Dive into Neural Networks, the backbone of modern AI, understand its mathematics, implement it from scratch, and explore its applications

Neural networks are at the core of artificial intelligence (AI), fueling a variety of applications from spotting objects in photos to translating languages. In this article, we’ll dive into what neural networks are, how they work, and why they’re a big deal in our technology-driven world today.
Index
· 1: Understanding the Basics
∘ 1.1: What are Neural Networks?
∘ 1.2: Types of Neural Networks
· 2: The Architecture of Neural Networks
∘ 2.1: The Structure of a Neuron
∘ 2.2: Layers
∘ 2.3: The Role of Layers in Learning
· 3: The Mathematics of Neural Networks
∘ 3.1: Weighted Sum
∘ 3.2: Activation Functions
∘ 3.3: Backpropagation: The Core of Neural Learning
∘ 3.4: Step by Step example
∘ 3.5: Improvements
· 4: Implementing Neural Networks
∘ 4.1: Building a Simple Neural Network in Python
∘ 4.2: Utilizing Libraries for Neural Network Implementation (TensorFlow)
· 5: Challenges
∘ 5.1: Overcoming Overfitting
1: Understanding the Basics
1.1: What are Neural Networks?
Neural networks are a cool blend of biology and computer science, inspired by our brain’s setup to tackle complicated computing tasks. Essentially, they’re algorithms designed to spot patterns and make sense of sensory data, which lets them do a ton of stuff like recognizing faces, understanding spoken words, making predictions, and understanding natural language.
The Biological Inspiration

Our brains have about 86 billion neurons, all linked up in a complex network. These neurons chat through connections called synapses, where signals can get stronger or weaker, influencing the message passed along. This is the foundation of how we learn and remember things.
Artificial neural networks take a page from this book, using digital neurons or nodes that connect in layers. You’ve got input layers that take in data, hidden layers that chew on this data, and output layers that spit out the result. As the network gets fed more data, it adjusts the connection strengths (or “weights”) to learn, kind of like how our brain’s synapses strengthen or weaken.
From Perceptrons to Deep Learning
Neural networks started with something called a perceptron in 1958, thanks to Frank Rosenblatt. This was a basic neural network meant for simple yes-or-no-type tasks. From there, we built more complex networks, like multi-layer perceptrons (MLPs), which can understand more complicated data relationships thanks to having one or more hidden layers.
Then came deep learning, which is all about neural networks with lots of layers. These deep neural networks are capable of learning from huge piles of data, and they’re behind a lot of the AI breakthroughs we hear about, from beating human Go players to powering self-driving cars.
Understanding Through Patterns
One of the biggest strengths of neural networks is their ability to learn patterns in data without being directly programmed for specific tasks. This process, called “training,” lets neural networks pick up on general trends and make predictions or decisions based on what they’ve learned.
Thanks to this capability, neural networks are super versatile and can be used for a wide array of applications, from image recognition to language translation, to forecasting stock market trends. They’re proving that tasks once thought to require human intelligence can now be tackled by AI.
1.2: Types of Neural Networks
Before diving into their structure and math, let’s take a look at the most popular types of Neural Networks we may find today. This will give us a better understanding of their potential and capabilities. I will try to cover all of them in future articles, so make sure to subscribe!
Feedforward Neural Networks (FNN)
Starting with the basics, the Feedforward Neural Network is the simplest type. It’s like a one-way street for data — information travels straight from the input, through any hidden layers, and out the other side to the output. These networks are the go-to for simple predictions and sorting things into categories.
Convolutional Neural Networks (CNN)
CNNs are the big guns in the world of computer vision. They’ve got a knack for picking up on the spatial patterns in images, thanks to their specialized layers. This ability makes them stars at recognizing images, spotting objects within them, and classifying what they see. They’re the reason your phone can tell a dog from a cat in photos.
Recurrent Neural Networks (RNN)
RNNs have a memory of sorts, making them great for anything involving sequences of data, like sentences, DNA sequences, handwriting, or stock market trends. They loop information back around, allowing them to remember previous inputs in the sequence. This makes them ace at tasks like predicting the next word in a sentence or understanding spoken language.
Long Short-Term Memory Networks (LSTM)
LSTMs are a special breed of RNNs built to remember things for longer stretches. They’re designed to solve the problem of RNNs forgetting stuff over long sequences. If you’re dealing with complex tasks that need to hold onto information for a long time, like translating paragraphs or predicting what happens next in a TV series, LSTMs are your go-to.
Generative Adversarial Networks (GAN)
Imagine two AIs in a cat-and-mouse game: one generates fake data (like images), and the other tries to catch what’s fake and what’s real. That’s a GAN. This setup allows GANs to create incredibly realistic images, music, text, and more. They’re the artists of the neural network world, generating new, realistic data from scratch.
2: The Architecture of Neural Networks
At the core of neural networks are what we call neurons or nodes, inspired by the nerve cells in our brains. These artificial neurons are the workhorses that handle the heavy lifting of receiving, crunching, and passing along information. Let’s dive into how these neurons are built.
2.1: The Structure of a Neuron
A neuron gets its input either directly from the data we’re interested in or from the outputs of other neurons. These inputs are like a list, with each item on the list representing a different characteristic of the data.
For each input, the neuron does a little math: it multiplies the input by a “weight” and then adds a “bias.” Think of weights as the neuron’s way of deciding how important an input is, and bias as a tweak to make sure the neuron’s output fits just right. During the network’s training, it adjusts these weights and biases to get better at its job.
Next, the neuron sums up all these weighted inputs and biases and runs the total through a special function called an activation function. This step is where the magic happens, allowing the neuron to tackle complex patterns by bending and stretching the data in nonlinear ways. Popular choices for this function are ReLU, Sigmoid, and Tanh, each with its way of tweaking the data.
2.2: Layers

