
Simplifying the neural nets behind Generative Video Diffusion
We’ve witnessed remarkable strides in AI image generation. But what happens when we add the dimension of time? Videos are moving images, after all.
Text-to-video generation is a complex task that requires AI to understand not just what things look like, but how they move and interact over time. It is an order of magnitude more complex than text-to-image.
To produce a coherent video, a neural network must:
1. Comprehend the input prompt
2. Understand how the world works
3. Know how objects move and how physics applies
4. Generate a sequence of frames that make sense spatially, temporally, and logically
Despite these challenges, today’s diffusion neural networks are making impressive progress in this field. In this article, we will cover the main ideas behind video diffusion models — main challenges, approaches, and the seminal papers in the field.
Text to Image Overview
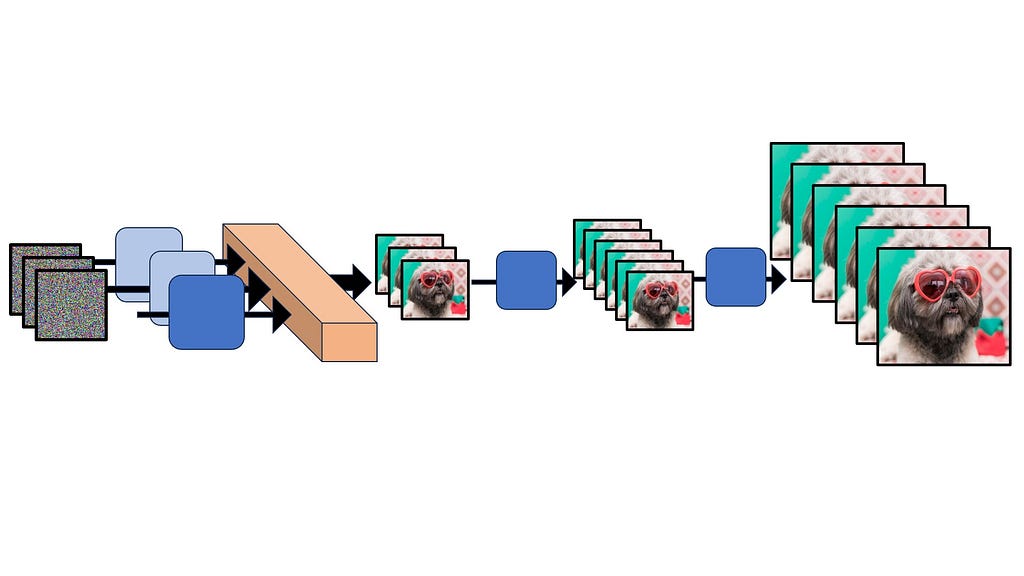
To understand text-to-video generation, we need to start with its predecessor: text-to-image diffusion models. These models have a singular goal — to transform random noise and a text prompt into a coherent image. In general, all generative image models do this — Variational Autoencoders (VAE), Generative Adversarial Neural Nets (GANs), and yes, Diffusion too.
