

Syntax, use cases and expert tips for mastering advanced SQL
As an experienced data professional working in the tech industry for many years, I have processed tons of large datasets. SQL is the most frequently used tool for data manipulation, data query, and analysis. Although mastering basic and intermediate SQL is relatively easy, achieving mastery of this tool and wielding it adeptly in diverse scenarios is sometimes challenging. There are a few advanced SQL techniques that you must be familiar with if you want to work for top tech companies. Today, I’ll share the most useful advanced SQL techniques that you’ll undoubtedly use in your work. To help you understand them better, I’ll create some use cases and use mock data to explain the scenarios in which to use them and how to use them. For each use case, programming code will also be provided.
Window Functions
Window functions perform calculations across a specified set of rows, known as a “window”, from a query and return a single value related to the current row.
We’d like to use the sales data from a promotion at Star Department Store to explain window functions. The table contains three columns: Sale_Person_ID, which is the ID unique for each sales person, Department, where the sales person is from, and Sales_Amount, which is the sales performance of each person during the promotion. The management of Star Department Store wants to see the subtotal sales amount for each department. The task for you is to add a column, dept_total, to the table.
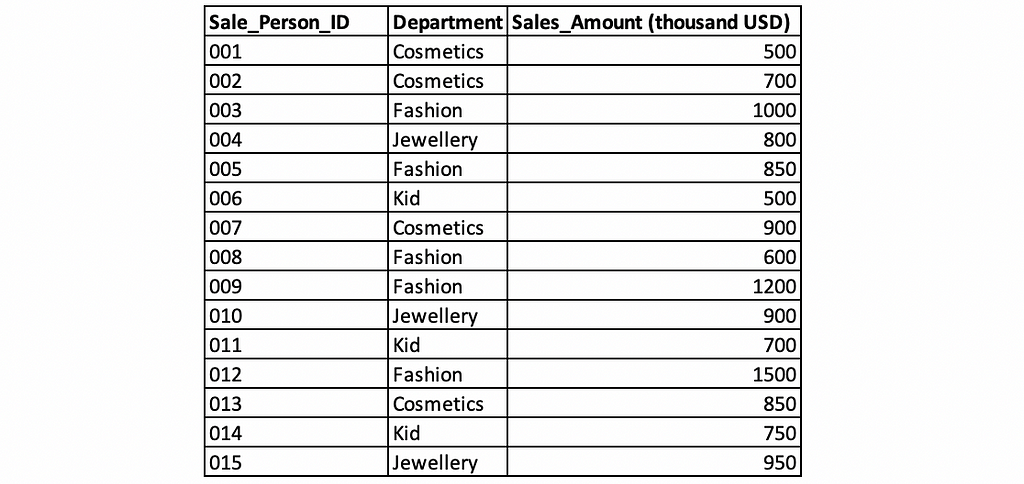
Firstly, we create a table promo_sales with the 3 columns in the Database.
CREATE TABLE promo_sales(
Sale_Person_ID VARCHAR(40) PRIMARY KEY,
Department VARCHAR(40),
Sales_Amount int
);
INSERT INTO promo_sales VALUES (001, 'Cosmetics', 500);
INSERT INTO promo_sales VALUES (002, 'Cosmetics', 700);
INSERT INTO promo_sales VALUES (003, 'Fashion', 1000);
INSERT INTO promo_sales VALUES (004, 'Jewellery', 800);
INSERT INTO promo_sales VALUES (005, 'Fashion', 850);
INSERT INTO promo_sales VALUES (006, 'Kid', 500);
INSERT INTO promo_sales VALUES (007, 'Cosmetics', 900);
INSERT INTO promo_sales VALUES (008, 'Fashion', 600);
INSERT INTO promo_sales VALUES (009, 'Fashion', 1200);
INSERT INTO promo_sales VALUES (010, 'Jewellery', 900);
INSERT INTO promo_sales VALUES (011, 'Kid', 700);
INSERT INTO promo_sales VALUES (012, 'Fashion', 1500);
INSERT INTO promo_sales VALUES (013, 'Cosmetics', 850);
INSERT INTO promo_sales VALUES (014, 'Kid', 750);
INSERT INTO promo_sales VALUES (015, 'Jewellery', 950);
Next, we need to calculate the subtotal sales amount for each department and add a column, dept_total, to the table promo_sales. Without using window functions, we would create another table, named department_total, using a “GROUP BY” clause to get the sales amount for each department. Then, we would join the tables promo_sales and department_total. Window functions provide a powerful way to perform this calculation within a single SQL query, simplifying and optimizing the data processing task.
