

Benchmarking as a Measure of Success
Benchmarks are often hailed as a hallmark of success. They are a celebrated way of measuring progress — whether it’s achieving the sub 4-minute mile or the ability to excel on standardized exams. In the context of Artificial Intelligence (AI) benchmarks are the most common method of evaluating a model’s capability. Industry leaders such as OpenAI, Anthropic, Meta, Google, etc. compete in a race to one-up each other with superior benchmark scores. However, recent research studies and industry grumblings are casting doubt about whether common benchmarks truly capture the essence of a models ability.
Data Contamination Leading to Memorization
Emerging research points to the probability that training sets of some models have been contaminated with the very data that they are being assessed on — raising doubts on the the authenticity of their benchmark scores reflecting true understanding. Just like in films where actors can portray Doctors or Scientists, they deliver the lines without truly grasping the underlying concepts. When Cillian Murphy played famous physicist J. Robert Oppenheimer in the movie Oppenheimer, he likely did not understand the complex physics theories he spoke of. Although benchmarks are meant to evaluate a models capabilities, are they truly doing so if like an actor the model has memorized them?
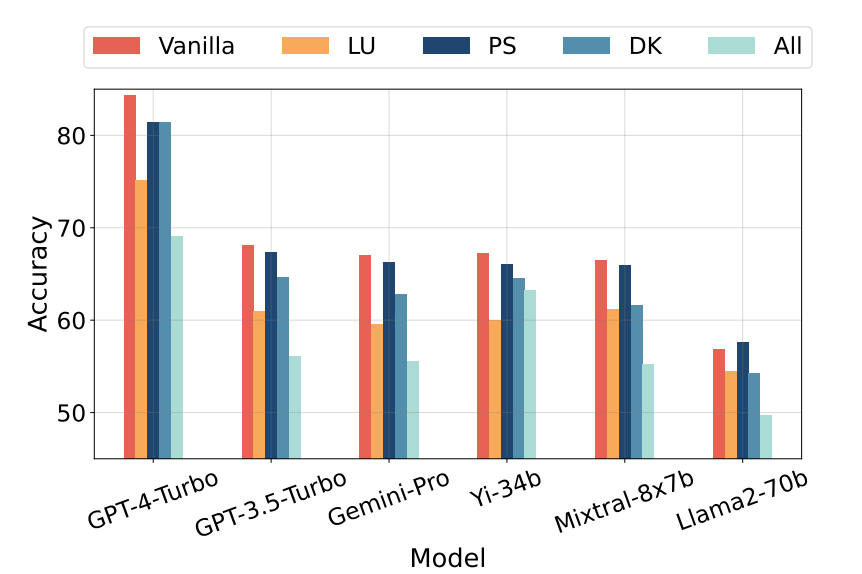
Recent findings from the University of Arizona have discovered that GPT-4 is contaminated with AG News, WNLI, and XSum datasets discrediting their associated benchmarks[1]. Further, researchers from the University of Science and Technology of China found that when they deployed their “probing” technique on the popular MMLU Benchmark [2], results decreased dramatically.
Their probing techniques included a series of methods meant to challenge the models understanding of the question when posed different ways with different answer options, but the same correct answer. Examples of the probing techniques consisted of: paraphrasing questions, paraphrasing choices, permuting choices, adding extra context into questions, and adding a new choice to the benchmark questions.
From the graph below, one can gather that although each tested model performed well on the unaltered “vanilla” MMLU benchmark, when probing techniques were added to different sections of the benchmark (LU, PS, DK, All) they did not perform as strongly.
Future Considerations on how to evaluate AI
This evolving situation prompts a re-evaluation of how AI models are assessed. The need for benchmarks that both reliably demonstrate capabilities and anticipate the issues of data contamination and memorization is becoming apparent.
As models continue to evolve and are updated to potentially include benchmark data in their training sets, benchmarks will have an inherently short lifespan. Additionally, model context windows are increasing rapidly, allowing a larger amount of context to be included in the models response. The larger the context window the more potential impact of contaminated data indirectly skewing the model’s learning process, making it biased towards the seen test examples .
The Rise of the Dynamic and Real-World Benchmark
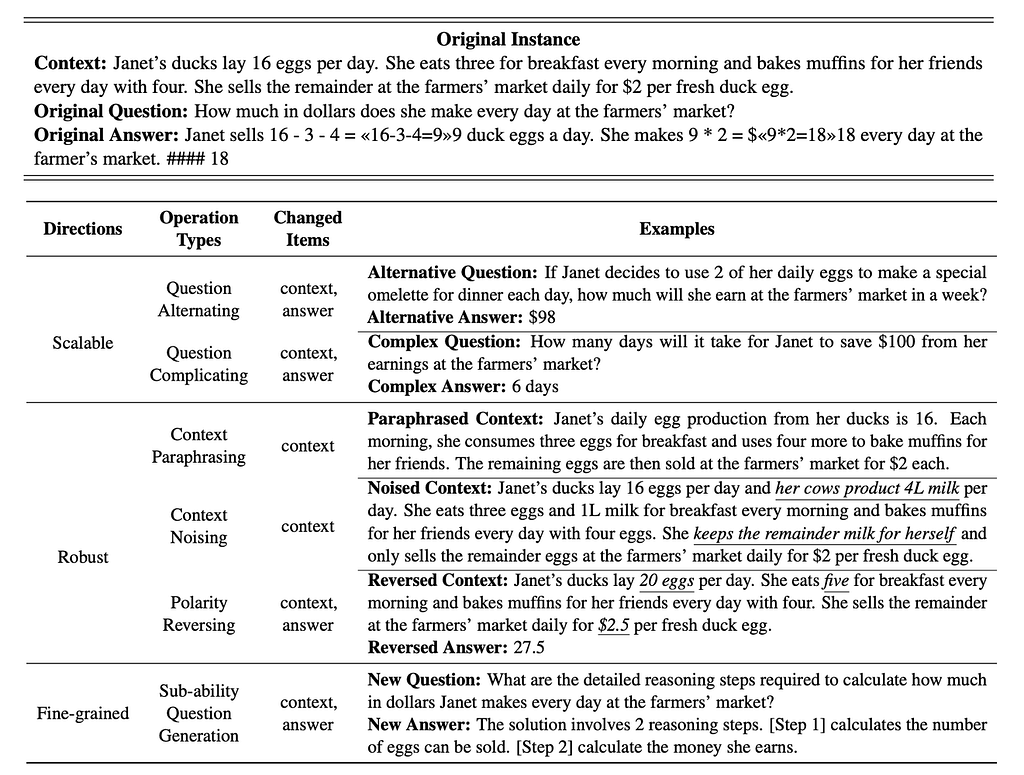
To address these challenges, innovative approaches such as dynamic benchmarks are emerging, employing tactics like: altering questions, complicating questions, introduce noise into the question, paraphrasing the question, reversing the polarity of the question, and more [3].
The example below provides an example on several methods to alter benchmark questions (either manually or language model generated).
As we move forward, the imperative to align evaluation methods more closely with real-world applications becomes clear. Establishing benchmarks that accurately reflect practical tasks and challenges will not only provide a truer measure of AI capabilities but also guide the development of Small Language Models (SLMs) and AI Agents. These specialized models and agents require benchmarks that genuinely capture their potential to perform practical and helpful tasks.
The Death of the Static AI Benchmark was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
The Death of the Static AI Benchmark
Go Here to Read this Fast! The Death of the Static AI Benchmark