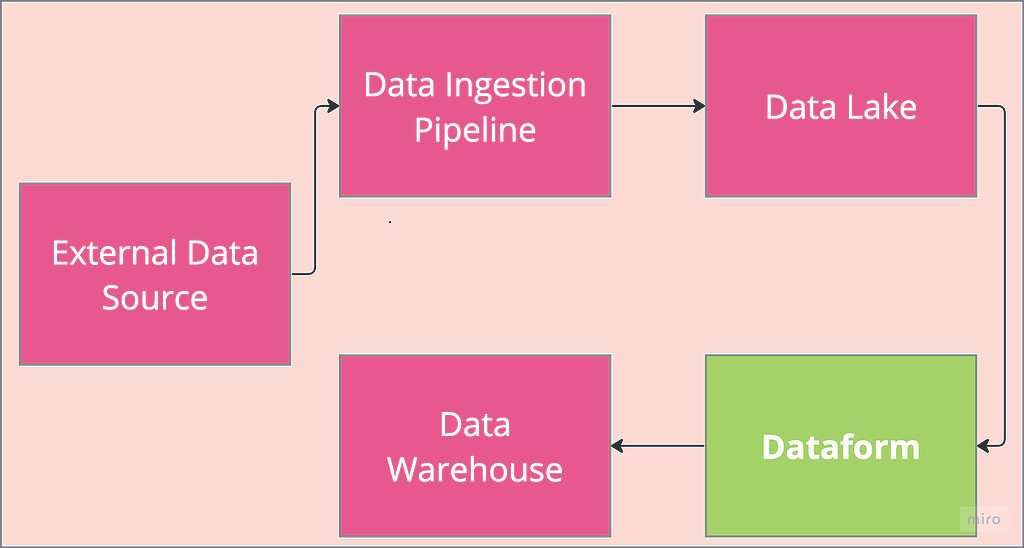
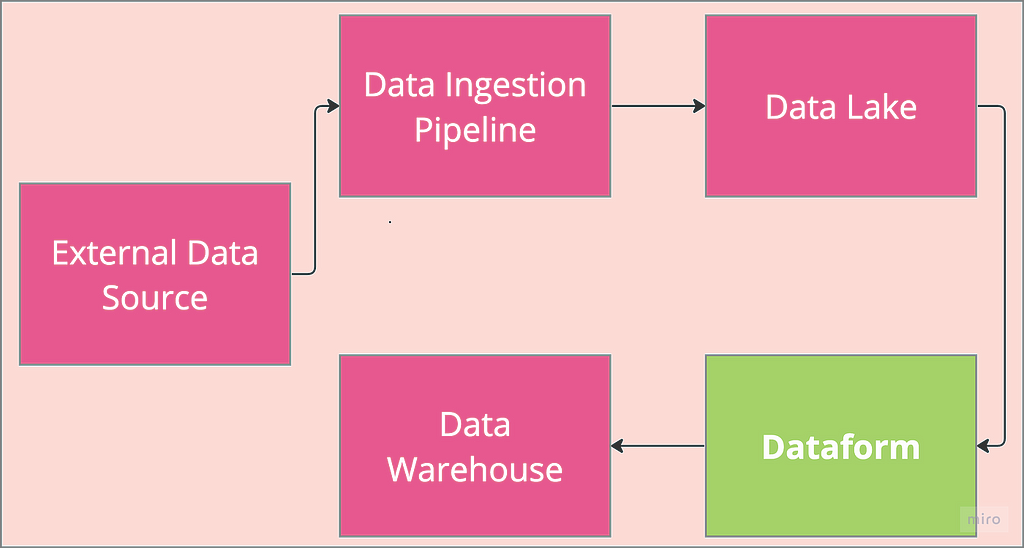
MLOps: Datapipeline Orchestration
Part 2 of Dataform 101: Provisioning Dataform with least privilege access control
This is the concluding part of Dataform 101 showing the fundamentals of setting up Dataform with a focus on its authentication flow. This second part focussed on terraform implementation of the flow explained in part 1.
