
A conversational question-answering tool built using LangChain, Pinecone, Flask, React and AWS
Introduction
Have you ever encountered a podcast or a video you wanted to watch, but struggled to find the time due to its length? Have you wished for an easy way to refer back to specific sections of content in this form ?
This is an issue I’ve faced many times when it comes to YouTube videos of popular podcasts like The Diary of a CEO. Indeed, a lot of the information covered in podcasts such as this is readily available through a quick Google search. But listening to an author’s take on something they are passionate about, or hearing about a successful entrepreneur’s experience from their perspective tends to provide much more insight and clarity.
Motivated by this problem and a desire to educate myself on LLM-powered applications and their development, I decided to build a chatbot which allows users to ask questions about the content of YouTube videos using the RAG (Retrieval Augmented Generation) framework. In the rest of this post, I’ll talk through my experience developing this application using LangChain, Pinecone, Flask, and React, and deploying it with AWS:

I’ve limited code snippets to those that I think will be most useful. For anyone interested, the complete codebase for the application can be found here.
Backend
We’ll be using the transcripts of YouTube videos as the source from which the LLM generates answers to user-defined questions. To facilitate this, the backend will need a method of retrieving and appropriately storing these for use in real time, as well as one for using them to generate answers. We also want a way of storing chat histories so that users can refer back to them at a later time. Let’s see how the backend can be developed to satisfy all of these requirements now.
Response generation
Since this is a conversational question-answering tool, the application must be able to generate answers to questions while taking both the relevant context and chat history into account. This can be achieved using Retrieval Augmented Generation with Conversation Memory, as illustrated below:

For clarity, the steps involved are as follows:
- Question summarisation: The current question and the chat history are condensed into a standalone question using an appropriate prompt asking the LLM to do so.
- Semantic search: Next, the YouTube transcript chunks that are most relevant to this condensed question must be retrieved. The transcripts themselves are stored as embeddings, which are numerical representations of words and phrases, learned by an embedding model that captures their content and semantics. During the semantic search, the components of each transcript whose embeddings are most similar to those of the condensed question are retrieved.
- Context-aware generation: These retrieved transcript chunks are then used as the context within another prompt to the LLM asking it to answer the condensed question. Using the condensed question ensures that the generated answer is relevant to the current question as well as previous questions asked by the user during the chat.
Data Pipeline
Before moving on to the implementation of the process outlined above, let’s take a step back and focus on the YouTube video transcripts themselves. As discussed, they must be stored as embeddings to efficiently search for and retrieve them during the semantic search phase of the RAG process. Let’s go through the source, method of retrieval and method of storage for these now.
- Source: YouTube provides access to metadata like video IDs, as well as autogenerated transcripts through its Data API. To begin with, I’ve selected this playlist from The Diary of a CEO podcast, in which various money experts and entrepreneurs discuss personal finance, investing, and building successful businesses.
- Retrieval: I make use of one class responsible for retrieving metadata on YouTube videos like Video IDs by interacting directly with the YouTube Data API, and another which uses the youtube-transcript-API Python package to retrieve the video transcripts. These transcripts are then stored as JSON files in an S3 bucket in their raw form.
