Balancing correctness, latency, and cost in unbounded data processing
Table of contents
- Before we move on
- Introduction from the paper.
- The details of the Dataflow model.
- Implementation and designs of the model.
Intro
Google Dataflow is a fully managed data processing service that provides serverless unified stream and batch data processing. It is the first choice Google would recommend when dealing with a stream processing workload. The service promises to ensure correctness and latency regardless of how big your workload is. To achieve these characteristics, Google Dataflow is backed by a dedicated processing model, Dataflow, resulting from many years of Google research and development. This blog post is my note after reading the paper: The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing. If you want to learn more about stream processing, I strongly recommend this paper. It contains all the lessons and insights from Google’s introduction of the Dataflow model to deal with its global-scale stream processing demand. Despite being written in 2015, I believe this paper’s contribution will never be old.
Note: The paper was published in 2015, so some details may be changed or updated now; if you have any feedback or information that can supplement my blog, feel free to comment.
Before we move on
To avoid more confusing
- Dataflow is the Google stream processing model.
- Apache Beam lets users define processing logic based on the Dataflow model.
- Google Cloud Dataflow is a unified processing service from Google Cloud; you can think it’s the destination execution engine for the Apache Beam pipeline.
Workflow: You define the unified processing logic using Apache Beam and decide to run the pipeline on the execution engine you want, such as Google Dataflow, Spark, Flink, etc.
Before we explore the Dataflow model in depth, the following sections will introduce some information, such as context, challenges, and concepts.
Paper’s Introduction
At the time of the paper writing, data processing frameworks like MapReduce and its “cousins “ like Hadoop, Pig, Hive, or Spark allow the data consumer to process batch data at scale. On the stream processing side, tools like MillWheel, Spark Streaming, or Storm came to support the user. Still, these existing models did not satisfy the requirement in some common use cases.
Consider an example: A streaming video provider’s business revenue comes from billing advertisers for the amount of advertising watched on their content. They want to know how much to bill each advertiser daily and aggregate statistics about the videos and ads. Moreover, they want to run offline experiments over large amounts of historical data. They want to know how often and for how long their videos are being watched, with which content/ads, and by which demographic groups. All the information must be available quickly to adjust their business in near real-time. The processing system must also be simple and flexible to adapt to the business’s complexity. They also require a system that can handle global-scale data since the Internet allows companies to reach more customers than ever. Here are some observations from people at Google about the state of the data processing systems of that time:
- Batch systems such as MapReduce, FlumeJava (internal Google technology), and Spark fail to ensure the latency SLA since they require waiting for all data input to fit into a batch before processing it.
- Streaming processing systems that provide scalability and fault tolerance fall short of the expressiveness or correctness aspect.
- Many cannot provide exactly once semantics, impacting correctness.
- Others lack the primitives necessary for windowing or provide windowing semantics that are limited to tuple- or processing-time-based windows (e.g., Spark Streaming)
- Most that provide event-time-based windowing rely on ordering or have limited window triggering.
- MillWheel and Spark Streaming are sufficiently scalable, fault-tolerant, and low-latency but lack high-level programming models.
They conclude the major weakness of all the models and systems mentioned above is the assumption that the unbounded input data will eventually be complete. This approach does not make sense anymore when faced with the realities of today’s enormous, highly disordered data. They also believe that any approach to solving diverse real-time workloads must provide simple but powerful interfaces for balancing the correctness, latency, and cost based on specific use cases. From that perspective, the paper has the following conceptual contribution to the unified stream processing model:
- Allowing for calculating event-time ordered (when the event happened) results over an unbounded, unordered data source with configurable combinations of correctness, latency, and cost attributes.
- Separating pipeline implementation across four related dimensions:
– What results are being computed?
– Where in event time they are being computed.
– When they are materialized during processing time,
– How do earlier results relate to later refinements?
- Separating the logical abstraction of data processing from the underlying physical implementation layer allows users to choose the processing engine.
In the rest of this blog, we will see how Google enables this contribution. One last thing before we move to the next section: Google noted that there is “nothing magical about this model. “ The model doesn’t make your expensive-computed task suddenly run faster; it provides a general framework that allows for the simple expression of parallel computation, which is not tied to any specific execution engine like Spark or Flink.
