

Tracing the roots of ChatGPT: GPT-1, the foundation of OpenAI’s LLMs
The GPT (Generative Pre-Training) model family, first introduced by OpenAI in 2018, is another important application of the Transformer architecture. It has since evolved through versions like GPT-2, GPT-3, and InstructGPT, eventually leading to the development of OpenAI’s powerful LLMs.
In other words: understanding GPT models is essential for anyone looking to dive deeper into the world of LLMs.
This is the first part of our GPT series, in which we will try to walk through the core concepts in GPT-1 as well as the prior works that have inspired it.
Below are the topics we will cover in this article:
Prior to GPT-1:
- The Pre-training and Finetuning Paradigm: the journey from CV to NLP.
- Previous Work: Word2vec, GloVe, and other methods using LM for pretraining.
- Decoder-only Transformer.
- Auto-regressive vs. Auto-encoding Language Models.
Core concepts in GPT-1:
- Key Innovations.
- Pre-training.
- Finetuning.
Prior to GPT-1
Pre-training and Finetuning
The pretraining + finetuning paradigm, which firstly became popular in Computer Vision, refers to the process of training a model using two stages: pretraining and then finetuning.
In pretraining stage, the model is trained on a large-scale dataset that related to the downstream task at hand. In Computer Vision, this is done usually by learning an image classification model on ImageNet, with its most commonly used subset ILSVR containing 1K categories, each has 1K images.
Although 1M images doesn’t sound like “large-scale” by today’s standard, ILSVR was truly remarkable in a decade ago and was indeed much much larger than what we could have for specific CV tasks.
Also, the CV community has explored a lot of ways to get rid of supervised pre-training as well, for example MoCo (by Kaiming He et al.) and SimCLR (by Ting Chen et al.), etc.
After pre-training, the model is assumed to have learnt some general knowledge about the task, which could accelerate the learning process on the downstream task.
Then comes to finetuning: In this stage, the model will be trained on a specific downstream task with high-quality labeled data, often in much smaller scale compared to ImageNet. During this stage, the model will pick up some domain-specific knowledge related to the task at-hand, which helps improve its performance.
For a lot of CV tasks, this pretraining + finetuning paradigm demonstrates better performance compared to directly training the same model from scratch on the limited task-specific data, especially when the model is complex and hence more likely to overfit on limited training data. Combined with modern CNN networks such as ResNet, this leads to a performance leap in many CV benchmarks, where some of which even achieve near-human performance.
Therefore, a natural question arises: how can we replicate such success in NLP?
Previous Explorations of Pretraining Prior to GPT-1
In fact, the NLP community never stops trying in this direction, and some of the efforts can date back to as early as 2013, such as Word2Vec and GloVe (Global Vectors for Word Representation).
Word2Vec
The Word2Vec paper “Distributed Representations of Words and Phrases and their Compositionality” was honored with the “Test of Time” award at NeurIPS 2023. It’s really a must-read for anyone not familiar with this work.
Today it feels so natural to represent words or tokens as embedding vectors, but this wasn’t the case before Word2Vec. At that time, words were commonly represented by one-hot encoding or some count-based statistics such as TD-IDF (term frequency-inverse document frequency) or co-occurrence matrices.
For example in one-hot encoding, given a vocabulary of size N, each word in this vocabulary will be assigned an index i, and then it will be represented as a sparse vector of length N where only the i-th element is set to 1.
Take the following case as an example: in this toy vocabulary we only have four words: the (index 0), cat (index 1), sat (index 2) and on (index 3), and therefore each word will be represented as a sparse vector of length 4(the ->1000, cat -> 0100, sat -> 0010, on -> 0001).
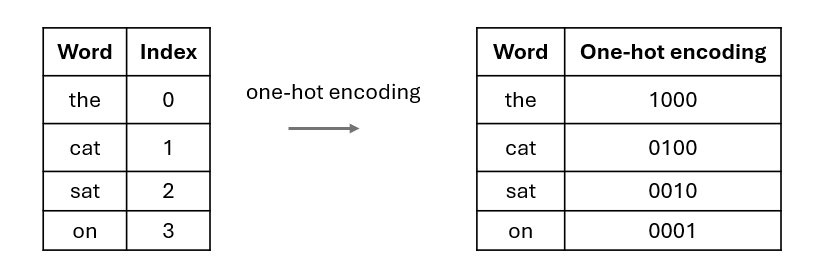
The problem with this simple method is that, as vocabulary grows larger and larger in real-world cases, the one-hot vectors will become extremely long. Also, neural networks are not designed to handle these sparse vectors efficiently.