We can use SUM() function to complete the task.
SELECT
Sale_Person_ID,
Department,
Sales_Amount,
SUM(Sales_Amount) OVER (PARTITION BY Department) AS dept_total
FROM
promo_sales;
Thereafter, the table promo_sales has one additional column dept_total as expected.
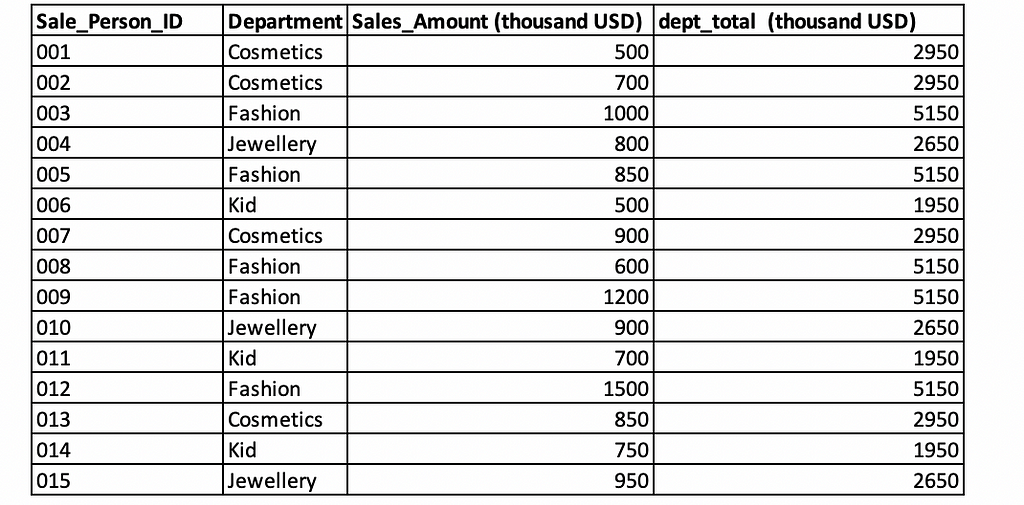
This example illustrates that window functions do not reduce the number of rows in the result set, unlike aggregate functions used with GROUP BY. Window functions can perform calculations such as running totals, averages, and counts, and they can also be used for operations like ranking and more. Now, let’s move on to the next example.
The management of Star Department Store also wants to rank the sales persons by their performance during the promotion within each department. This time we can use RANK() to rank the sales persons.