Unbounded/Bounded
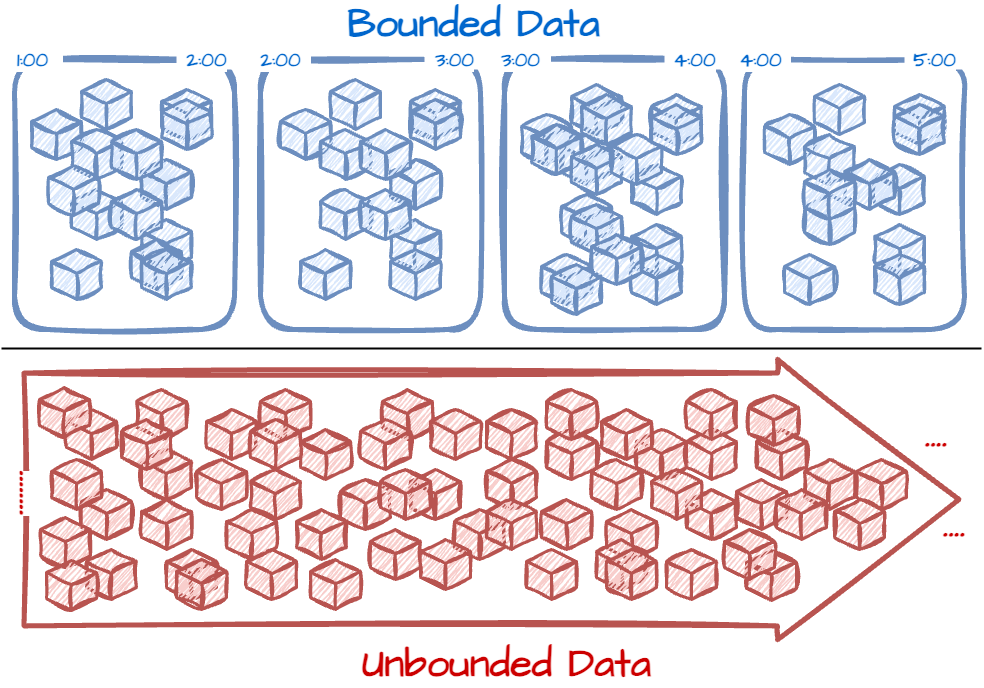
The paper’s authors use the term unbounded/bounded to define infinite/finite data. They avoid using streaming/batch terms because they usually imply using a specific execution engine. The term unbound data describes the data that doesn’t have a predefined boundary, e.g., the user interaction events of an active e-commerce application; the data stream only stops when the application is inactive. Whereas bounded data refers to data that can be defined by clear start and end boundaries, e.g., daily data export from the operation database.
To continue with the introduction section, we will review some concepts used throughout the paper.
Windowing
The organizer
Windowing divides the data into finite chunks. Usually, the system uses time notions to organize data into the window (e.g., all data in the last 1 hour will belong to one window). All data in the windows are processed as a group. Users require grouping operations on the window abstractions: aggregation or time-bounded operation when processing unbound data. On the other hand, some operations on unbounded data don’t need the window notion, like filtering, mapping, or inner join. Windows may be aligned, e.g., applied across all the data for a given window, or unaligned, e.g., applied across only specific subsets of the data in that window. There are three major types of windows:
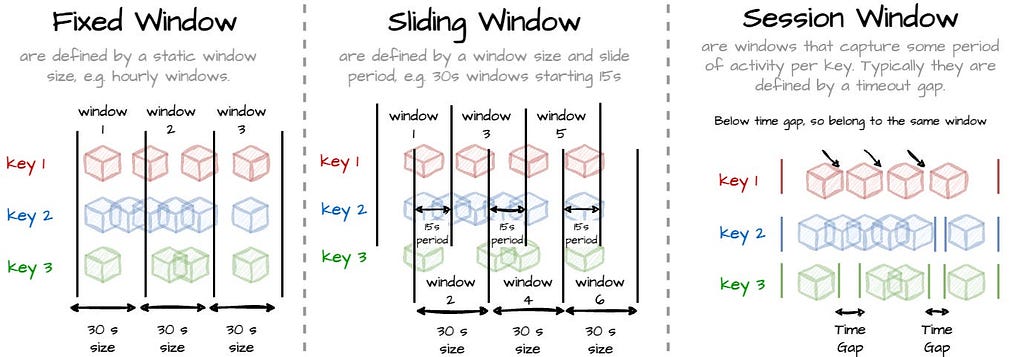
- Fixed: The windows are defined as static window size, e.g., hourly windows.