Dataform Provisioning
Dataform can be set up via the GCP console, but Terraform provides an elegant approach to provisioning and managing infrastructure such as Dataform. The use of Terraform offers portability, reusability and infrastructure versioning along with many other benefits. As a result, Terraform knowledge is required to follow along in this section. If you are familiar with Terraform, head over to the GitHub repo and download all the code. If not, Google cloud skills boost has good resources to get started.
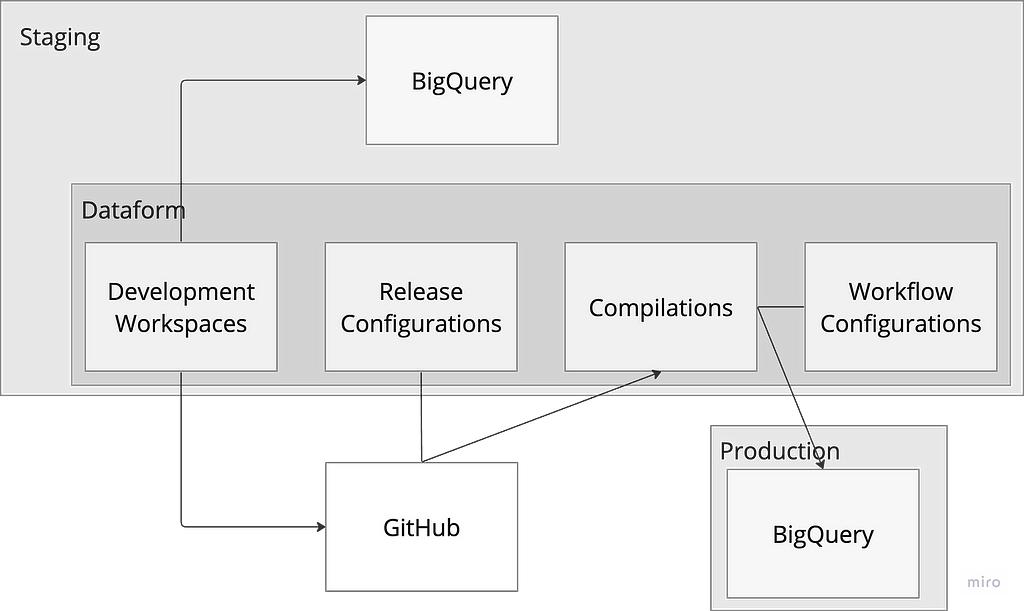
Environments setup
We start by setting up the two environments, prod and staging , as reflected in the architecture flow diagram above. It should be noted that the code development is done on macOS system, and as such, a window system user might need some adjustments to follow along.
mkdir prod
mkdir staging
Set up staging files
All the initial codes are written within the staging directory. This is because the proposed architecture provisions Dataform within the staging environment and only few resources are provisioned in the production environment.
Let’s start by provisioning a remote bucket to store the Terraform state in remote backend. This bit would be done manually and we wouldnt bring the bucket under terraform management. It is a bit of a chicken-and-egg case whether the bucket in which the Terraform state is stored should be managed by the same Terraform. What you call a catch-22. So we manually create a bucket named dataform-staging-terraform-state within the staging environment by adding the following in the staging directory:
#staging/backend.tf
terraform {
backend "gcs" {
bucket = "dataform-staging-terraform-state"
prefix = "terraform/state"
}
Next, add resource providers to the code base.
#staging/providers.tf
terraform {
required_providers {
google = {
source = "hashicorp/google"
version = ">=5.14.0"
}
google-beta = {
source = "hashicorp/google-beta"
version = ">=5.14.0"
}
}
required_version = ">= 1.7.3"
}
provider "google" {
project = var.project_id
}
We then create a variable file to define all the variables used for the infrastructure provisioning.
#staging/variables.tf
variable "project_id" {
type = string
description = "Name of the GCP Project."
}
variable "region" {
type = string
description = "The google cloud region to use"
default = "europe-west2"
}
variable "project_number" {
type = string
description = "Number of the GCP Project."
