

What “temperature” is, how it works, its relationship to the beam search heuristic, and how LLM output generation can still go haywire
If you’ve spent any time with APIs for LLMs like those from OpenAI or Anthropic, you’ll have seen the temperature setting available in the API. How is this parameter used, and how does it work?
From the Anthropic chat API documentation:
temperature (number)
Amount of randomness injected into the response.
Defaults to 1.0. Ranges from 0.0 to 1.0. Use temperature closer to 0.0 for
analytical / multiple choice, and closer to 1.0 for creative and
generative tasks.
Note that even with temperature of 0.0, the results will not be
fully deterministic.
Temperature (as is generally implemented) doesn’t really inject randomness into the response. In this post, I’ll walk through what this setting does, and how it’s used in beam search, the most common text generation technique for LLMs, as well as demonstrate some output-generation examples (failures and successes) using a reference implementation in Github.
What you’re getting yourself into:
- Revisiting LLM Inference and Token Prediction
- Greedy Search
- Beam Search
- Temperature
- Implementation Details
- Greedy Search and Beam Search Generation Examples
– Greedy Search
– Beam Search
– Beam Search with Temperature
– Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo and Scoring Penalties - Conclusion
Revisiting LLM Inference and Token Prediction
If you’re here, you probably have some understanding of how LLMs work.
At a high level, LLM text generation involves predicting the next token in a sequence, which depends on the cumulative probability of the preceding tokens. This process utilizes internal probability distributions that are shaped by:
- The model’s internal, learned weights, refined through extensive training on vast datasets
- The entire input context (the query and any other augmenting data or documents)
- The set of tokens generated thus far
Transformer-based generative models build representations of their input contexts through Self-Attention, allowing them to dynamically assess and prioritize different parts of the input based on their relevance to the current prediction point. During sequence decoding, these models evaluate how each part of the input influences the emerging sequence, ensuring that each new token reflects an integration of both the input and the evolving output (largely through Cross-Attention).
The Stanford CS224N course materials are a great resource for these concepts.
The key point I want to make here is that when the model decides on the probabilistically best token, it’s generally evaluating the entire input context, as well as the entire generated sequence in-progress. However, the most intuitive process for using these predictions to iteratively build text sequences is simplistic: a greedy algorithm, where the output text is built based on the most-likely token at every step.
Below I’ll discuss how it works, where it fails, and some techniques used to adapt to those failures.
Greedy Search
The most natural way to use a model to build an output sequence is to gradually predict the next-best token, append it to a generated sequence, and continue until the end of generation. This is called greedy search, and is the most simple and efficient way to generate text from an LLM (or other model). In its most basic form, it looks something like this:
sequence = ["<start>"]
while sequence[-1] != "<end>":
# Given the input context, and seq so far, append most likely next token
sequence += model(input, sequence)
return "".join(sequence)
Undergrad Computer Science algorithms classes have a section on graph traversal algorithms. If you model the universe of potential LLM output sequences as a graph of tokens, then the problem of finding the optimal output sequence, given input context, closely resembles the problem of traversing a weighted graph. In this case, the edge “weights” are probabilities generated from attention scores, and the goal of the traversal is to minimize the overall cost (maximize the overall probability) from beginning to end.

Out of all possible text generation methods, this is the most computationally efficient — the number of inferences is 1:1 with the number of output tokens. However, there are some problems.
At every step of token generation, the algorithm selects the highest-probability token given the output sequence so far, and appends it to that sequence. This is the simplicity and flaw of this approach, along with all other greedy algorithms — it gets trapped in local minima. Meaning, what appears to be the next-best token right now may not, in fact, be the next-best token for the generated output overall.
"We can treat it as a matter of"
[course (p=0.9) | principle (p=0.5)] | cause (p=0.2)]"
Given some input context and the generated string so far, We can treat it as a matter of course seems like a logical and probable sequence to generate.
But what if the contextually-accurate sentence is We can treat it as a matter of cause and effect? Greedy search has no way to backtrack and rewrite the sequence token course with cause and effect. What seemed like the best token at the time actually trapped output generation into a suboptimal sequence.