Additionally, the semantic relationships between related words will be lost during this process as the index for each word is randomly assigned, meaning similar words have no connection in this representation.
With that, you can better understand the significance of Word2Vec’s contribution now: By representing words as continuous vectors in a high-dimensional space where words with similar contexts have similar vectors, it completely revolutionized the field of NLP.
With Word2Vec, related words will be mapped closer in the embedding space. For example, in the figure below the authors show the PCA projection of word embeddings for some countries and their corresponding capitals, with their relationships automatically captured by Word2Vec without any supervised information provided.
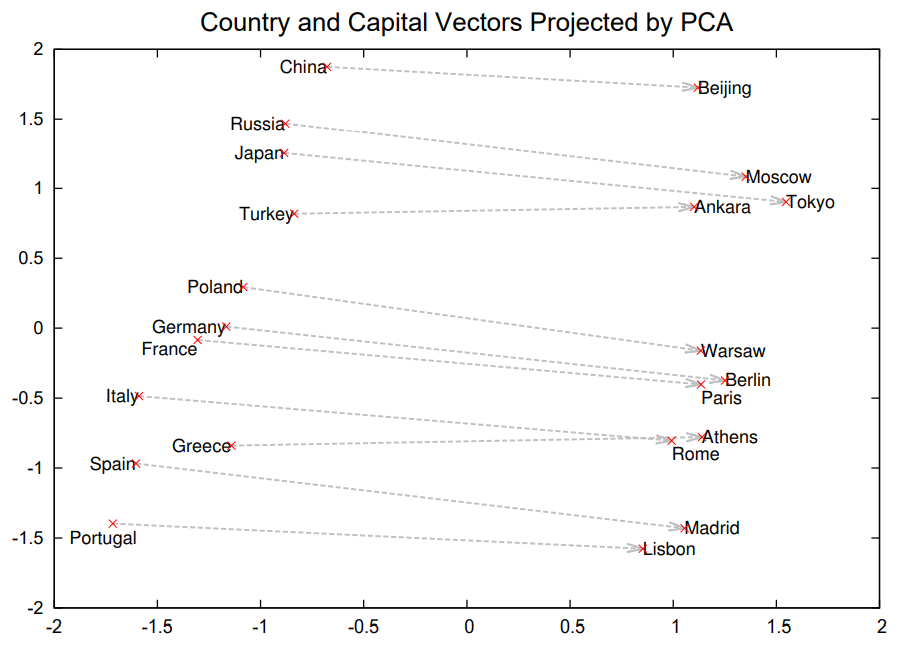
Word2Vec is learnt in an unsupervised manner, and once the embeddings are learnt, they can be easily used in downstream tasks. This is one of the earliest efforts exploring semi-supervised learning in NLP.
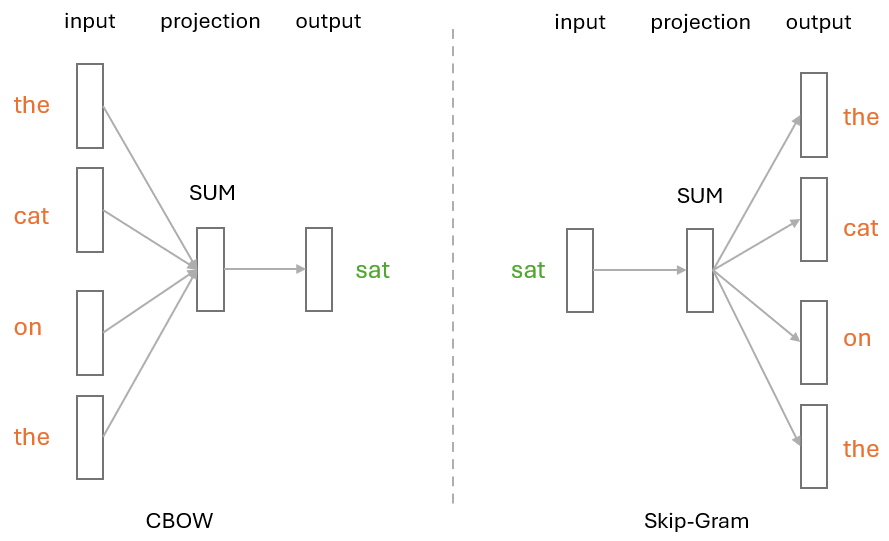
More specifically, it can leverage either the CBOW (Continuous Bag of Words) or Skip-Gram architectures to learn word embeddings.