- Sliding: The windows are defined by a window size and slide period, e.g., 30-minute windows starting every five minutes.
- Sessions: The windows capture some period of activity over a subset of the data, in this case, per key. Typically, they are defined by a timeout gap.
Time Domains
When handling time-related events data, there are two domains of time to consider:
- Event Time: the time the event itself happened. For example, if the system device recorded you purchasing a game item at 11:30, this is considered the event time.
- Processing Time: The time at which an event is observed at any given point during processing. For example, the purchased game item is recorded at 11:30 but only arrives at the stream processing system at 11:35; this “11:35“ is the processing time.
Given that definition, event time will never change, but processing time changes constantly for each event as it flows through the pipeline step. This is a critical factor when analyzing events in the context of when they occurred. The difference between the event_time and the processing_time is called time domain skew. The skew can result from many potential reasons, such as communication delays or time spent processing in each pipeline stage. Metrics, such as watermarks, are good ways to visualize the skew. For the paper, the authors considered a lower watermark on event times that the pipeline has processed. These watermarks provide a notion to tell the system that: “no more data which have event time sooner this point of time will appear in the pipeline.” the watermarks are used not only to observe the skew between time domains but also to monitor the overall system. In a super-ideal world, the skew would always be zero; we could always process all events right when they happen.

In the following sections, we will learn the details of the Dataflow model.
Core primitives
The model has two core transformations that operate on the (key, value) pair; both transformations can work on bounded and unbounded data:
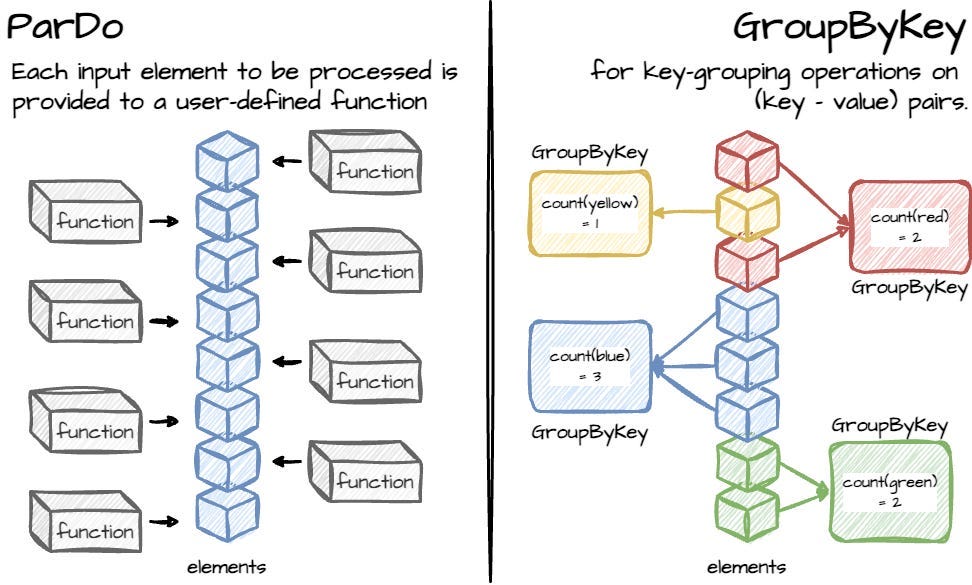
- ParDo is for generic parallel processing. It will process each input element with a provided user-defined function (called a DoFn in Dataflow), which can produce zero or more output per input element. The input doesn’t need to be the unbound collections.
- GroupByKey for grouping operations based on the defined key.
The ParDo operates on each element so it can be translated to unbounded data. The GroupByKey collects all data for a given key before sending it to the downstream steps. If the input source is unbounded, it is impossible to define when it will end. The standard solution is data windowing.
