Leveraging TensorFlow Transform for scaling data pipelines for production environments

Data pre-processing is one of the major steps in any Machine Learning pipeline. Tensorflow Transform helps us achieve it in a distributed environment over a huge dataset.
Before going further into Data Transformation, Data Validation is the first step of the production pipeline process, which has been covered in my article Validating Data in a Production Pipeline: The TFX Way. Have a look at this article to gain better understanding of this article.
I have used Colab for this demo, as it is much easier (and faster) to configure the environment. If you are in the exploration phase, I would recommend Colab as well, as it would help you concentrate on the more important things.
ML Pipeline operations begins with data ingestion and validation, followed by transformation. The transformed data is trained and deployed. I have covered the validation part in my earlier article, and now we will be covering the transformation section. To get a better understanding of pipelines in Tensorflow, have a look at the below article.
TFX | ML Production Pipelines | TensorFlow
As established earlier, we will be using Colab. So we just need to install the tfx library and we are good to go.
! pip install tfx
After installation restart the session to proceed.
Next come the imports.
# Importing Libraries
import tensorflow as tf
from tfx.components import CsvExampleGen
from tfx.components import ExampleValidator
from tfx.components import SchemaGen
from tfx.v1.components import ImportSchemaGen
from tfx.components import StatisticsGen
from tfx.components import Transform
from tfx.orchestration.experimental.interactive.interactive_context import InteractiveContext
from google.protobuf.json_format import MessageToDict
import os
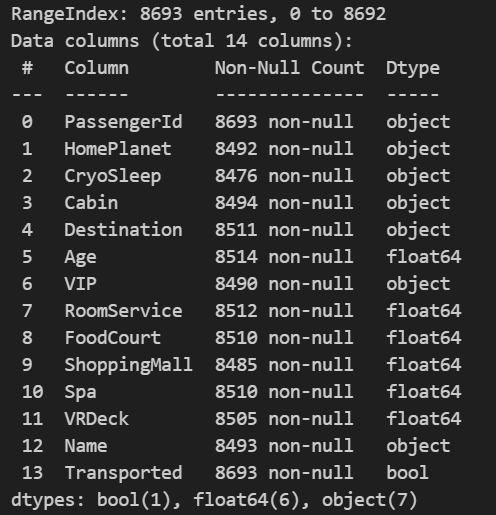
We will be using the spaceship titanic dataset from Kaggle, as in the data validation article. This dataset is free to use for commercial and non-commercial purposes. You can access it from here. A description of the dataset is shown in the below figure.
In order to begin with the data transformation part, it is recommended to create folders where the pipeline components would be placed (else they will be placed in the default directory). I have created two folders, one for the pipeline components and the other for our training data.
# Path to pipeline folder
# All the generated components will be stored here
_pipeline_root = '/content/tfx/pipeline/'
# Path to training data
# It can even contain multiple training data files
_data_root = '/content/tfx/data/'
Next, we create the InteractiveContext, and pass the path to the pipeline directory. This process also creates a sqlite database for storing the metadata of the pipeline process.
InteractiveContext is meant for exploring each stage of the process. At each point, we can have a view of the artifacts that are created. When in a production environment, we will ideally be using a pipeline creation framework like Apache Beam, where this entire process will be executed automatically, without intervention.
# Initializing the InteractiveContext
# This will create an sqlite db for storing the metadata
context = InteractiveContext(pipeline_root=_pipeline_root)
Next, we start with data ingestion. If your data is stored as a csv file, we can use CsvExampleGen, and pass the path to the directory where the data files are stored.
Make sure the folder contains only the training data and nothing else. If your training data is divided into multiple files, ensure they have the same header.
# Input CSV files
example_gen = CsvExampleGen(input_base=_data_root)
TFX currently supports csv, tf.Record, BigQuery and some custom executors. More about it in the below link.
The ExampleGen TFX Pipeline Component | TensorFlow
To execute the ExampleGen component, use context.run.
