Towards AGI: LLMs and Foundational Models’ Roles in the Lifelong Learning Revolution

Integrating Innovations in Continual Learning Advancements Towards Artificial General Intelligence (AGI), Including VOYAGER, DEPS, and AutoGPT.
Authors: Elahe Aghapour, Salar Rahili
Introduction:
In the past decade and especially with the success of deep learning, an ongoing discussion has formed around the possibility of building an Artificial General Intelligence (AGI). The ultimate goal in AGI is to create an agent that is able to perform any task that a human being is capable of. A core capability required for such an agent is to be able to continuously learn new skills and use its learned skills to learn more complicated skills faster. These skills must be broken up into sub-tasks, where the agent interacts with the environment, learning from its failures until success. And upon learning a new skill, the agent should integrate the skill into its existing repertoire of acquired skills for the future. Large language models (LLM) have shown that they have a good understanding of the world and how different tasks can be accomplished. There has been a series of interesting articles published in the past few years with the goal of using an LLM as the core decision maker for continual learning. These works have mostly chosen similar testing environments such as Crafter or Minecraft, since it can simulate the ultimate AGI goal of survival and thrival.
To explore the latest advancements in this field, we first outline the collaborative functioning of various building blocks that facilitate the learning process. Subsequently, we dive into the specifics of each component, comparing their implementation and functionality across different research articles.
Overview:
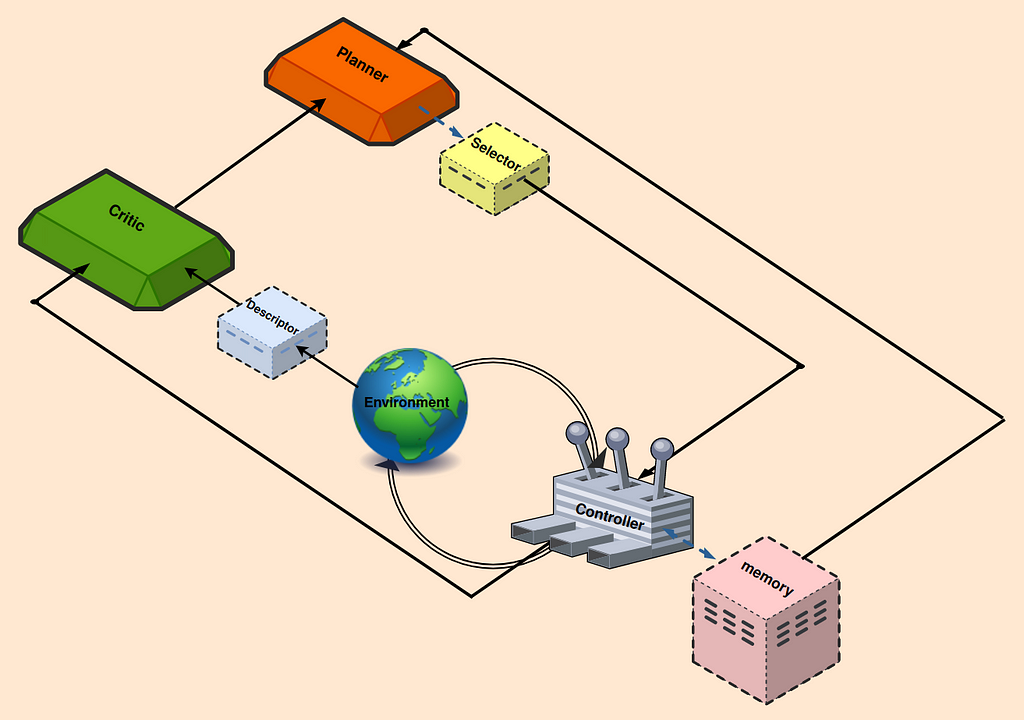
To develop the iterative and continuous process of learning/accomplishing tasks, many recommended frameworks adopt a recognizable process. Those with a background in feedback control or reinforcement learning will notice a similar structure (see Fig. 1); however, there are notable additions that minimize human manual input and enhance process automation.
