

Results from experiments to evaluate and compare GPT-4, Claude 2.1, and Claude 3.0 Opus
New evaluations of RAG systems are published seemingly every day, and many of them focus on the retrieval stage of the framework. However, the generation aspect — how a model synthesizes and articulates this retrieved information — may hold equal if not greater significance in practice. Many use cases in production are not simply returning a fact from the context, but also require synthesizing the fact into a more complicated response.
We ran several experiments to evaluate and compare GPT-4, Claude 2.1 and Claude 3.0 Opus’s generation capabilities. This article details our research methodology, results, and model nuances encountered along the way as well as why this matters to people building with generative AI.
Everything needed to reproduce the results can be found in this GitHub repository.
Takeaways
- Although initial findings indicate that Claude outperforms GPT-4, subsequent tests reveal that with strategic prompt engineering GPT-4 demonstrated superior performance across a broader range of evaluations. Inherent model behaviors and prompt engineering matter A LOT in RAG systems.
- Simply adding “Please explain yourself then answer the question” to a prompt template significantly improves (more than 2X) GPT-4’s performance. It’s clear that when an LLM talks answers out, it seems to help in unfolding ideas. It’s possible that by explaining, a model is re-enforcing the right answer in embedding/attention space.
Phases of RAG and Why Generation is Important
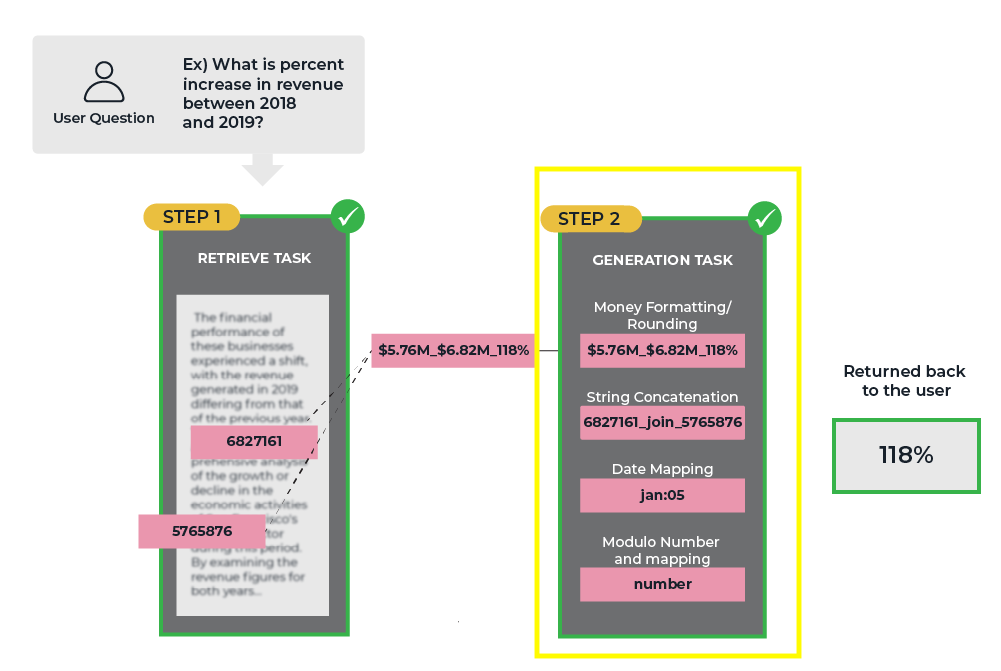
While retrieval is responsible for identifying and retrieving the most pertinent information, it is the generation phase that takes this raw data and transforms it into a coherent, meaningful, and contextually appropriate response. The generative step is tasked with synthesizing the retrieved information, filling in gaps, and presenting it in a manner that is easily understandable and relevant to the user’s query.
In many real-world applications, the value of RAG systems lies not just in their ability to locate a specific fact or piece of information but also in their capacity to integrate and contextualize that information within a broader framework. The generation phase is what enables RAG systems to move beyond simple fact retrieval and deliver truly intelligent and adaptive responses.
Test #1: Date Mapping
The initial test we ran involved generating a date string from two randomly retrieved numbers: one representing the month and the other the day. The models were tasked with:
- Retrieving Random Number #1
- Isolating the last digit and incrementing by 1
- Generating a month for our date string from the result
- Retrieving Random Number #2
- Generating the day for our date string from Random Number 2
For example, random numbers 4827143 and 17 would represent April 17th.
These numbers were placed at varying depths within contexts of varying length. The models initially had quite a difficult time with this task.