Neural networks are structured in layers, sort of like a layered cake, with each layer made up of multiple neurons. The way these layers stack up forms the network’s architecture:
Input Layer
This is where the data enters the network. Each neuron here corresponds to one feature of the data. In the image above the input layer is the first layer on the left holding two nodes.
Hidden Layers
These are the layers sandwiched between the input and output, as we can see from the image above. You might have just one or a bunch of these hidden layers, doing the grunt work of computations and transformations. The more layers (and neurons in each layer) you have, the more intricate patterns the network can learn. But, this also means more computing power is needed and a higher chance of the network getting too caught up in the training data, a problem known as overfitting.
Output Layer
This is the network’s final stop, where it spits out the results. Depending on the task, like if it’s classifying data, this layer might have a neuron for each category, using something like the softmax function to give probabilities for each category. In the image above, the last layer holds only one node, suggesting that the is used for a regression task.
2.3: The Role of Layers in Learning
The hidden layers are the network’s feature detectives. As data moves through these layers, the network gets better at spotting and combining input features, layering them into a more complex understanding of the data.
With each layer the data passes through, the network can pick up on more intricate patterns. Early layers might learn basic stuff like shapes or textures, while deeper layers get the hang of more complex ideas, like recognizing objects or faces in pictures.
3: The Mathematics of Neural Networks
3.1: Weighted Sum
The first step in the neural computation process involves aggregating the inputs to a neuron, each multiplied by their respective weights, and then adding a bias term. This operation is known as the weighted sum or linear combination. Mathematically, it is expressed as:

where:
- z is the weighted sum,
- wi represents the weight associated with the i-th input,
- xi is the i-th input to the neuron,
- b is the bias term, a unique parameter that allows adjusting the output along with the weighted sum.
The weighted sum is crucial because it constitutes the raw input signal to a neuron before any non-linear transformation. It allows the network to perform a linear transformation of the inputs, adjusting the importance (weight) of each input in the neuron’s output.
3.2: Activation Functions
As we said before, activation functions play a pivotal role in determining the output of a neural network. They are mathematical equations that determine whether a neuron should be activated or not. Activation functions introduce non-linear properties to the network, enabling it to learn complex data patterns and perform tasks beyond mere linear classification, which is essential for deep learning models. Here, we delve into several key types of activation functions and their significance:
Sigmoid Activation Function
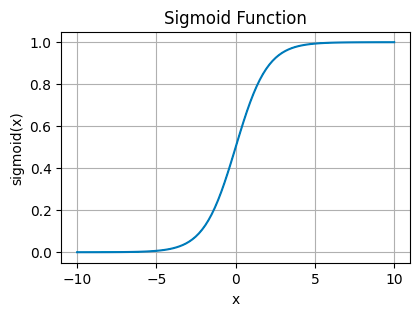
This function squeezes its input into a narrow range between 0 and 1. It’s like taking any value, no matter how large or small, and translating it into a probability.

You’ll see sigmoid functions in the final layer of binary classification networks, where you need to decide between two options — yes or no, true or false, 1 or 0.
Hyperbolic Tangent Function (tanh)
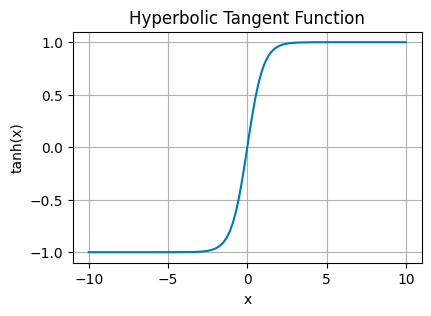
tanh stretches the output range to between -1 and 1. This centers the data around 0, making it easier for layers down the line to learn from it.
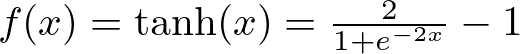
It’s often found in the hidden layers, helping to model more complex data relationships by balancing the input signal.
Rectified Linear Unit (ReLU)

ReLU is like a gatekeeper that passes positive values unchanged but blocks negatives, turning them to zero. This simplicity makes it very efficient and helps overcome some tricky problems in training deep neural networks.

Its simplicity and efficiency have made ReLU incredibly popular, especially in convolutional neural networks (CNNs) and deep learning models.
Leaky Rectified Linear Unit (Leaky ReLU)

Leaky ReLU allows a tiny, non-zero gradient when the input is less than zero, which keeps neurons alive and kicking even when they’re not actively firing.