As the first step, a broadly defined task is assigned to the agent by a human, echoing the main goal of lifelong learning. This task often takes the form of a prompt outlining the primary objective, for instance, “explore the environment, and accomplish as many diverse tasks as possible”. The Planner block, conditioned on this broadly defined objective, breaks down the goal into a sequence of executable, understandable tasks. Such breakdown requires an understanding of the environment in which the agent operates. Since LLMs have been trained on a huge corpus of data, they could be the best candidates for being planners. In addition, any supplementary, explicit, or manual context can enhance their performance.
Within the Selector block, a set of derived subtasks is provided by the Planner. The Selector, guided by the main objective and insights from the Critic, determines the most suitable next subtask that not only will generate the best outcome, but also satisfies the prerequisites. The Controller’s job is to generate actions to accomplish the current subtask. To minimize redundant efforts and leverage previously acquired tasks, several studies propose incorporating a Memory block. This block is used to retrieve the most similar learned tasks, thus integrating them into its ongoing workflow.
The generated action is then introduced to the Environment. To assess the impact of recent actions, the Critic monitors the environment state providing the feedback that includes identifying any shortcomings, reasons for failure, or potential task completion. An LLM based Critic necessitates the text input which is accomplished by the Descriptor block, to describe/transform the state of the environment and agent into text. Critic then informs the Planner on what exactly happened in the last attempt and provides comprehensive feedback to assist Planner for the next trial.
Building Blocks description: Comparing Design and Implementation Across Studies
In this section, we explore each block in detail, discussing the various approaches adopted by different researchers.
Planner
This component organizes lifelong learning tasks in a given environment. The ultimate goal can be given manually as in DEPS, or be more like a guideline, i.e., encouraging learning of diverse behavior as a part of the Planner prompt, like in VOYAGER.
The LLM-based Planner orchestrates the learning process by setting tasks that align with the agent’s current state, its skill level, and the provided instructions in its prompt. Such functionality is integrated into LLMs, based on the assumption that they have been exposed to a similar task decomposition process during their training. However, this assumption was not valid in SPRING since they ran the experiment on the Crafter environment which was released after the data collection for GPT-3.5 and GPT-4 models. Therefore, they proposed a method to extract all relevant information from the environment manual text, and then summarize it into a small-size context that will be concatenated to prompts later. In real life applications, agents come across a variety of environments with differing levels of complexity and such straightforward yet efficient methods can be crucial in avoiding the need for fine-tuning of pre-trained models for newly developed tasks.
VOYAGER employed GPT-4 as an automatic curriculum module, attempting to propose increasingly difficult tasks based on the exploration progress and the agent’s state. Its prompt consists of several components, such as:
(1) encouraging exploration while setting the constraints,
(2) the current agent’s state,
(3) previously completed and failed tasks,
(4) any additional context from another GPT-3.5 self-question answering module.
It then outputs a task to be completed by the agent.
DEPS used CODEX, GPT-4, ChatGPT, and GPT-3 as their LLM planner in different environments. The prompt includes:
(1) the formidable ultimate goal (e.g., obtain a diamond in Minecraft environment),
(2) its most recently generated plan,
(3) description of the environment, and its explanation.
In order to improve the efficiency of the plan, DEPS also proposed a state-aware Selector to choose the nearest goal based on the current state from the candidate goal sets generated by the Planner. In complex environments, there often exist multiple viable plans, while many of them prove inefficient in execution and some goals within a plan can be executed in any order, allowing flexibility. Prioritizing closer goals can enhance plan efficiency. To this end, they trained a neural network using offline trajectories to predict and rank based on the time step required for completing the given goals at the current state. The Planner in collaboration with the Selector will generate a sequence of tasks to be accomplished.accomplished.
Controller:
The main responsibility of the controller is to choose the next action to accomplish the given task. The Controller could be another LLM, e.g., VOYAGER, or a deep reinforcement learning model, e.g., DEPS, generating actions based on the state and the given task. VOYAGER employs GPT-4 in an interactive prompting to play the role of the controller. VOYAGER, Progprompt, and CaP choose to use code as the action space instead of low-level motor commands. This is crucial for long horizon tasks since the code can naturally represent temporally extended and compositional actions. The prompt for code generation in VOYAGER includes:
(1) A code generation motivation guideline,
(2) A list of available control primitive APIs with their description,
(3) Relevant skills/codes retrieved from the memory,
(4) The generated code from the previous round, environment feedback, execution errors, and Critic’s output
(5) Current state
(6) Chain-of-thought prompting to do reasoning before code generation.