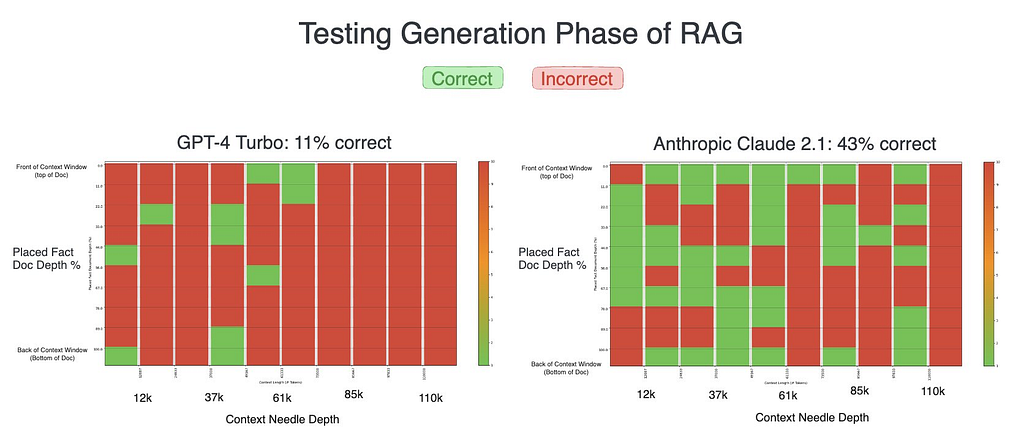
While neither model performed great, Claude 2.1 significantly outperformed GPT-4 in our initial test, almost quadrupling its success rate. It was here that Claude’s verbose nature — providing detailed, explanatory responses — seemed to give it a distinct advantage, resulting in more accurate outcomes compared to GPT-4’s initially concise replies.
Prompted by these unexpected results, we introduced a new variable to the experiment. We instructed GPT-4 to “explain yourself then answer the question,” a prompt that encouraged a more verbose response akin to Claude’s natural output. The impact of this minor adjustment was profound.
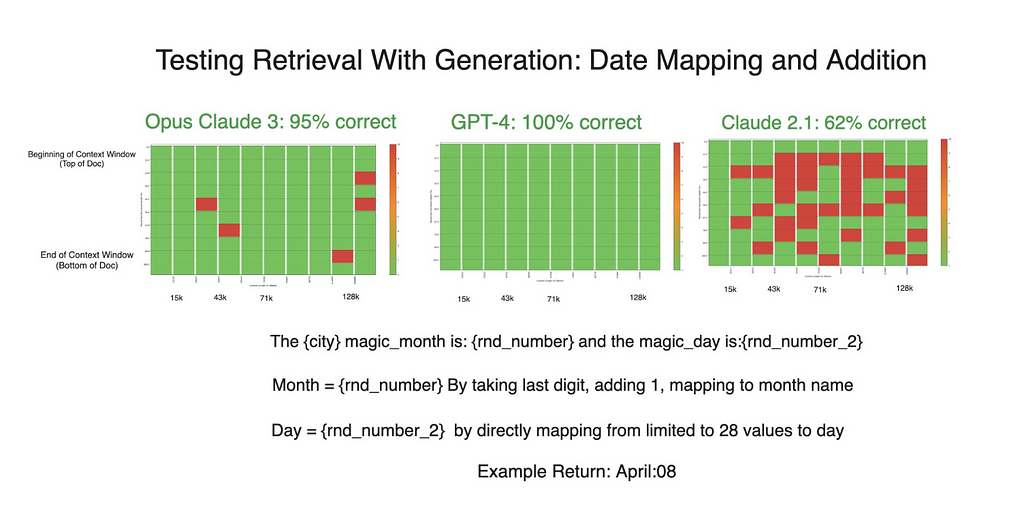
GPT-4’s performance improved dramatically, achieving flawless results in subsequent tests. Claude’s results also improved to a lesser extent.
This experiment not only highlights the differences in how language models approach generation tasks but also showcases the potential impact of prompt engineering on their performance. The verbosity that appeared to be Claude’s advantage turned out to be a replicable strategy for GPT-4, suggesting that the way a model processes and presents its reasoning can significantly influence its accuracy in generation tasks. Overall, including the seemingly minute “explain yourself” line to our prompt played a role in improving the models’ performance across all of our experiments.
Further Testing and Results

We conducted four more tests to assess prevailing models’ ability to synthesize and transform retrieved information into various formats:
- String Concatenation: Combining pieces of text to form coherent strings, testing the models’ basic text manipulation skills.
- Money Formatting: Formatting numbers as currency, rounding them, and calculating percentage changes to evaluate the models’ precision and ability to handle numerical data.
- Date Mapping: Converting a numerical representation into a month name and date, requiring a blend of retrieval and contextual understanding.