The need to account for lower-probability tokens at each step, in the hope that better output sequences are generated later, is where beam search is useful.
Beam Search
Returning to the graph-search analogy, in order to generate the optimal text for any given query and context, we’d have to fully explore the universe of potential token sequences. The solution resembles the A* search algorithm (more closely than Dijkstra’s algorithm, since we don’t necessarily want shortest path, but lowest-cost/highest-likelihood).

Since we’re working with natural language, the complexity involved is far too high to exhaust the search space for every query in most contexts. The solution is to trim that search space down to a reasonable number of candidate paths through the candidate token graph; maybe just 4, 8, or 12.
Beam search is the heuristic generally used to approximate that ideal A*-like outcome. This technique maintains k candidate sequences which are incrementally built up with the respective top-k most likely tokens. Each of these tokens contributes to an overall sequence score, and after each step, the total set of candidate sequences are pruned down to the best-scoring top k.

The “beam” in beam search borrows the analogy of a flashlight, whose beam can be widened or narrowed. Taking the example of generating the quick brown fox jumps over the lazy dog with a beam width of 2, the process looks something like this:

At this step, two candidate sequences are being maintained: “the” and “a”. Each of these two sequences need to evaluate the top-two most likely tokens to follow.
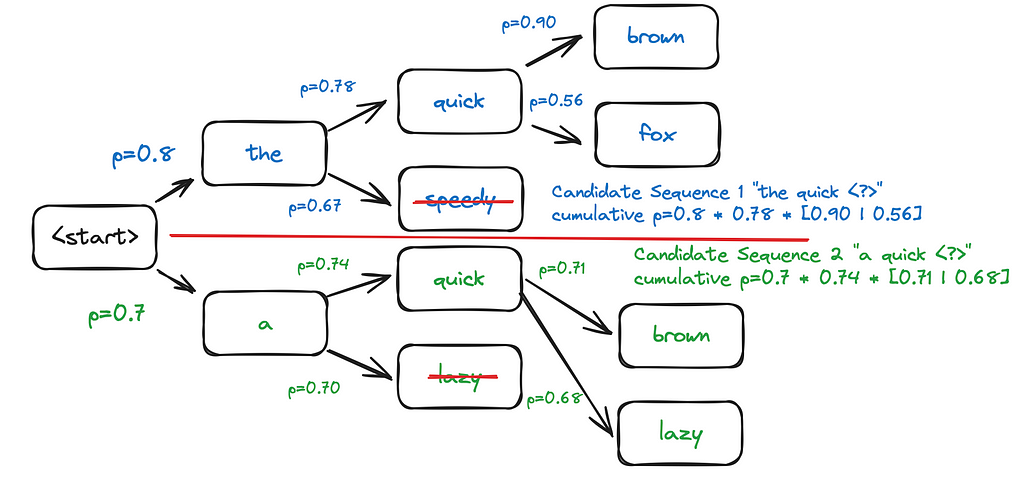
After the next step, “the speedy” has been eliminated, and “the quick” has been selected as the first candidate sequence. For the second, “a lazy” has been eliminated, and “a quick” has been selected, as it has a higher cumulative probability. Note that if both candidates above the line have a higher likelihood that both candidates below the line, then they will represent the two candidate sequences after the subsequent step.