}
variable "location" {
type = string
description = "The google cloud location in which to create resources"
default = "EU"
}
variable "dataform_staging_service_account" {
type = string
description = "Email of the service account Dataform uses to execute queries in staging env"
}
variable "dataform_prod_service_account" {
type = string
description = "Email of the service account Dataform uses to execute queries in production"
}
variable "dataform_github_token" {
description = "Dataform GitHub Token"
type = string
sensitive = true
}
The auto.tfvars file is added to ensure the variables are auto-discoverable. Ensure to substitute appropriately for the variable placeholders in the file.
#staging/staging.auto.tfvars
project_id = "{staging-project-id}"
region = "{staging-project--region}"
project_number = "{staging-project-number}"
dataform_staging_service_account = "dataform-staging"
dataform_prod_service_account = "{dataform-prod-service-account-email}"
dataform_github_token = "dataform_github_token"
This is followed by secret provisioning where the machine user token is stored.
#staging/secrets.tf
resource "google_secret_manager_secret" "dataform_github_token" {
project = var.project_id
secret_id = var.dataform_github_token
replication {
user_managed {
replicas {
location = var.region
}
}
}
}
After provisioning the secret, a data resource is added to the terraform codebase for dynamically reading the stored secret value so Dataform has access to the machine user GitHub credentials when provisioned. The data resource is conditioned on the secret resource to ensure that it only runs when the secret has already been provisioned.
#staging/data.tf
data "google_secret_manager_secret_version" "dataform_github_token" {
project = var.project_id
secret = var.dataform_github_token
depends_on = [
google_secret_manager_secret.dataform_github_token
]
}
We proceed to provision the required service account for the staging environment along with granting the required permissions for manifesting data to BigQuery.
#staging/service_accounts.tf
resource "google_service_account" "dataform_staging" {
account_id = var.dataform_staging_service_account
display_name = "Dataform Service Account"
project = var.project_id
}
And the BQ permissions
#staging/iam.tf
resource "google_project_iam_member" "dataform_staging_roles" {
for_each = toset([
"roles/bigquery.dataEditor",
"roles/bigquery.dataViewer",
"roles/bigquery.user",
"roles/bigquery.dataOwner",
])
project = var.project_id
role = each.value
member = "serviceAccount:${google_service_account.dataform_staging.email}"
depends_on = [
google_service_account.dataform_staging
]
}
It is crunch time, as we have all the required infrastructure to provision Dataform in the staging environment.
#staging/dataform.tf
resource "google_dataform_repository" "dataform_demo" {
provider = google-beta
name = "dataform_demo"
project = var.project_id
region = var.region
service_account = "${var.dataform_staging_service_account}@${var.project_id}.iam.gserviceaccount.com"
git_remote_settings {
url = "https://github.com/kbakande/terraforming-dataform"
default_branch = "main"
authentication_token_secret_version = data.google_secret_manager_secret_version.dataform_github_token.id
}
workspace_compilation_overrides {
default_database = var.project_id
}
}
resource "google_dataform_repository_release_config" "prod_release" {
provider = google-beta
project = var.project_id
region = var.region
repository = google_dataform_repository.dataform_demo.name
name = "prod"
git_commitish = "main"
cron_schedule = "30 6 * * *"
code_compilation_config {
default_database = var.project_id
default_location = var.location
default_schema = "dataform"
assertion_schema = "dataform_assertions"
}
depends_on = [
google_dataform_repository.dataform_demo
]
}
resource "google_dataform_repository_workflow_config" "prod_schedule" {
provider = google-beta
project = var.project_id
region = var.region
name = "prod_daily_schedule"
repository = google_dataform_repository.dataform_demo.name
release_config = google_dataform_repository_release_config.prod_release.id
cron_schedule = "45 6 * * *"
invocation_config {
included_tags = []
transitive_dependencies_included = false
transitive_dependents_included = false
fully_refresh_incremental_tables_enabled = false
service_account = var.dataform_prod_service_account
}
depends_on = [
google_dataform_repository.dataform_demo
]
}
The google_dataform_repository resource provisions a dataform repository where the target remote repo is specified along with the token to access the repo. Then we provision the release configuration stating which remote repo branch to generate the compilation from and configuring the time with cron schedule.