It’s a tweak to ReLU used in cases where the network might suffer from “dead neurons,” ensuring all parts of the network stay active over time.
Exponential Linear Unit (ELU)

ELU smooths out the function for negative inputs (using a parameter α for scaling), allowing for negative outputs but with a gentle curve. This can help the network maintain a mean activation closer to zero, improving learning dynamics.
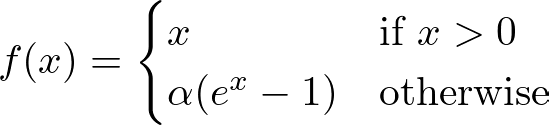
Useful in deeper networks where ReLU’s sharp threshold could slow down learning.
Softmax Function
The softmax function turns logits, the raw output scores from the neurons, into probabilities by exponentiating and normalizing them. It ensures that the output values sum up to one, making them directly interpretable as probabilities.

It’s the go-to for the output layer in multi-class classification problems, where each neuron corresponds to a different class, and you want to pick the most likely one.
3.3: Backpropagation: The Core of Neural Learning
Backpropagation, short for “backward propagation of errors,” is a method for efficiently calculating the gradient of the loss function concerning all weights in the network. It consists of two main phases: a forward pass, where the input data is passed through the network to generate an output, and a backward pass, where the output is compared to the target value, and the error is propagated back through the network to update the weights.
The essence of backpropagation is the chain rule of calculus, which is used to calculate the gradients of the loss function for each weight by multiplying the gradients of the layers behind it. This process reveals how much each weight contributes to the error, providing a clear path for its adjustment.
The chain rule for backpropagation can be represented as follows:

where:
- ∂a/∂L is the gradient of the loss function to the activation,
- ∂z/∂a is the gradient of the activation function to the weighted input z,
- ∂w/∂z is the gradient of the weighted input to the weight w,
- z represents the weighted sum of inputs and a is the activation.
Gradient Descent: Optimizing the Weights
Gradient Descent is an optimization algorithm used for minimizing the loss function in a neural network. It works by iteratively moving the weights in the direction of the steepest decrease in loss. The amount by which the weights are adjusted in each iteration is determined by the learning rate, a hyperparameter that controls the size of the steps.
Mathematically, the weight update rule in gradient descent can be expressed as:

where:
- w-new and w-old represent the updated (new) and current (old) values of the weight, respectively,
- η is the learning rate, a hyperparameter that controls the size of the step taken in the direction of the negative gradient,
- ∂w/∂L is the gradient of the loss function for the weight.
In practice, backpropagation and gradient descent are performed in tandem. Backpropagation computes the gradient (the direction and magnitude of the error) for each weight in the network, and gradient descent uses this information to update the weights to minimize the loss. This iterative process continues until the model converges to a state where the loss is minimized or a criterion is met.
3.4: Step by Step example
Let’s explore an example involving backpropagation and gradient descent in a simple neural network. This neural network will have a single hidden layer. We’ll work through a single iteration of training with one data point to understand how these processes update the network’s weights.
Network Structure:
- Inputs: x1, x2 (2-dimensional input vector)
- Hidden Layer: 2 neurons, with activation function f(z)=ReLU(z)=max(0,z)
- Output Layer: 1 neuron, with activation function g(z)=σ(z)=1+e−z1 (Sigmoid function for binary classification)
- Loss Function: Binary Cross-Entropy Loss.
Forward Pass
Given inputs x1, x2, weights w, and biases b, the forward pass calculates the network’s output. The process for a single hidden layer network with ReLU activation in the hidden layer and a sigmoid activation in the output layer is as follows:
1: Input to Hidden Layer
Let the initial weights from the input to the hidden layer be w11, w12, w21, w22, and the biases be b1, b2 for the two hidden neurons, respectively.
Given an input vector [x1, x2], the weighted sum for each neuron in the hidden layer is:
Applying the ReLU activation function:

