You’ve heard of OpenAI and Nvidia, but do you know who else is involved in the AI wave and how they all fit together?
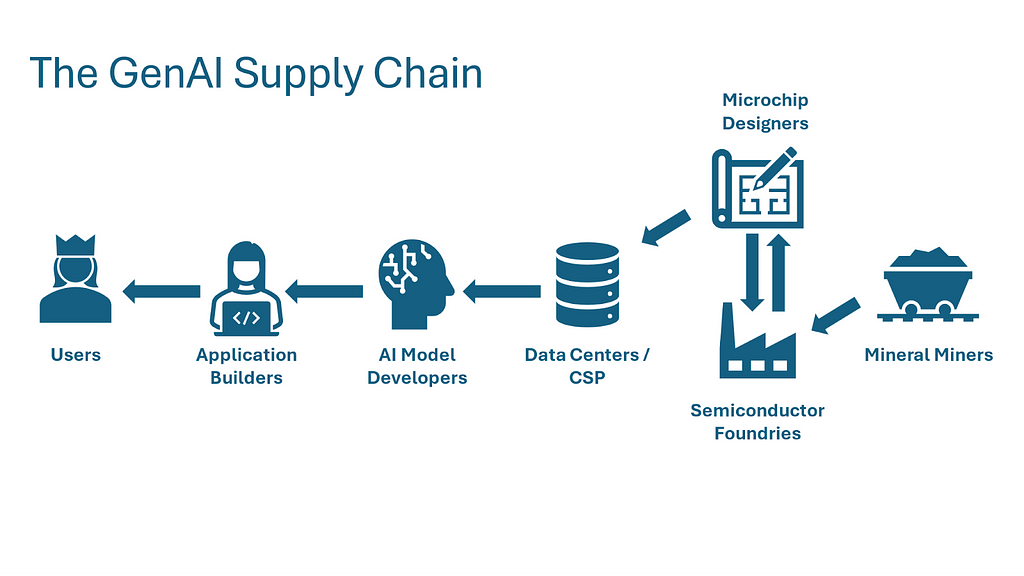
Several months ago, I visited the MoMA in NYC and saw the work Anatomy of an AI System by Kate Crawford and Vladan Joler. The work examines the Amazon Alexa supply chain from raw resource extraction to devise disposal. This made me to think about everything that goes into producing today’s generative AI (GenAI) powered applications. By digging into this question, I came to understand the many layers of physical and digital engineering that GenAI applications are built upon.
I’ve written this piece to introduce readers to the major components of the GenAI value chain, what role each plays, and who the major players are at each stage. Along the way, I hope to illustrate the range of businesses powering the growth of AI, how different technologies build upon each other, and where vulnerabilities and bottlenecks exist. Starting with the user-facing applications emerging from technology giants like Google and the latest batch of startups, we’ll work backward through the value chain down to the sand and rare earth metals that go into computer chips.
End Application Builders

Technology giants, corporate IT departments, and legions of new startups are in the early phases of experimenting with potential use cases for GenAI. These applications may be the start of a new paradigm in computer applications, marked by radical new systems of human-computer interaction and unprecedented capabilities to understand and leverage unstructured and previously untapped data sources (e.g., audio).
Many of the most impactful advances in computing have come from advances in human-computer interaction (HCI). From the development of the GUI to the mouse to the touch screen, these advances have greatly expanded the leverage users gain from computing tools. GenAI models will further remove friction from this interface by equipping computers with the power and flexibility of human language. Users will be able to issue instructions and tasks to computers just as they might a reliable human assistant. Some examples of products innovating in the HCI space are:
- Siri (AI Voice Assistant) — Enhances Apple’s mobile assistant with the capability to understand broader requests and questions
- Palantir’s AIP (Autonomous Agents) — Strips complexity from large powerful tools through a chat interface that directs users to the desired functionality and actions
- Lilac Labs (Customer Service Automation) — Automates drive-through customer ordering with voice AI
GenAI equips computer systems with agency and flexibility that was previously impossible when sets of preprogrammed procedures guided their functionality and their data inputs needed to fit well-defined rules established by the programmer. This flexibility allows applications to perform more complex and open ended knowledge tasks that were previously strictly in the human domain. Some examples of new applications leveraging this flexibility are:
- GitHub Copilot (Coding Assistant) — Amplifies programmer productivity by implementing code based on the user’s intent and existing code base
- LenAI (Knowledge Assistant) — Saves knowledge workers time by summarizing meetings, extracting critical insights from discussions, and drafting communications
- Perplexity (AI Search) — Answers user questions reliably with citations by synthesizing traditional internet searches with AI-generated summaries of internet sources
A diverse group of players is driving the development of these use cases. Hordes of startups are springing up, with 86 of Y Combinator’s W24 batch focused on AI technologies. Major tech companies like Google have also introduced GenAI products and features. For instance, Google is leveraging its Gemini LLM to summarize results in its core search products. Traditional enterprises are launching major initiatives to understand how GenAI can complement their strategy and operations. JP Morgan CEO Jamie Dimon said AI is “unbelievable for marketing, risk, fraud. It’ll help you do your job better.” As companies understand how AI can solve problems and drive value, use cases and demand for GenAI will multiply.