- Storage: Next, the transcripts need to be converted to embeddings and stored in a vector database. However, a pre-requisite to this step is splitting them into chunks so that upon retrieval, we get segments of text that are of the highest relevance to each question while also minimising the length of the LLM prompt itself. To satisfy this requirement I define a custom S3JsonFileLoader class here (due to some issues with LangChain’s out-of-the-box version), and make use of the text splitter object to split the transcripts at load time. I then make use of LangChain’s interface to the Pinecone Vectorstore (my vector store of choice for efficient storage, search and retrieval of the transcript embeddings) to store the transcript chunks as embeddings expected by OpenAI’s gpt-3.5-turbo model:
import os
import pinecone
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Pinecone
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from chatytt.embeddings.s3_json_document_loader import S3JsonFileLoader
# Define the splitter with which to split the transcripts into chunks
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=pre_processing_conf["recursive_character_splitting"]["chunk_size"],
chunk_overlap=pre_processing_conf["recursive_character_splitting"][
"chunk_overlap"
],
)
# Load and split the transcript
loader = S3JsonFileLoader(
bucket="s3_bucket_name",
key="transcript_file_name",
text_splitter=text_splitter,
)
transcript_chunks = loader.load(split_doc=True)
# Connect to the relevant Pinecone vectorstore
pinecone.init(
api_key=os.environ.get("PINECONE_API_KEY"), environment="gcp-starter"
)
pinecone_index = pinecone.Index(os.environ.get("INDEX_NAME"), pool_threads=4)
# Store the transcrpt chunks as embeddings in Pinecone
vector_store = Pinecone(
index=pinecone_index,
embedding=OpenAIEmbeddings(),
text_key="text",
)
vector_store.add_documents(documents=transcript_chunks)
We can also make use of a few AWS services to automate these steps using a workflow configured to run periodically. I do this by implementing each of the three steps mentioned above in separate AWS Lamba Functions (a form of serverless computing, which provisions and utilises resources as needed at runtime), and defining the order of their execution using AWS Step Functions (a serverless orchestration tool). This workflow is then executed by an Amazon EventBridge schedule which I’ve set to run once a week so that any new videos added to the playlist are retrieved and processed automatically:
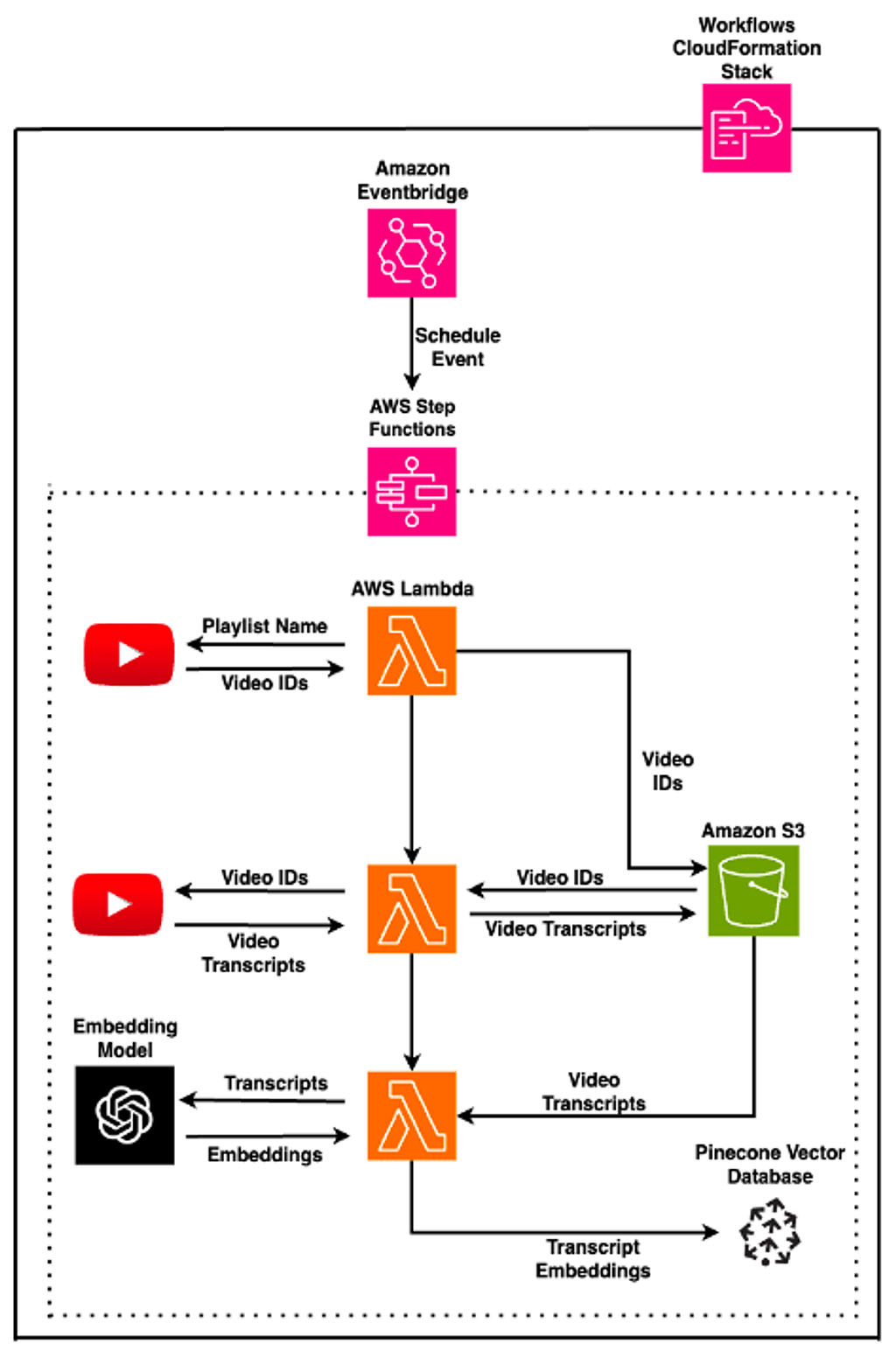
Note that I have obtained permission from the The Diary of a CEO channel, to use the transcripts of videos from the playlist mentioned above. Anyone wishing to use third party content in this way, should first obtain permission from the original owners.
Implementing RAG
Now that the transcripts for our playlist of choice are periodically being retrieved, converted to embeddings and stored, we can move on to the implementation of the core backend functionality for the application i.e. the process of generating answers to user-defined questions using RAG. Luckily, LangChain has a ConversationalRetrievalChain that does exactly that out of the box! All that’s required is to pass in the query, chat history, a vector store object that can be used to retrieve transcripts chunks, and an LLM of choice into this chain like so:
import pinecone
from langchain.vectorstores import Pinecone
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
# Define the vector store with which to perform a semantic search against
# the Pinecone vector database
pinecone.init(
api_key=os.environ.get("PINECONE_API_KEY"), environment="gcp-starter"
)
pinecone_index = pinecone.Index(os.environ.get("INDEX_NAME"), pool_threads=4)
vector_store = Pinecone(
index=pinecone_index,
embedding=OpenAIEmbeddings(),
text_key="text",
)
# Define the retrieval chain that will perform the steps in RAG
# with conversation memory as outlined above.
chain = ConversationalRetrievalChain.from_llm(
llm=ChatOpenAI(), retriever=vector_store.as_retriever()
)
# Call the chain passing in the current question and the chat history
response = chain({"question": query, "chat_history": chat_history})["answer"]
I’ve also implemented the functionality of this chain from scratch, as described in LangChain’s tutorials, using both LangChain Expression Language here and SequentialChain here . These may provide more insight into all of the actions taking place under the hood in the chain used above.