# Execute the component
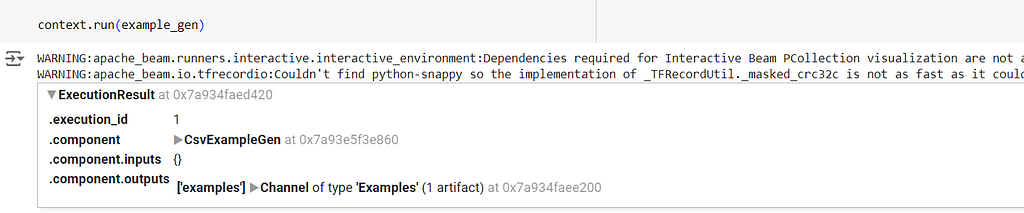
context.run(example_gen)
After running the component, this will be our output. It provides the execution_id, component details and where the component’s outputs are saved.
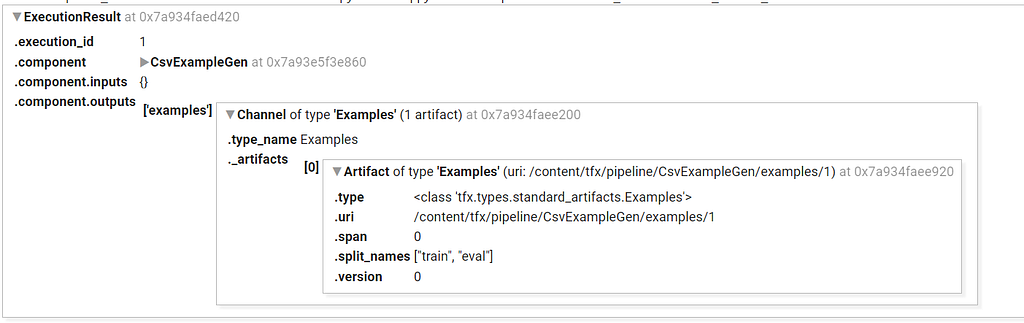
On expanding, we should be able to see these details.
The directory structure looks like the below image. All these artifacts have been created for us by TFX. They are automatically versioned as well, and the details are stored in metadata.sqlite. The sqlite file helps maintain data provenance or data lineage.

To explore these artifacts programatically, use the below code.
# View the generated artifacts
artifact = example_gen.outputs['examples'].get()[0]
# Display split names and uri
print(f'split names: {artifact.split_names}')
print(f'artifact uri: {artifact.uri}')
The output would be the name of the files and the uri.

Let us copy the train uri and have a look at the details inside the file. The file is stored as a zip file and is stored in TFRecordDataset format.
# Get the URI of the output artifact representing the training examples
train_uri = os.path.join(artifact.uri, 'Split-train')
# Get the list of files in this directory (all compressed TFRecord files)
tfrecord_filenames = [os.path.join(train_uri, name)
for name in os.listdir(train_uri)]
# Create a `TFRecordDataset` to read these files
dataset = tf.data.TFRecordDataset(tfrecord_filenames, compression_type="GZIP")
The below code is obtained from Tensorflow, it is the standard code that can be used to pick up records from TFRecordDataset and returns the results for us to examine.
# Helper function to get individual examples
def get_records(dataset, num_records):
'''Extracts records from the given dataset.
Args:
dataset (TFRecordDataset): dataset saved by ExampleGen
num_records (int): number of records to preview
'''
# initialize an empty list
records = []
# Use the `take()` method to specify how many records to get
for tfrecord in dataset.take(num_records):
# Get the numpy property of the tensor
serialized_example = tfrecord.numpy()
# Initialize a `tf.train.Example()` to read the serialized data
example = tf.train.Example()
# Read the example data (output is a protocol buffer message)
example.ParseFromString(serialized_example)
# convert the protocol bufffer message to a Python dictionary
example_dict = (MessageToDict(example))
# append to the records list
records.append(example_dict)
return records
# Get 3 records from the dataset
sample_records = get_records(dataset, 3)
# Print the output
pp.pprint(sample_records)
We requested for 3 records, and the output looks like this. Every record and its metadata are stored in dictionary format.