AI Model Builders
With the release of OpenAI’s ChatGPT (powered by the GPT-3.5 model) in late 2022, GenAI exploded into the public consciousness. Today, models like Claude (Anthropic), Gemini (Google), and Llama (Meta) have challenged GPT for supremacy. The model provider market and development landscape are still in their infancy, and many open questions remain, such as:
- Will smaller domain/task-specific models proliferate, or will large models handle all tasks?
- How far can model sophistication and capability advance under the current transformer architecture?
- How will capabilities advance as model training approaches the limit of all human-created text data?
- Which players will challenge the current supremacy of OpenAI?
While speculating about the capability limits of artificial intelligence is beyond the scope of this discussion, the market for GenAI models is likely large (many prominent investors certainly value it highly). What do model builders do to justify such high valuations and so much excitement?
The research teams at companies like OpenAI are responsible for making architectural choices, compiling and preprocessing training datasets, managing training infrastructure, and more. Research scientists in this field are rare and highly valued; with the average engineer at OpenAI earning over $900k. Not many companies can attract and retain people with this highly specialized skillset required to do this work.
Compiling the training datasets involves crawling, compiling, and processing all text (or audio or visual) data available on the internet and other sources (e.g., digitized libraries). After compiling these raw datasets, engineers layer in relevant metadata (e.g., tagging categories), tokenize data into chunks for model processing, format data into efficient training file formats, and impose quality control measures.
While the market for AI model-powered products and services may be worth trillions within a decade, many barriers to entry prevent all but the most well-resourced companies from building cutting-edge models. The highest barrier to entry is the millions to billions of capital investment required for model training. To train the latest models, companies must either construct their own data centers or make significant purchases from cloud service providers to leverage their data centers. While Moore’s law continues to rapidly lower the price of computing power, this is more than offset by the rapid scale up in model sizes and computation requirements. Training the latest cutting-edge models requires billions in data center investment (in March 2024, media reports described an investment of $100B by OpenAI and Microsoft on data centers to train next gen models). Few companies can afford to allocate billions toward training an AI model (only tech giants or exceedingly well-funded startups like Anthropic and Safe Superintelligence).
Finding the right talent is also incredibly difficult. Attracting this specialized talent requires more than a 7-figure compensation package; it requires connections with the right fields and academic communities, and a compelling value proposition and vision for the technology’s future. Existing players’ high access to capital and domination of the specialized talent market will make it difficult for new entrants to challenge their position.
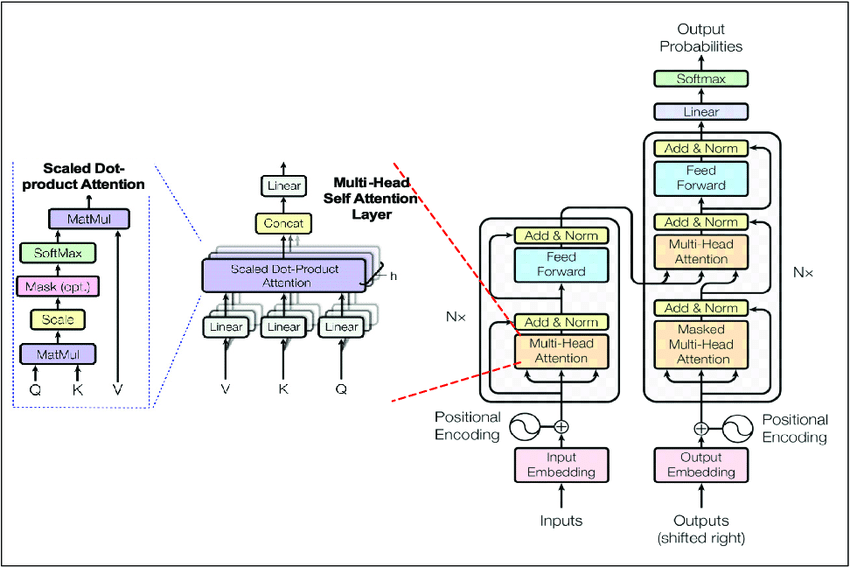
Knowing a bit about the history of the AI model market helps us understand the current landscape and how the market may evolve. When ChatGPT burst onto the scene, it felt like a breakthrough revolution to many, but was it? Or was it another incremental (albeit impressive) improvement in a long series of advances that were invisible outside of the development world? The team that developed ChatGPT built upon decades of research and publicly available tools from industry, academia, and the open-source community. Most notable is the transformer architecture itself — the critical insight driving not just ChatGPT, but most AI breakthroughs in the past five years. First proposed by Google in their 2017 paper Attention is All You Need, the transformer architecture is the foundation for models like Stable Diffusion, GPT-4, and Midjourney. The authors of that 2017 paper have founded some of the most prominent AI startups (e.g., CharacterAI, Cohere).
