

Open-source intelligence (OSINT) is something that can add tremendous value to organizations. Insight gained from analyzing social media data, web data, or global research, can be great in supporting all kinds of analyses. This article will give an overview of using topic modeling to help us make sense of thousands of pieces of open-source research.
What is Topic Modeling?
Topic modeling is an unsupervised machine learning technique used to analyze documents and identity ‘topics’ using semantic similarity. This is similar to clustering, but not every document is exclusive to one topic. It is more about grouping the content found in a corpus. Topic modeling has many different applications but is mainly used to better understand large amounts of text data.

For example, a retail chain may model customer surveys and reviews to identify negative reviews and drill down into the key issues outlined by their customers. In this case, we will import a large amount of articles and abstracts to understand the key topics in our dataset.
Note: Topic modeling can be computationally expensive at scale. In this example, I used the Amazon Sagemaker environment to take advantage of their CPU.
OpenAlex
OpenAlex is a free to use catalogue system of global research. They have indexed over 250 million pieces of news, articles, abstracts, and more.
Luckily for us, they have a free (but limited) and flexible API that will allow us to quickly ingest tens of thousands of articles while also applying filters, such as year, type of media, keywords, etc.
Creating a Data Pipeline
While we ingest the data from the API, we will apply some criteria. First, we will only ingest documents where the year is between 2016 and 2022. We want fairly recent language as terms and taxonomy of certain subjects can change over long periods of time.
We will also add key terms and conduct multiple searches. While normally we would likely ingest random subject areas, we will use key terms to narrow our search. This way, we will have an idea of how may high-level topics we have, and can compare that to the output of the model. Below, we create a function where we can add key terms and conduct searches through the API.
import pandas as pd
import requests
def import_data(pages, start_year, end_year, search_terms):
"""
This function is used to use the OpenAlex API, conduct a search on works, a return a dataframe with associated works.
Inputs:
- pages: int, number of pages to loop through
- search_terms: str, keywords to search for (must be formatted according to OpenAlex standards)
- start_year and end_year: int, years to set as a range for filtering works
"""
#create an empty dataframe
search_results = pd.DataFrame()
for page in range(1, pages):
#use paramters to conduct request and format to a dataframe
response = requests.get(f'https://api.openalex.org/works?page={page}&per-page=200&filter=publication_year:{start_year}-{end_year},type:article&search={search_terms}')
data = pd.DataFrame(response.json()['results'])
#append to empty dataframe
search_results = pd.concat([search_results, data])
#subset to relevant features
search_results = search_results[["id", "title", "display_name", "publication_year", "publication_date",
"type", "countries_distinct_count","institutions_distinct_count",
"has_fulltext", "cited_by_count", "keywords", "referenced_works_count", "abstract_inverted_index"]]
return(search_results)
We conduct 5 different searches, each being a different technology area. These technology areas are inspired by the DoD “Critical Technology Areas”. See more here:
USD(R&E) Strategic Vision and Critical Technology Areas – DoD Research & Engineering, OUSD(R&E)
Here is an example of a search using the required OpenAlex syntax:
#search for Trusted AI and Autonomy
ai_search = import_data(35, 2016, 2024, "'artificial intelligence' OR 'deep learn' OR 'neural net' OR 'autonomous' OR drone")
After compiling our searches and dropping duplicate documents, we must clean the data to prepare it for our topic model. There are 2 main issues with our current output.
- The abstracts are returned as an inverted index (due to legal reasons). However, we can use these to return the original text.
- Once we obtain the original text, it will be raw and unprocessed, creating noise and hurting our model. We will conduct traditional NLP preprocessing to get it ready for the model.
Below is a function to return original text from an inverted index.
def undo_inverted_index(inverted_index):
"""
The purpose of the function is to 'undo' and inverted index. It inputs an inverted index and
returns the original string.
"""
#create empty lists to store uninverted index
word_index = []
words_unindexed = []
#loop through index and return key-value pairs
for k,v in inverted_index.items():
for index in v: word_index.append([k,index])
#sort by the index
word_index = sorted(word_index, key = lambda x : x[1])
#join only the values and flatten
for pair in word_index:
words_unindexed.append(pair[0])
words_unindexed = ' '.join(words_unindexed)
return(words_unindexed)
Now that we have the raw text, we can conduct our traditional preprocessing steps, such as standardization, removing stop words, lemmatization, etc. Below are functions that can be mapped to a list or series of documents.
def preprocess(text):
"""
This function takes in a string, coverts it to lowercase, cleans
it (remove special character and numbers), and tokenizes it.
"""
#convert to lowercase
text = text.lower()
#remove special character and digits
text = re.sub(r'd+', '', text)
text = re.sub(r'[^ws]', '', text)
#tokenize
tokens = nltk.word_tokenize(text)
return(tokens)
def remove_stopwords(tokens):
"""
This function takes in a list of tokens (from the 'preprocess' function) and
removes a list of stopwords. Custom stopwords can be added to the 'custom_stopwords' list.