Next, we move ahead to the subsequent process, which is to generate the statistics for the data using StatisticsGen. We pass the outputs from the example_gen object as the argument.
We execute the component using statistics.run, with statistics_gen as the argument.
# Generate dataset statistics with StatisticsGen using the example_gen object
statistics_gen = StatisticsGen(
examples=example_gen.outputs['examples'])
# Execute the component
context.run(statistics_gen)
We can use context.show to view the results.
# Show the output statistics
context.show(statistics_gen.outputs['statistics'])
You can see that it is very similar to the statistics generation that we have discussed in the TFDV article. The reason is, TFX uses TFDV under the hood to perform these operations. Getting familiar with TFDV will help understand these processes better.
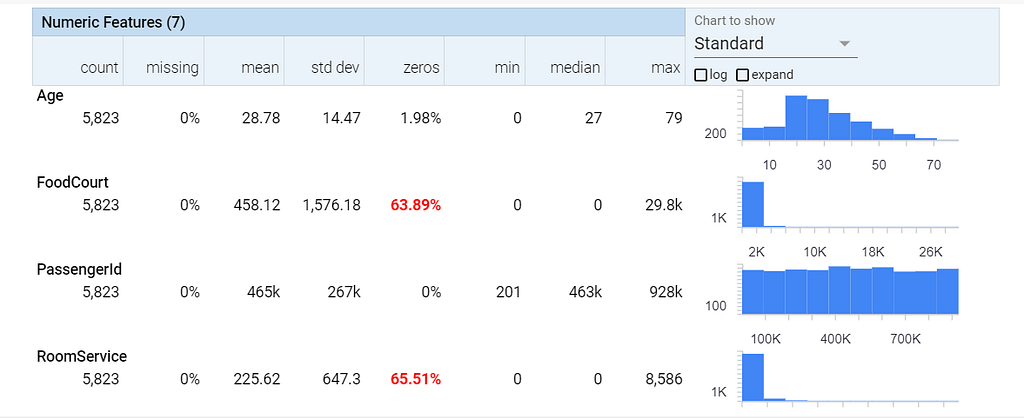
Next step is to create the schema. This is done using the SchemaGen by passing the statistics_gen object. Run the component and visualize it using context.show.
# Generate schema using SchemaGen with the statistics_gen object
schema_gen = SchemaGen(
statistics=statistics_gen.outputs['statistics'],
)
# Run the component
context.run(schema_gen)
# Visualize the schema
context.show(schema_gen.outputs['schema'])
The output shows details about the underlying schema of the data. Again, same as in TFDV.
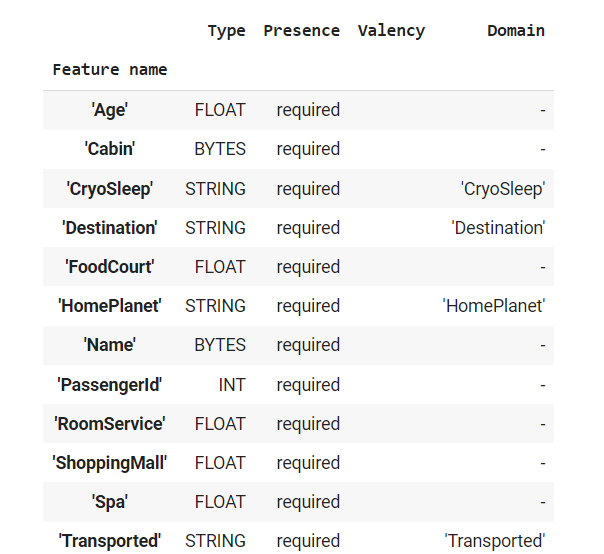
If you need to make modifications to the schema presented here, make them using tfdv, and create a schema file. You can pass it using the ImportSchemaGen and ask tfx to use the new file.