Given the common transformer architecture, what will enable some models to “win” against others? Variables like model size, input data quality/quantity, and proprietary research differentiate models. Model size has shown to correlate with improved performance, and the best funded players could differentiate by investing more in model training to further scale up their models. Proprietary data sources (such as those possessed by Meta from its user base and Elon Musk’s xAI from Tesla’s driving videos) could help some models learn what other models don’t have access to. GenAI is still a highly active area of ongoing research — research breakthroughs at companies with the best talent will partially determine the pace of advancement. It’s also unclear how strategies and use cases will create opportunities for different players. Perhaps application builders leverage multiple models to reduce dependency risk or to align a model’s unique strengths with specific use cases (e.g., research, interpersonal communications).
Cloud Service Providers & Data Center Operators
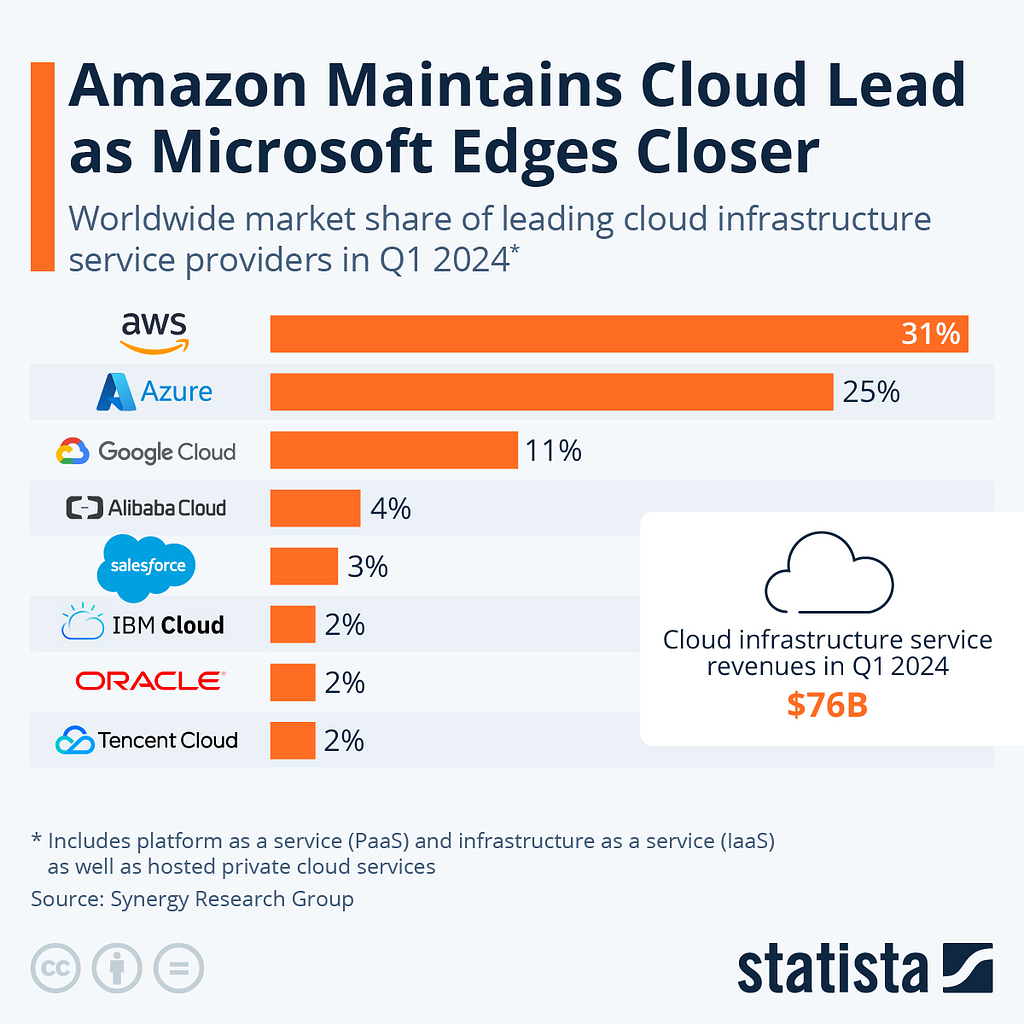
We discussed how model providers invest billions to build or rent computing resources to train these models. Where is that spending going? Much of it goes to cloud service providers like Microsoft’s Azure (used by OpenAI for GPT) and Amazon Web Services (used by Anthropic for Claude).