1.2: Hidden Layer to Output:
Let the weights from the hidden layer to the output neuron be w31, w32, and the bias be b3.
The weighted sum at the output neuron is:
Applying the Sigmoid activation function for the output:
Loss Calculation (Binary Cross-Entropy):
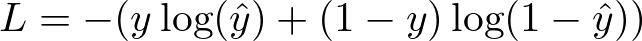
Backward Pass (Backpropagation):
Now things get a bit more complex, as we need to calculate the gradient on the formulas we applied in the forward pass.
Output Layer Gradients
Let’s start with the output layer. The derivative of the loss function for z3 is:
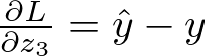
The gradients of the loss for weights and bias of the output layer:
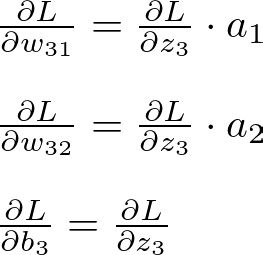
Hidden Layer Gradients
The gradients of the loss for the hidden layer activations (chain rule applied):
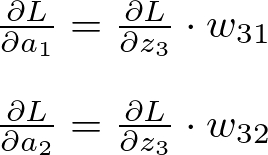
The gradients of the loss concerning weights and biases of the hidden layer:
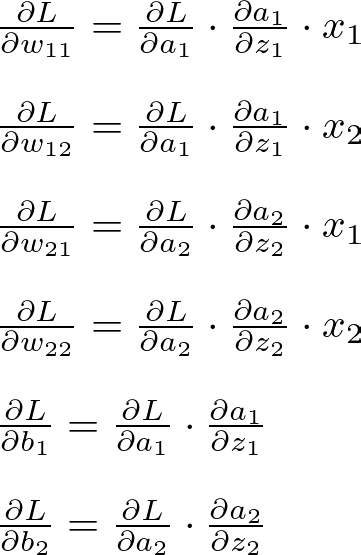
These steps are then repeated until a criterion is met, such as a maximum number of epochs.
3.5: Improvements
While the basic idea of Gradient Descent is simple — take small steps in the direction that reduces error the most — several tweaks and improvements have been made to this method to enhance its efficiency and effectiveness.
Stochastic Gradient Descent (SGD)
Stochastic Gradient Descent (SGD) takes the core idea of gradient descent but changes the approach by using just one training example at a time to calculate the gradient and update the weights. This method is similar to making decisions based on quick, individual observations rather than waiting to gather everyone’s opinion. It can make the learning process much faster because the model updates more frequently and with less computational burden.
To learn more about SGD look at this article:
Stochastic Gradient Descent: Math and Python Code
Adam (Adaptive Moment Estimation)
Adam, short for Adaptive Moment Estimation, is like the wise advisor to SGD’s youthful energy. It takes the concept of adjusting weights based on the data’s gradient but does so with a more sophisticated, personalized approach for each parameter in the model. Adam combines ideas from two other gradient descent improvements, AdaGrad and RMSProp, to adapt the learning rate for each weight in the network based on the first (mean) and second (uncentered variance) moments of the gradients.
Learn more about Adam Optimizer here:
The Math behind Adam Optimizer
4: Implementing Neural Networks
4.1: Building a Simple Neural Network in Python
Let’s finally recreate a neural network from scratch. For better readability, I will divide the code into 4 parts: NeuralNetwork class, Trainer class, and implementation.
You can find the whole code on this Jupyter Notebook. The notebook contains a fine-tuning bonus that will likely increase the performance of the Neural Network:
NeuralNetwork Class
Let’s start with the NN class, which defines the architecture of our Neural Network:
import numpy as np
class NeuralNetwork:
"""
A simple neural network with one hidden layer.
Parameters:
-----------
input_size: int
The number of input features
hidden_size: int
The number of neurons in the hidden layer
output_size: int
The number of neurons in the output layer
loss_func: str
The loss function to use. Options are 'mse' for mean squared error, 'log_loss' for logistic loss, and 'categorical_crossentropy' for categorical crossentropy.
"""
def __init__(self, input_size, hidden_size, output_size, loss_func='mse'):
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.loss_func = loss_func
# Initialize weights and biases
self.weights1 = np.random.randn(self.input_size, self.hidden_size)
self.bias1 = np.zeros((1, self.hidden_size))
self.weights2 = np.random.randn(self.hidden_size, self.output_size)
self.bias2 = np.zeros((1, self.output_size))
# track loss
self.train_loss = []
self.test_loss = []
def forward(self, X):
"""
Perform forward propagation.
Parameters:
-----------
X: numpy array
The input data
Returns:
--------
numpy array
The predicted output
"""
# Perform forward propagation
self.z1 = np.dot(X, self.weights1) + self.bias1
self.a1 = self.sigmoid(self.z1)
self.z2 = np.dot(self.a1, self.weights2) + self.bias2
if self.loss_func == 'categorical_crossentropy':
self.a2 = self.softmax(self.z2)
else:
self.a2 = self.sigmoid(self.z2)
return self.a2
def backward(self, X, y, learning_rate):
"""
Perform backpropagation.
Parameters:
-----------
X: numpy array
The input data
y: numpy array
The target output
learning_rate: float
The learning rate
"""
# Perform backpropagation
m = X.shape[0]
# Calculate gradients
if self.loss_func == 'mse':
self.dz2 = self.a2 - y
elif self.loss_func == 'log_loss':
self.dz2 = -(y/self.a2 - (1-y)/(1-self.a2))
elif self.loss_func == 'categorical_crossentropy':
self.dz2 = self.a2 - y
else:
raise ValueError('Invalid loss function')
self.dw2 = (1 / m) * np.dot(self.a1.T, self.dz2)
self.db2 = (1 / m) * np.sum(self.dz2, axis=0, keepdims=True)
self.dz1 = np.dot(self.dz2, self.weights2.T) * self.sigmoid_derivative(self.a1)
self.dw1 = (1 / m) * np.dot(X.T, self.dz1)
self.db1 = (1 / m) * np.sum(self.dz1, axis=0, keepdims=True)
# Update weights and biases
self.weights2 -= learning_rate * self.dw2
self.bias2 -= learning_rate * self.db2
self.weights1 -= learning_rate * self.dw1
self.bias1 -= learning_rate * self.db1
def sigmoid(self, x):
"""
Sigmoid activation function.
Parameters:
-----------
x: numpy array
The input data
Returns:
--------
numpy array
The output of the sigmoid function
"""
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(self, x):
"""
Derivative of the sigmoid activation function.
Parameters:
-----------
x: numpy array
The input data
Returns:
--------
numpy array
The output of the derivative of the sigmoid function
"""
return x * (1 - x)
def softmax(self, x):
"""
Softmax activation function.
Parameters:
-----------
x: numpy array