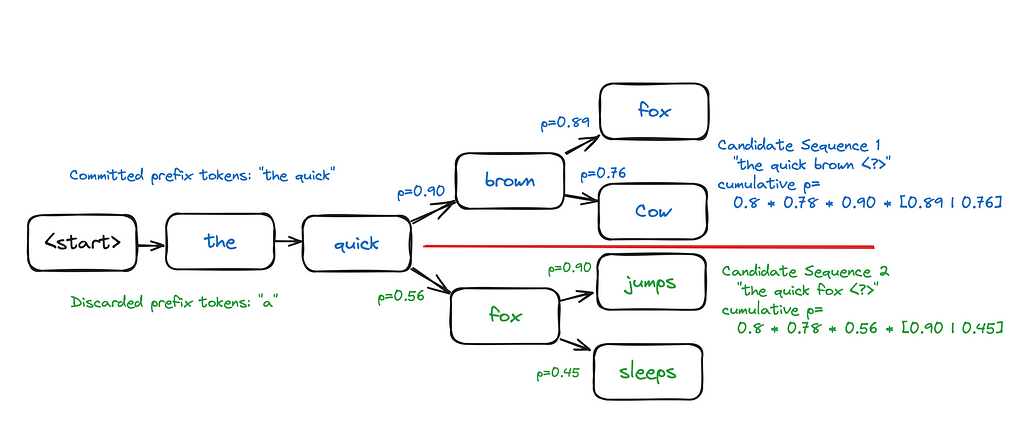
This process continues until either a maximum token length limit has been reached, or all candidate sequences have appended an end-of-sequence token, meaning we’ve concluded generating text for that sequence.
Increasing the beam width increases the search space, increasing the likelihood of a better output, but at a corresponding increase space and computational cost. Also note that a beam search with beam_width=1 is effectively identical to greedy search.
Temperature
Now, what does temperature have to do with all of this? As I mentioned above, this parameter doesn’t really inject randomness into the generated text sequence, but it does modify the predictability of the output sequences. Borrowing from information theory: temperature can increase or decrease the entropy associated with a token prediction.
The softmax activation function is typically used to convert the raw outputs (ie, logits) of a model’s (including LLMs) prediction into a probability distribution (I walked through this a little here). This function is defined as follows, given a vector Z with n elements:

This function emits a vector (or tensor) of probabilities, which sum to 1.0 and can be used to clearly assess the model’s confidence in a class prediction in a human-interpretable way.
A “temperature” scaling parameter T can be introduced which scales the logit values prior to the application of softmax.
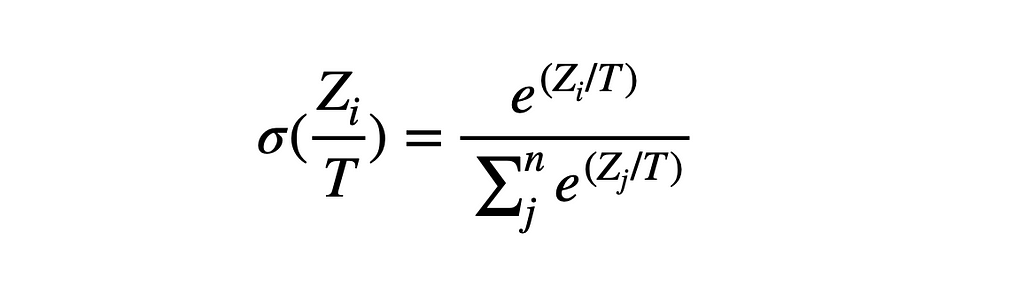
The application of T > 1.0 has the effect of scaling down logit values and produces the effect of the muting the largest differences between the probabilities of the various classes (it increases entropy within the model’s predictions)
Using a temperature of T < 1.0 has the opposite effect; it magnifies the differences, meaning the most confident predictions will stand out even more compared to alternatives. This reduces the entropy within the model’s predictions.
In code, it looks like this:
scaled_logits = logits_tensor / temperature
probs = torch.softmax(scaled_logits, dim=-1)
Take a look at the effect over 8 possible classes, given some hand-written logit values:

The above graph was plotted using the following values:
ts = [0.5, 1.0, 2.0, 4.0, 8.0]
logits = torch.tensor([3.123, 5.0, 3.234, 2.642, 2.466, 3.3532, 3.8, 2.911])
probs = [torch.softmax(logits / t, dim=-1) for t in ts]
The bars represent the logit values (outputs from model prediction), and the lines represent the probability distribution over those classes, with probabilities defined on the right-side label. The thick red line represents the expected distribution, with temperature T=1.0, while the other lines demonstrate the change in relative likelihood with a temperature range from 0.5 to 8.0.
You can clearly see how T=0.5 emphasizes the likelihood of the largest-magnitude logit index, while T=8.0 reduces the difference in probabilities between classes to almost nothing.