Another alternative for the controller is to train a deep reinforcement learning agent to generate actions based on the current state and goal. DEPS used imitation learning to train such a model.
Memory:
Humans use different types of memory to accomplish a given task. The main memory functionalities can be categorized into:
1- Short-term memory: Stores information that we are actively using for tasks like learning and reasoning. It’s thought to hold around 7 items and lasts for about 20–30 seconds [10]. To the best of our knowledge, all LLM based lifelong learning methods are using short term memory by in-context learning which is limited by the context length of the LLM.
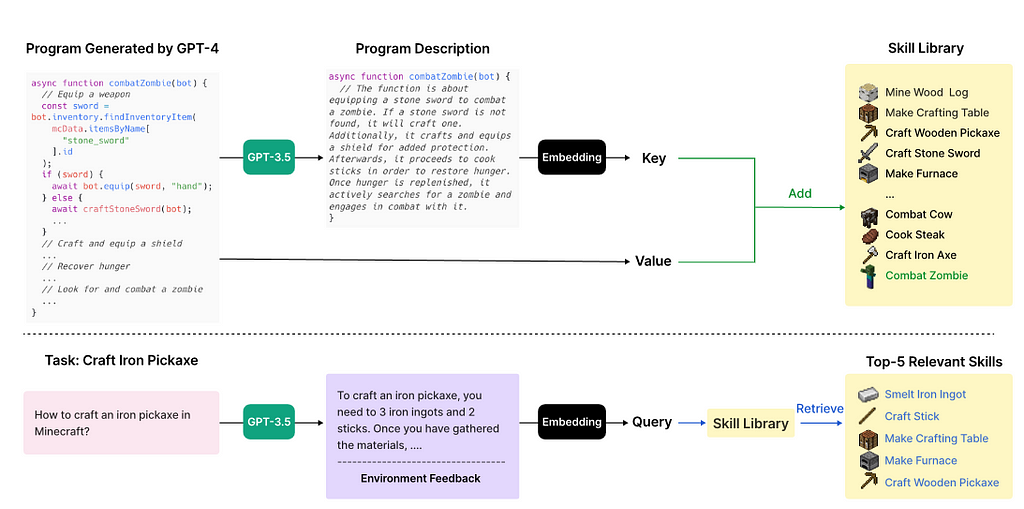
2- Long-term memory: Stores and retrieves information for a long time. This can be implemented as an external vector store with fast retrieval. VOYAGER benefits from long term memory by adding/retrieving learned skills from external vector stores. Skills, as we discussed, are executable codes generated by the Controller which guide the steps needed to accomplish the task.
When the Critic verifies that the code can complete the task, the GPT-3.5 is used to generate a description for the code. Then, the skill will be stored in the skill library, where the embedding of the description acts as the key and the code as the value (see Fig. 2). When a new task is suggested by the Planner, the GPT-3.5 generates a general suggestion for completing the task. They use the embedding of the suggested solution, augmented with environment feedback, to retrieve the top 5 relevant skills from the skill library (see Fig. 2).
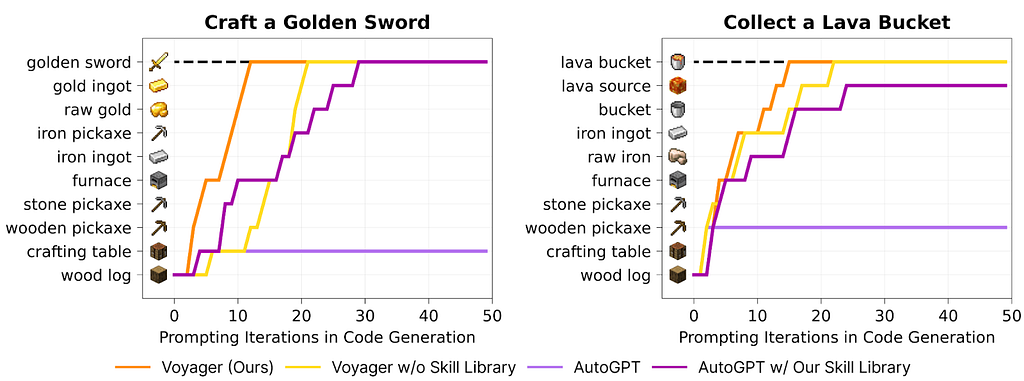
Adding long-term memory can significantly boost the performance. Fig. 3 demonstrates how critical the skill library is for VOYAGER. This also indicates that adding a skill library to Auto-GPT can substantially improve its performance. Both short-term and long-term memory work with the Controller to generate and refine its policy in order to accomplish the goal.
