

Watermarking for AI Text and Synthetic Proteins
Understanding AI applications in bio for machine learning engineers
Misinformation and bioterrorism are not new threats, but the scale and ease with which they can be unleashed has rapidly increased. LLMs make the creation of autonomous chatbots intent on sowing discord trivial, while generative protein design models dramatically expand the population of actors capable of committing biowarfare. The tools we will need as a society to combat these ills are varied but one important component will be our ability to detect their presence. That is where watermarking comes in.
Watermarking or digital watermarking, unlike the physical watermark that holds your child’s school pictures ransom, is a secret signal used to identify ownership. Effective watermarks must be robust, withstanding modifications while remaining undetectable without specialized methods. They are routinely used in various creative domains, from protecting copyrighted digital images and videos to ensuring the integrity of documents. If we can develop effective watermarking techniques for GenAI, we can gain a powerful tool in the fight against misinformation and bioterrorism.
In our series, we’ve explored how other generative text and biology breakthroughs have relied on related architectural breakthroughs and current watermarking proposals are no different. Google announced SynthID-Text, a production-ready text watermarking scheme deployed as part of Gemini in October 2024. Their method modifies the final sampling procedure or inference by applying a secret randomized function and so does the generative protein design watermarking proposal from the team at the University of Maryland, College Park.


{kind=link}
Key Desired Qualities in Watermarking
Robustness — it should withstand perturbations of the watermarked text/structure.
If an end user can simply swap a few words before publishing or the protein can undergo mutations and become undetectable, the watermark is insufficient.
Detectability — it should be reliably detected by special methods but not otherwise.
For text, if the watermark can be detected without secret keys, it likely means the text is so distorted it sounds strange to the reader. For protein design, if it can be detected nakedly, it could lead to a degradation in design quality.
Watermarking text and Synthtext-ID
Let’s delve into this topic. If you are like me and spend too much time on Twitter, you are already aware that many people realize ChatGPT overuses certain words. One of those is “delve” and its overuse is being used to analyze how frequently academic articles are written by or with the help of ChatGPT. This is itself a sort of “fragile” watermarking because it can help us identify text written by an LLM. However, as this becomes common knowledge, finding and replacing instances of “delve” is too easy. But the idea behind SynthText-ID is there, we can tell the difference between AI and human written text by the probability of words selected.
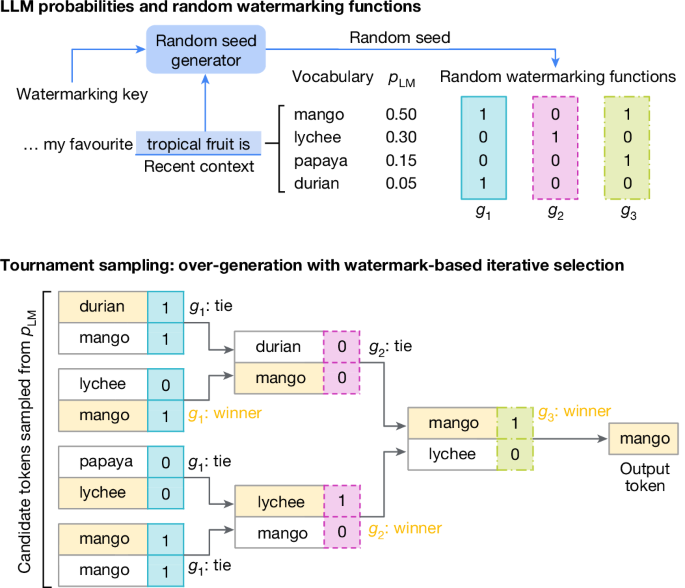
SynthText-ID uses “tournament sampling” to modify the probability of a token being selected according to a random watermarking function. This is an efficient method for watermarking because it can be done during inference without changing the training procedure. This method improves upon Gumble Sampling, which adds random perturbation to the LLM’s probability distribution before the sampling step.
In the paper’s example, the sequence “my favorite tropical fruit is” can be completed satisfactorily with any token from a set of candidate tokens (mango, durian, lychee etc). These candidates are sampled from the LLMs probability distribution conditioned on the preceding text. The winning token is selected after a bracket is constructed and each token pair is scored using a watermarking function based on a context window and a watermarking key. This process introduces a statistical signature into the generated text to be measured later.
To detect the watermark, each token is scored with the watermarking function, and the higher the mean score, the more likely the text came from an LLM. A simple threshold is applied to predict the text’s origin.
The strength of this signature is controlled by a few factors:
- The number of rounds (m) in the tournament (typically m=30) where each round strengthens the signature (and also decreases the score variance).
- The entropy of the LLM. Low entropy models don’t allow enough randomness for the tournament to select candidates which score highly. FWIW this seems like a big issue to the author who has never used any setting other than temperature=0 with ChatGPT.
- The length of the text; longer sequences contain more evidence and thus the statistical certainty increases.