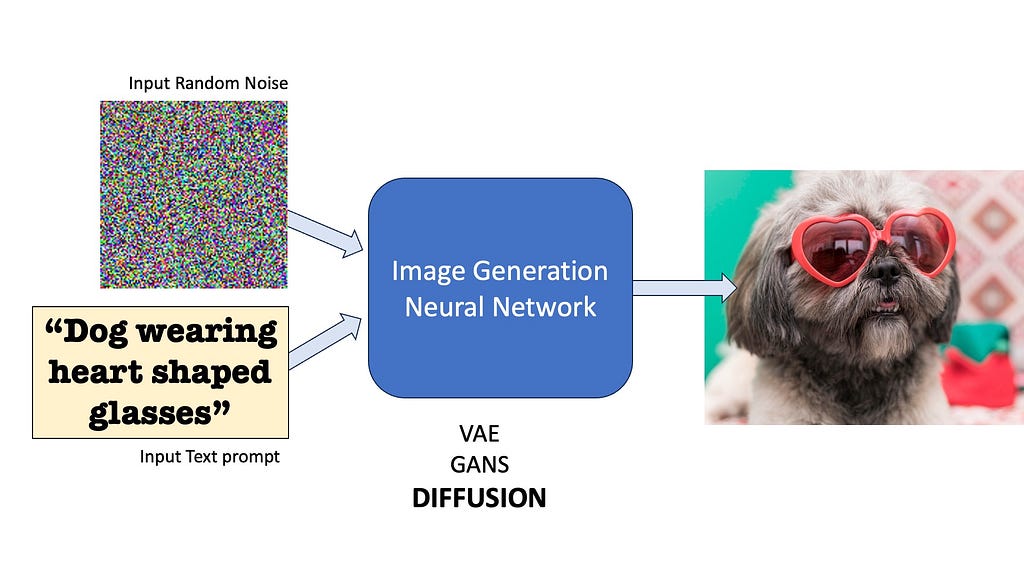
Diffusion, in particular, relies on a gradual denoising process to generate images.
1. Start with a randomly generated noisy image
2. Use a neural network to progressively remove noise
3. Condition the denoising process on text input
4. Repeat until a clear image emerges

But how are these denoising neural networks trained?
During training, we start with real images and progressively add noise to it in small steps — this is called forward diffusion. This generates a lot of samples of clear image and their slightly noisier versions. The neural network is then trained to reverse this process by inputting the noisy image and predicting how much noise to remove to retrieve the clearer version. In text-conditional models, we train attention layers to attend to the inputted prompt for guided denoising.

This iterative approach allows for the generation of highly detailed and diverse images. You can watch the following YouTube video where I explain text to image in much more detail — concepts like Forward and Reverse Diffusion, U-Net, CLIP models, and how I implemented them in Python and Pytorch from scratch.
If you are comfortable with the core concepts of Text-to-Image Conditional Diffusion, let’s move to videos next.
The Temporal Dimension: A New Frontier
In theory, we could follow the same conditioned noise-removal idea to do text-to-video diffusion. However, adding time into the equation introduces several new challenges:
1. Temporal Consistency: Ensuring objects, backgrounds, and motions remain coherent across frames.
2. Computational Demands: Generating multiple frames per second instead of a single image.
3. Data Scarcity: While large image-text datasets are readily available, high-quality video-text datasets are scarce.

The Evolution of Video Diffusion
Because of the lack of high quality datasets, text-to-video cannot rely just on supervised training. And that is why people usually also combine two more data sources to train video diffusion models — one — paired image-text data, which is much more readily available, and two — unlabelled video data, which are super-abundant and contains lots of information about how the world works. Several groundbreaking models have emerged to tackle these challenges. Let’s discuss some of the important milestone papers one by one.
We are about to get into the technical nitty gritty! If you find the material ahead difficult, feel free to watch this companion video as a visual side-by-side guide while reading the next section.
Video Diffusion Model (VDM) — 2022
VDM Uses a 3D U-Net architecture with factorized spatio-temporal convolution layers. Each term is explained in the picture below.