Critic:
Critic or self-verification is an LLM based module which provides critique on the previously executed plan and provides feedback on how to refine the plan to accomplish the task. Reflexion enhances agent reasoning with dynamic memory and self-reflection. The self-reflection is a GPT-4, playing the role of Critic. It takes the reward signal, current trajectory and its persistent memory to generate verbal feedback for self-improvement for future trials. This feedback is more informative than a scalar reward and is stored in the memory to be used by the Planner to refine the plan.
VOYAGER and DEPS execute the generated actions, code, by the Controller to obtain the Environment feedback and possibly execution errors. This information is incorporated into the Critic prompt, where it is asked to act as a critic and determine whether the goal is completed or not. Moreover, if the task has failed, it provides suggestions on how to complete the task.
Descriptor:
In LLM based lifelong learning the Planner input and output is text. Some environments such as Crafter are text based while for the rest of the environments, they return a rendering of 2D or 3D image, or possibly a few state variables. A descriptor acts as a bridge, converting the modalities into text and incorporating them into an LLM’s prompt.
Autonomous AI agents:
This blog primarily discusses recent studies that integrate foundational models with continual learning, a significant stride towards achieving AGI. However, it’s important to recognize that these approaches represent a subset of the broader endeavor to develop autonomous agents. Several notable initiatives likely served as catalysts for the research discussed here. We will briefly highlight these in the following section.
Recently, several works, such as AutoGPT and BabyAGI, appear to be inspiring in using LLMs as the brain, and are designed to be an autonomous agent to solve complex problems. You provide them with a task. They run in a loop, breaking the task into subtasks, prompting themselves, responding to the prompt, and repeating the process until they achieve the provided goal. They also can have access to different APIs, such as internet access, which can substantially broaden their use cases.
AutoGPT is both a GPT-3.5 and a GPT-4, teamed up with a companion bot that guides and tells them what to do. AutoGPT has internet access and is able to interact with apps, software, and services, both online and local. To accomplish a higher-level goal given by humans, AutoGPT uses a format of prompting called Reason and ACT (ReACT). ReACT enables the agent to receive an input, understand it, act based on it, reason upon the results, and then re-run that loop if needed. Since AutoGPT can prompt itself, it can think and reason while accomplishing the task, looking for solutions, discard the unsuccessful ones, and consider different options.
BabyAGI is another recently introduced autonomous AI agent. It has three LLM based components (See Fig. 4):
1- There is a task creation agent that comes up with a task list (similar to Planer)
2- A prioritization agent tries to prioritize a task list by LLM prompting (similar to Selector)
3- An execution agent (Similar to Controller) executes a task with highest priority.
Both AutoGPT and BabyAGI use a vector store under the hood to store intermediate results and learn from the experiences.