- Whether a non-distortionary and distortionary configuration is used.
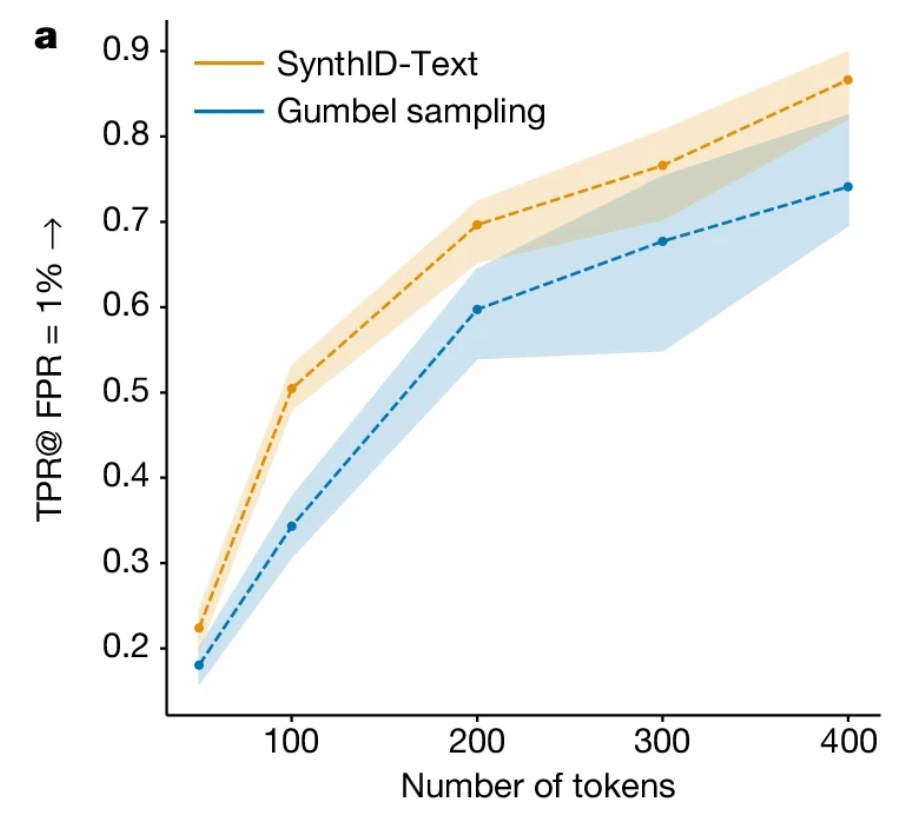
Distortion refers to the emphasis placed on preserving text quality versus detection. The non-distortionary configuration prioritizes the quality of the text, trading off detectability. The distortionary configuration does the opposite. The distortionary configuration uses more than two tokens in each tournament match, thus allowing for more wiggle room to select the highest-scoring tokens. Google says they will implement a non-distortionary version of this algorithm in Gemini.
The non-distortionary version reaches a TPR (True Positive Rate) approaching 90% with a False Positive rate of 1% for 400 token sequences, this is roughly 1–2 paragraphs. A (non-paid) tweet or X post is limited to 280 characters or about 70–100 tokens. The TPR at that length is only about 50% which calls into question how effective this method will be in the wild. Maybe it will be great for catching lazy college students but not foreign actors during elections?
Watermarking Generative Proteins and Biosecurity
Biosecurity is a word you may have started hearing a lot more frequently after Covid. We will likely never definitively know if the virus came from a wet market or a lab leak. But, with better watermarking tools and biosecurity practices, we might be able to trace the next potential pandemic back to a specific researcher. There are existing database logging methods for this purpose, but the hope is that generative protein watermarking would enable tracing even for new or modified sequences that might not match existing hazardous profiles and that watermarks would be more robust to mutations. This would also come with the benefit of enhanced privacy for researchers and simplifications to the IP process.
When a text is distorted by the watermarking process, it could confuse the reader or just sound weird. More seriously, distortions in generative protein design could render the protein utterly worthless or functionally distinct. To avoid distortion, the watermark must not alter the overall statistical properties of the designed proteins.
The watermarking process is similar enough to SynthText-ID. Instead of modifying the token probability distribution, the amino acid residue probability distribution is adjusted. This is done via an unbiased reweighting function (Gumble Sampling, instead of tournament sampling) which takes the original probability distribution of residues and transforms it based on a watermark code derived from the researcher’s private key. Gumble sampling is considered unbiased because it is specifically designed to approximate the maximum of a set of values in a way that maintains the statistical properties of the original distribution without introducing systematic errors; or on average the introduced noise cancels out.