In CBOW, the model tries to predict the target word based on its surrounding words. For example, given the sentence “The cat sat on the mat,” CBOW would try to predict the target word “sat” given the context words “The,” “cat,” “on,” “the.” This architecture is effective when the goal is to predict a single word from the context.
However, Skip-Gram works quite the opposite way — it uses a target word to predict its surrounding context words. Taking the same sentence as example, this time the target word “sat” becomes the input, and the model would try to predict context words like “The,” “cat,” “on,” and “the.” Skip-Gram is particularly useful for capturing rare words by leveraging the context in which they appear.
GloVe
Another work along this line of research is GloVe, which is also an unsupervised method to generate word embeddings. Unlike Word2Vec which focuses on a local context, GloVe is designed to capture global statistical information by constructing a word co-occurrence matrix and factorizing it to obtain dense word vectors.
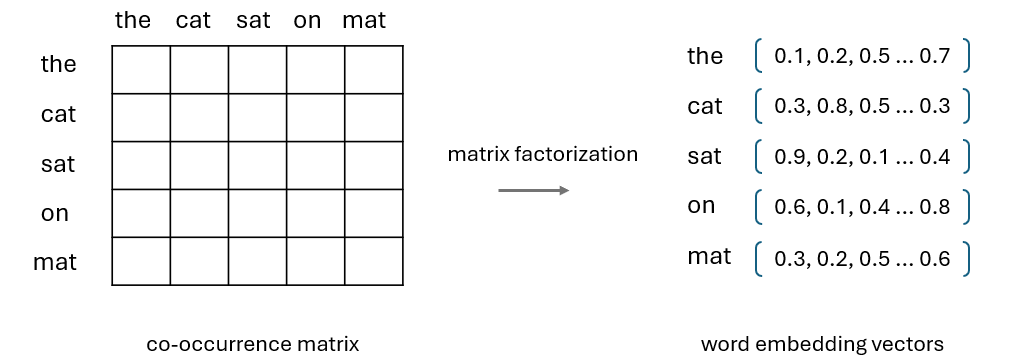
Note that both Word2Vec and GloVe can mainly transfer word-level information, which is often not sufficient in handling complex NLP tasks as we need to capture high-level semantics in the embeddings. This leads to more recent explorations on unsupervised pre-training of NLP models.
Unsupervised Pre-Training
Before GPT, many works have explored unsupervised pre-training with different objectives, such as language model, machine translation and discourse coherence, etc. However, each method only outperforms others on certain downstream tasks and it remained unclear what optimization objectives were most effective or most useful for transfer.
You may have noticed that language models had already been explored as training objectives in some of the earlier works, but why didn’t these methods succeed like GPT?
The answer is Transformer models.
When the earlier works were proposed, there is no Transformer models yet, so researchers could only rely on RNN models like LSTM for pre-training.
This brings us to the next topic: the Transformer architecture used in GPT.
Decoder-only Transformer
In GPT, the Transformer architecture is a modified version of the original Transformer called decoder-only Transformer. This is a simplified Transformer architecture proposed by Google in 2018, and it contains only the decoder.
Below is a comparison of the encoder-decoder architecture introduced in the original Transformer vs. the decoder-only Transformer architecture used in GPT. Basically, the decoder-only architecture removes the encoder part entirely along with the cross-attention, leading to a more simplified architecture.
