Dive into model pre-training, fine-tuning, RAG, prompt engineering, and more!

Introduction
Generative AI adoption is rapidly increasing for both individuals and businesses. A recent Gartner study found that GenAI solutions are the number one AI solution used by organizations, with most companies leveraging GenAI features built into existing tools like Microsoft 365 Copilot. In my experience, most businesses are looking for some sort of “private ChatGPT” they can use to get more value from their unique organizational data. Company goals vary from finding information in particular documents, generating reports based on tabular data, and summarizing content, to finding all the projects related to some domain, and much more.
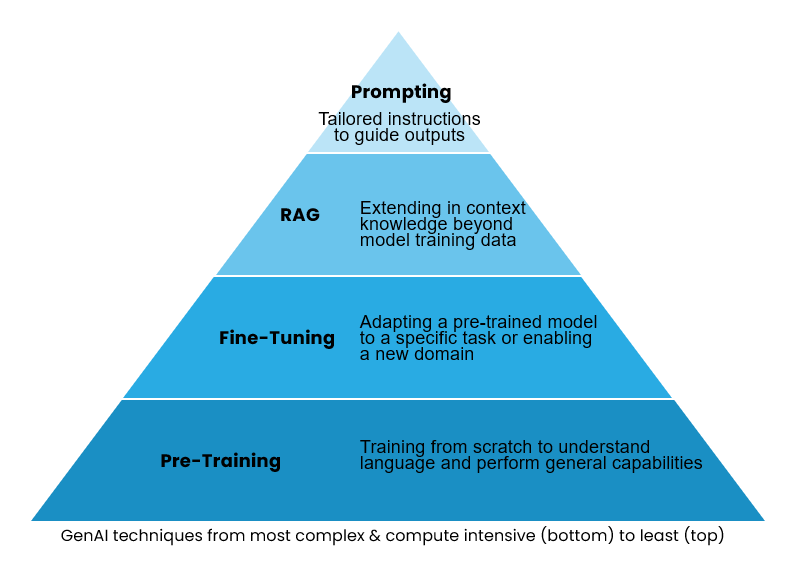
This article explores various approaches to solve these problems, outlining the pros, cons, and applications of each. My goal is to provide guidance on when to consider different approaches and how to combine them for the best outcomes, covering everything from the most complex and expensive approaches like pre-training to the simplest, most cost-effective techniques like prompt engineering.
The sequence of the article is intended to build from the foundational concepts for model training (pre-training, continued pre-training, and fine tuning) to the more commonly understood techniques (RAG and prompt engineering) for interacting with existing models.
Background
There is no one-size fits all approach to tackling GenAI problems. Most use cases require a combination of techniques to achieve successful outcomes. Typically, organizations start with a model like GPT-4, Llama3 70b Instruct, or DBRX Instruct which have been pretrained on trillions of tokens to perform next token prediction, then fine-tuned for a particular task, like instruction or chat. Instruction based models are trained and optimized to follow specific directions given in the prompt while chat based models are trained and optimized to handle conversational formats over multiple turns, maintaining context and coherence throughout the conversation.
Using existing models allows organizations to take advantage of the significant time and financial investments made by companies like OpenAI, Meta, and Databricks to curate datasets, create innovative architectures, and train and evaluate their models.
Although not every company will need to pre-train or instruction fine-tune their models, anyone using a Large Language Model (LLM) benefits from the groundwork laid by these industry leaders. This foundation allows other companies to address their unique challenges without starting from scratch.