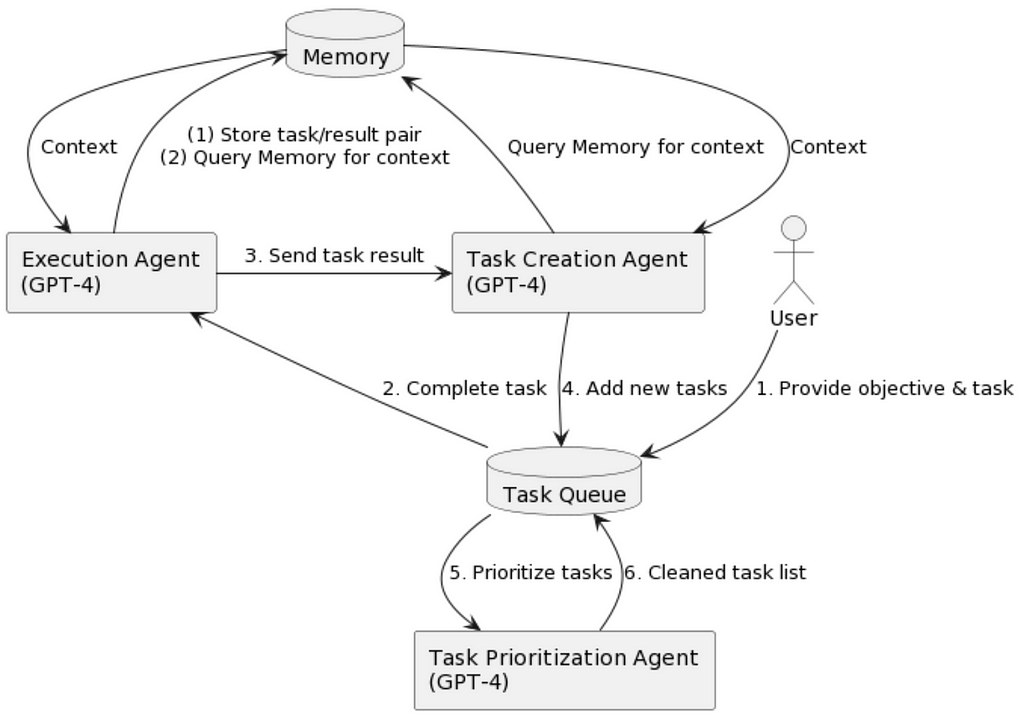
Fig. 4: BabyAGI flowchart diagram (image source Yohei Nakajima’s website)
Limitations and challenges:
1- LLM based lifelong learning heavily depends on the reliability of LLMs to accurately understand the environment and effectively plan and critique. However, studies reveal that LLMs can sometimes produce hallucinations, make up facts, and assign tasks that do not exist. Notably, in some of the referenced studies, substituting GPT-4 with GPT-3.5 led to a significant decline in performance, underscoring the critical role of the LLM model employed.
2- LLMs exhibit inaccuracies when employed as a Planner or a Critic. The Critic may provide incorrect feedback or fail to accurately verify task completion. Similarly, the Planner might become trapped in a repetitive cycle, unable to adjust its plan even after several attempts. Adding a well-designed, event-triggered human intervention process can boost the performance of these models in such scenarios.
3- The limited context length in LLMs restricts the short-term memory capability, affecting their ability to retain detailed past experiences and their results, detailed instructions, and available control primitive APIs. A long context length is very critical, especially in self-verification, to learn from past experiences and failures. Despite ongoing research efforts, to extend context length or employ methods like Transformer-XL, in most cases authors used GPT-4 with the maximum of 8,192 tokens context length.
4- Most of these works, except SPRING, assume that the LLM knows all the necessary information required to initiate lifelong learning before starting the experiment. However, this assumption might not always hold true. Providing Internet access to agents, as in AutoGPT, or providing textual material as input context, as in SPRING, can be helpful to address follow-up questions.
References:
[1] VOYAGER: Wang, Guanzhi, et al. “Voyager: An open-ended embodied agent with large language models.”, 2023
[2] DEPS: Wang, Zihao, et al. “Describe, explain, plan and select: Interactive planning with large language models enables open-world multi-task agents.”, 2023
[3] SPRING: Wu, Yue, et al. “SPRING: GPT-4 Out-performs RL Algorithms by Studying Papers and Reasoning.”, 2023
[4] Reflexion: Shinn, Noah, et al. “Reflexion: Language agents with verbal reinforcement learning.”, 2023
[5] Progprompt: Singh, Ishika, et al. “Progprompt: Generating situated robot task plans using large language models.”, 2023
[6] React: Yao, Shunyu, et al. “React: Synergizing reasoning and acting in language models.”, 2022
[7] CaP: Liang, Jacky, et al. “Code as policies: Language model programs for embodied control.”, 2023
[8] AutoGPT. https://github.com/Significant-Gravitas/Auto-GPT
[9] babyAGI: https://github.com/yoheinakajima/babyagi
[10] Weng, Lilian, et al. LLM-powered Autonomous Agents”, 2023
Towards AGI: LLMs and Foundational Models’ Roles in the Lifelong Learning Revolution was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Towards AGI: LLMs and Foundational Models’ Roles in the Lifelong Learning Revolution