SELECT
Sale_Person_ID,
Department,
Sales_Amount,
RANK() OVER (PARTITION BY Department ORDER BY Sales_Amount DESC) AS Rank_in_Dept
FROM
promo_sales;
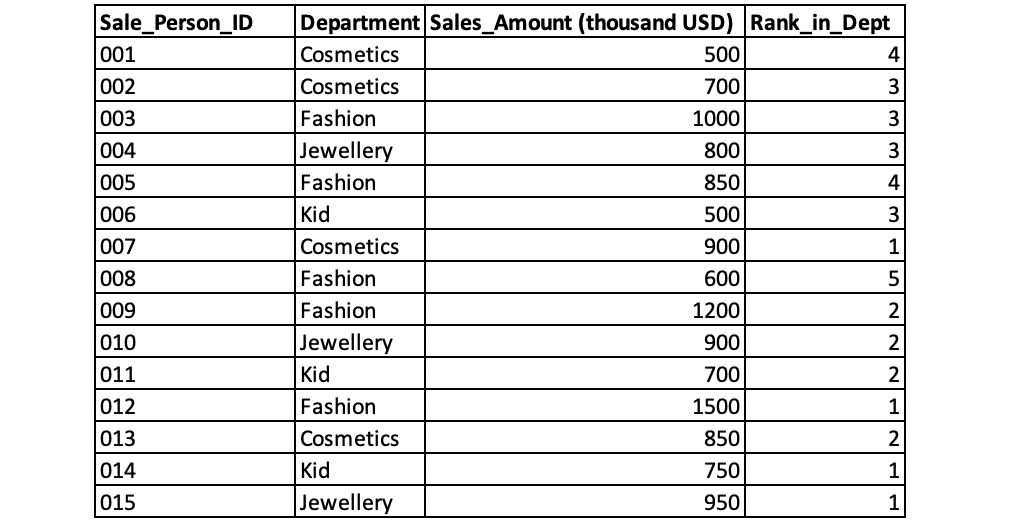
Window functions are widely used in data analysis. Common types of window functions include ranking functions, aggregate functions, offset functions and distribution functions.
1. Ranking Functions: Ranking functions assign a rank or row number to each row within a partition of a result set.
· ROW_NUMBER(): Assigns unique sequential integers to rows
· RANK(): Assigns rank with gaps for ties
· DENSE_RANK(): Assigns rank without gaps for ties
· NTILE(n): Divides rows into n approximately equal groups
2. Aggregate Functions: Aggregate functions are used to perform calculation or run statistics across a set of rows related to the current row.
· SUM (): Calculate the total value within a partition
· AVG(): Calculate the mean value within a partition
· COUNT(): Get the count of elements within a partition
· MAX(): Get the largest value within a partition
· MIN(): Get the smallest value within a partition
3. Offset Functions: Offset functions allow access to data from other rows in relation to the current row. They are used when you need to compare values between rows or when you run time-series analysis or trend detection.
· LAG(): Access data from a previous row
· LEAD(): Access data from a subsequent row
· FIRST_VALUE(): Get first value in an ordered set
· LAST_VALUE(): Get last value in an ordered set
4. Distribution Functions: Distribution functions calculate the relative position of a value within a group of values and also help you understand the distribution of values.
· PERCENT_RANK(): Calculates the percentile rank of a row
· CUME_DIST(): Calculates the cumulative distribution of a value
· PERCENTILE_CONT(): Calculates a continuous percentile value
· PERCENTILE_DISC(): Calculates a discrete percentile value
Subqueries
A subquery, also known as a nested query or inner query, is a query within another SQL query. It can be used to generate a new column, a new table or some conditions to further restrict the data to be retrieved in the main query.
Let’s continue to use the data table promo_sales from Star Department Store for demonstration.
- Subquery for new column generation
This time we’d like to add a new column to show the difference between each sales person’s sales amount and the department average.
SELECT
Sale_Person_ID,
Department,
Sales_Amount,
Sales_Amount - (SELECT AVG(Sales_Amount) OVER (PARTITION BY Department) FROM promo_sales) AS sales_diff
FROM
promo_sales;
2. Subquery to create a new table
The table mkt_cost contains the advertising costs for all departments during this promotion. To determine which department is the most cost-efficient, we need to calculate the return on advertising spend for each department. We can use a subquery to create a new table that includes the total sales amounts and marketing costs for these departments, and then analyze the data in this new table.