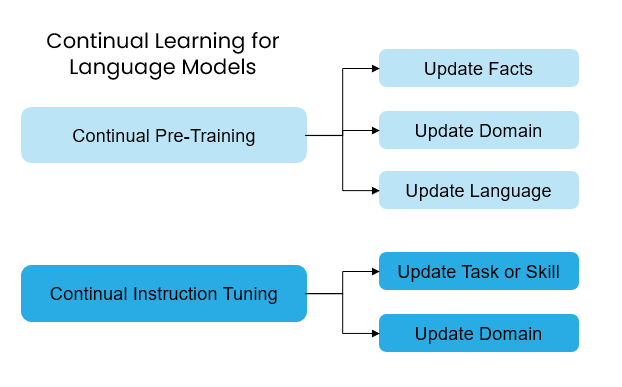
In the following sections, we’ll explore pre-training, fine-tuning (both instruction fine-tuning, and continued pre-training), Retrieval Augmented Generation (RAG), fine-tuning embeddings for RAG, and prompt engineering, discussing how and when each of these approaches should be used or considered.
Setting the Baseline with Pre-Training
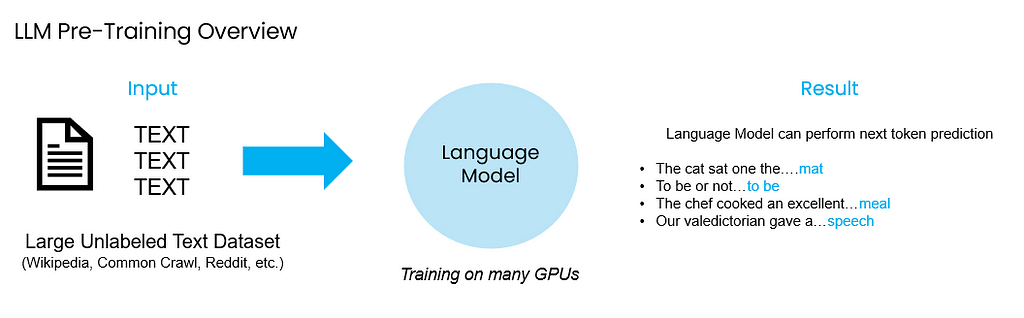
Overview: Pre-Training a model creates a foundation which will be used as a base for all downstream tasks. This process includes defining the architecture for the model, curating a massive dataset (generally trillions of tokens), training the model, and evaluating its performance. In the context of LLMs and SLMs, the pre-training phase is used to inject knowledge into the model, enabling it to predict the next word or token in a sequence. For instance, in the sentence “the cat sat on the ___”, the model learns to predict “mat”.
Companies like OpenAI have invested heavily in the pre-training phase for their GPT models, but since models like GPT-3.5, GPT-4, and GPT-4o are closed source it is not possible to use the underlying architecture and pre-train the model on a different dataset with different parameters. However, with resources like Mosaic AI’s pre-training API it is possible to pre-train open source models like DBRX.
Pros:
- Complete control: The benefit of pre-training a model is that you’d have complete control over the entire process to create the model. You can tailor the architecture, dataset, and training parameters to your needs and test it with evaluations representative of your domain instead of a focusing primarily on common benchmarks.
- Inherent domain specific knowledge: By curating a dataset focused on a particular domain, the model can develop a deeper understanding of that domain compared to a general purpose model.
Cons:
- Most expensive option: Pre-training requires an extreme amount of computational power (many, many GPUs) which means the cost of pre-training is typically in the millions to tens or hundreds of millions of dollars and often takes weeks to complete the training.
- Knowledge cutoffs: The final model is also completed at a certain point in time, so it will have no inherent understanding of real time information unless augmented by techniques like RAG or function-calling.
- Advanced requirements: This approach requires the most data and the most advanced expertise to achieve meaningful results.
Applications: Generally, pre-training your own model is only necessary if none of the other approaches are sufficient for your use case. For example, if you wanted to train a model to understand a new language it has no previous exposure to, you may consider pre-training it then fine-tuning it for your intended use.