Saving Chat History
The backend can generate answers to questions now, but it would also be nice to store and retrieve chat history so that users can refer to old chats as well. Since this is a known access pattern of the same item for different users I decided to use DynamoDB, a NoSQL database known for its speed and cost efficiency in handling unstructured data of this form. In addition, the boto3 SDK simplifies interaction with the database, requiring just a few functions for storing and retrieving data:
import os
import time
from typing import List, Any
import boto3
table = boto3.resource("dynamodb").Table(os.environ.get("CHAT_HISTORY_TABLE_NAME")
def fetch_chat_history(user_id: str) -> str:
response = table.get_item(Key={"UserId": user_id})
return response["Item"]
def update_chat_history(user_id: str, chat_history: List[dict[str, Any]]):
chat_history_update_data = {
"UpdatedTimestamp": {"Value": int(time.time()), "Action": "PUT"},
"ChatHistory": {"Value": chat_history, "Action": "PUT"},
}
table.update_item(
Key={"UserId": user_id}, AttributeUpdates=chat_history_update_data
)
def is_new_user(user_id: str) -> bool:
response = table.get_item(Key={"UserId": user_id})
return response.get("Item") is None
def create_chat_history(user_id: str, chat_history: List[dict[str, Any]]):
item = {
"UserId": user_id,
"CreatedTimestamp": int(time.time()),
"UpdatedTimestamp": None,
"ChatHistory": chat_history,
}
table.put_item(Item=item)
Exposing Logic via an API
We have now covered all of the core functionality, but the client side of the app with which the user interacts will need some way of triggering and making use of these processes. To facilitate this, each of the three pieces of logic (generating answers, saving chat history, and retrieving chat history) are exposed through separate endpoints within a Flask API, which will be called by the front end:
from dotenv import load_dotenv
from flask import Flask, request, jsonify
from flask_cors import CORS
from chatytt.chains.standard import ConversationalQAChain
from chatytt.vector_store.pinecone_db import PineconeDB
from server.utils.chat import parse_chat_history
from server.utils.dynamodb import (
is_new_user,
fetch_chat_history,
create_chat_history,
update_chat_history,
)
load_dotenv()
app = Flask(__name__)
# Enable Cross Origin Resource Sharing since the server and client
# will be hosted seperately
CORS(app)
pinecone_db = PineconeDB(index_name="youtube-transcripts", embedding_source="open-ai")
chain = ConversationalQAChain(vector_store=pinecone_db.vector_store)
@app.route("/get-query-response/", methods=["POST"])
def get_query_response():
data = request.get_json()
query = data["query"]
raw_chat_history = data["chatHistory"]
chat_history = parse_chat_history(raw_chat_history)
response = chain.get_response(query=query, chat_history=chat_history)
return jsonify({"response": response})
@app.route("/get-chat-history/", methods=["GET"])
def get_chat_history():
user_id = request.args.get("userId")
if is_new_user(user_id):
response = {"chatHistory": []}
return jsonify({"response": response})
response = {"chatHistory": fetch_chat_history(user_id=user_id)["ChatHistory"]}
return jsonify({"response": response})
@app.route("/save-chat-history/", methods=["PUT"])
def save_chat_history():
data = request.get_json()
user_id = data["userId"]
if is_new_user(user_id):
create_chat_history(user_id=user_id, chat_history=data["chatHistory"])
else:
update_chat_history(user_id=user_id, chat_history=data["chatHistory"])
return jsonify({"response": "chat saved"})
if __name__ == "__main__":
app.run(debug=True, port=8080)
Lastly, I use AWS Lambda to wrap the three endpoints in a single function that is then triggered by an API Gateway resource, which routes requests to the correct endpoint by constructing an appropriate payload for each as needed. The flow of this setup now looks as follows:

Frontend
With the backend for the app complete, I’ll briefly cover the implementation of the user interface in React, giving special attention to the interactions with the server component housing the API above.
I make use of dedicated functional components for each section of the app, covering all of the typical requirements one might expect in a chatbot application:
- A container for user inputs with a send chat button.
- A chat feed in which user inputs and answers are displayed.
- A sidebar containing chat history, a new chat button and a save chat button.
The interaction between these components and the flow of data is illustrated below:

The API calls to each of the three endpoints and the subsequent change of state of the relevant variables on the client side, are defined in separate functional components:
- The logic for retrieving the generated answer to each question:
import React from "react";
import {chatItem} from "./LiveChatFeed";
interface Props {
setCurrentChat: React.SetStateAction<any>
userInput: string
currentChat: Array<chatItem>
setUserInput: React.SetStateAction<any>
}
function getCurrentChat({setCurrentChat, userInput, currentChat, setUserInput}: Props){
// The current chat is displayed in the live chat feed. Since we don't want
// to wait for the LLM response before displaying the users question in
// the chat feed, copy it to a seperate variable and pass it to the current
// chat before pining the API for the answer.