The input data
Returns:
--------
numpy array
The output of the softmax function
"""
exps = np.exp(x - np.max(x, axis=1, keepdims=True))
return exps/np.sum(exps, axis=1, keepdims=True)
Initialization
def __init__(self, input_size, hidden_size, output_size, loss_func='mse'):
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.loss_func = loss_func
# Initialize weights and biases
self.weights1 = np.random.randn(self.input_size, self.hidden_size)
self.bias1 = np.zeros((1, self.hidden_size))
self.weights2 = np.random.randn(self.hidden_size, self.output_size)
self.bias2 = np.zeros((1, self.output_size))
# track loss
self.train_loss = []
self.test_loss = []
The __init__ method initializes a new instance of the NeuralNetwork class. It takes the size of the input layer (input_size), the hidden layer (hidden_size), and the output layer (output_size) as arguments, along with the type of loss function to use (loss_func), which defaults to mean squared error (‘mse’).
Inside this method, the network’s weights and biases are initialized. weights1 connects the input layer to the hidden layer, and weights2 connects the hidden layer to the output layer. The biases (bias1 and bias2) are initialized to zero arrays. This initialization uses random numbers for weights to break symmetry and zeros for biases as a starting point.
It also initializes two lists, train_loss and test_loss, to track the loss during the training and testing phases, respectively.
Forward Propagation (forward method)
def forward(self, X):
# Perform forward propagation
self.z1 = np.dot(X, self.weights1) + self.bias1
self.a1 = self.sigmoid(self.z1)
self.z2 = np.dot(self.a1, self.weights2) + self.bias2
if self.loss_func == 'categorical_crossentropy':
self.a2 = self.softmax(self.z2)
else:
self.a2 = self.sigmoid(self.z2)
return self.a2
The forward method takes the input data X and passes it through the network. It calculates the weighted sums (z1, z2) and applies the activation function (sigmoid or softmax, depending on the loss function) to these sums to get the activations (a1, a2).
For the hidden layer, it always uses the sigmoid activation function. For the output layer, it uses softmax if the loss function is ‘categorical_crossentropy’ and sigmoid otherwise. The choice between sigmoid and softmax depends on the nature of the task (binary/multi-class classification).
This method returns the final output (a2) of the network, which can be used to make predictions.
Backpropagation (backward method)
def backward(self, X, y, learning_rate):
# Perform backpropagation
m = X.shape[0]
# Calculate gradients
if self.loss_func == 'mse':
self.dz2 = self.a2 - y
elif self.loss_func == 'log_loss':
self.dz2 = -(y/self.a2 - (1-y)/(1-self.a2))
elif self.loss_func == 'categorical_crossentropy':
self.dz2 = self.a2 - y
else:
raise ValueError('Invalid loss function')
self.dw2 = (1 / m) * np.dot(self.a1.T, self.dz2)
self.db2 = (1 / m) * np.sum(self.dz2, axis=0, keepdims=True)
self.dz1 = np.dot(self.dz2, self.weights2.T) * self.sigmoid_derivative(self.a1)
self.dw1 = (1 / m) * np.dot(X.T, self.dz1)
self.db1 = (1 / m) * np.sum(self.dz1, axis=0, keepdims=True)
# Update weights and biases
self.weights2 -= learning_rate * self.dw2
self.bias2 -= learning_rate * self.db2
self.weights1 -= learning_rate * self.dw1
self.bias1 -= learning_rate * self.db1
The backward method implements the backpropagation algorithm, which is used to update the weights and biases in the network based on the error between the predicted output and the actual output (y).
It calculates the gradients of the loss function for the weights and biases (dw2, db2, dw1, db1) using the chain rule. The gradients indicate how much the weights and biases need to be adjusted to minimize the error.
The learning rate (learning_rate) controls how big of a step is taken during the update. The method then updates the weights and biases by subtracting the product of the learning rate and their respective gradients.
Different gradient calculations are performed based on the chosen loss function, illustrating the flexibility of the network to adapt to various tasks.
Activation Functions (sigmoid, sigmoid_derivative, softmax methods)
def sigmoid(self, x):
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(self, x):
return x * (1 - x)
def softmax(self, x):
exps = np.exp(x - np.max(x, axis=1, keepdims=True))
return exps/np.sum(exps, axis=1, keepdims=True)
sigmoid: This method implements the sigmoid activation function, which squashes the input values into a range between 0 and 1. It’s particularly useful for binary classification problems.
sigmoid_derivative: This computes the derivative of the sigmoid function, used during backpropagation to calculate gradients.
softmax: The softmax function is used for multi-class classification problems. It converts scores from the network into probabilities by taking the exponent of each output and then normalizing these values so that they sum up to 1.
Trainer Class
The code below introduces a Trainer class designed to train a neural network model. It encapsulates everything needed to conduct training, including executing training cycles (epochs), calculating loss, and adjusting the model’s parameters through backpropagation based on the loss.
class Trainer:
"""
A class to train a neural network.
Parameters:
-----------
model: NeuralNetwork
The neural network model to train
loss_func: str
The loss function to use. Options are 'mse' for mean squared error, 'log_loss' for logistic loss, and 'categorical_crossentropy' for categorical crossentropy.
"""
def __init__(self, model, loss_func='mse'):
self.model = model
self.loss_func = loss_func
self.train_loss = []
self.test_loss = []
def calculate_loss(self, y_true, y_pred):
"""
Calculate the loss.
Parameters:
-----------
y_true: numpy array
The true output
y_pred: numpy array
The predicted output
Returns:
--------
float
The loss
"""
if self.loss_func == 'mse':