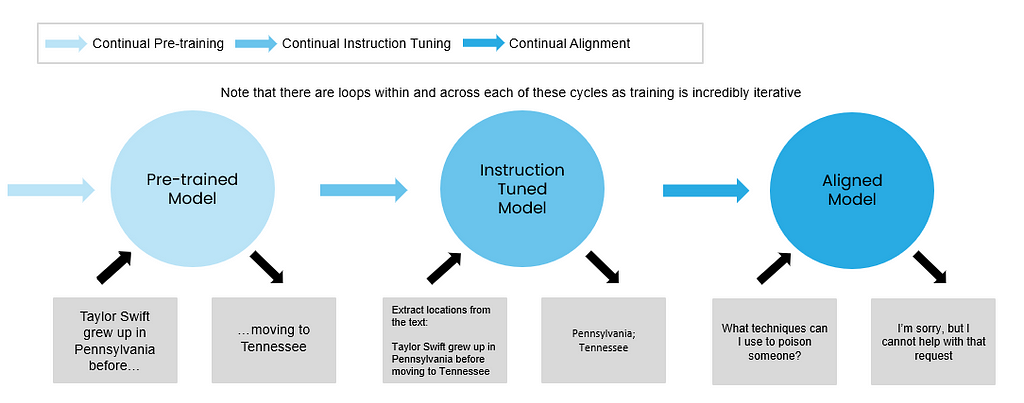
Once the base training is complete, the models typically need to be fine-tuned so that they can perform tasks effectively. When you see a model labeled as a chat or instruct model, that indicates the base model has been fine-tuned for either of those purposes. Nearly any model you interact with today has been fine-tuned for one of these purposes so that end users can interact with the model efficiently.
Given the incredible cost and intensive process required to pre-train a model, most organizations decide to leverage existing models in their GenAI use cases. To get started with pretraining, check out Mosaic AI’s pretraining API, this allows you to pretrain a Databricks DBRX model with different parameter sizes.
Adding Knowledge with Continued Pre-Training (CPT)
Overview: CPT is a type of fine-tuning that allows extends the knowledge of an existing model rather than training the entire model from scratch. The output of a model that’s gone through CPT will still predict the next token. In general it’s recommended that you use CPT then Instruction Fine-Tuning (IFT) this way you can extend the model’s knowledge first, then tune it to a particular task like following instructions or chat. If done in the reverse order, the model may forget instructions that it learned during the IFT phase.
Pros:
- No need for labeled training data: CPT does not require labeled training data. This is great if you have a lot of domain-specific or new information you want to teach the model in general. Since the output is still focused on next token prediction, the output from CPT is helpful if you want a text-completion model.
- Faster and more cost effective than pre-training: CPT can be completed in hours or days using less GPUs than pre-training making it faster and cheaper!
Cons:
- Still comparatively expensive: CPT is significantly cheaper than pre-training, but can still be expensive and cost tens of thousands of dollars to train a model depending on the volume of data and number of GPUs required.
- Requires curated evaluations: Additionally, you will need to create your own evaluations to make sure the model is performing well in the new domain you are teaching it.
- Typically requires subsequent IFT: For most use cases, you would still need to perform IFT on the model once CPT finishes so that the final model can properly respond to questions or chats. This ultimately increases the time and cost until you have a model ready for use.
Applications: For industries with highly domain specific content like healthcare or legal, CPT may be a great option for introducing new topics to the model. With tools like Mosaic AI’s Fine-Tuning API you can easily get started with CPT, all you need is a series of text files you want to use for training. For the CPT process, all the text files will be concatenated with a separation token between each of the documents, Mosaic handles the complexity behind the scenes for how these files get fed to the model for training.
As an example, let’s say we used CPT with a series of text files about responsible AI and AI policies. If I prompt the model to “Tell me three principles important to Responsible AI”, I would likely get a response with a high probability to follow the sentence I prompted like “I need to understand the key Responsible AI principles so I can train an effective model”. Although this response is related to my prompt, it does not directly answer the question. This demonstrates the need for IFT to refine the models instruction following capabilities.
Tailoring Responses with Instruction Fine-Tuning (IFT)
Overview: IFT is used to teach a model how to perform a particular task. It typically requires thousands of examples and can be used for a specific purpose such as improving question answering, extracting key information, or adopting a certain tone.
Pros:
- Speed and cost-effectiveness: IFT takes significantly less time to complete, this type of training can be achieved in minutes making it not only faster, but much cheaper compared to pre-training or CPT.