const userInputText = userInput
setUserInput("")
setCurrentChat([
...currentChat,
{
"text": userInputText,
isBot: false
}
])
// Create API payload for the post request
const options = {
method: 'POST',
headers: {
"Content-Type": 'application/json',
'Accept': 'application/json'
},
body: JSON.stringify({
query: userInputText,
chatHistory: currentChat
})
}
// Ping the endpoint, wait for the response, and add it to the current chat
// so that it appears in the live chat feed.
fetch(`${import.meta.env.VITE_ENDPOINT}get-query-response/`, options).then(
(response) => response.json()
).then(
(data) => {
setCurrentChat([
...currentChat,
{
"text": userInputText,
"isBot": false
},
{
"text": data.response,
"isBot": true
}
])
}
)
}
export default getCurrentChat
2. Saving chat history when the user clicks the save chat button:
import React, {useState} from "react";
import {chatItem} from "./LiveChatFeed";
import saveIcon from "../assets/saveicon.png"
import tickIcon from "../assets/tickicon.png"
interface Props {
userId: String
previousChats: Array<Array<chatItem>>
}
function SaveChatHistoryButton({userId, previousChats}: Props){
// Define a state to determine if the current chat has been saved or not.
const [isChatSaved, setIsChatSaved] = useState(false)
// Construct the payload for the PUT request to save chat history.
const saveChatHistory = () => {
const options = {
method: 'PUT',
headers: {
"Content-Type": 'application/json',
'Accept': 'application/json'
},
body: JSON.stringify({
"userId": userId,
"chatHistory": previousChats
})
}
// Ping the API with the chat history, and set the state of
// isChatSaved to true if successful
fetch(`${import.meta.env.VITE_ENDPOINT}save-chat-history/`, options).then(
(response) => response.json()
).then(
(data) => {
setIsChatSaved(true)
}
)
}
// Display text on the save chat button dynamically depending on the value
// of the isChatSaved state.
return (
<button
className="save-chat-history-button"
onClick={() => {saveChatHistory()}}
> <img className={isChatSaved?"tick-icon-img":"save-icon-img"} src={isChatSaved?tickIcon:saveIcon}/>
{isChatSaved?"Chats Saved":"Save Chat History"}
</button>
)
}
export default SaveChatHistoryButton
3. Retrieving chat history when the app first loads up:
import React from "react";
import {chatItem} from "./LiveChatFeed";
interface Props {
userId: String
previousChats: Array<Array<chatItem>>
setPreviousChats: React.SetStateAction<any>
}
function getUserChatHistory({userId, previousChats, setPreviousChats}: Props){
// Create the payload for the GET request
const options = {
method: 'GET',
headers: {
"Content-Type": 'application/json',
'Accept': 'application/json'
}
}
// Since this is a GET request pass in the user id as a query parameter
// Set the previousChats state to the chat history returned by the API.
