
Deciphering SQL Query Performance: A Practical Analysis in Data Warehousing and Database Management Systems

Unlike Python and other imperative programming languages, which require the explicit detailing of algorithms in a step-by-step manner to optimize, SQL is a declarative programming language that focuses not on the sequence of operations, but rather on expressing the logic of what you want to achieve. How a query is executed in the database depends on the database system itself, particularly on a component called the query planner (or optimizer) which decides the best way to execute the query. That’s why an almost identical query can be executed very differently in data warehouses compared to traditional DBMSs.
For most data workers, it’s usually not so important to be concerned about the difference, as long as the query is able to retrieve the correct data. However, this changes when creating interactive dashboards or machine learning pipelines. In these cases, frequently run queries can significantly impact query efficiency and cost. Well-designed queries can save users time in loading data and metrics, and can also save the company thousands of dollars on BigQuery or Snowflake bills.
Today, we will focus on a common use case: comparing multiple query syntaxes and databases. We’ll see and understand the differences between how these databases approach retrieving and calculating data.
Here’s a common question: Finding out active doctors last year? Suppose there is a ‘doctors’ table that records doctors’ information, and a ‘patient admissions’ table that records instances of patients being admitted by doctors. The goal is to filter out those doctors who had at least one patient admission in the last year (this could be a dynamic time period in machine learning pipelines or interactive dashboards).
Practically, there’s three common ways to write this query: EXIST, IN, and JOIN. We will analyze them and run experiments on Bigquery and PostgreSQL, to validate our analysis.
First approach: IN
For Python users, the IN operator might be the most intuitive approach. This involves first filtering out the admission records from the last year, and then checking if the doctors are listed in those records. We’ll also test out whether adding a DISTINCT will increase performance.
SELECT d.*
FROM `tool-for-analyst.richard_workspace.doctors` d
WHERE d.doctor_id IN (
SELECT doctor_id
FROM `tool-for-analyst.richard_workspace.patient_admissions` admissions
WHERE admissions.Admission_Date BETWEEN '2023–01–01' AND '2023–12–31'
);
Second approach EXISTS:
Another approach involves using the EXISTS operator, which filters the results to include only those for which the subquery returns at least one record. EXISTS operates on the concept of a ‘Semi JOIN,’ meaning that it doesn’t actually perform a join on the right-hand side; instead, it merely checks if a join would yield results for any given tuple. When it finds one it stops. This could offer some performance advantages.
SELECT d.*
FROM `tool-for-analyst.richard_workspace.doctors` d
WHERE EXISTS (
SELECT 1
FROM `tool-for-analyst.richard_workspace.patient_admissions` pa
WHERE pa.doctor_id = d.doctor_id
AND pa.Admission_Date BETWEEN '2023–01–01' AND '2023–12–31'
)
Third approach:
The third approach involves using JOIN, which is the most classic method in relational database philosophy. There are some frequent disputes in forums about when to filter and whether to use a subquery or a Common Table Expression (CTE). We have included these considerations in our experiment as well.
JOIN after filter in subquery
SELECT d.doctor_id, name, Hospital, Age, Gender
FROM `tool-for-analyst.richard_workspace.doctors` d
INNER JOIN (
SELECT DISTINCT doctor_id
FROM `tool-for-analyst.richard_workspace.patient_admissions`
WHERE Admission_Date BETWEEN '2023–01–01' AND '2023–12–31'
) admissions
ON d.doctor_id = admissions.doctor_id;
Filter and GROUP BY after JOIN
SELECT d.doctor_id, d.name, d.Hospital, d.Age, d.Gender
FROM `tool-for-analyst.richard_workspace.doctors` d
INNER JOIN `tool-for-analyst.richard_workspace.patient_admissions` pa
ON d.doctor_id = pa.doctor_id
WHERE pa.Admission_Date BETWEEN '2023–01–01' AND '2023–12–31'
GROUP BY d.doctor_id, d.name, d.Hospital, d.Age, d.Gender;
CTE filter before JOIN
WITH filtered_admissions AS(
SELECT DISTINCT doctor_id
FROM `tool-for-analyst.richard_workspace.patient_admissions` admissions
WHERE admissions.Admission_Date
BETWEEN '2023–01–01' AND '2023–12–31'
)
SELECT d.*
FROM `tool-for-analyst.richard_workspace.doctors` d
JOIN filtered_admissions
ON d.doctor_id = filtered_admissions.doctor_id;
Now we have six queries to test. They all get the same result from the database but have slight differences in logic or syntax.