Cloud service providers (CSPs) play a crucial role in the GenAI value chain by providing the necessary infrastructure for model training (they also often provide infrastructure to the end application builders, but this section will focus on their interactions with the model builders). Major model builders primarily do not own and operate their own computing facilities (known as data centers). Instead, they rent vast amounts of computing power from the hyper-scaler CSPs (AWS, Azure, and Google Cloud) and other providers.
CSPs produce the resource computing power (manufactured by inputting electricity to a specialized microchip, thousands of which comprise a data center). To train their models, engineers provide the computers operated by CSPs with instructions to make computationally expensive matrix calculations over their input datasets to calculate billions of parameters of model weights. This model training phase is responsible for the high upfront cost of investment. Once these weights are calculated (i.e., the model is trained), model providers use these parameters to respond to user queries (i.e., make predictions on a novel dataset). This is a less computationally expensive process known as inference, also done using CSP computing power.
The cloud service provider’s role is building, maintaining, and administering data centers where this “computing power” resource is produced and used by model builders. CSP activities include acquiring computer chips from suppliers like Nvidia, “racking and stacking” server units in specialized facilities, and performing regular physical and digital maintenance. They also develop the entire software stack to manage these servers and provide developers with an interface to access the computing power and deploy their applications.
The principal operating expense for data centers is electricity, with AI-fueled data center expansion likely to drive a significant increase in electricity usage in the coming decades. For perspective, a standard query to ChatGPT uses ten times as much energy as an average Google Search. Goldman Sachs estimates that AI demand will double the data center’s share of global electricity usage by the decade’s end. Just as significant investments must be made in computing infrastructure to support AI, similar investments must be made to power this computing infrastructure.
Looking ahead, cloud service providers and their model builder partners are in a race to construct the largest and most powerful data centers capable of training the next generation models. The data centers of the future, like those under development by the partnership of Microsoft and OpenAI, will require thousands to millions of new cutting-edge microchips. The substantial capital expenditures by cloud service providers to construct these facilities are now driving record profits at the companies that help build those microchips, notably Nvidia (design) and TSMC (manufacturing).
Microchip Designers

At this point, everyone’s likely heard of Nvidia and its meteoric, AI-fueled stock market rise. It’s become a cliche to say that the tech giants are locked in an arms race and Nvidia is the only supplier, but is it true? For now, it is. Nvidia designs a form of computer microchip known as a graphical processing unit (GPU) that is critical for AI model training. What is a GPU, and why is it so crucial for GenAI? Why are most conversations in AI chip design centered around Nvidia and not other microchip designers like Intel, AMD, or Qualcomm?
Graphical processing units (as the name suggests) were initially used to serve the computer graphics market. Graphics for CGI movies like Jurassic Park and video games like Doom require expensive matrix computations, but these computations can be done in parallel rather than in series. Standard computer processors (CPUs) are optimized for fast sequential computation (where the input to one step could be output from a prior step), but they cannot do large numbers of calculations in parallel. This optimization for “horizontally” scaled parallel computation rather than accelerated sequential computation was well-suited for computer graphics, and it also came to be perfect for AI training.