fetch(`${import.meta.env.VITE_ENDPOINT}get-chat-history/?userId=${userId}`, options).then(
(response) => response.json()
).then(
(data) => {
if (data.response.chatHistory.length > 0) {
setPreviousChats(
[
...previousChats,
...data.response.chatHistory
]
)
}
}
)
}
export default getUserChatHistory
For the UI itself, I chose something very similar to ChatGPT’s own interface housing a central chat feed component, and a sidebar containing supporting content like chat histories. Some quality-of-life features for the user include automatic scrolling to the most recently created chat item, and previous chats loading upon sign-in (I have not included these in the article, but you can find their implementation in the relevant functional component here). The final UI appears as shown below:
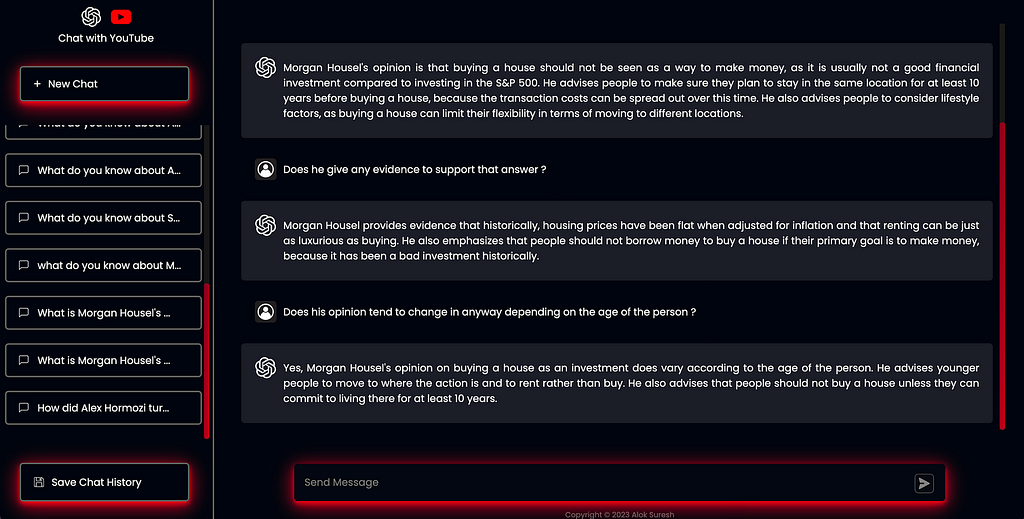
Now that we have a fully functional UI, all that’s left is hosting it for use online which I’ve chosen to do with AWS Amplify. Among other things, Amplify is a fully managed web hosting service that handles resource provisioning and hosting of web applications. User authentication for the app is managed by Amazon Cognito allowing user sign-up and sign-on, alongside handling credential storage and management:

Comparison to ChatGPT responses
Now that we’ve discussed the process of building the app, let’s have a deep dive into the responses generated for some questions, and compare these to the same question posed to ChatGPT*.
Note that this type of comparison is inherently an “unfair” one since the underlying prompts to the LLM used in our application will contain additional context (in the form of relevant transcript chunks) retrieved from the semantic search step. However, it will allow us to qualitatively assess just how much of a difference the prompts created using RAG make, to the responses generated by the same underlying LLM.
*All ChatGPT responses are from gpt-3.5, since this was the model used in the application.
Example 1:
You want to learn about the contents in this video where Steven Bartlett chats to Morgan Housel, a financial writer and investor. Based on the title of the video, it looks like he’s against buying a house — but suppose you don’t have time to watch the whole thing to find out why. Here is a snippet of the conversation I had with the application asking about it:

You can also see the conversation memory in action here, where in follow-up questions I make no mention of Morgan Housel explicitly or even the words “house” or “buying”. Since the summarised query takes previous chat history into account, the response from the LLM reflects previous questions and their answers. The portion of the video in which Housel mentions the points above can be found roughly an hour and a half into the podcast — around the 1:33:00–1:41:00 timestamp.
I asked ChatGPT the same thing, and as expected got a very generic answer that is non-specific to Housel’s opinion.

It’s arguable that since the video came out after the model’s last “knowledge update” the comparison is flawed, but Housel’s opinions are also well documented in his book ‘The Psychology of Money’ which was published in 2020. Regardless, the reliance on these knowledge updates further highlights the benefits of context-aware answer generation over standalone models.
Example 2
Below are some snippets from a chat about this discussion with Alex Hormozi, a monetization and acquisitions expert. From the title of the video, it looks like he knows a thing or two about successfully scaling businesses so I ask for more details on this:

This seems like a reasonable answer, but let’s see if we can extract any more information from the same line of questioning.


Notice the level of detail the LLM is able to extract from the YouTube transcripts. All of the above can be found over a 15–20 minute portion of the video around the 17:00–35:00 timestamp.
Again, the same question posed to ChatGPT returns a generic answer about the entrepreneur but lacks the detail made available through the context within the video transcripts.