- Task-specific customization: This is a great method to get tailored results out of the model by guiding it to respond in a particular tone, classify documents, revise certain documents, and more.
Cons:
- Requires labeled dataset: IFT needs labeled data to teach the model how it should behave. While there are many open-source datasets available, it may take time to properly create and label a dataset for your unique use case.
- Potential decrease in general capabilities: Introducing new skills through IFT may reduce the model’s performance on general tasks. If you are concerned about maintaining the model’s ability to generalize, you may want to include examples of general skills in your training and evaluation set this way you can measure performance on the general tasks as well as the new skill(s) you are teaching.
Applications: IFT helps the model perform particular tasks like question answering much better. Using the prompt “Tell me three principles important to Responsible AI”, a model that had undergone IFT would likely respond with an answer to the question like “Responsible AI is critical for ensuring the ethical use of models grounded in core principles like transparency, fairness, and privacy. Following responsible AI principles helps align the solution with broader societal values and ethical standards”. This response is more useful to the end user compared to a response that may come from a CPT or PT model only since it addresses the question directly.
Note that there are a variety of fine-tuning approaches and techniques designed to improve the overall model performance and reduce both time and cost associated with training.
Finding real-time or private information with Retrieval Augmented Generation (RAG)
Overview: RAG enables language models to answer questions using information outside of their training data. In the RAG process, a user query triggers a retrieval of relevant information from a vector index, which is then integrated into a new prompt along with the original query to generate a response. This technique is one of the most common techniques used today due to its effectiveness and simplicity.
Pros:
- Access to real-time information & information beyond training data: RAG allows models to utilize query information from diverse and constantly updated sources like the internet or internal document datastores. Anything that can be stored in a vector index or retrieved via a plugin/tool, can be used in the RAG process.
- Ease of implementation: RAG does not require custom training making it both cost-effective and straightforward to get started. It’s also a very well documented and researched area with many articles providing insights on how to improve responses from RAG systems.
- Traceability and citations: All generated responses can include citations for which documents were used to answer the query making it easy for the user to verify the information and understand how the response was generated. Since you know exactly what information got sent to the model to answer the question, it’s easy to provide a traceable answers to the end user, and if needed the end user can look at the referenced documents for more information. In comparison, if you are querying a model directly, it’s difficult to know how it answered that question or what references were used to generate the response.
Cons:
- Context window limitations: The first major problem is the context windows of different models, some models like GPT-4 and 4o have 128k token context window, while the Llama-3 series is still only 8k tokens. With smaller context windows, you cannot pass as much information to the model to answer the question. As a result, it becomes more important to have robust chunking and chunk re-ranking techniques in place so you can retreive the right context and use this to respond to the user correctly.
- The “Lost in the Middle Problem”: Even with longer context windows, there is a common “lost in the middle problem” where models tend to pay more attention to information at the beginning or end of the prompt, meaning that if the answer to the question lies in the middle of the context, the model may still answer incorrectly even when presented with all the information needed to answer the question. Similarly, the models might mix up information they’ve retrieved and answer the question only partially correct. For example, I’ve seen when asking a model to find information about two companies and return their point of view on AI, the model has on occasion mixed up the companies policies.
- Top K Retrieval Challenge: In typical RAG pipelines, only the top K documents (or chunks of text) related to the query are retrieved and sent to the model for a final response. This pattern yields better results when looking for specific details in a document corpus, but often fails to correctly answer exhaustive search based questions. For example, the prompt “give me all of the documents related to responsible AI” would need additional logic to keep searching through the vector index for all responsible AI documents instead of stopping after returning the first top K related chunks.
- Overly similar documents: If the vector index contains documents that are all semantically similar, it might be difficult for the model to retrieve the exact document relevant to the task. This is particularly true in specialized domains or domains with uniform language. This may not be a problem in a vector index where the content of all the documents is diverse, however, if you’re using RAG against an index on medical documents where all the language is very similar and not something a typical embedding model would be trained on, it might be harder to find the documents / answers you’re looking for.