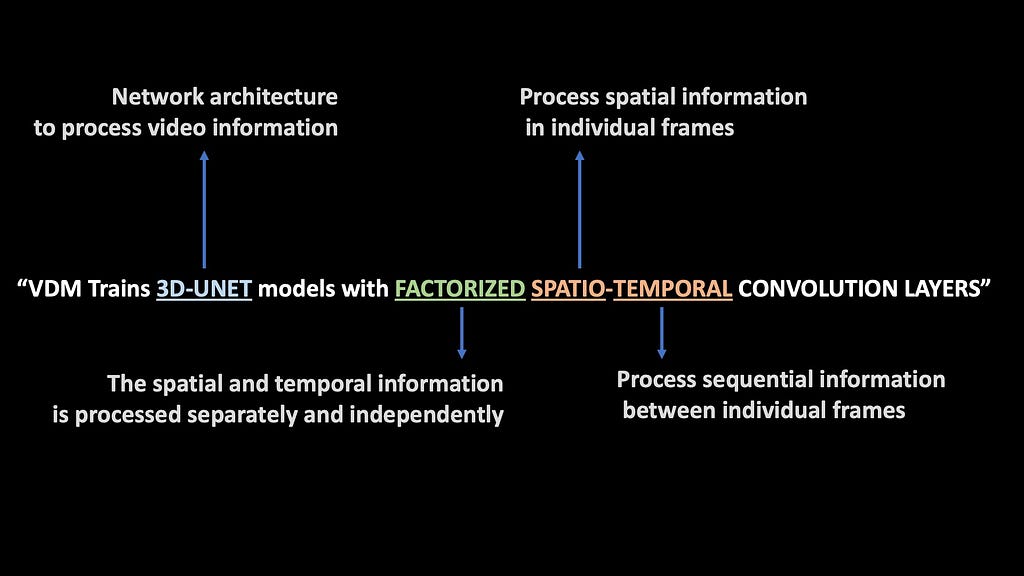
VDM is jointly trained on both image and video data. VDM replaces the 2D UNets from Image Diffusion models with 3D UNet models. The video is input into the model as a time sequence of 2D frames. The term Factorized basically means that the spatial and temporal layers are decoupled and processed separately from each other. This makes the computations much more efficient.
What is a 3D-UNet?
3D U-Net is a unique computer vision neural network that first downsamples the video through a series of these factorized spatio-temporal convolutional layers, basically extracting video features at different resolutions. Then, there is an upsampling path that expands the low-dimensional features back to the shape of the original video. While upsampling, skip connections are used to reuse the generated features during the downsampling path.
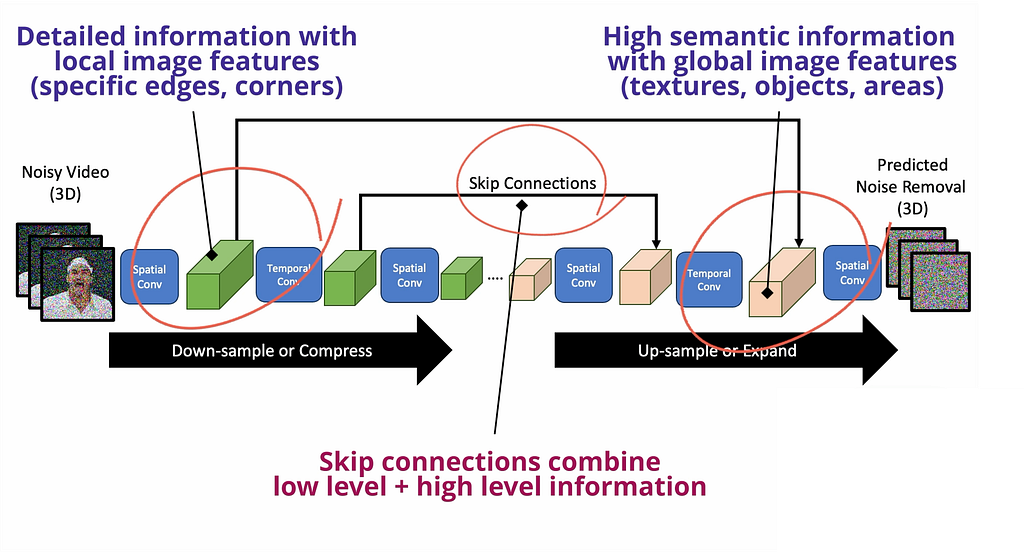
Remember in any convolutional neural network, the earlier layers always capture detailed information about local sections of the image, while latter layers pick up global level pattern by accessing larger sections — so by using skip connections, U-Net combines local details with global features to be a super-awesome network for feature learning and denoising.