Given GPUs served a niche market until the rise of video games in the late 90s, how did they come to dominate the AI hardware market, and how did GPU makers displace Silicon Valley’s original titans like Intel? In 2012, the program AlexNet won the ImageNet machine learning competition by using Nvidia GPUs to accelerate model training. They showed that the parallel computation power of GPUs was perfect for training ML models because like computer graphics, ML model training relied on highly parallel matrix computations. Today’s LLMs have expanded upon AlexNet’s initial breakthrough to scale up to quadrillions of arithmetic computations and billions of model parameters. With this explosion in parallel computing demand since AlexNet, Nvidia has positioned itself as the only potential chip for machine learning and AI model training thanks to heavy upfront investment and clever lock-in strategies.
Given the huge marketing opportunity in GPU design, it is reasonable to ask why Nvidia has no significant challengers (at the time of this writing, Nvidia holds 70–95% of the AI chip market share). Nvidia’s early investments in the ML and AI market before ChatGPT and before even AlexNet were key in establishing a hefty lead over other chipmakers like AMD. Nvidia allocated significant investment in research and development for the scientific computing (to become ML and AI) market segment before there was a clear commercial use case. Because of these early investments, Nvidia had already developed the best supplier and customer relationships, engineering talent, and GPU technology when the AI market took off.
Perhaps Nvidia’s most significant early investment and now its deepest moat against competitors is its CUDA programming platform. CUDA is a low-level software tool that enables engineers to interface with Nvidia’s chips and write parallel native algorithms. Many models, such as LlaMa, leverage higher-level Python libraries built upon these foundational CUDA tools. These lower level tools enable model designers to focus on higher-level architecture design choices without worrying about the complexities of executing calculations at the GPU processor core level. With CUDA, Nvidia built a software solution to strategically complement their hardware GPU products by solving many software challenges AI builders face.
CUDA not only simplifies the process of building parallelized AI and machine learning models on Nvidia chips, it also locks developers onto the Nvidia system, raising significant barriers to exit for any companies looking to switch to Nvidia’s competitors. Programs written in CUDA cannot run on competitor chips, which means that to switch off Nvidia chips, companies must rebuild not just the functionality of the CUDA platform, they must also rebuild any parts of their tech stack dependent on CUDA outputs. Given the massive stack of AI software built upon CUDA over the past decade, there is a substantial switching cost for anyone looking to move to competitors’ chips.
Microchip Manufacturers (Foundries)

Companies like Nvidia and AMD design chips, but they do not manufacture them. Instead, they rely on semiconductor manufacturing specialists known as foundries. Modern semiconductor manufacturing is one of the most complex engineering processes ever invented, and these foundries are a long way from most people’s image of a traditional factory. To illustrate, transistors on the latest chips are only 12 Silicon atoms long, shorter than the wavelength of visible light. Modern microchips have trillions of these transistors packed onto small silicon wafers and etched into atom-scale integrated circuits.
The key to manufacturing semiconductors is a process known as photolithography. Photolithography involves etching intricate patterns on a silicon wafer, a crystalized form of the element silicon used as the base for the microchip. The process involves coating the wafer with a light-sensitive chemical called photoresist and then exposing it to ultraviolet light through a mask that contains the desired circuit. The exposed areas of the photoresist are then developed, leaving a pattern that can be etched into the wafer. The most critical machines for this process are developed by the Dutch company ASML, which produces extreme ultraviolet (EUV) lithography systems and holds a similar stranglehold to Nvidia in its segment of the AI value chain.
Just as Nvidia came to dominate the GPU design market, its primary manufacturing partner, Taiwan Semiconductor Manufacturing Company (TSMC), holds a similarly large share of the manufacturing market for the most advanced AI chips. To understand TSMC’s place in the semiconductor manufacturing landscape, it is helpful to understand the broader foundry landscape.
Semiconductor manufacturers are split between two main foundry models: pure-play and integrated. Pure-play foundries, such as TSMC and GlobalFoundries, focus exclusively on manufacturing microchips for other companies without designing their own chips (the complement to fabless companies like Nvidia and AMD, who design but do not manufacture their chips). These foundries specialize in fabrication services, allowing fabless semiconductor companies to design microchips without heavy capital expenditures in manufacturing facilities. In contrast, integrated device manufacturers (IDMs) like Intel and Samsung design, manufacture, and sell their chips. The integrated model provides greater control over the entire production process but requires significant investment in both design and manufacturing capabilities. The pure-play model has gained popularity in recent decades due to the flexibility and capital efficiency it offers fabless designers, while the integrated model continues to be advantageous for companies with the resources to maintain design and fabrication expertise.