Deployment
The final thing we’ll discuss is the process of deploying each of the components on AWS. The data pipeline, backend, and frontend are each contained within their own CloudFormation stacks (collections of AWS resources). Allowing these to be deployed in isolation like this, ensures that the entire app is not redeployed unnecessarily during development. I make use of AWS SAM (Serverless Application Model) to deploy the infrastructure for each component as code, leveraging the SAM template specification and CLI:
- The SAM template specification — A short-hand syntax, that serves as an extension to AWS CloudFormation, for defining and configuring collections of AWS resources, how they should interact, and any required permissions.
- The SAM CLI — A command line tool used, among other things, for building and deploying resources as defined in a SAM template. It handles the packaging of application code and dependencies, converting the SAM template to CloudFormation syntax and deploying templates as individual stacks on CloudFormation.
Rather than including the complete templates (resource definitions) of each component, I will highlight specific areas of interest for each service we’ve discussed throughout the post.
Passing sensitive environment variables to AWS resources:
External components like the Youtube Data API, OpenAI API and Pinecone API are relied upon heavily throughout the application. Although it is possible to hardcode these values into the CloudFormation templates and pass them around as ‘parameters’, a safer method is to create secrets for each in AWS SecretsManager and reference these secrets in the template like so:
Parameters:
YoutubeDataAPIKey:
Type: String
Default: '{{resolve:secretsmanager:youtube-data-api-key:SecretString:youtube-data-api-key}}'
PineconeAPIKey:
Type: String
Default: '{{resolve:secretsmanager:pinecone-api-key:SecretString:pinecone-api-key}}'
OpenaiAPIKey:
Type: String
Default: '{{resolve:secretsmanager:openai-api-key:SecretString:openai-api-key}}'
Defining a Lambda Function:
These units of serverless code form the backbone of the data pipeline and serve as an entry point to the backend for the web application. To deploy these using SAM, it’s as simple as defining the path to the code that the function should run when invoked, alongside any required permissions and environment variables. Here is an example of one of the functions used in the data pipeline:
FetchLatestVideoIDsFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: ../code_uri/.
Handler: chatytt.youtube_data.lambda_handlers.fetch_latest_video_ids.lambda_handler
Policies:
- AmazonS3FullAccess
Environment:
Variables:
PLAYLIST_NAME:
Ref: PlaylistName
YOUTUBE_DATA_API_KEY:
Ref: YoutubeDataAPIKey
Retrieving the definition of the data pipeline in Amazon States Language:
In order to use Step Functions as an orchestrator for the individual Lambda functions in the data pipeline, we need to define the order in which each should be executed as well as configurations like max retry attempts in Amazon States Language. An easy way to do this is by using the Workflow Studio in the Step Functions console to diagrammatically create the workflow, and then take the autogenerated ASL definition of the workflow as a starting point that can be altered appropriately. This can then be linked in the CloudFormation template rather than being defined in place:
EmbeddingRetrieverStateMachine:
Type: AWS::Serverless::StateMachine
Properties:
DefinitionUri: statemachine/embedding_retriever.asl.json
DefinitionSubstitutions:
FetchLatestVideoIDsFunctionArn: !GetAtt FetchLatestVideoIDsFunction.Arn
FetchLatestVideoTranscriptsArn: !GetAtt FetchLatestVideoTranscripts.Arn
FetchLatestTranscriptEmbeddingsArn: !GetAtt FetchLatestTranscriptEmbeddings.Arn
Events:
WeeklySchedule:
Type: Schedule
Properties:
Description: Schedule to run the workflow once per week on a Monday.
Enabled: true
Schedule: cron(0 3 ? * 1 *)
Policies:
- LambdaInvokePolicy:
FunctionName: !Ref FetchLatestVideoIDsFunction
- LambdaInvokePolicy:
FunctionName: !Ref FetchLatestVideoTranscripts
- LambdaInvokePolicy:
FunctionName: !Ref FetchLatestTranscriptEmbeddings
See here for the ASL definition used for the data pipeline discussed in this post.