# Adding a schema file manually
schema_gen = ImportSchemaGen(schema_file="path_to_schema_file/schema.pbtxt")
Next, we validate the examples using the ExampleValidator. We pass the statistics_gen and schema_gen as arguments.
# Validate the examples using the ExampleValidator
# Pass statistics_gen and schema_gen objects
example_validator = ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_gen.outputs['schema'])
# Run the component.
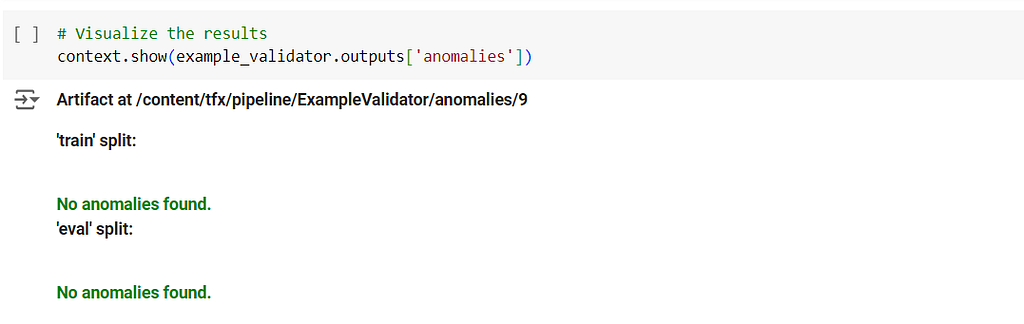
context.run(example_validator)
This should be your ideal output to show that all is well.
At this point, our directory structure looks like the below image. We can see that for every step in the process, the corresponding artifacts are created.

Let us move to the actual transformation part. We will now create the constants.py file to add all the constants that are required for the process.
# Creating the file containing all constants that are to be used for this project
_constants_module_file = 'constants.py'
We will create all the constants and write it to the constants.py file. See the “%%writefile {_constants_module_file}”, this command does not let the code run, instead, it writes all the code in the given cell into the specified file.
%%writefile {_constants_module_file}
# Features with string data types that will be converted to indices
CATEGORICAL_FEATURE_KEYS = [ 'CryoSleep','Destination','HomePlanet','VIP']
# Numerical features that are marked as continuous
NUMERIC_FEATURE_KEYS = ['Age','FoodCourt','RoomService', 'ShoppingMall','Spa','VRDeck']
# Feature that can be grouped into buckets
BUCKET_FEATURE_KEYS = ['Age']
# Number of buckets used by tf.transform for encoding each bucket feature.
FEATURE_BUCKET_COUNT = {'Age': 4}
# Feature that the model will predict
LABEL_KEY = 'Transported'
# Utility function for renaming the feature
def transformed_name(key):
return key + '_xf'
Let us create the transform.py file, which will contain the actual code for transforming the data.
# Creating a file that contains all preprocessing code for the project
_transform_module_file = 'transform.py'
Here, we will be using the tensorflow_transform library. The code for transformation process will be written under the preprocessing_fn function. It is mandatory we use the same name, as tfx internally searches for it during the transformation process.
%%writefile {_transform_module_file}
import tensorflow as tf
import tensorflow_transform as tft
import constants
# Unpack the contents of the constants module
_NUMERIC_FEATURE_KEYS = constants.NUMERIC_FEATURE_KEYS
_CATEGORICAL_FEATURE_KEYS = constants.CATEGORICAL_FEATURE_KEYS
_BUCKET_FEATURE_KEYS = constants.BUCKET_FEATURE_KEYS
_FEATURE_BUCKET_COUNT = constants.FEATURE_BUCKET_COUNT
_LABEL_KEY = constants.LABEL_KEY
_transformed_name = constants.transformed_name
# Define the transformations
def preprocessing_fn(inputs):
outputs = {}
# Scale these features to the range [0,1]
for key in _NUMERIC_FEATURE_KEYS:
outputs[_transformed_name(key)] = tft.scale_to_0_1(
inputs[key])
# Bucketize these features
for key in _BUCKET_FEATURE_KEYS:
outputs[_transformed_name(key)] = tft.bucketize(
inputs[key], _FEATURE_BUCKET_COUNT[key])
# Convert strings to indices in a vocabulary
for key in _CATEGORICAL_FEATURE_KEYS:
outputs[_transformed_name(key)] = tft.compute_and_apply_vocabulary(inputs[key])
# Convert the label strings to an index
outputs[_transformed_name(_LABEL_KEY)] = tft.compute_and_apply_vocabulary(inputs[_LABEL_KEY])
return outputs
We have used a few standard scaling and encoding functions for this demo. The transform library actually hosts a whole lot of functions. Explore them here.