Applications: Any use case involving question and answering over a set of documents will typically involve RAG. It’s a very practical way to get started with Generative AI and requires no additional model training. The emerging concept of AI Agents also tend to have at least one tool for RAG. Many agent implementations will have RAG based tools for different data sources. For example, an internal support agent might have access to an HR tool and IT support tool. In this set-up there could be a RAG component for both the HR and IT documents, each tool could have the same pipeline running behind the scenes, the only difference would be the document dataset.
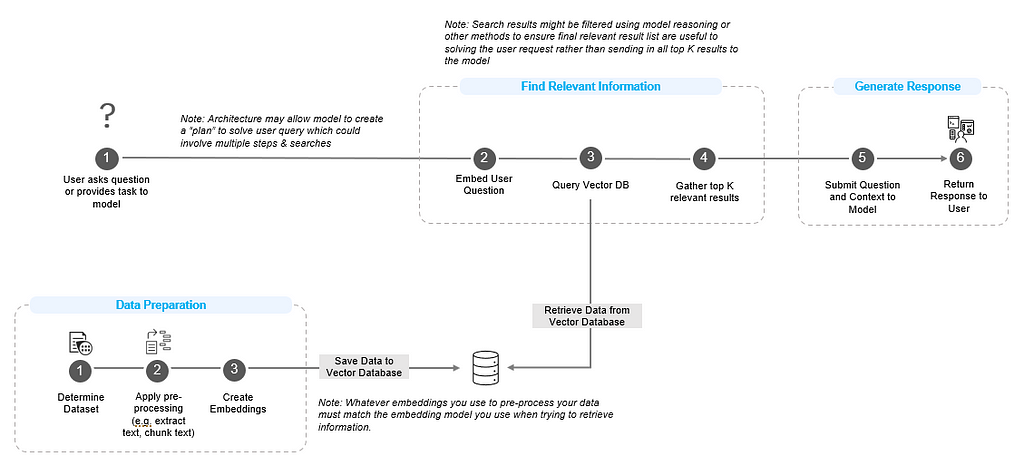
Improving the R in RAG by Fine-Tunning Embeddings
Overview: Fine-Tuning Embeddings can improve the retrieval component of RAG. The goal of fine-tuning embeddings is to push the vector embeddings further apart in the vector space, making them more different from one another and therefore easier to find the documents most relevant to the question.
Pros:
- Generally cost-effective: Fine-tuning embeddings is comparatively inexpensive when considering other training methods.
- Domain-specific customization: This method can be a great option for distinguishing text in domains that the underlying embedding model was not as exposed to during training. For example, highly specific legal or health care documents may benefit from fine-tuning embeddings for those corpuses in their RAG pipeline.
Cons:
- Requires labeled data & often re-training: A labeled dataset is needed to fine-tune an embedding model. Additionally, you may need to continuously re-train the embedding model as you add additional information to your index.
- Additional maintenance across indexes: Depending on how many data sources you’re querying you also might have to keep track of multiple sets of embedding models and their related data sources. It’s important to remember that whatever embedding model was used to embed the corpus of documents must be the same model used to embed the query when it’s time to retrieve relevant information. If you are querying against multiple indexes, each embedded using a different embedding model, then you’ll need to make sure that your models match at the time of retrieval.
Applications: Fine-tuning embeddings is a great option if the traditional RAG approach is not effective because the documents in your index are too similar to one another. By fine-tuning the embeddings you can teach the model to differentiate better between domain specific concepts and improve your RAG results.