VDM is jointly trained on paired image-text and video-text datasets. While it’s a great proof of concept, VDM generates quite low-resolution videos for today’s standards.
You can read more about VDM here.
Make-A-Video (Meta AI) — 2022
Make-A-Video by Meta AI takes the bold approach of claiming that we don’t necessarily need labeled-video data to train video diffusion models. WHHAAA?! Yes, you read that right.
Adding temporal layers to Image Diffusion
Make A Video first trains a regular text-to-image diffusion model, just like Dall-E or Stable Diffusion with paired image-text data. Next, unsupervised learning is done on unlabelled video data to teach the model temporal relationships. The additional layers of the network are trained using a technique called masked spatio-temporal decoding, where the network learns to generate missing frames by processing the visible frames. Note that no labelled video data is needed in this pipeline (although further video-text fine-tuning is possible as an additional third step), because the model learns spatio-temporal relationships with paired text-image and raw unlabelled video data.
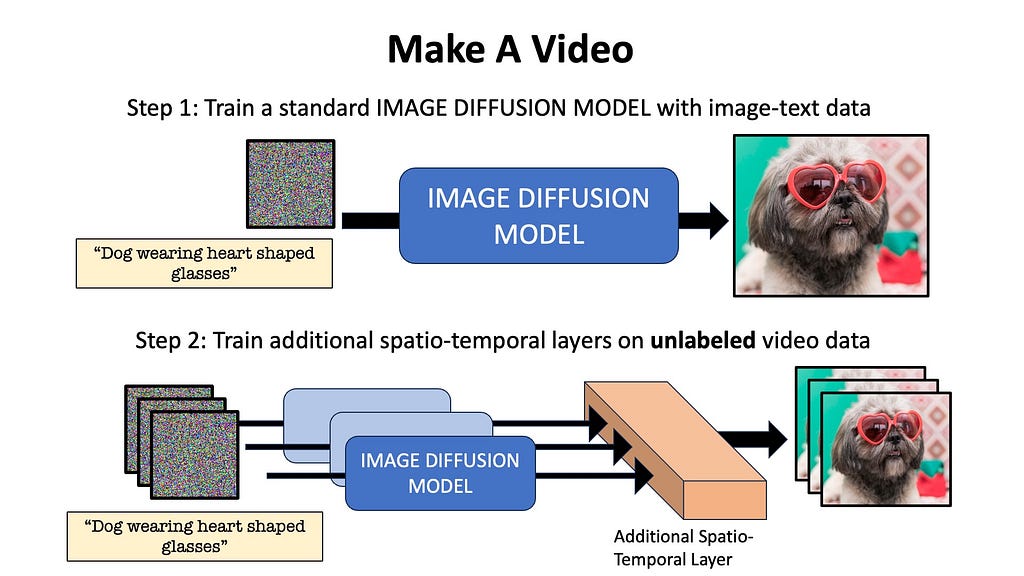
The video outputted by the above model is 64×64 with 16 frames. This video is then upsampled along the time and pixel axis using separate neural networks called Temporal Super Resolution or TSR (insert new frames between existing frames to increase frames-per-second (fps)), and Spatial Super Resolution or SSR (super-scale the individual frames of the video to be higher resolution). After these steps, Make-A-Video outputs 256×256 videos with 76 frames.
You can learn more about Make-A-Video right here.