Module: tft | TFX | TensorFlow
Now it is time to see the transformation process in action. We create a Transform object, and pass example_gen and schema_gen objects, along with the path to the transform.py we created.
# Ignore TF warning messages
tf.get_logger().setLevel('ERROR')
# Instantiate the Transform component with example_gen and schema_gen objects
# Pass the path for transform file
transform = Transform(
examples=example_gen.outputs['examples'],
schema=schema_gen.outputs['schema'],
module_file=os.path.abspath(_transform_module_file))
# Run the component
context.run(transform)
Run it and the transformation part is complete!
Take a look at the transformed data shown in the below image.

Why not just use scikit-learn library or pandas to do this?
This is your question now, right?
This process is not meant for an individual wanting to preprocess their data and get going with model training. It is meant to be applied on large amounts of data (data that mandates distributed processing) and an automated production pipeline that can’t afford to break.
After applying the transform, your folder structure looks like this
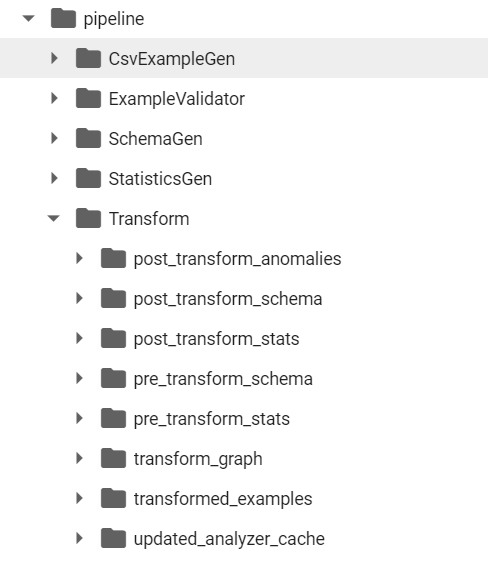
It contains pre and post transform details. Further, a transform graph is also created.
Remember, we scaled our numerical features using tft.scale_to_0_1. Functions like this requires computing details that require analysis of the entire data (like the mean, minimum and maximum values in a feature). Analyzing data distributed over multiple machines, to get these details is performance intensive (especially if done multiple times). Such details are calculated once and maintained in the transform_graph. Any time a function needs them, it is directly fetched from the transform_graph. It also aids in applying transforms created during the training phase directly to serving data, ensuring consistency in the pre-processing phase.
Another major advantage is of using Tensorflow Transform libraries is that every phase is recorded as artifacts, hence data lineage is maintained. Data Versioning is also automatically done when the data changes. Hence it makes experimentation, deployment and rollback easy in a production environment.
That’s all to it. If you have any questions please jot them down in the comments section.
You can download the notebook and the data files used in this article from my GitHub repository using this link
What Next?
To get a better understanding of the pipeline components, read the below article.
Understanding TFX Pipelines | TensorFlow
Thanks for reading my article. If you like it, please encourage by giving me a few claps, and if you are in the other end of the spectrum, let me know what can be improved in the comments. Ciao.
Unless otherwise noted, all images are by the author.
TensorFlow Transform: Ensuring Seamless Data Preparation in Production was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
TensorFlow Transform: Ensuring Seamless Data Preparation in Production
Go Here to Read this Fast! TensorFlow Transform: Ensuring Seamless Data Preparation in Production