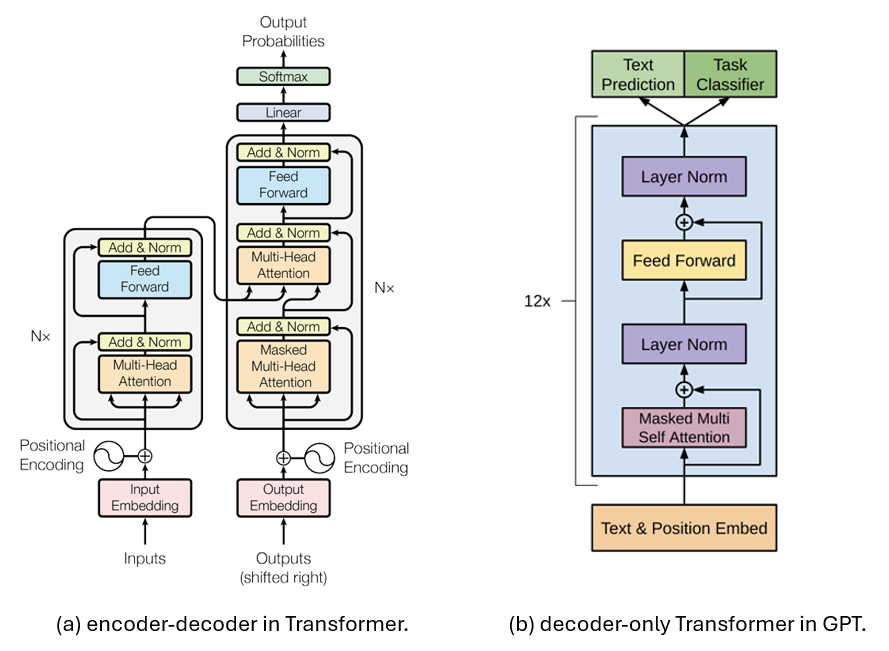
So what’s the benefit of making Transformer decoder-only?
Compared with encoder-only models such as BERT, decoder-only models often perform better in generating coherent and contextually relevant text, making them ideal for text generation tasks.
Encoder-only models like BERT, on the other hand, often perform better in tasks that require understanding the input data, like text classification, sentiment analysis, and named entity recognition, etc.
There is another type of models that employ both the encoder and decoder Transformer, such as T5 and BART, with the encoder processes the input, while the decoder generates the output based on the encoded representation. While such a design makes them more versatile in handling a wide range of tasks, they are often more computationally intensive than encoder-only or decoder-only models.
In a nutshell, while both built on Transformer models and tried to leverage pre-training + finetuning scheme, GPT and BERT have chosen very different ways to achieve that similar goal. More specifically, GPT conducts pre-training in an auto-regressive manner, while BERT follows an auto-encoding approach.
Auto-regressive vs. Auto-encoding Language Models
An easy way to understand their difference is to compare their training objectives.
In Auto-regressive language models, the training objective is often to predict the next token in the sequence, based on previous tokens. Due to the dependency on previous tokens, this usually lead to a unidirectional (typically left-to-right) approach, as we show in the left of Figure 6.
By contrast, auto-encoding language models are often trained with objectives like Masked Language Model or reconstructing the entire input from corrupted versions. This is often done in a bi-directional manner where the model can leverage all the tokens around the masked one, in other words, both the left and right side tokens. This is illustrated in the right of Figure 6.
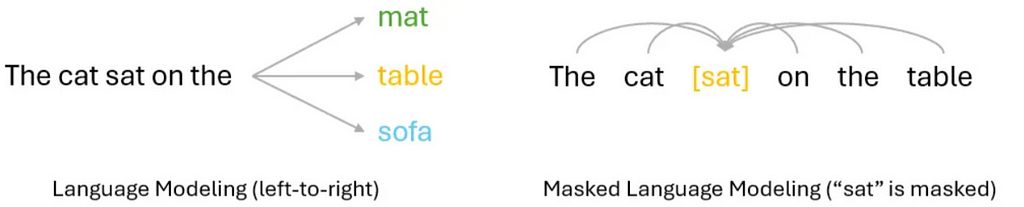
Simply put, auto-regressive LM is more suitable for text generation, but its unidirectional modeling approach may limit its capability in understanding the full context. Auto-encoding LM, on the other hand, can do a better job at context understanding, but is not designed for generative tasks.