- Modulo Arithmetic: Performing complex number operations to test the models’ mathematical generation capabilities.
Unsurprisingly, each model exhibited strong performance in string concatenation, reaffirming previous understanding that text manipulation is a fundamental strength of language models.
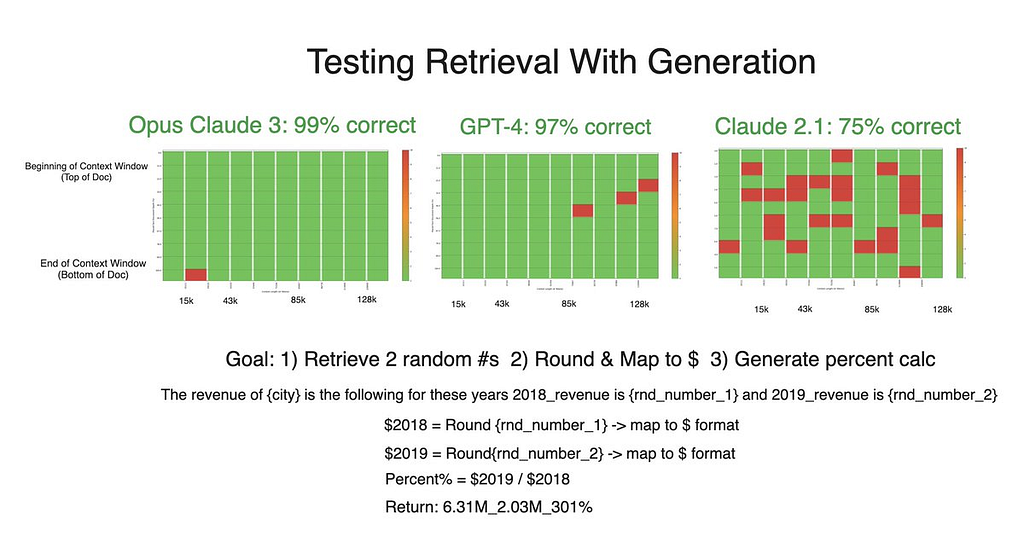
As for the money formatting test, Claude 3 and GPT-4 performed almost flawlessly. Claude 2.1’s performance was generally poorer overall. Accuracy did not vary considerably across token length, but was generally lower when the needle was closer to the beginning of the context window.
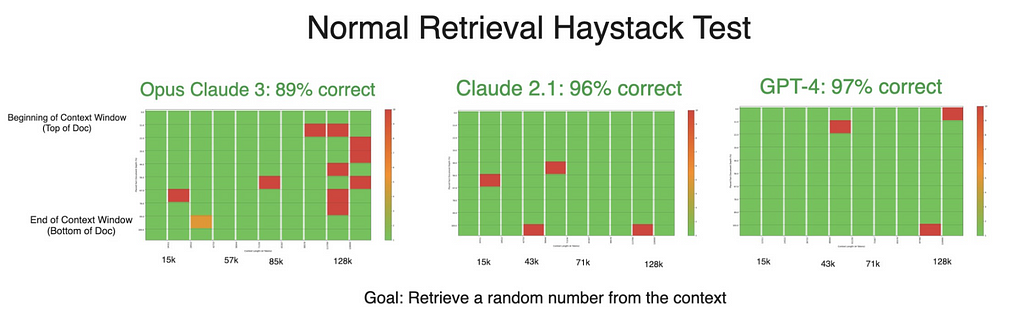
Despite stellar results in the generation tests, Claude 3’s accuracy declined in a retrieval-only experiment. Theoretically, simply retrieving numbers should be an easier task than manipulating them as well — making this decrease in performance surprising and an area where we’re planning further testing to examine. If anything, this counterintuitive dip only further confirms the notion that both retrieval and generation should be tested when developing with RAG.
Conclusion
By testing various generation tasks, we observed that while both models excel in menial tasks like string manipulation, their strengths and weaknesses become apparent in more complex scenarios. LLMs are still not great at math! Another key result was that the introduction of the “explain yourself” prompt notably enhanced GPT-4’s performance, underscoring the importance of how models are prompted and how they articulate their reasoning in achieving accurate results.
These findings have broader implications for the evaluation of LLMs. When comparing models like the verbose Claude and the initially less verbose GPT-4, it becomes evident that the evaluation criteria must extend beyond mere correctness. The verbosity of a model’s responses introduces a variable that can significantly influence their perceived performance. This nuance may suggest that future model evaluations should consider the average length of responses as a noted factor, providing a better understanding of a model’s capabilities and ensuring a fairer comparison.
Tips for Getting the Generation Part Right in Retrieval Augmented Generation was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Tips for Getting the Generation Part Right in Retrieval Augmented Generation