"""
#set default and custom stopwords
stop_words = nltk.corpus.stopwords.words('english')
custom_stopwords = []
stop_words.extend(custom_stopwords)
#filter out stopwords
filtered_tokens = [word for word in tokens if word not in stop_words]
return(filtered_tokens)
def lemmatize(tokens):
"""
This function conducts lemmatization on a list of tokens (from the 'remove_stopwords' function).
This shortens each word down to its root form to improve modeling results.
"""
#initalize lemmatizer and lemmatize
lemmatizer = nltk.WordNetLemmatizer()
lemmatized_tokens = [lemmatizer.lemmatize(token) for token in tokens]
return(lemmatized_tokens)
def clean_text(text):
"""
This function uses the previously defined functions to take a string and
run it through the entire data preprocessing process.
"""
#clean, tokenize, and lemmatize a string
tokens = preprocess(text)
filtered_tokens = remove_stopwords(tokens)
lemmatized_tokens = lemmatize(filtered_tokens)
clean_text = ' '.join(lemmatized_tokens)
return(clean_text)
Now that we have a preprocessed series of documents, we can create our first topic model!
Creating a Topic Model
For our topic model, we will use gensim to create a Latent Dirichlet Allocation (LDA) model. LDA is the most common model for topic modeling, as it is very effective in identifying high-level themes within a corpus. Below are the packages used to create the model.
import gensim.corpora as corpora
from gensim.corpora import Dictionary
from gensim.models.coherencemodel import CoherenceModel
from gensim.models.ldamodel import LdaModel
Before we create our model, we must prepare our corpus and ID mappings. This can be done with just a few lines of code.
#convert the preprocessed text to a list
documents = list(data["clean_text"])
#seperate by ' ' to tokenize each article
texts = [x.split(' ') for x in documents]
#construct word ID mappings
id2word = Dictionary(texts)
#use word ID mappings to build corpus
corpus = [id2word.doc2bow(text) for text in texts]
Now we can create a topic model. As you will see below, there are many different parameters that will affect the model’s performance. You can read about the many parameters in gensim’s documentation.
#build LDA model
lda_model = LdaModel(corpus = corpus, id2word = id2word, num_topics = 10, decay = 0.5,
random_state = 0, chunksize = 100, alpha = 'auto', per_word_topics = True)
The most import parameter will be the number of topics. Here, we set an arbitrary 10. Since we don’t know how many topics there should be, this parameter should definitely be optimized. But how do we measure the quality of our model?
This is where coherence scores come in. The coherence score is a measure from 0–1. Coherence scores measure the quality of our topics by making sure they are sound and distinct. We want clear boundaries between well-defined topics. While this is a bit subjective in the end, it gives us a great idea of the quality of our results.
#compute coherence score
coherence_model_lda = CoherenceModel(model = lda_model, texts = texts, dictionary = id2word, coherence = 'c_v')
coherence_score = coherence_model_lda.get_coherence()
print(coherence_score)
Here, we get a coherence score of about 0.48, which isn’t too bad! But not ready for production.
Visualize Our Topic Model
Topic models can be difficult to visualize. Lucky for us, there is a great module ‘pyLDAvis’ that can automatically produce an interactive visualization that allows us to view our topics in a vector space and drill down into each topic.
import pyLDAvis
#create Topic Distance Visualization
pyLDAvis.enable_notebook()
lda_viz = pyLDAvis.gensim.prepare(lda_model, corpus, id2word)
lda_viz
As you can see below, this produces a great visualization where we can get a quick idea of how our model performed. By looking into the vector space, we see some topics are distinct and well-defined. However, we also have some overlapping topics.