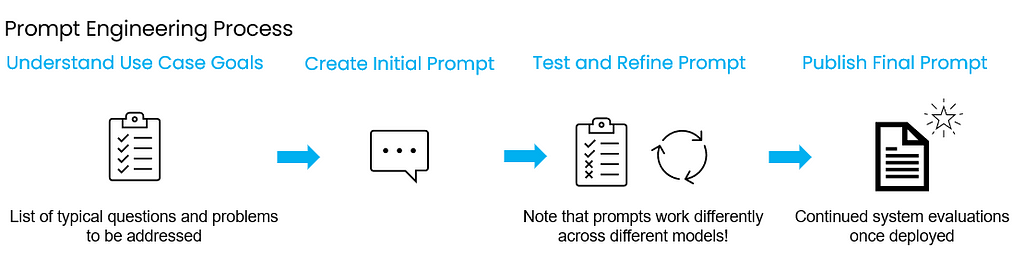
Talking to Models with Prompt Engineering
Overview: Prompt engineering is the most common way to interact with Generative AI models, it is merely sending a message to the model that’s designed to get the output you want. It can be as simple as “Tell me a story about a German Shepherd” or it can be incredibly complicated with particular details regarding what you’d like the model to do.
Pros:
- Immediate results: Experimenting with different prompts can be done anytime you have access to a language model and results are returned in seconds (or less)! As soon as the idea hits, you can begin working on refining a prompt until the model gives the desired response.
- High performance on general tasks: Prompt engineering alone works great for generic tasks that do not require any retrieval of business specific information or real-time information.
- Compatibility with other techniques: It will work with models that have been pre-trained, continuously pre-trained, or fine-tuned, and it can be used in conjunction with RAG making it the most used and versatile of the approaches.
Cons:
- Limited capability on its own: Prompt engineering alone is typically not enough to get the model to perform how you want. In most cases, people want the model to interact with some external data whether it’s a document database, API call, or SQL table, all of which will need to combine prompt engineering with RAG or other specialized tool calling.
- Precision challenges: Writing the perfect prompt can be challenging and often requires a lot of tweaking until the model performs as intended. The prompt that works great with one model might fail miserably with another, requiring lots of iterations and experimentation across many models and prompt variations.
Applications: Prompt Engineering will be used in combination with all of the aforementioned techniques to produce the intended response. There are many different techniques for prompt engineering to help steer the model in the right direction. For more information on these techniques I recommend this Prompt Engineering Guide from Microsoft they give a variety of examples from Chain-of-Thought prompting and beyond.
Conclusion
Generative AI technology is changing and improving everyday. Most applications will require leveraging a variety of the techniques described in this article. Getting started with existing language models that have been fine-tuned for instruction or chat capabilities and focusing on prompt engineering and RAG is a great place to start! From here finding more tailored use cases that require fine-tuning/instruction fine-tuning can provide even greater benefits.
Looking ahead, AI agents offer a promising way to take advantage of the latest advancements in both closed and open-source models that have been pre-trained on tons of public data and fine-tuned for chat/instruction following. When given the right tools, these agents can perform incredible tasks on your behalf from information retrieval with RAG to helping plan company events or vacations.
Additionally, we can expect to see a proliferation of more domain specific models as organizations with lots of specialized data begin pre-training their own models. For instance, companies like Harvey are already developing tailored AI solutions that can handle the unique demands of the legal industry. This trend will likely continue, leading to highly specialized models that deliver even more precise and relevant results in various fields.
By combining the strengths of different AI techniques and leveraging the power of AI agents and domain-specific models, organizations can unlock the full potential of Generative AI.
Additional References
- Gartner Survey Finds Generative AI Is Now the Most Frequently Deployed AI Solution in Organizations
- Instruction Tuning for Large Language Models: A Survey
- Continual Pre-Training of Large Language Models: How to (re)warm your model?
- Continual Learning for Large Language Models: A Survey
- Lost in the Middle: How Language Models Use Long Contexts
- Mosaic AI Fine-Tuning Documentation
- Prompt Engineering Guide / Recording from Microsoft
- Prompt Engineering Guide from Anthropic
- What is the Cost of Training Large Language Models from Cudo Compute
Interested in discussing further or collaborating? Reach out on LinkedIn!
Understanding Techniques for Solving GenAI Challenges was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Understanding Techniques for Solving GenAI Challenges
Go Here to Read this Fast! Understanding Techniques for Solving GenAI Challenges