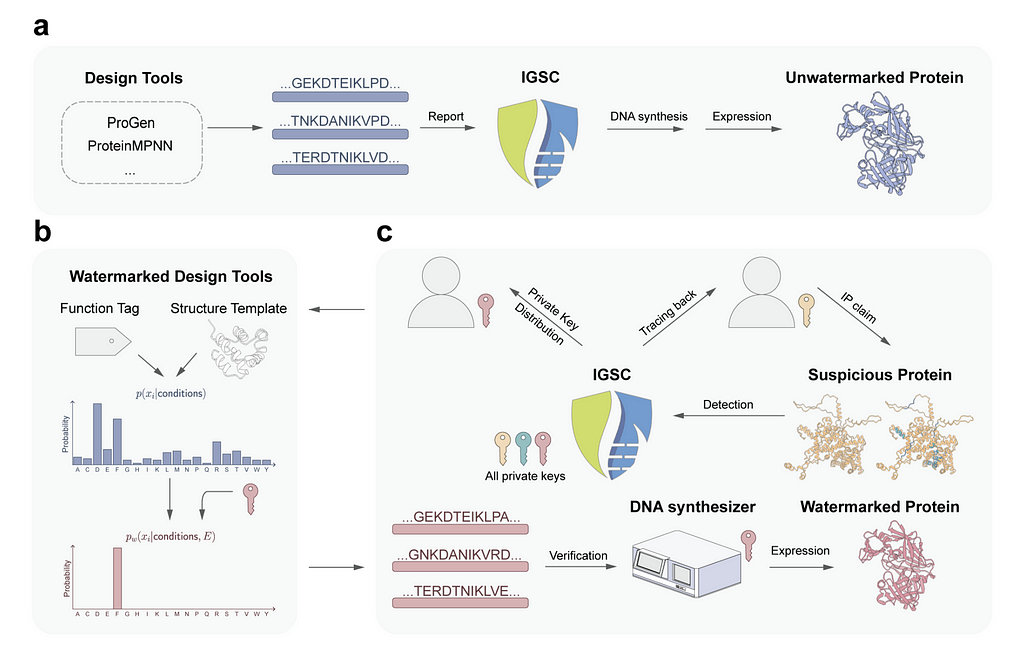
The researchers validated that the reweighting function was unbiased through experimental validation with proteins designed by ProteinMPNN, a deep learning–based protein sequence design model. Then the pLDDT or predicted local distance difference test is predicted using ESMFold (Evolutionary Scale Modeling) before and after watermarking. Results show no change in performance.
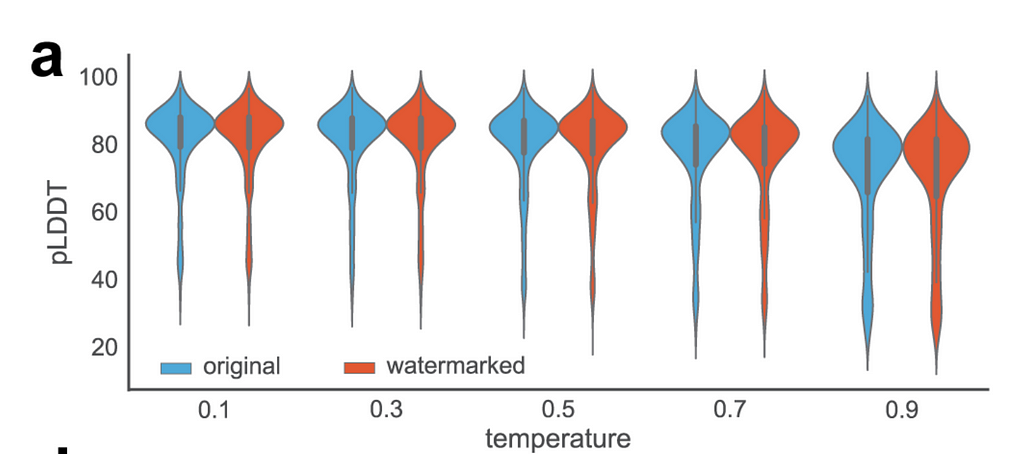
Similar to detection with low-temperature LLM settings, detection is more difficult when there are only a few possible high-quality designs. The resulting low entropy makes it difficult to embed a detectable watermark without introducing noticeable changes. However, this limitation may be less dire than the similar limitation for LLMs. Low entropy design tasks may only have a few proteins in the protein space that can satisfy the requirements. That makes them easier to track using existing database methods.
Takeaways
- Watermarking methods for LLMs and Protein Designs are improving but still need to improve! (Can’t rely on them to detect bot armies!)
- Both approaches focus on modifying the sampling procedure; which is important because it means we don’t need to edit the training process and their application is computationally efficient.
- The temperature and length of text are important factors concerning the detectability of watermarks. The current method (SynthText-ID) is only about 90% TPR for 1–2 paragraph length sequences at 1% FPR.
- Some proteins have limited possible structures and those are harder to watermark. However, existing methods should be able to detect those sequences using databases.
Watermarking for AI Text and Synthetic Proteins: Fighting Misinformation and Bioterrorism was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Watermarking for AI Text and Synthetic Proteins: Fighting Misinformation and Bioterrorism