

A simple guide to Turing Machines, how they came to be, and how they helped us define what an algorithm is
Introduction
When we think of algorithms, we often describe them as similar to a recipe: a series of steps we follow to complete some task. We frequently use that definition when writing code, breaking down what must be done into smaller steps and writing code that executes them.
Although that intuitive notion of algorithm serves us well most of the time, having a formal definition allows us to do even more. With it, we can prove that some problems are fundamentally unsolvable, have a common ground for comparing and analyzing algorithms, and develop new ones. Nowadays, the Turing Machine is what typically fills that spot.
The Birth of the Turing Machine
Until the beginning of the 20th century, even mathematicians didn’t have a formal definition of what an algorithm was. Much like most of us do today, they relied on that same intuitive concept: a finite number of steps by which a function could be effectively calculated.
This became a limiting factor for mathematics in the last century. In 1928, David Hilbert, alongside Wilhelm Ackermann, proposed the decision problem, or the Entscheidungsproblem in German. The problem went as follows:
Is there an algorithm that can definitely answer “yes” or “no” to any mathematical statement?
This question couldn’t be answered without a proper definition of algorithm. Even before this, in 1900, Hilbert had also proposed 23 problems as challenges for the century to come, one of which ran into the same issue. The lack of a formal notion had already been plaguing mathematicians for a while.
Around 1936, two separate solutions to the Entscheidungsproblem were published independently. To solve it, they each proposed a method for how to define an algorithm. Alan Turing gave birth to the Turing Machine and Alonzo Church invented λ-Calculus. Both reached the same conclusion: the algorithm hypothesized by Hilbert and Ackermann couldn’t exist.
The two descriptions were equivalent in terms of power. That is, anything that could be described by a Turing machine could be described by λ-calculus and vice-versa. We tend to prefer Turing’s definition when discussing computer theory but assume both to be perfectly sufficient methods of describing an algorithm. This is known as the Church-Turing thesis.
A function can only be calculated by an effective method if it is computable by a Turing machine (or λ-calculus).
How Turing Machines Work
In simple terms, one can think of a Turing machine as a black box that receives a string of characters, processes it in some way, and returns whether it either accepts or denies the input.
This may seem strange at first, but it’s common in low-level languages like C, C++, or even bash script. When writing code in one of these languages, we often return 0 at the end of our script to signify a successful execution. We may have it instead return a 1 in case of a generic error.
#include <stdio.h>
int main()
{
printf("Hello World!");
return 0;
}
These values can then be checked by the operating system or other programs. Programming languages also allow for the return of numbers greater than 1 to specify a particular type of error but the general gist is still the same. As for what it means for a machine to accept or reject a certain input, that’s entirely up to the one who designed it.
Behind the curtain, the machine is made up of two core components: a control block and a tape. The tape is infinite and corresponds to the model’s memory. The control block can interact with the tape through a moving head that can both read from and write into the tape. The head can move left and right across the tape. It can go infinitely into the right but can’t go further left than the tape’s starting element as the tape only expands indefinitely towards one side.

