boss') as managerName from employee emp
left join employee mgr on emp.manager_id = mgr.employee_id
Here the query returns the manager’s name corresponding to each employee by joining the same employee table with itself on manager_id = employee_id.
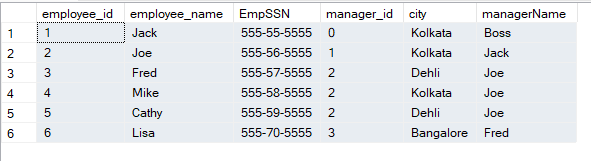
WARNING: Do not forget to use alias for the employee table, to differentiate between two parts of the self join. Also, the join column should be correctly used.
Similarly, we can even find the different levels of hierarchy by recursively joining the CTE as a self-join with itself.
WITH
EmployeeHierarchy AS (
SELECT
employee_id, employee_name, manager_id, 0
AS
level
FROM
employee
WHERE
manager_id = 0
UNION ALL
SELECT
emp.employee_id, emp.employee_name, emp.manager_id, eh.level + 1
FROM
employee emp
JOIN
EmployeeHierarchy eh
ON
emp.manager_id = eh.employee_id
)
SELECT
employee_id, employee_name, level
FROM
EmployeeHierarchy;
Products and Categories:
This can be related to hierarchical data only, however, this is a precise subset. Self Joins can be extremely handy to identify all combinations of products, categories and subcategories. In the manufacturing industry, this can provide components and sub-components, in e-commerce it can be used to get similar products or categories.
Let’s learn it through an example:
Create table and insert dummy data:
create table bom (item_id int, parent_id int null,description varchar(50), quantity int)
INSERT INTO bom (item_id, parent_id, description, quantity)
VALUES (1, NULL, 'Widget (Main Assembly)', 1),
(2, 1, 'Gear A', 2),
(3, 1, 'Spring B', 4),
(4, 2, 'Screw C (Small)', 10),
(5, 2, 'Screw C (Large)', 5),
(6, 3, 'Nut D', 1);
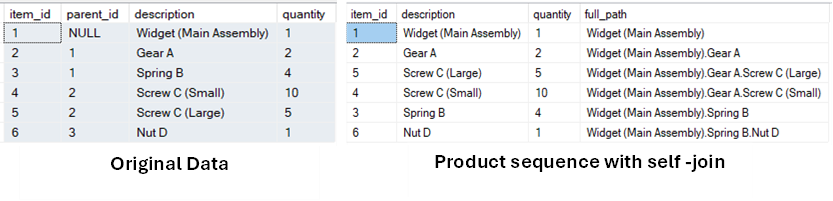
We created a table with columns of item_id, parent_id, description, and quantity. We have also inserted sample data from a manufacturing line, where ‘Widget (Main Assembly)’ is the parent product and Gear, Screw, nut etc. are sub-products.
We can use self-join to identify the parent-child relationship, and recursive self-join can identify the full product sequence.
Let’s review this with the query and the results:
WITH recursive_bom AS (
SELECT item_id, parent_id, description, quantity, cast(description as nvarchar(255)) AS full_path
FROM bom
WHERE parent_id IS NULL -- Starting point: Top-level items
UNION ALL
SELECT
b.item_id,
b.parent_id,
b.description,
b.quantity,
cast(CONCAT(rb.full_path, '.', b.description) as nvarchar(255)) AS full_path
FROM bom b
INNER JOIN recursive_bom rb ON b.parent_id = rb.item_id
)
SELECT item_id, description, quantity, full_path
FROM recursive_bom
ORDER BY full_path;
Sample Data and Output
User Segmentation:
In Business and Data Analytics, an important aspect is user segmentation. Users are often categorised based on their purchase behavior, their frequency of interation with the business etc. A self-join can be a greeat way to identify these patterns in the transaction data.
Let’s consider the below example:
We need to identify returning customers within a specified time period ( 7 days ) for an eccommerce business. Similar challenges can be found on the internet, example here.
Let’s create a test table and insert some sample records in the table.
Trick: You can ask ChatGpt to generate the test data as per need.