Windowing
Systems that support grouping typically redefine their GroupByKey operation to be GroupByKeyAndWindow. The authors’ significant contribution in this aspect is the unaligned window. The first is treating all windowing strategies as unaligned from the dataflow model and allowing custom adjustments to apply aligned windows when needed. The second is any windowing process can be broken apart into two related operations:
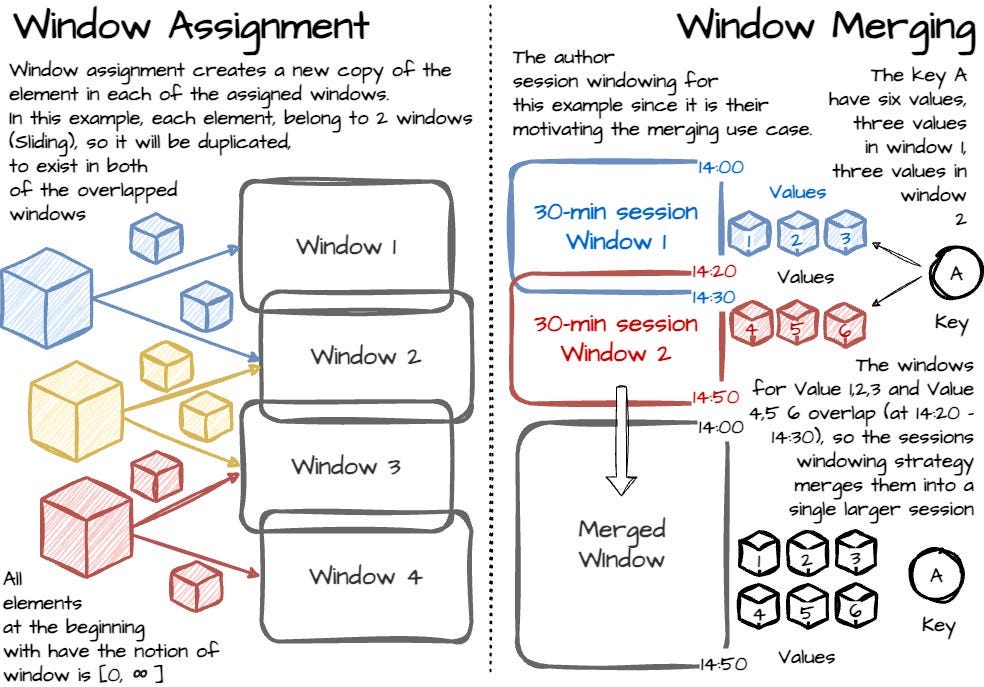
- AssignWindows assigns the element to zero or more windows. From the model’s view, window assignment creates a new copy of a component in each window.
- MergeWindows merges windows at grouping time. This allows the construction of data-driven windows over time as data arrive and are grouped. Window merging occurs as part of the GroupByKeyAndWindow operation. We see the example below for a better understanding:
Triggers & Incremental Processing
Although there is support for unaligned windows, event-time windows raised another challenge: The need to tell the system when to emit the results for a window because the data can appear in the pipeline in an unordered way. The initial solution of using event-time progress metrics like watermark (which is mentioned above) has some shortcomings:
A reminder so you don’t have to scroll up: The watermark is an indicator that tells the system that “no more data which have event time sooner this point of time will appear in the pipeline.” For example, at the given time, the watermark is “11:30”, meaning no events with event_time less than 11:30 will appear anymore.
- They are sometimes too fast: this behavior means late data may arrive behind the watermark.
- They are sometimes too slow: this behavior can cause the whole pipeline to be held back to wait for a slow data point.