Imagen Video (Google) — 2022
Imagen video employs a cascade of seven models for video generation and enhancement. The process starts with a base video generation model that creates low-resolution video clips. This is followed by a series of super-resolution models — three SSR (Spatial Super Resolution) models for spatial upscaling and three TSR (Temporal Super Resolution) models for temporal upscaling. This cascaded approach allows Imagen Video to generate high-quality, high-resolution videos with impressive temporal consistency. Generates high-quality, high-resolution videos with impressive temporal consistency

VideoLDM (NVIDIA) — 2023
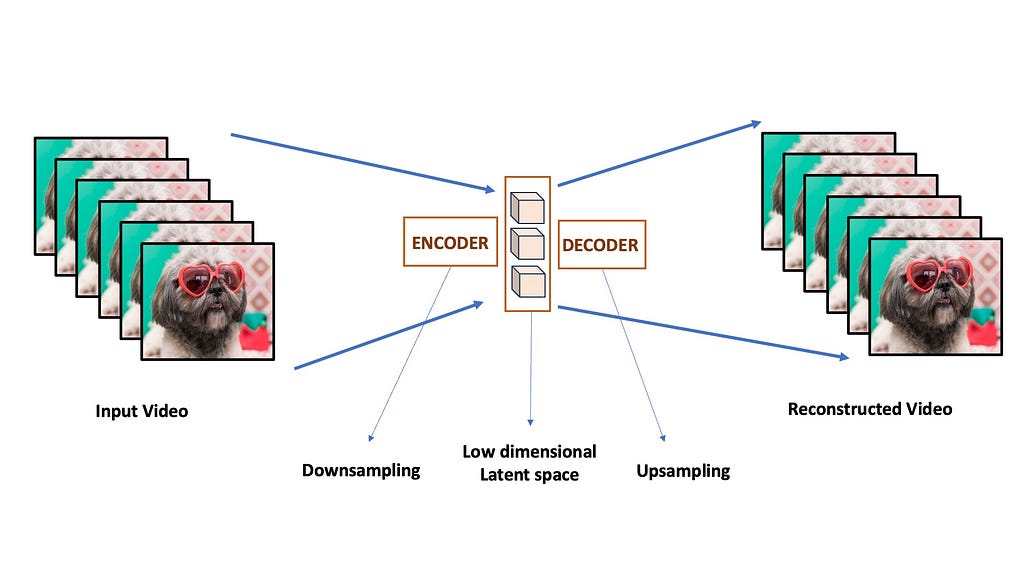
Models like Nvidia’s VideoLDM tries to address the temporal consistency issue by using latent diffusion modelling. First they train a latent diffusion image generator. The basic idea is to train a Variational Autoencoder or VAE. The VAE consists of an encoder network that can compress input frames into a low dimensional latent space and another decoder network that can reconstruct it back to the original images. The diffusion process is done entirely on this low dimensional space instead of the full pixel-space, making it much more computationally efficient and semantically powerful.

What are Latent Diffusion Models?
The diffusion model is trained entirely in the low dimensional latent space, i.e. the diffusion model learns to denoise the low dimensional latent space images instead of the full resolution frames. This is why we call it Latent Diffusion Models. The resulting latent space outputs is then pass through the VAE decoder to convert it back to pixel-space.
The decoder of the VAE is enhanced by adding new temporal layers in between it’s spatial layers. These temporal layers are fine-tuned on video data, making the VAE produce temporally consistent and flicker-free videos from the latents generated by the image diffusion model. This is done by freezing the spatial layers of the decoder and adding new trainable temporal layers that are conditioned on previously generated frames.

You can learn more about Video LDMs here.
SORA (OpenAI) — 2024
While Video LDM compresses individual frames of the video to train an LDM, SORA compresses video both spatially and temporally. Recent papers like CogVideoX have demonstrated that 3D Causal VAEs are great at compressing videos making diffusion training computationally efficient, and able to generate flicker-free consistent videos.