>>> [print(f' t={t}n l={(logits/t)}n p={p}n') for p,t in zip(probs, ts)]
t=0.5
l=tensor([6.2460, 10.000, 6.4680, 5.2840, 4.9320, 6.7064, 7.6000, 5.8220])
p=tensor([0.0193, 0.8257, 0.0241, 0.0074, 0.0052, 0.0307, 0.0749, 0.0127])
t=1.0
l=tensor([3.1230, 5.0000, 3.2340, 2.6420, 2.4660, 3.3532, 3.8000, 2.9110])
p=tensor([0.0723, 0.4727, 0.0808, 0.0447, 0.0375, 0.0911, 0.1424, 0.0585])
t=2.0
l=tensor([1.5615, 2.5000, 1.6170, 1.3210, 1.2330, 1.6766, 1.9000, 1.4555])
p=tensor([0.1048, 0.2678, 0.1108, 0.0824, 0.0754, 0.1176, 0.1470, 0.0942])
t=4.0
l=tensor([0.7807, 1.2500, 0.8085, 0.6605, 0.6165, 0.8383, 0.9500, 0.7278])
p=tensor([0.1169, 0.1869, 0.1202, 0.1037, 0.0992, 0.1238, 0.1385, 0.1109])
t=8.0
l=tensor([0.3904, 0.6250, 0.4042, 0.3302, 0.3083, 0.4191, 0.4750, 0.3639])
p=tensor([0.1215, 0.1536, 0.1232, 0.1144, 0.1119, 0.1250, 0.1322, 0.1183])
Now, this doesn’t necessarily change the relative likelihood between any two classes (numerical stability issues aside), so how does this have any practical effect in sequence generation?
The answer lies back in the mechanics of beam search. A temperature value greater than 1.0 makes it less likely a high-scoring individual token will outweigh a series of slightly-less-likely tokens, which in conjunction result in a better-scoring output.
>>> sum([0.9, 0.3, 0.3, 0.3]) # raw probabilities
1.8 # dominated by first token
>>> sum([0.8, 0.4, 0.4, 0.4]) # temperature-scaled probabilities
2.0 # more likely overall outcome
Implementation Details
Beam search implementations typically work with log-probabilities of the softmax probabilities, which is common in the ML domain among many others. The reasons include:
- The probabilities in use are often vanishingly small; using log probs improves numerical stability
- We can compute a cumulative probability of outcomes via the addition of logprobs versus the multiplication of raw probabilities, which is slightly computationally faster as well as more numerically stable. Recall that p(x) * p(y) == log(p(x)) + log(p(y))
- Optimizers, such as gradient descent, are simpler when working with log probs, which makes derivative calculations more simple and loss functions like cross-entropy loss already involve logarithmic calculations
This also means that the values of the log probs we’re using as scores are negative real numbers. Since softmax produces a probability distribution which sums to 1.0, the logarithm of any class probability is thus ≤ 1.0 which results in a negative value. This is slightly annoying, however it is consistent with the property that higher-valued scores are better, while greatly negative scores reflect extremely unlikely outcomes:
>>> math.log(3)
1.0986122886681098
>>> math.log(0.99)
-0.01005033585350145
>>> math.log(0.98)
-0.020202707317519466
>>> math.log(0.0001)
-9.210340371976182
>>> math.log(0.000000000000000001)
-41.44653167389282
Here’s most of the example code, highly annotated, also available on Github. Definitions for GeneratedSequence and ScoredToken can be found here; these are mostly simple wrappers for tokens and scores.