This led to the observation that using only watermarks to decide when to emit the window’s result is likely to increase the latency (when the watermark is slow) or impact the accuracy of the pipeline (missing some data if the watermark is too fast ). The authors observe in the Lambda Architecture (which has two separate pipelines, streaming and batch, and the result from the two pipelines finally converge in the end) that the paradigm doesn’t solve the completeness problem by providing correct answers faster; instead, it gives the low-latency estimate of a result from the streaming pipeline, then promises to deliver the correctness result from the batch pipeline. They stated that if we want to achieve the same thing in a single pipeline, we need a mechanism to provide multiple panes (answers) for any given window. This feature, called trigger, allows the user to specify when to trigger the output results for a given window. Here is an illustration to provide you with a similar idea between the trigger and the semantics in Lambda Architecture
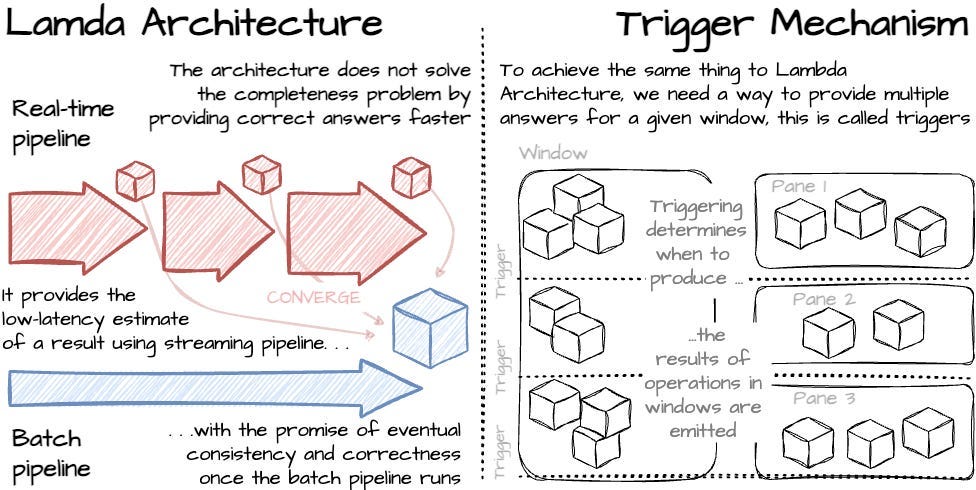
The system the authors introduce supports the following trigger implementation:
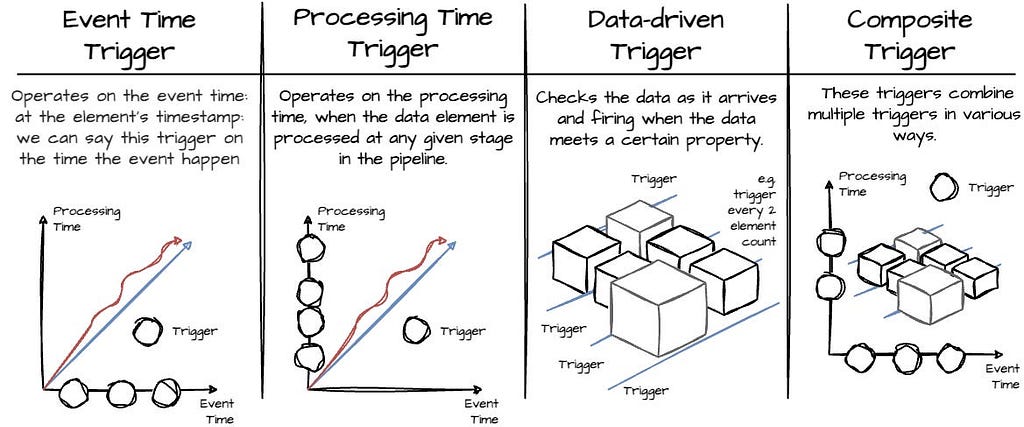
- Triggering at completion estimates such as watermarks.
- Triggering at the point in processing time.
- Triggering based on data-arriving characteristics such as counts, bytes, data punctuations, pattern matching, etc.
- Supporting the implementation combination using loops, sequences, or logical combinations (AND, OR)
- The users can define their triggers utilizing both the underlying primitives of the execution runtime (e.g., watermark timers, processing-time timers) and external signals (e.g., data injection requests, external progress metrics)
Besides controlling when the system will emit the window’s result, the trigger mechanism also provides a way to control how panes (answers) for a given window relate to each other via the following refinement modes:

- Discarding: When triggering, the system discards all content’s window. The later results have no relation to previous results. This mode is helpful in cases where the downstream consumer needs the values from various triggers to be independent. This is also the most efficient option in terms of space for buffering data.
- Accumulating: When triggering, the system keeps window contents in a persistent state; later results are related to previous results. This is useful when the downstream consumer expects to overwrite old values with new ones when receiving multiple results for the same window. It is also the mode used in Lambda Architecture systems, where the streaming pipeline outputs low-latency results, which are then overwritten later by the results from the batch pipeline.
- Accumulating & Retracting: When triggering, in addition to the Accumulating semantics, the emitted result’s copy is also stored in a persistent state. When the window triggers again in the future, a retraction for the previous value will be emitted first, followed by the new value.