return np.mean((y_pred - y_true)**2)
elif self.loss_func == 'log_loss':
return -np.mean(y_true*np.log(y_pred) + (1-y_true)*np.log(1-y_pred))
elif self.loss_func == 'categorical_crossentropy':
return -np.mean(y_true*np.log(y_pred))
else:
raise ValueError('Invalid loss function')
def train(self, X_train, y_train, X_test, y_test, epochs, learning_rate):
"""
Train the neural network.
Parameters:
-----------
X_train: numpy array
The training input data
y_train: numpy array
The training target output
X_test: numpy array
The test input data
y_test: numpy array
The test target output
epochs: int
The number of epochs to train the model
learning_rate: float
The learning rate
"""
for _ in range(epochs):
self.model.forward(X_train)
self.model.backward(X_train, y_train, learning_rate)
train_loss = self.calculate_loss(y_train, self.model.a2)
self.train_loss.append(train_loss)
self.model.forward(X_test)
test_loss = self.calculate_loss(y_test, self.model.a2)
self.test_loss.append(test_loss)
Here’s a detailed breakdown of the class and its methods:
Class Initialization (__init__ method)
def __init__(self, model, loss_func='mse'):
self.model = model
self.loss_func = loss_func
self.train_loss = []
self.test_loss = []
The constructor takes a neural network model (model) and a loss function (loss_func) as inputs. The loss_func defaults to mean squared error (‘mse’) if not specified.
It initializes train_loss and test_loss lists to keep track of the loss values during the training and testing phases, allowing for monitoring of the model’s performance over time.
Calculating Loss (calculate_loss method)
def calculate_loss(self, y_true, y_pred):
if self.loss_func == 'mse':
return np.mean((y_pred - y_true)**2)
elif self.loss_func == 'log_loss':
return -np.mean(y_true*np.log(y_pred) + (1-y_true)*np.log(1-y_pred))
elif self.loss_func == 'categorical_crossentropy':
return -np.mean(y_true*np.log(y_pred))
else:
raise ValueError('Invalid loss function')
This method calculates the loss between the predicted outputs (y_pred) and the true outputs (y_true) using the specified loss function. This is crucial for evaluating how well the model is performing and for performing backpropagation.
The method supports three types of loss functions:
- Mean Squared Error (‘mse’): Used for regression tasks, calculating the average of the squares of the differences between predicted and true values.
- Logistic Loss (‘log_loss’): Suited for binary classification problems, computing the loss using the log-likelihood method.
- Categorical Crossentropy (‘categorical_crossentropy’): Ideal for multi-class classification tasks, measuring the discrepancy between true labels and predictions.
If an invalid loss function is provided, it raises a ValueError.
Training the Model (train method)
def train(self, X_train, y_train, X_test, y_test, epochs, learning_rate):
for _ in range(epochs):
self.model.forward(X_train)
self.model.backward(X_train, y_train, learning_rate)
train_loss = self.calculate_loss(y_train, self.model.a2)
self.train_loss.append(train_loss)
self.model.forward(X_test)
test_loss = self.calculate_loss(y_test, self.model.a2)
self.test_loss.append(test_loss)
The train method manages the training process over a specified number of epochs using the training (X_train, y_train) and testing datasets (X_test, y_test). It also takes a learning_rate parameter that influences the step size in the parameter update during backpropagation.
For each epoch (training cycle), the method performs the following steps:
- Forward Pass on Training Data: It uses the model’s forward method to compute the predicted outputs for the training data.
- Backward Pass (Parameter Update): It applies the model’s backward method using the training data and labels (y_train) along with the learning_rate to update the model’s weights and biases based on the gradients calculated from the loss.
- Calculate Training Loss: The training loss is calculated using the calculate_loss method with the training labels and the predictions. This loss is then appended to the train_loss list for monitoring.
- Forward Pass on Testing Data: Similarly, the method computes predictions for the testing data to evaluate the model’s performance on unseen data.
- Calculate Testing Loss: It calculates the testing loss using the testing labels and predictions, appending this loss to the test_loss list.
Implementation
In this section, I will outline a complete process for loading a dataset, preparing it for training, and using it to train a neural network for a classification task. The process involves data preprocessing, model creation, training, and evaluation.
For this task, we will use the digits dataset from the open-source (BSD-3 license) sci-kit learn library. Click here for more information about Sci-Kit Learn.
# Load the digits dataset
digits = load_digits()
# Preprocess the dataset
scaler = MinMaxScaler()
X = scaler.fit_transform(digits.data)
y = digits.target
# One-hot encode the target output
encoder = OneHotEncoder(sparse=False)
y_onehot = encoder.fit_transform(y.reshape(-1, 1))
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y_onehot, test_size=0.2, random_state=42)
# Create an instance of the NeuralNetwork class
input_size = X.shape[1]
hidden_size = 64
output_size = len(np.unique(y))
loss_func = 'categorical_crossentropy'
epochs = 1000
learning_rate = 0.1
nn = NeuralNetwork(input_size, hidden_size, output_size, loss_func)
trainer = Trainer(nn, loss_func)
trainer.train(X_train, y_train, X_test, y_test, epochs, learning_rate)
# Convert y_test from one-hot encoding to labels
y_test_labels = np.argmax(y_test, axis=1)
# Evaluate the performance of the neural network
predictions = np.argmax(nn.forward(X_test), axis=1)
accuracy = np.mean(predictions == y_test_labels)
print(f"Accuracy: {accuracy:.2%}")
Let’s walk through each step:
Load the Dataset
# Load the digits dataset
digits = load_digits()

