

Three Reasons Why Developers Should Use DuckDB
How software developers can use DuckDB for data analysis
Software developers have to wear many hats: from writing code, designing systems to analysing data dumps during an incident. Most of our tools are optimised for the task — for writing code we have powerful IDEs, for designing systems we have feature-rich diagramming tools.
For data analysis, do software developers have the best tool for the job? In this article, I list three key reasons why DuckDB, an open-source analytical database is a must-have tool for software developers.
Reason #1: Uses universally understood SQL
Imagine you work for a food-delivery company as a software developer. You receive an email that there is a sudden increase in payment-related customer complaints. The email includes a CSV file like this with some orders categorised by the nature of the complaint. As a developer under the heat, you may be inclined to quickly lookup how to analyse a CSV file on StackOverflow, which tells us to use awk.
awk -F','
'NR > 1 {count[$6]++} END
{for (value in count) print value, count[value]}'
datagenerator/adjusted_transactions.csv | sort
CUSTOMER_SUPPORT_REFUND 8494
INSUFFICIENT_FUNDS 1232
MANUAL_ADJUSTMENT 162
REVERSED_PAYMENT 62815
It is natural to ask a followup question: how often do we see these errors per order? Answering iterative questions using tools like awk can be challenging because of its unfamiliar syntax. Moreover, had the data been in another format like JSON, we would have to use a different tool like jq with its completely different syntax and usage pattern.
DuckDB solves the problem of needing specific tooling for specific data formats by providing a unified SQL interface to a wide array of file types. Developers use SQL on a very regular basis and it is the language used to query the most deployed database in the world. Owing to the ubiquity of SQL, non-relational data systems have added support for accessing data using SQL: like MongoDB, Spark, Elastic-search and AWS Athena.
Going back to the original CSV file, using duckdb and SQL we can quite simply find how often an error is reported per order:
duckdb -c "
with per_order_counts AS (
select
order_id, reason,
count(transaction_id) as num_reports
from 'datagenerator/adjusted_transactions.csv'
group by 1,2
)
select reason, avg(num_reports) AS avg_per_order_count
from per_order_counts group by 1 order by reason;"
┌─────────────────────────┬─────────────────────┐
│ reason │ avg_per_order_count │
│ varchar │ double │
├─────────────────────────┼─────────────────────┤
│ CUSTOMER_SUPPORT_REFUND │ 10.333333333333334 │
│ INSUFFICIENT_FUNDS │ 2.871794871794872 │
│ MANUAL_ADJUSTMENT │ 1.2 │
│ REVERSED_PAYMENT │ 50.57568438003221 │
└─────────────────────────┴─────────────────────┘
Reason #2: Supports multiple databases and file types
Assume our fictional food-delivery app is built using microservices. Say, there is a users microservice which stores user information in PostgreSQL and another orders microservice which stores order information in MySQL.
It is very hard to answer the following cross-microservice question: Are VIP users affected more compared to non-VIP users?
Typical setups to solve this use data pipelines to aggregate data from all microservices in one data warehouse, which is expensive and not easy to keep updated in realtime.
Using DuckDB, we can attach a MySQL database and a PostgreSQL database to join data across databases and filter against a CSV file. The database setup and code is available in this repository:
ATTACH 'host=localhost port=5432 dbname=flock user=swan password=mallard'
AS pg_db (TYPE postgres_scanner, READ_ONLY);
ATTACH 'host=localhost port=3306 database=flock user=swan password=mallard'
AS mysql_db (TYPE mysql_scanner, READ_ONLY);
select u.tier,
count(distinct o.id) as order_count
from pg_db.users u join mysql_db.orders o
on u.id = o.created_by
where o.id IN (
select order_id
from 'datagenerator/adjusted_transactions.csv'
)
group by 1 ;
┌─────────┬─────────────┐
│ tier │ order_count │
│ varchar │ int64 │
├─────────┼─────────────┤
│ plus │ 276 │
│ normal │ 696 │
│ club │ 150 │
│ vip │ 148 │
└─────────┴─────────────┘
In the above snippet we queried PostgreSQL, MySQL and a CSV file, but DuckDB supports many other data sources like Microsoft Excel, JSON and S3 files — all using the same SQL interface.
Reason #3: Portability and Extensibility
DuckDB runs on the command-line shell as a standalone process without any additional dependency (like a server process). This portability makes DuckDB comparable to other Unix tools like sed, jq , sort and awk.
DuckDB can also be imported as a library in programs written in languages like Python and Javascript. In fact, DuckDB can also run in the browser — in this link, a SQL query fetches Rich Hickey’s repositories from Github and groups them by language — all from within the browser:

For features not included in DuckDB, community extensions can be used to add more functionality like cryptographic hash functions which were added as a community extension.
Conclusion
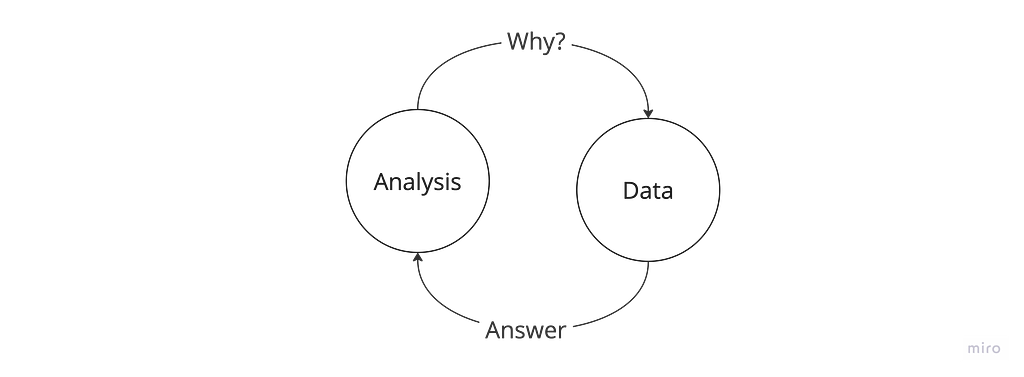
Data analysis is an iterative process of asking questions about the data to get to an explanation of why something is happening. Quoting Carl Jung, “to ask the right question is already half the solution to a problem”.
With traditional command-line tools, between the data and the question, there is the additional step of figuring out how to answer that question. This interrupts the iterative questioning process.

DuckDB unifies the proliferation of tools: (1) it runs everywhere (2) can query multiple data sources (3) with a declarative language that is widely understood. Using DuckDB, the feedback loop for iterative analysis is much shorter making DuckDB the one true tool that all developers should keep in their toolbox for analysing data.
Three reasons why developers should use DuckDB was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Three reasons why developers should use DuckDB
Go Here to Read this Fast! Three reasons why developers should use DuckDB