Q1: IN
Q2: IN with DISTINCT in subquery
Q3: EXISTS
Q4: JOIN with a subquery that filters the time range
Q5: JOIN before any filter, then use GROUP BY to deduplicate
Q6: JOIN with a CTE that filters the time range
Experiment result:

We executed each query 10 times in a generated test dataset, shifting the time range by 1 day for each test. By using BigQuery execution details and the EXPLAIN ANALYZE command in PostgreSQL, we obtained detailed information on execution times and plans. The test results are clear. If this is for a real-world use case, we can simply select the best-performing option and move on. However, in this blog, we will dig a bit deeper and ask: Why?
Dig into Planner:
The answer could be found in the execution plan, which reveals the true approach the database engine is calculating the query.
Bigquery:
The execution plans for Q1 ‘IN’ and Q3 ‘EXISTS’ are exactly the same. The two-step execution first filtered in the subquery, then used a SEMI JOIN to identify doctors with at least one patient admission. This was a perfect example of what we mentioned earlier: SQL is a declarative language that describes what you need, and BigQuery figures out how to execute it. Even if the SQL logic differed in its approach to the problem, BigQuery recognized that they required the same result and decided to use the same execution approach to optimize them.
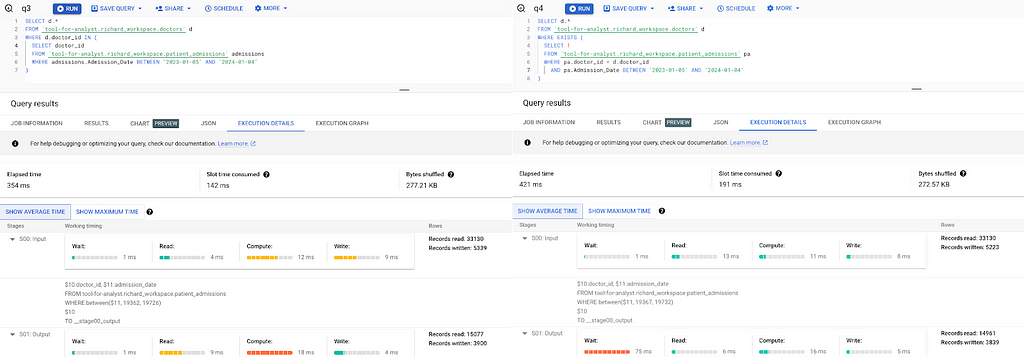
Adding DISTINCT in the IN subquery resulted in a much worse performance. It was quite interesting to observe that adding a single DISTINCT could have such a significant impact on the query running speed. When we looked into the query execution plan, we could see that a single DISTINCT causes two additional steps in the query execution. This led to more temporary tables being saved in the process, resulting in a significantly slower execution time.
Among the three JOIN methods, it was surprising that Q5 ‘JOIN before filter’ demonstrates the best performance, while the two other approaches trying to optimize filter and JOIN sequence, Q4 ‘JOIN with subquery’ and Q6 ‘JOIN with CTE’, exhibit poor performance. Upon examining the planner, it appeared that BigQuery actually recognized that executing the filter before the JOIN can optimize efficiency. However, when we tried to manually control the sequence by forcing the filter to occur before the JOIN, it resulted in more steps in the execution plan and significantly slower execution times. Interestingly, the subquery and the CTE approaches had the exact same execution plan, which is also very similar to the Q2 ‘IN with DISTINCT’ plan. The only difference was that in the final step, it used an INNER JOIN instead of a SEMI JOIN.