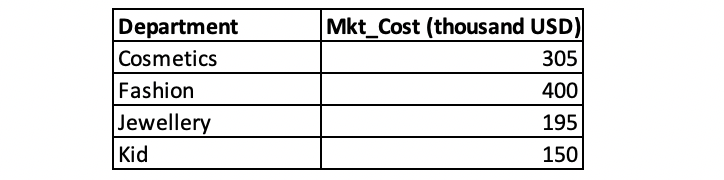
SELECT
Department,
dept_ttl,
Mkt_Cost,
dept_ttl/Mkt_Cost AS ROAS
FROM
(SELECT
s.Department,
SUM(s.Sales_Amount) AS dept_ttl,
c.Mkt_Cost
FROM
promo_sales s
GROUP BY s.Department
LEFT JOIN
mkt_cost c
ON s.Department=c.Department
)
3. Subquery to create restrictive conditions
The subquery can also be used to select sales persons whose sales amount exceeded the average amount of all sales persons.
SELECT
Sale_Person_ID,
Department,
Sales_Amount
FROM
promo_sales
WHERE
Sales_Amount > (SELECT AVG(salary) FROM promo_sales);
Besides the 3 types of subqueries above, there’s one frequently-used subquery — correlated subquery, which depends on the outer query for its values. It’s executed once for each row in the outer query.
Correlated subquery can be used to find the sales persons whose sales performance were above the average of their department during the promotion.
SELECT
ps_1.Sale_Person_ID,
ps_1.Department,
ps_1.Sales_Amount
FROM
promo_sales ps_1
WHERE
ps_1.Sales_Amount > (
SELECT AVG(ps_2.Sales_Amount)
FROM promo_sales ps_2
WHERE ps_2.Department = ps_1.Department
);
Subqueries allow you to write complex queries that answer sophisticated questions about your data. But it’s important to use them judiciously, as overuse can lead to performance issues, especially with large datasets.
Common Table Expressions
A Common Table Expression (CTE) is a named temporary result set that exists within the scope of a single SQL statement. CTEs are defined using a WITH clause and can be referenced one or more times in a subsequent SELECT, INSERT, UPDATE, DELETE, or MERGE statement.
There are primarily two types of CTEs in SQL:
- Non-recursive CTEs: Non-recursive CTEs are used to simplify complex queries through breaking them down into more manageable parts. They don’t reference themselves so they are the simplest type of CTEs.
- Recursive CTEs: Recursive CTEs references themselves within their definitions, allowing you to work with hierarchical or tree-structure data.
Now, let’s use the non-recursive CTEs to work with data table promo_sales. The task is to calculate the average sales amount from each department and compare it with the store average during the promotion.
WITH dept_avg AS (
SELECT
Department,
AVG(Sales_Amount) AS dept_avg
FROM
promo_sales
GROUP BY
Department
),
store_avg AS (
SELECT AVG(Sales_Amount) AS store_avg
FROM promo_sales
)
SELECT
d.Department,
d.dept_avg,
s.store_avg,
d.dept_avg - s.store_avg AS diff
FROM
dept_avg d
CROSS JOIN
store_avg s;
Since recursive CTEs can deal with hierarchical data, we are trying to generate a sequence of numbers from 1 to 10.
WITH RECURSIVE sequence_by_10(n) AS (
SELECT 1
UNION ALL
SELECT n + 1
FROM sequence_by_10
WHERE n < 10
)
SELECT n FROM sequence_by_10;
CTEs are powerful because they improve the readability and maintainability of complex queries by simplifying them. They’re especially useful when you need to reference the same subquery multiple times in the main query or when you’re working with recursive structures.
Conclusion
The three advanced SQL techniques can significantly enhance your data manipulation and analysis capabilities. Window functions allow you to perform complex calculations across sets of rows while maintaining the context of individual records. Subqueries enable you to write complex queries to answer sophisticated questions about your data. CTEs offer a powerful way to structure and simplify your SQL queries, making them more readable and maintainable. By integrating these advanced techniques into your SQL toolkit, you should be able to upgrade your SQL skills to tackle complicated data challenges, deliver valuable insights or generate story-telling dashboard in your role as a data professional.
The Most Useful Advanced SQL Techniques to Succeed in the Tech Industry was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
The Most Useful Advanced SQL Techniques to Succeed in the Tech Industry
Go Here to Read this Fast! The Most Useful Advanced SQL Techniques to Succeed in the Tech Industry