The dataset used here is the digits dataset, which is commonly used for classification tasks involving recognizing handwritten digits.
Preprocess the Dataset
# Preprocess the dataset
scaler = MinMaxScaler()
X = scaler.fit_transform(digits.data)
y = digits.target
The features of the dataset are scaled to a range between 0 and 1 using the MinMaxScaler. This is a common preprocessing step to ensure that all input features have the same scale, which can help the neural network learn more effectively.
The scaled features are stored in X, and the target labels (which digit each image represents) are stored in y.
One-hot Encode the Target Output
# One-hot encode the target output
encoder = OneHotEncoder(sparse=False)
y_onehot = encoder.fit_transform(y.reshape(-1, 1))
Since this is a classification task with multiple classes, the target labels are one-hot encoded using OneHotEncoder. One-hot encoding transforms the categorical target data into a format that’s easier for neural networks to understand and work with, especially for classification tasks.
Split the Dataset
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y_onehot, test_size=0.2, random_state=42)
The dataset is split into training and testing sets using train_test_split, with 80% of the data used for training and 20% for testing. This split allows for training the model on one portion of the data and then evaluating its performance on a separate, unseen portion to check how well it generalizes.
Create an Instance of the NeuralNetwork Class
# Create an instance of the NeuralNetwork class
input_size = X.shape[1]
hidden_size = 64
output_size = len(np.unique(y))
loss_func = 'categorical_crossentropy'
epochs = 1000
learning_rate = 0.1
nn = NeuralNetwork(input_size, hidden_size, output_size, loss_func)
A neural network instance is created with specified input size (the number of features), hidden size (the number of neurons in the hidden layer), output size (the number of unique labels), and the loss function to use. The input size matches the number of features, the output size matches the number of unique target classes, and a hidden layer size is chosen.
Training the Neural Network
trainer = Trainer(nn, loss_func)
trainer.train(X_train, y_train, X_test, y_test, epochs, learning_rate)
An instance of the Trainer class is created with the neural network and loss function. The train method is then called with the training and testing datasets, along with the number of epochs and the learning rate specified. This process iteratively adjusts the neural network’s weights and biases to minimize the loss function, using the training data for learning and the testing data for validation.
Evaluate the Performance
# Convert y_test from one-hot encoding to labels
y_test_labels = np.argmax(y_test, axis=1)
# Evaluate the performance of the neural network
predictions = np.argmax(nn.forward(X_test), axis=1)
accuracy = np.mean(predictions == y_test_labels)
print(f"Accuracy: {accuracy:.2%}")
After training, the model’s performance is evaluated on the test set. Since the targets were one-hot encoded, np.argmax is used to convert the one-hot encoded predictions back to label form. The accuracy of the model is calculated by comparing these predicted labels against the actual labels (y_test_labels) and then printed out.
Now, this code lacks a few activation functions we talked about, improvements such as SGD or Adam Optimizer, and more. I leave this to you to take and make this code your own, by filling the gaps with your code. In this way, you will truly master Neural Networks.
4.2: Utilizing Libraries for Neural Network Implementation (TensorFlow)
Well, that was a lot! Luckily for us, we don’t need to write such a long code every time we want to work with NNs. We can leverage libraries such as Tensorflow and PyTorch which will create Deep Learning models for us with minimum code. In this example, we will create and explain a TensorFlow version of training a neural network on the digits dataset, similar to the process described previously.
As before let’s first import the required libraries, and the dataset and let’s preprocess it, in the same fashion we did before.
import tensorflow as tf
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, OneHotEncoder
# Load the digits dataset
digits = load_digits()
# Scale the features to a range between 0 and 1
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(digits.data)
# One-hot encode the target labels
encoder = OneHotEncoder(sparse=False)
y_onehot = encoder.fit_transform(digits.target.reshape(-1, 1))
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y_onehot, test_size=0.2, random_state=42)
Secondly, let’s build the NN:
# Define the model architecture
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(X_train.shape[1],)),
tf.keras.layers.Dense(len(np.unique(digits.target)), activation='softmax')
])
Here, a Sequential model is created, indicating a linear stack of layers.
The first layer is a densely-connected layer with 64 units (neurons) and ReLU activation. It expects input from the shape (X_train.shape[1],), which matches the number of features in the dataset.