# The initial candidate sequence is simply the start token ID with
# a sequence score of 0
candidate_sequences = [
GeneratedSequence(tokenizer, start_token_id, end_token_id, 0.0)
]
for i in tqdm.tqdm(range(max_length)):
# Temporary list to store candidates for the next generation step
next_step_candidates = []
# Iterate through all candidate sequences; for each, generate the next
# most likely tokens and add them to the next-step sequnce of candidates
for candidate in candidate_sequences:
# skip candidate sequences which have included the end-of-sequence token
if not candidate.has_ended():
# Build a tensor out of the candidate IDs; add a single batch dimension
gen_seq = torch.tensor(candidate.ids(), device=device).unsqueeze(0)
# Predict next token
output = model(input_ids=src_input_ids, decoder_input_ids=gen_seq)
# Extract logits from output
logits = output.logits[:, -1, :]
# Scale logits using temperature value
scaled_logits = logits / temperature
# Construct probability distribution against scaled
# logits through softmax activation function
probs = torch.softmax(scaled_logits, dim=-1)
# Select top k (beam_width) probabilities and IDs from the distribution
top_probs, top_ids = probs.topk(beam_width)
# For each of the top-k generated tokens, append to this
# candidate sequence, update its score, and append to the list of next
# step candidates
for i in range(beam_width):
# the new token ID
next_token_id = top_ids[:, i].item()
# log-prob of the above token
next_score = torch.log(top_probs[:, i]).item()
new_seq = deepcopy(candidate)
# Adds the new token to the end of this sequence, and updates its
# raw and normalized scores. Scores are normalized by sequence token
# length, to avoid penalizing longer sequences
new_seq.append(ScoredToken(next_token_id, next_score))
# Append the updated sequence to the next candidate sequence set
next_step_candidates.append(new_seq)
else:
# Append the canddiate sequence as-is to the next-step candidates
# if it already contains an end-of-sequence token
next_step_candidates.append(candidate)
# Sort the next-step candidates by their score, select the top-k
# (beam_width) scoring sequences and make them the new
# candidate_sequences list
next_step_candidates.sort()
candidate_sequences = list(reversed(next_step_candidates))[:beam_width]
# Break if all sequences in the heap end with the eos_token_id
if all(seq.has_ended() for seq in candidate_sequences):
break
return candidate_sequences
In the next section, you can find some results of running this code on a few different datasets with different parameters.
Greedy Search and Beam Search Generation Examples
As I mentioned, I’ve published some example code to Github, which uses the t5-small transformer model from Hugging Face and its corresponding T5Tokenizer. The examples below were run through the T5 model against the quick brown fox etc Wikipedia page, sanitized through an extractor script.
Greedy Search
Running –greedy mode:
$ python3 src/main.py --greedy --input ./wiki-fox.txt --prompt "summarize the following document"
greedy search generation results:
[
the phrase is used in the annual Zaner-Bloser National Handwriting Competition.
it is used for typing typewriters and keyboards, typing fonts. the phrase
is used in the earliest known use of the phrase.
]
This output summarizes part of the article well, but overall is not great. It’s missing initial context, repeats itself, and doesn’t state what the phrase actually is.
Beam Search
Let’s try again, this time using beam search for output generation, using an initial beam width of 4 and the default temperature of 1.0
$ python3 src/main.py --beam 4 --input ./wiki-fox.txt --prompt "summarize the following document"
[lots of omitted output]
beam search (k=4, t=1.0) generation results:
[
"the quick brown fox jumps over the lazy dog" is an English-language pangram.
the phrase is commonly used for touch-typing practice, typing typewriters and
keyboards. it is used in the annual Zaner-Bloser National
Handwriting Competition.
]
This output is far superior to the greedy output above, and the most remarkable thing is that we’re using the same model, prompt and input context to generate it.
There are still a couple mistakes in it; for example “typing typewriters”, and perhaps “keyboards” is ambiguous.