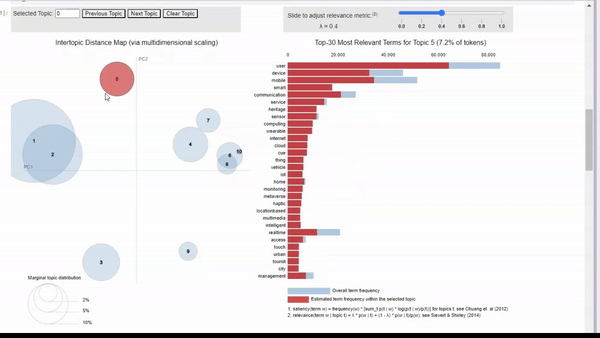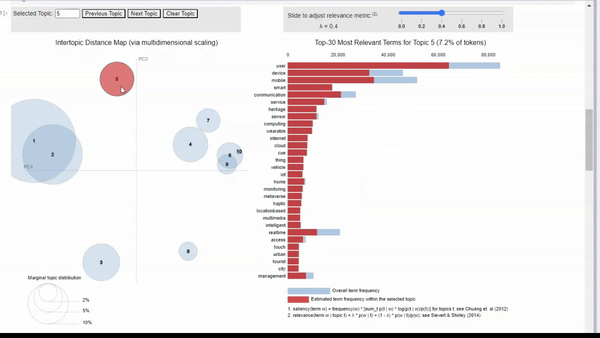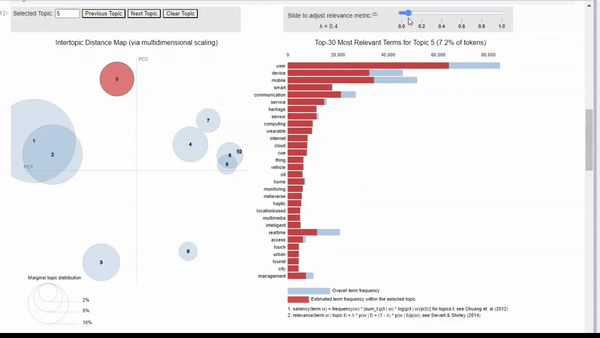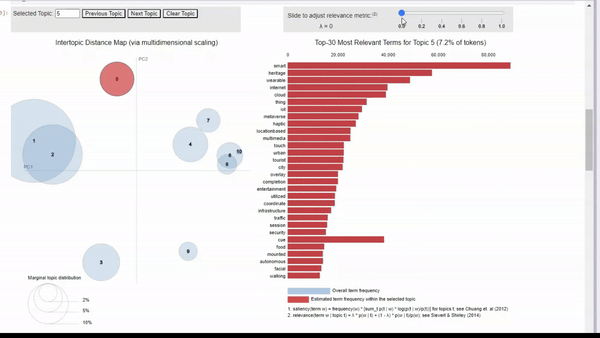
We can click on a topic to few the most relevant tokens. As we adjust the relevance metric (lambda), we can see topic-specific tokens by sliding it left, and seeing relevant but less topic-specific tokens by sliding it to the right.
When clicking into each topic, I can vaguely see the topics that I originally searched for. For example, topic 5 seems to align with my ‘human-machine interfaces’ search. There is also a cluster of topics that seem to be related to biotechnology, but some are more clear than others.
Optimize the Topic Model
From the pyLDAvis interface and our coherence score of 0.48, there is definitely room for improvement. For our final step, lets write a function where we can loop through values for different parameters and try to optimize our coherence score. Below, is a function that tests different values of the number of topics and the decay rate. The function computes the coherence score for every combination of parameters and saves them in a data frame.
def lda_model_evaluation():
"""
This function loops through a number of parameters for an LDA model, creates the model,
computes the coherenece score, and saves the results in a pandas dataframe. The outputed dataframe
contains the values of the parameters tested and the resulting coherence score.
"""
#define empty lists to save results
topic_number, decay_rate_list, score = [], [], []
#loop through a number of parameters
for topics in range(5,12):
for decay_rate in [0.5, 0.6, 0.7]:
#build LDA model
lda_model = LdaModel(corpus = corpus, id2word = id2word, num_topics = topics, decay = decay_rate,
random_state = 0, chunksize = 100, alpha = 'auto', per_word_topics = True)
#compute coherence score
coherence_model_lda = CoherenceModel(model = lda_model, texts = texts, dictionary = id2word, coherence = 'c_v')
coherence_score = coherence_model_lda.get_coherence()
#append parameters to lists
topic_number.append(topics)
decay_rate_list.append(decay_rate)
score.append(coherence_score)
print("Model Saved")
#gather result into a dataframe
results = {"Number of Topics": topic_number,
"Decay Rate": decay_rate_list,
"Score": score}
results = pd.DataFrame(results)
return(results)
Just by passing a couple of small ranges through two parameters, we identified parameters that increased our coherence score from 0.48 to 0.55, a sizable improvement.
Next Steps
To continue to build a production-level model, there is plenty of experimentation to be had with the parameters. Because LDA is so computationally expensive, I kept the experiment above limited and only compared about 20 different models. But with more time and power, we can compare hundreds of models.
As well, there are improvements to be made with our data pipeline. I noticed several words that may need to be added to our stop word list. Words like ‘use’ and ‘department’ are not adding any semantic value, especially for documents about different technologies. As well, there are technical terms that do not get processed correctly, resulting in a single letter or a group of letters. We could spend some time doing a bag-of-words analysis to identify those stop word opportunities. This would eliminate noise in our dataset.
Conclusion
In this article, we:
- Got an introduction to topic modeling and the OpenAlex data source
- Built a data pipeline to ingest data from an API and prepare it for an NLP model
- Constructed an LDA model and visualized the results using pyLDAvis
- Wrote code to help us find the optimal parameters
- Discussed next steps for model improvement
This is my first Medium article, so I hope you enjoyed it. Please feel free to leave feedback, ask questions, or request other topics!
Topic Modeling Open-Source Research with the OpenAlex API was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Topic Modeling Open-Source Research with the OpenAlex API
Go Here to Read this Fast! Topic Modeling Open-Source Research with the OpenAlex API