At first, the tape is empty, filled only with blank symbols (⊔). When the machine reads the input string, it gets placed at the leftmost part of the tape. The head is also moved to the leftmost position, allowing the machine to start reading the input sequence from there. How it goes about reading the input, whether it writes over it, and any other implementation details are defined in the control block.
The control block is made up of a set of states interconnected by a transition function. The transitions defined in the transition function specify how to move between states depending on what is read from the tape, as well as what to write onto it and how to move its head.
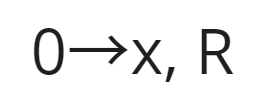
In the transition above, the first term refers to what is being read from the tape. Following the arrow, the next term will be written on the tape. Not only does the tape allow for any of the characters in the input to be written on it, but it also permits the usage of additional symbols present only in the tape. Following the comma, the last term is the direction in which to move the head: R means right and L means left.
The diagram below describes the inner workings of a Turing machine that accepts any string of at least 2 in length that starts and ends with 0, with an arbitrary amount of 1s in the middle. The transitions are placed next to arrows that point from one state to another. Every time the machine reads a character from the tape, it will check all the transitions that leave its current state. Then, it transitions along the arrow containing that symbol into the next state.
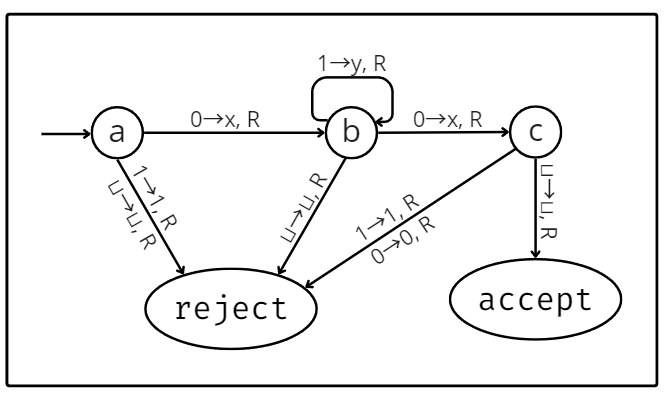
The Turing machine has 3 special states: a starting, an acceptance, and a rejection state. The starting state is indicated in the diagram by an arrow that only connects on one end and, as the name suggests, is the state the machine starts in. The remaining 2 states are equally straightforward: if the machine reaches the acceptance state, it accepts the input, and if it reaches the rejection state, it rejects it. Note that it may also loop eternally, without ever reaching either of them.
The diagram used was one for a deterministic Turing machine. That means every state had a transition leaving it for every possible symbol it may have read from the tape. In a non-deterministic Turing machine, this wouldn’t be the case. It is one of many Turing machine variations. Some may adopt more than one tape, others may have a “printer” attached, etc. The one thing to keep in mind with variations of the model is that they’re all equivalent in terms of power. That is, anything that any Turing machine variation can compute can also be calculated by the deterministic model.
The picture below is of a simple physical model of a Turing machine built by Mike Davey. It has a tape that can be moved left or right by two rotating motors and at its center lies a circuit that can read from and write onto the tape, perfectly capturing Turing’s concept.

The Relation to Modern Computers
Despite being simple, Turing machines are mighty. As the modern definition of an algorithm, it boasts the power to compute anything a modern computer can. After all, modern computers are based on the same principles. One might even refer to them as highly sophisticated real-world implementations of Turing machines.
That said, the problems dealt with by modern computers and the data structures used to tackle them are often much more complex than what we’ve discussed. How do Turing machines solve these problems? The trick behind it is encoding. No matter how complex, any data structure can be represented as a simple string of characters.

In the example above, we represent an undirected connected graph as a list of nodes followed by a list of edges. We use parenthesis and commas to isolate the individual nodes and edges. As long as the algorithm implemented by the Turing machine considers this representation, it should be able to perform any graph-related computations done by modern computers.
Data structures are stored in much the same way in real computers — just strings consisting of ones and zeros. In the end, at the barest level, all modern computers do is read and write strings of bits from and onto memory while following some logic. And, in doing so, they allow us to solve all kinds of problems from the barest to the highest complexity.
Conclusion
Understanding Turing machines and how they work provides helpful insight into the capabilities and limitations of computers. Beyond giving us a solid theoretical foundation to understand the underpinnings of complex algorithms, it allows us to determine whether an algorithm can even solve a given problem in the first place.
They are also central to complexity theory, which studies the difficulty of computational problems and how many resources, like time or memory, are required to solve them. Analyzing the complexity of an algorithm is an essential skill for anyone who works with software. Not only does it allow for the development of more efficient models and algorithms, as well as the optimization of existing ones, but it’s also helpful in choosing the right algorithm for the job.
In conclusion, a deep comprehension of Turing machines not only grants us a profound understanding of computers’ capabilities and boundaries but also gives us the foundation and tools necessary to ensure the efficiency of our solutions and drive innovation forward.
Reference
Introduction to the Theory of Computation
What Exactly Is An Algorithm? Turing Machines Explained was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
What Exactly Is An Algorithm? Turing Machines Explained
Go Here to Read this Fast! What Exactly Is An Algorithm? Turing Machines Explained