The beam search code I shared will emit its decision-making progress as it progresses through the text generation (full output here). For example, the first two steps:
beginning beam search | k = 4 bos = 0 eos = 1 temp = 1.0 beam_width = 4
0.0: [], next token probabilities:
p: 0.30537632: ▁the
p: 0.21197866: ▁"
p: 0.13339639: ▁phrase
p: 0.13240208: ▁
next step candidates:
-1.18621039: [the]
-1.55126965: ["]
-2.01443028: [phrase]
-2.02191186: []
-1.1862103939056396: [the], next token probabilities:
p: 0.61397356: ▁phrase
p: 0.08461960: ▁
p: 0.06939770: ▁"
p: 0.04978605: ▁term
-1.5512696504592896: ["], next token probabilities:
p: 0.71881396: the
p: 0.08922042: qui
p: 0.05990228: The
p: 0.03147057: a
-2.014430284500122: [phrase], next token probabilities:
p: 0.27810165: ▁used
p: 0.26313403: ▁is
p: 0.10535818: ▁was
p: 0.03361856: ▁
-2.021911859512329: [], next token probabilities:
p: 0.72647911: earliest
p: 0.19509122: a
p: 0.02678721: '
p: 0.00308457: s
next step candidates:
-1.67401379: [the phrase]
-1.88142237: ["the]
-2.34145740: [earliest]
-3.29419887: [phrase used]
-3.34952199: [phrase is]
-3.65579963: [the]
-3.65619993: [a]
Now if we look at the set of candidates in the last step:
next step candidates:
-15.39409454: ["the quick brown fox jumps over the lazy dog" is an English-language pangram. the phrase is commonly used for touch-typing practice, typing typewriters and keyboards. it is used in the annual Zaner-Bloser National Handwriting Competition.]
-16.06867695: ["the quick brown fox jumps over the lazy dog" is an English-language pangram. the phrase is commonly used for touch-typing practice, testing typewriters and keyboards. it is used in the annual Zaner-Bloser National Handwriting Competition.]
-16.10376084: ["the quick brown fox jumps over the lazy dog" is an English-language pangram. the phrase is commonly used for touch-typing practice, typing typewriters and keyboards. it is used in the annual Zaner-Bloser national handwriting competition.]
You can see that the top-scoring sentence containing typing typewriters outscored the sentence containing testing typewriters by -15.39 to -16.06, which, if we raise to Euler’s constant to convert back into cumulative probabilities, is a probabilistic difference of just 0.00001011316%. There must be a way to overcome this tiny difference!
Beam Search with Temperature
Let’s see if this summarization could be improved by applying a temperature value to smooth over some of the log probability scores. Again, everything else, the model, and the input context, will otherwise be identical to the examples above.
$ python3 src/main.py --beam 4 --temperature 4.0 --input ./wiki-fox.txt --prompt "summarize the following document"
[lots of omitted output]
beam search (k=4, t=4.0) generation results:
[
"the quick brown fox jumps over the lazy dog" is an English-language pangram.
it is commonly used for touch-typing practice, testing typewriters and
computer keyboards. earliest known use of the phrase started with "A"
]
This output correctly emitted “testing typewriters” rather than “typing typewriters” and specified “computer keyboards”. It also, interestingly, chose the historical fact that this phrase originally started with “a quick brown fox” over the Zaner-Bloser competition fact above. The full output is also available here.
Whether or not this output is better is a subjective matter of opinion. It’s different in a few nuanced ways, and the usage and setting of temperature values will vary by application. I think its better, and again, its interesting because no model weights, model architecture, or prompt was changed to obtain this output.
Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo and Scoring Penalties
Let’s see if the beam search, with temperature settings used above, works properly for my favorite English-language linguistic construct: Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo.
$ python3 src/main.py --beam 4 --temperature 4.0 --input ./wiki-buffalo.txt --prompt "summarize the linguistic construct in the following text"
[lots of omitted outputs]
beam search (k=4, t=4.0) generation results:
[
"Buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo
buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo
buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo
buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo
buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo
buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo
buffalo buffalo buffalo buffalo buffalo buffalo
]
Utter disaster, though a predictable one. Given the complexity of this input document, we need additional techniques to handle contexts like this. Interestingly, the final iteration candidates didn’t include a single rational sequence:
next step candidates:
-361.66266489: ["Buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo]
-362.13168168: ["buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo]
-362.22955942: ["Buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo.]