Create table and insert dummy data:
create table ecom_tran (
tranid int,
userid int,
created_date datetime,
itemname varchar(50)
)
INSERT INTO ecom_tran (tranid, userid, created_date, itemname, price_paid)
VALUES
(1, 201, '2024-02-23 11:45:00', 'Running Shoes'),
(2, 202, '2024-02-24 10:00:00', 'Yoga Mat'),
(3, 203, '2024-02-26 14:10:00', 'Water Bottle'),
(4, 204, '2024-02-27 09:30:00', 'Gym Bag'),
(5, 205, '2024-02-28 12:00:00', 'Protein Powder'),
(6, 201, '2024-02-29 15:15:00', 'Phone Case'),
(7, 206, '2024-03-01 10:45:00', 'Webcam'),
(8, 202, '2024-03-02 16:30:00', 'Pen Drive'),
(9, 207, '2024-03-04 12:00:00', 'Powerbank'),
(10, 203, '2024-03-05 09:00:00', 'Monitor'),
(11, 101, '2024-03-06 11:00:00', 'Mouse'),
(12, 102, '2024-03-07 14:45:00', 'Speaker'),
(13, 103, '2024-03-08 10:10:00', 'Tablet'),
(14, 101, '2024-03-09 13:30:00', 'Headphones'),
(15, 104, '2024-03-10 17:00:00', 'Book'),
(16, 102, '2024-03-11 08:20:00', 'Coffee Maker'),
(17, 105, '2024-03-12 11:15:00', 'Smartwatch'),
(18, 101, '2024-03-13 15:45:00', 'Shirt'),
(19, 103, '2024-03-14 12:30:00', 'Laptop')
Solution approach:
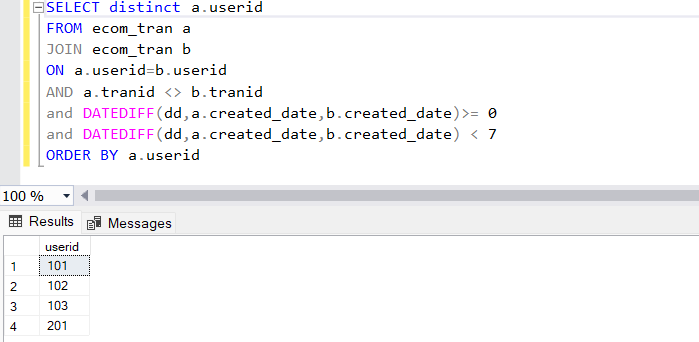
In the sample table created, we have the userid, transactionid and the created_date column which are relevant to the challenge. As we have been asked to identify the users who have made at least 2 purchases within a 7 day period, we can consider the below approach:
- Check how many diferent transactions the users have made.
- Combine each transactions along with itself to identify all possible pairs of transaction by the same user.
- Calculate the date difference between the two combinations.
- The date difference should be > 0 and < 7. This will ensure only records where transactions have been made within 7 days are returned.
- We can collect the distinct userids to identify the users that have returning transactions within 7 days.
This is a classic use case to consider Self-Join along with non-equi join.
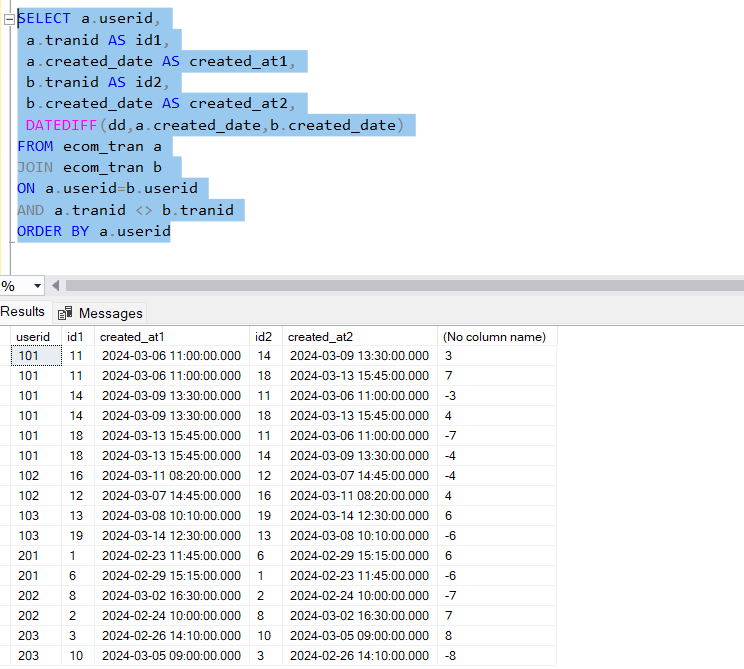
SELECT a.userid,
a.tranid AS id1,
a.created_date AS created_at1,
b.tranid AS id2,
b.created_date AS created_at2,
mod(DATEDIFF(dd,a.created_date,b.created_date))
FROM ecom_tran a
JOIN ecom_tran b
ON a.userid=b.userid
AND a.tranid <> b.tranid
ORDER BY a.userid
The above query generate all combinations of transactions made by same users. We have achieved this by joining the ecom_tran to itself, with the help of aliases, on column userid. This inner join ensures, only transactions of same user are returned.
Howver the non equi join is on a.tranid <> b.tranid , this ensures the same transactions are not repeated.
We also calculated the date difference between the two transactions.
Now if we just filter on the ones where the date difference between the created_dates is > 0 and < 7, that will give us all transcations that happened within 7 days by same user. We can take a distinct value of the userid column to just identify the users that made returning purchases within 7 days.
Conclusion:
I hope you got a general understaning and intuition about how the self join performs in SQL. Though self joins are not very intuitive to understand and use, theer are specific use cases where they are indespensible.
I have covered only few of the possible scenarios. Yet, this is sufficient to give you confiedence while facing any SQL interview questions. Even if the question might need intuitive understanding to solve the challenges, these concepts will help to identify what approach to use.
All Lessons in the SQL Intermediate series is covered below:
https://medium.com/tag/sqlintermediate
When Do You Self Join? A Handy Trick was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
When Do You Self Join? A Handy Trick
Go Here to Read this Fast! When Do You Self Join? A Handy Trick