The output layer has several units equal to the number of unique target classes and uses the softmax activation function to output probabilities for each class.
# Compile the model
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
The model is compiled with the Adam optimizer and categorical cross-entropy as the loss function, suitable for multi-class classification tasks. Accuracy is specified as a metric for evaluation.
Lastly, let’s train and evaluate the performance of our NN:
# Train the model
history = model.fit(X_train, y_train, epochs=1000, validation_data=(X_test, y_test), verbose=2)
# Evaluate the model on the test set
test_loss, test_accuracy = model.evaluate(X_test, y_test, verbose=2)
print(f"Test accuracy: {test_accuracy:.2%}")
The model is trained using the fit method with 1000 epochs, and the testing set is used as validation data. verbose=2 indicates that one line per epoch will be printed for logging.
Finally, the model’s performance is evaluated on the test set using the evaluate method, and the test accuracy is printed.
5: Challenges
5.1: Overcoming Overfitting
Overfitting is like when a neural network becomes a bit too obsessed with its training data, picking up on all the tiny details and noise, to the point where it struggles to handle new, unseen data. It’s like studying so hard for your exams by memorizing the textbook word for word but then not being able to apply what you’ve learned to any question that’s phrased differently. This problem can hold back a model’s ability to perform well in real-world situations, where being able to generalize or apply what it’s learned to new scenarios, is key. Luckily, there are several clever techniques to help prevent or lessen overfitting, making our models more versatile and ready for the real world. Let’s take a look at a few of them, but don’t worry about mastering all of them now as I will cover anti-overfitting techniques in a separate article.
Dropout: This is like randomly turning off some of the neurons in the network during training. It stops the neurons from getting too dependent on each other, forcing the network to learn more robust features that aren’t just relying on a specific set of neurons to make predictions.
Early Stopping
This involves watching how the model does on a validation set (a separate chunk of data) as it’s training. If the model starts doing worse on this set, it’s a sign that it’s beginning to overfit, and it’s time to stop training.
Using a Validation Set
Dividing your data into three sets — training, validation, and test — helps keep an eye on overfitting. The validation set is for tuning the model and picking the best version, while the test set gives you a fair assessment of how well the model is doing.
Simplifying The Model
Sometimes, less is more. If a model is too complex, it might start picking up noise from the training data. By choosing a simpler model or dialing back on the number of layers, we can reduce the risk of overfitting.
As you experiment with NN, you will see that fine-tuning and tackling overfitting will play a pivotal role in NN’s performance. Making sure you master anti-overfitting techniques is a must for a successful data scientist. Because of its importance, I will dedicate an entire article to these techniques to make sure you can fine-tune the best NNs and guarantee an optimal performance for your projects.
6: Conclusion
Diving into the world of neural networks opens our eyes to the incredible potential these models hold within the realm of artificial intelligence. Starting with the basics, like how neural networks use weighted sums and activation functions to process information, we’ve seen how techniques like backpropagation and gradient descent empower them to learn from data. Especially in areas like image recognition, we’ve witnessed firsthand how neural networks are solving complex challenges and pushing technology forward.
Looking ahead, it’s clear we are only at the beginning of a long journey called “Deep Learning”. In the next articles, we will talk about more advanced deep learning architectures, fine-tuning methods, and much more!
Bibliography
- Goodfellow, Ian, Yoshua Bengio, and Aaron Courville. “Deep Learning.” MIT Press, 2016. This comprehensive textbook provides an extensive overview of deep learning, covering the mathematical underpinnings and practical aspects of neural networks.
- LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. “Deep learning.” Nature 521, no. 7553 (2015): 436–444. A landmark paper by pioneers in the field, summarizing the key concepts and achievements in deep learning and neural networks.
You made it to the end. Congrats! I hope you enjoyed this article, if so consider leaving a like and following me, as I will regularly post similar articles. My goal is to recreate all the most popular algorithms from scratch and make machine learning accessible to everyone.
The Math Behind Neural Networks was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
The Math Behind Neural Networks