The following section will describe how Google implements and designs the Dataflow model.
Implementation
The paper’s authors say they’ve implemented this model internally using FlumeJava, a Java library that makes it easy to develop, test, and run efficient data-parallel pipelines. MillWheel acts as the beneath stream execution engine. Additionally, an external reimplementation for Google Cloud Dataflow is primarily complete at the time of the paper’s writing. Interestingly, the core windowing and triggering code is quite general, and a significant portion is shared across batch and streaming implementations.
Design Principles
The core principles of the Dataflow model:
- Never rely on any notion of completeness.
- Be flexible to accommodate the diversity of known use cases and those to come in the future.
- It not only makes sense but also adds value in the context of each of the envisioned execution engines.
- Encourage clarity of implementation.
- Support robust analysis of data in the context in which they occurred.
Motivating Experiences
As they designed the Model, they gained real-world experiences with FlumeJava and MillWheel. Things that worked well would be reflected in the model; things that were less well would motivate changes in approach. Here are some of their experiences that influenced the design choice:
- Unified Model: The original motivation for this design choice is that one huge pipeline runs in streaming mode on MillWheel by default but with a dedicated FlumeJava batch implementation for large-scale backfills. Another motivation came from an experience with Lambda Architecture, where one customer ran the streaming pipeline in MillWheel with a nightly MapReduce (batch) to generate truth. They found that customers stopped trusting the weakly consistent results between pipelines over time.
- Sessions are a critical use case within Google. This mechanism is used in many cases, including search, ads, analytics, social media, and YouTube. Any users who care about correlating bursts of user activity over a period of time would leverage sessions. Thus, support for sessions became an indispensable part of the model’s design.
- Triggers, Accumulation, & Retraction: Two teams with billing pipelines running on MillWheel had problems that motivated parts of the model. The best practice at the time was to use the watermark as a completion metric, with extra ad hoc logic for late data. Lacking a system for updates and retractions, a team that processed resource utilization statistics decided to build their own solution. Another billing team had significant issues with watermark lags caused by stragglers (slow-running units affect overall job performance completion.) in the input. These shortcomings became significant motivators in the design and shifted the focus from targeting completeness to adaptability over time. This results in two decisions: triggers, which allow the flexible specification of when results are materialized, and incremental processing support via accumulation.
- Watermark Triggers: Many MillWheel pipelines calculate aggregate statistics. Most do not require 100% accuracy; they care about having a mostly complete view of their data in a reasonable amount of time. Given the high level of accuracy that they achieve with watermarks for structured input sources like log files, customers find watermarks very effective in triggering a single, highly accurate aggregate per window.
- Processing Time Triggers: The recommendation pipelines emit their output using processing-time timers. These systems, having regularly updated, partial views of the data, were much more valuable than waiting until mostly complete views were ready based on the watermark. This also meant that the notion of a watermark would not affect the timeliness of output for the rest of the data.
- Data-Driven & Composite Triggers: The different detection systems in the anomaly detection pipeline used to track trends in Google web search motivated the data-driven triggers. These differences observe the stream of queries and calculate statistical estimates to check whether a spike exists. When they believe a spike is happening, they emit a start record; when they think it has ceased, they emit a stop. It was also a motivating case for trigger composition because, in reality, the system runs multiple differs simultaneously, multiplexing the output according to a set of logic.
Outro
In this week’s blog, we’ve discussed the design principle and implementation of the Dataflow model, the backbone behind the famous Google Cloud Dataflow service. If you want to dive deeper into the model, I highly recommend the book Streaming Systems: The What, Where, When, and How of Large-Scale Data Processing or the two-part blog from one of the paper’s authors: Streaming 101 and Streaming 102. I hope my work brings some value, especially to someone who wants to learn more about the stream processing world.
See you next blog!
References
[1] Google, The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data (2015).
My newsletter is a weekly blog-style email in which I note things I learn from people smarter than me.
So, if you want to learn and grow with me, subscribe here: https://vutr.substack.com.
The Stream Processing Model Behind Google Cloud Dataflow was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
The Stream Processing Model Behind Google Cloud Dataflow
Go Here to Read this Fast! The Stream Processing Model Behind Google Cloud Dataflow