PostgreSQL:
Regarding Postgres, the difference in query time among the six queries we analyzed was relatively minor. This could be because the testing dataset was not large enough to significantly highlight the differences. As the dataset increases in size, the performance differences between the approaches are likely to become more substantial.
Our analysis was based on results from ‘EXPLAIN ANALYZE.’ This tool is invaluable for understanding the performance characteristics of a PostgreSQL query. ‘EXPLAIN’ provides the execution plan that the PostgreSQL query planner generates for a given statement, while the ‘ANALYZE’ option actually executes the statement, allowing for a more accurate assessment of performance.
Q1 ‘IN’ and Q3 ‘EXISTS’ had the same execution plan with the lowest cost. Similar to BigQuery, PostgreSQL also recognized that the two queries required the same data and optimized for them.
Q2, Q4, and Q6 all have the exact same execution plan with a slightly higher cost. Despite the queries are different in logic or syntax, the Postgres planner decided to run the same execution: Filter -> Group by(DISTINCT) -> JOIN,
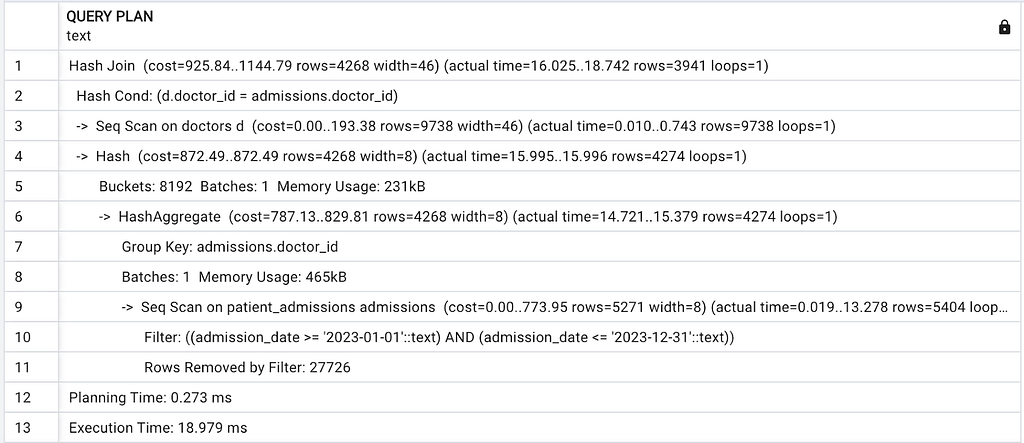
Q5 ‘JOIN before filter’ had the highest-cost execution plan. Although the PostgreSQL planner still managed to apply the filter before the JOIN, the deduplication process was applied to the larger table, resulting in a higher cost.
Conclusion:
In our experiment, approaches such as forcing a filter before a JOIN or adding the DISTINCT option for the IN operator did not increase our query performance; instead, they made it slower. Comparing BigQuery to Postgres, it’s evident that they each have their own niches and strengths. Their planners are also optimized for different goals using different approaches.
That’s being said, optimizing efficiency in a declarative language like SQL is not solely determined by your query. Equally important is how the database engine interprets, plans, and executes it. This process can greatly depend on the database’s design, as well as the structure and indexing of your data.
The experiment we conducted for the blog is specific to certain use cases and datasets. The most effective way to understand performance is to run your own queries, examine the query execution plan, and see what it’s going to do. Do Not to over-optimize based on theoretical assumptions. Practical testing and observation should always be your guiding principles in query optimization.
Understand Data Warehouse: Query Performance was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Understand Data Warehouse: Query Performance
Go Here to Read this Fast! Understand Data Warehouse: Query Performance