Defining the API resource:
Since the API for the web app will be hosted separately from the front-end, we must enable CORS (cross-origin resource sharing) support when defining the API resource:
ChatYTTApi:
Type: AWS::Serverless::Api
Properties:
StageName: Prod
Cors:
AllowMethods: "'*'"
AllowHeaders: "'*'"
AllowOrigin: "'*'"
This will allow the two resources to communicate freely with each other. The various endpoints made accessible through a Lambda function can be defined like so:
ChatResponseFunction:
Type: AWS::Serverless::Function
Properties:
Runtime: python3.9
Timeout: 120
CodeUri: ../code_uri/.
Handler: server.lambda_handler.lambda_handler
Policies:
- AmazonDynamoDBFullAccess
MemorySize: 512
Architectures:
- x86_64
Environment:
Variables:
PINECONE_API_KEY:
Ref: PineconeAPIKey
OPENAI_API_KEY:
Ref: OpenaiAPIKey
Events:
GetQueryResponse:
Type: Api
Properties:
RestApiId: !Ref ChatYTTApi
Path: /get-query-response/
Method: post
GetChatHistory:
Type: Api
Properties:
RestApiId: !Ref ChatYTTApi
Path: /get-chat-history/
Method: get
UpdateChatHistory:
Type: Api
Properties:
RestApiId: !Ref ChatYTTApi
Path: /save-chat-history/
Method: put
Defining the React app resource:
AWS Amplify can build and deploy applications using a reference to the relevant Github repository and an appropriate access token:
AmplifyApp:
Type: AWS::Amplify::App
Properties:
Name: amplify-chatytt-client
Repository: <https://github.com/suresha97/ChatYTT>
AccessToken: '{{resolve:secretsmanager:github-token:SecretString:github-token}}'
IAMServiceRole: !GetAtt AmplifyRole.Arn
EnvironmentVariables:
- Name: ENDPOINT
Value: !ImportValue 'chatytt-api-ChatYTTAPIURL'
Once the repository itself is accessible, Ampify will look for a configuration file with instructions on how to build and deploy the app:
version: 1
frontend:
phases:
preBuild:
commands:
- cd client
- npm ci
build:
commands:
- echo "VITE_ENDPOINT=$ENDPOINT" >> .env
- npm run build
artifacts:
baseDirectory: ./client/dist
files:
- "**/*"
cache:
paths:
- node_modules/**/*
As a bonus, it is also possible to automate the process of continuous deployment by defining a branch resource that will be monitored and used to re-deploy the app automatically upon further commits:
AmplifyBranch:
Type: AWS::Amplify::Branch
Properties:
BranchName: main
AppId: !GetAtt AmplifyApp.AppId
EnableAutoBuild: true
With deployment finalised in this way, it is accessible to anyone with the link made available from the AWS Amplify console. A recorded demo of the app being accessed like this can be found here:
Conclusion
At a high level, we have covered the steps behind:
- Building a data pipeline for the collection and storage of content as embeddings.
- Developing a backend server component which performs Retrieval Augmented Generation with Conversation Memory.
- Designing a user interface for surfacing generated answers and chat histories.
- How these components can be connected and deployed to create a solution that provides value and saves time.
We’ve seen how an application like this can be used to streamline and in some ways ‘optimise’ the consumption of content such as YouTube videos for learning and development purposes. But these methods can just as easily be applied in the workplace for internal use or for augmenting customer-facing solutions. This is why the popularity of LLMs, and the RAG technique in particular has garnered so much attention in many organisations.
I hope this article has provided some insight into how these relatively new techniques can be utilised alongside more traditional tools and frameworks for developing user-facing applications.
Acknowledgements
I would like to thank The Diary of a CEO team, for their permission to use the transcripts of videos from this playlist in this project, and in the writing of this article.
All images, unless otherwise noted, are by the author.
Using LLMs to Learn From YouTube was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Using LLMs to Learn From YouTube