Finally, workflow configuration is provisioned with a schedule slightly staggered ahead of the release configuration to ensure that the latest compilation is available when workflow configuration runs.
Once the Dataform is provisioned, a default service account is created along with it in the format service-{project_number}@gcp-sa-dataform.iam.gserviceaccount.com. This default service account would need to impersonate both the staging and prod service accounts to materialise data in those environments.
We modify the iam.tf file in the staging environment to grant the required roles for Dataform default service account to impersonate the service account in the staging environment and access the provisioned secret.
#staging/iam.tf
resource "google_project_iam_member" "dataform_staging_roles" {
for_each = toset([
"roles/bigquery.dataEditor",
"roles/bigquery.dataViewer",
"roles/bigquery.user",
"roles/bigquery.dataOwner",
])
project = var.project_id
role = each.value
member = "serviceAccount:${google_service_account.dataform_staging.email}"
depends_on = [
google_service_account.dataform_staging
]
}
resource "google_service_account_iam_binding" "custom_service_account_token_creator" {
service_account_id = "projects/${var.project_id}/serviceAccounts/${var.dataform_staging_service_account}@${var.project_id}.iam.gserviceaccount.com"
role = "roles/iam.serviceAccountTokenCreator"
members = [
"serviceAccount:@gcp-sa-dataform.iam.gserviceaccount.com">service-${var.project_number}@gcp-sa-dataform.iam.gserviceaccount.com"
]
depends_on = [
module.service-accounts
]
}
resource "google_secret_manager_secret_iam_binding" "github_secret_accessor" {
secret_id = google_secret_manager_secret.dataform_github_token.secret_id
role = "roles/secretmanager.secretAccessor"
members = [
"serviceAccount:@gcp-sa-dataform.iam.gserviceaccount.com">service-${var.project_number}@gcp-sa-dataform.iam.gserviceaccount.com"
]
depends_on = [
google_secret_manager_secret.dataform_github_token,
module.service-accounts,
]
}
Based on the principle of least privilege access control, the IAM binding for targeted resource is used to grant fine-grained access to the default service account.
In order not to prolong this post more than necessary, the terraform code for provisioning resources in prod environment is available in GitHub repo. We only need to provision remote backend bucket and the service account (along with fine grained permissions for default service account) in production environment. If the provisioning is successful, the dataform status in the staging environment should look similar to the image below.

Some pros and cons of the proposed architecture are highlighted as follows:
Pros
- Follows the principle of version control. The proposed architecture has only one version but the code can be materialised in multiple environments.
- Experimentation is confined within the staging environment which mitigate the chance of an unintended modification of production data.
Cons
- Concern that default service account might make unintended change in the production environment but this is mitigated with the least privilege access control.
- Multiple developers working concurrently within the staging environment might override data. Though not shown in this post, the scenario can be mitigated with workspace compilation override and schema suffix features of Dataform.
As with any architecture, there are pros and cons. The ultimate decision should be based on circumstances within the organisation. Hopefully, this post contributes towards making that decision.
Summary
In part 1, We have gone over some terminologies used within GCP Dataform and a walkthrough of the authentication flow for a single repo, multi environment Dataform set up. Terraform code is then provided in this part 2 along with the approach to implement least privilege access control for the service accounts.
I hope you find the post helpful in your understanding of Dataform. Lets connect on Linkedln
Image credit: All images in this post have been created by the Author
References
- https://medium.com/towards-data-science/understanding-dataform-terminologies-and-authentication-flow-aa98c2fbcdfb
- https://github.com/kbakande/terraforming-dataform
- https://www.cloudskillsboost.google/course_templates/443
- https://cloud.google.com/dataform/docs/workspace-compilation-overrides
Terraforming Dataform was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Terraforming Dataform