Core Concepts in GPT-1
Key Innovations
Most of the key innovations of GPT-1 have already been covered in above sections, so I will just list them here as a brief summary:
- GPT-1 is the first work that successfully leverages auto-regressive language modeling as unsupervised pre-training task, making the pre-training + finetuning paradigm a standard procedure for NLP tasks.
- Unlike its prior works that rely on RNNs and LSTMs, GPT-1 leverages decoder-only Transformer architecture, which improved parallelization and long-range dependency handling, leading to better performance.
Unsupervised Pre-training
In GPT pre-training, a standard language modeling objective is used:
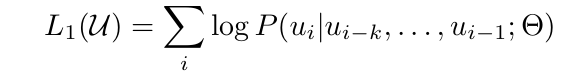
where k is the size of the context window, and the conditional probability P is modeled using the decoder-only Transformer with it parameters represented as θ.
Supervised Finetuning
Once the model is pre-trained, it can be adapted to a specific downstream task by finetuning on a task-specific dataset using a proper supervised learning objective.
One problem here is that GPT requires a continuous sequence of text as input, while some tasks may involve more than one input sequence. For example in Entailment we have both the premise and the hypothesis, and in some QA tasks we will need to handle three different input sequences: the document, the question and the answer.
To make it easier to fit into different tasks, GPT adopts some task-specific input transformations in the finetuning stage, as we show in the figure below:
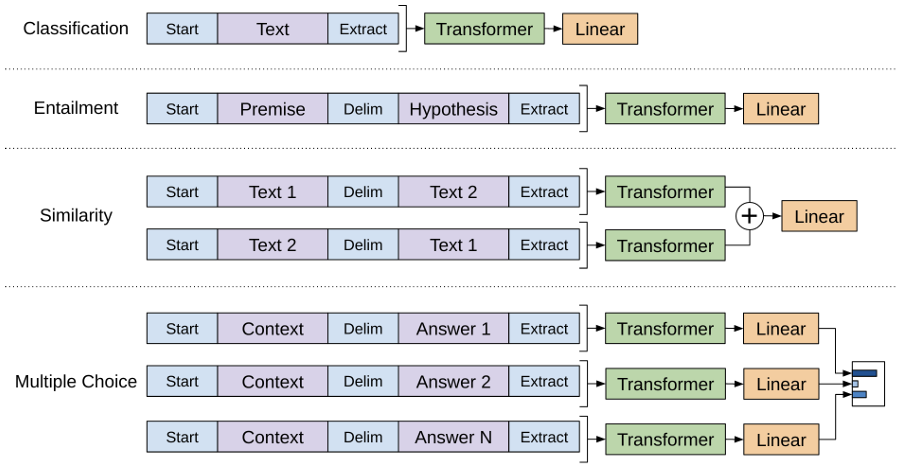
More specifically,
- For Entailment task, the premise and hypothesis sequences will be concatenated into a single sequence, with a delimiter token in between.
- For Similarity task, since there is no inherent ordering of the sentences, we can simply construct two input sequences by switching the two input sequences, get their respective embeddings and then add these two embeddings in a element-wise manner.
- For more complex Question Answering and Commonsense Reasoning tasks, where we are typically given a context document, a question and a set of possible answers, we can concatenate the document context and the question with each possible answer (again with a delimiter token in between), process each of these sequence independently, and then use a softmax layer to produce the final output distribution over possible answers.
Conclusions
In this article, we revisited the key techniques that inspired GPT-1 and highlighted its major innovations.
This is the first part of our GPT series, and in the next article, we will walk through the evolution from GPT-1 to GPT-2, GPT-3, and InstructGPT.
Thanks for reading!
Understanding the Evolution of ChatGPT: Part 1—An In-Depth Look at GPT-1 and What Inspired It was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Understanding the Evolution of ChatGPT: Part 1—An In-Depth Look at GPT-1 and What Inspired It