It is impossible to discuss semiconductor manufacturing without considering the vital role of Taiwan and the consequent geopolitical risks. In the late 20th century, Taiwan transformed itself from a low-margin, low-skilled manufacturing island into a semiconductor powerhouse, largely due to strategic government investments and a focus on high-tech industries. The establishment and growth of TSMC have been central to this transformation, positioning Taiwan at the heart of the global technology supply chain and leading to the outgrowth of many smaller companies to support manufacturing. However, this dominance has also made Taiwan a critical focal point in the ongoing geopolitical struggle, as China views the island as a breakaway province and seeks greater control. Any escalation of tensions could disrupt the global supply of semiconductors, with far-reaching consequences for the global economy, particularly in AI.
Silicon and Metal Miners

At the most basic level, all manufactured objects are created from raw materials extracted from the earth. For microchips used to train AI models, silicon and metals are their primary constituents. These and the chemicals used in the photolithography process are the primary inputs used by foundries to manufacture semiconductors. While the United States and its allies have come to dominate many parts of the value chain, its AI rival, China, has a firmer grasp on raw metals and other inputs.
The primary ingredient in any microchip is silicon (hence the name Silicon Valley). Silicon is one of the most abundant minerals in the earth’s crust and is commonly mined as Silica Dioxide (i.e., quartz or silica sand). Producing silicon wafers involves mining mineral quartzite, crushing it, and then extracting and purifying the elemental silicon. Next, chemical companies such as Sumco and Shin-Etsu Chemical convert pure silicon to wafers using a process called Czochralski growth, in which a seed crystal is dipped into molten high-purity silicon and slowly pulled upwards while rotating. This process creates a sizeable single-crystal silicon ingot sliced into thin wafers, which form the substrate for semiconductor manufacturing.
Beyond Silicon, computer chips also require trace amounts of rare earth metals. A critical step in semiconductor manufacturing is doping, in which impurities are added to the silicon to control conductivity. Doping is typically done with rare earth metals like Germanium, Arsenic, Gallium, and Copper. China dominates the global rare earth metal production, accounting for over 60% of mining and 85% of processing. Other significant rare earth metals producers include Australia, the United States, Myanmar, and the Democratic Republic of the Congo. The United States’ heavy reliance on China for rare earth metals poses significant geopolitical risks, as supply disruptions could severely impact the semiconductor industry and other high-tech sectors. This dependence has prompted efforts to diversify supply chains and develop domestic rare earth production capabilities in the US and other countries, though progress has been slow due to environmental concerns and the complex nature of rare earth processing.
Conclusion
The physical and digital technology stacks and value chains that support the development of AI are intricate and built upon decades of academic and industrial advances. The value chain encompasses end application builders, AI model builders, cloud service providers, chip designers, chip fabricators, and raw material suppliers, among many other key contributors. While much of the attention has been on major players like OpenAI, Nvidia, and TSMC, significant opportunities and bottlenecks exist at all points along the value chain. Thousands of new companies will be born to solve these problems. While companies like Nvidia and OpenAI might be the Intel and Google of their generation, the personal computing and internet booms produced thousands of other unicorns to fill niches and solve issues that came with inventing a new economy. The opportunities created by the shift to AI will take decades to be understood and realized, much as in personal computing in the 70s and 80s and the internet in the 90s and 00s.
While entrepreneurship and crafty engineering may solve many problems in the AI market, some problems involve far greater forces. No challenge is greater than rising geopolitical tension with China, which owns (or claims to own) most of the raw materials and manufacturing markets. This contrasts with the United States and its allies, who control most downstream phases of the chain, including chip design and model training. The struggle for AI dominance is especially vital because the opportunity unlocked by AI is not just economic but also military. Semi-autonomous weapons systems and cyberwarfare agents leveraging AI capabilities may play decisive roles in conflicts of the coming decades. Modern defense technology startups like Palantir and Anduril already show how AI capabilities can expand battlefield visibility and accelerate decision loops to gain potentially decisive advantage. Given AI’s high potential for disruption to the global order and the delicate balance of power between the United States and China, it is imperative that the two nations seek to maintain a cooperative relationship aimed at mutually beneficial development of AI technology for the betterment of global prosperity. Only by solving problems across the supply chain, from the scientific to the industrial to the geopolitical, can the promise of AI to supercharge humanity’s capabilities be realized.
What Goes Into AI? Exploring the GenAI Technology Stack was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
What Goes Into AI? Exploring the GenAI Technology Stack
Go Here to Read this Fast! What Goes Into AI? Exploring the GenAI Technology Stack