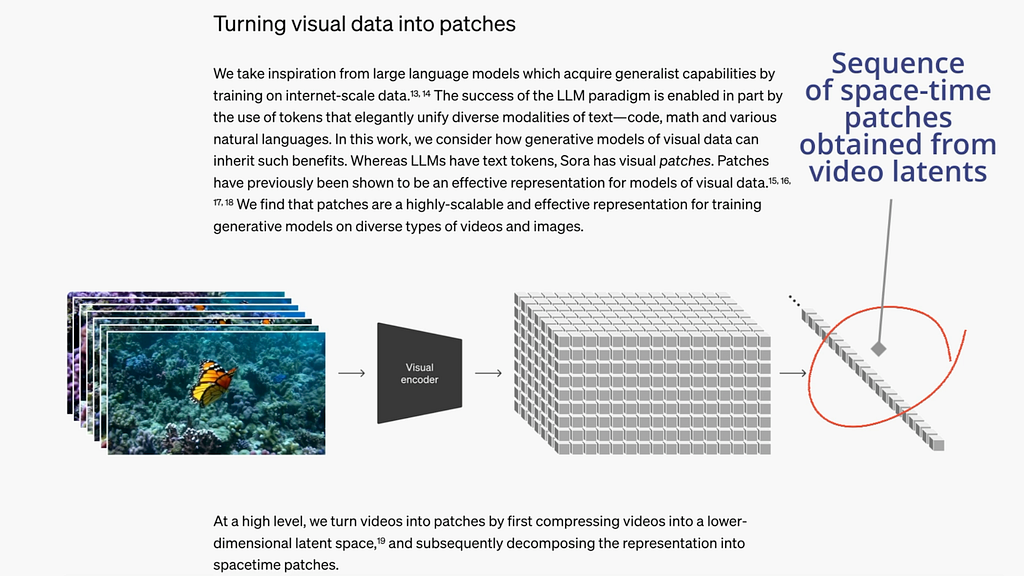
Transformers for Diffusion
A transformer model is used as the diffusion network instead of the more traditional UNEt model. Of course, transformers need the input data to be presented as a sequence of tokens. That’s why the compressed video encodings are flattened into a sequence of patches. Observe that each patch and its location in the sequence represents a spatio-temporal feature of the original video.
It is speculated that OpenAI has collected a rather large annotation dataset of video-text data which they are using to train conditional video generation models.
Combining all the strengths listed below, plus more tricks that the ironically-named OpenAI may never disclose, SORA promises to be a giant leap in video generation AI models.
- Massive video-text annotated dataset + pretraining techniques with image-text data and unlabelled data
- General architectures of Transformers
- Huge compute investment (thanks Microsoft)
- The representation power of Latent Diffusion Modeling.
What’s next
The future of AI is easy to predict. In 2024, Data + Compute = Intelligence. Large corporations will invest computing resources to train large diffusion transformers. They will hire annotators to label high-quality video-text data. Large-scale text-video datasets probably already exist in the closed-source domain (looking at you OpenAI), and they may become open-source within the next 2–3 years, especially with recent advancements in AI video understanding. It remains to be seen if the upcoming huge computing and financial investments could on their own solve video generation. Or will further architectural and algorithmic advancements be needed from the research community?
Links
Author’s Youtube Channel: https://www.youtube.com/@avb_fj
Video on this topic: https://youtu.be/KRTEOkYftUY
15-step Zero-to-Hero on Conditional Image Diffusion: https://youtu.be/w8YQc
Papers and Articles
Video Diffusion Models: https://arxiv.org/abs/2204.03458
Imagen: https://imagen.research.google/video/
Make A Video: https://makeavideo.studio/
Video LDM: https://research.nvidia.com/labs/toronto-ai/VideoLDM/index.html
CogVideoX: https://arxiv.org/abs/2408.06072
OpenAI SORA article: https://openai.com/index/sora/
Diffusion Transformers: https://arxiv.org/abs/2212.09748
Useful article: https://lilianweng.github.io/posts/2024-04-12-diffusion-video/
The Evolution of Text to Video Models was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
The Evolution of Text to Video Models
Go Here to Read this Fast! The Evolution of Text to Video Models