-362.60354519: ["Buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo]
-363.03604889: ["Buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo,]
-363.07167459: ["buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo]
-363.14155817: ["Buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo Buffalo]
-363.28574753: ["Buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo. the]
-363.35553551: ["Buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo a]
[more of the same]
We can apply a token-specific score decay (more like a penalty) to repeated tokens, which makes them appear less attractive (or more accurately, less likely solutions) to the beam search algorithm:
token_counts = Counter(t.token_id for t in candidate)
# For each of the top-k generated tokens, append to this candidate sequence,
# update its score, and append to the list of next step candidates
for i in range(beam_width):
next_token_id = top_ids[:, i].item() # the new token ID
next_score = torch.log(top_probs[:, i]).item() # log-prob of the above token
# Optionally apply a token-specific score decay to repeated tokens
if decay_repeated and next_token_id in token_counts:
count = token_counts[next_token_id]
decay = 1 + math.log(count + 1)
next_score *= decay # inflate the score of the next sequence accordingly
new_seq = deepcopy(candidate)
new_seq.append(ScoredToken(next_token_id, next_score))
Which results in the following, more reasonable output:
$ python3 src/main.py --decay --beam 4 --temperature 4.0 --input ./wiki-buffalo.txt --prompt "summarize the linguistic construct in the following text"
[lots of omitted outputs]
beam search (k=4, t=4.0) generation results:
[
"Buffalo buffalo" is grammatically correct sentence in English, often
presented as an example of how homophonies can be used to create complicated
language constructs through unpunctuated terms and sentences. it uses three
distinct meanings:An attributive noun (acting
]
You can see where where the scoring penalty pulled the infinite buffalos sequence below the sequence resulting in the above output:
next step candidates:
-36.85023594: ["Buffalo buffalo Buffalo]
-37.23766947: ["Buffalo buffalo"]
-37.31325269: ["buffalo buffalo Buffalo]
-37.45994210: ["buffalo buffalo"]
-37.61866760: ["Buffalo buffalo,"]
-37.73602080: ["buffalo" is]
[omitted]
-36.85023593902588: ["Buffalo buffalo Buffalo], next token probabilities:
p: 0.00728357: ▁buffalo
p: 0.00166316: ▁Buffalo
p: 0.00089072: "
p: 0.00066582: ,"
['▁buffalo'] count: 1 decay: 1.6931471805599454, score: -4.922133922576904, next: -8.33389717334955
['▁Buffalo'] count: 1 decay: 1.6931471805599454, score: -6.399034023284912, next: -10.834506414832013
-37.237669467926025: ["Buffalo buffalo"], next token probabilities:
p: 0.00167652: ▁is
p: 0.00076465: ▁was
p: 0.00072227: ▁
p: 0.00064367: ▁used
-37.313252687454224: ["buffalo buffalo Buffalo], next token probabilities:
p: 0.00740433: ▁buffalo
p: 0.00160758: ▁Buffalo
p: 0.00091487: "
p: 0.00066765: ,"
['▁buffalo'] count: 1 decay: 1.6931471805599454, score: -4.905689716339111, next: -8.306054711921485
['▁Buffalo'] count: 1 decay: 1.6931471805599454, score: -6.433023929595947, next: -10.892056328870039
-37.45994210243225: ["buffalo buffalo"], next token probabilities:
p: 0.00168198: ▁is
p: 0.00077098: ▁was
p: 0.00072504: ▁
p: 0.00065945: ▁used
next step candidates:
-43.62870741: ["Buffalo buffalo" is]
-43.84772754: ["buffalo buffalo" is]
-43.87371445: ["Buffalo buffalo Buffalo"]
-44.16472149: ["Buffalo buffalo Buffalo,"]
-44.30998302: ["buffalo buffalo Buffalo"]
So it turns out we need additional hacks (techniques) like this, to handle special kinds of edge cases.
Conclusion
This turned out to be much longer than what I was planning to write; I hope you have a few takeaways. Aside from simply understanding how beam search and temperature work, I think the most interesting illustration above is how, even given the incredible complexity and capabilities of LLMs, implementation choices affecting how their predictions are used have a huge effect on the quality on their output. The application of simple undergraduate Computer Science concepts to sequence construction can result in dramatically different LLM outputs, even with all other input being identical.
When we encounter hallucinations, errors, or other quirks when working with LLMs, its entirely possible (and perhaps likely) that these are quirks with the output sequence construction algorithms, rather than any “fault” of the trained model itself. To the user of an API, it’s almost impossible to tell the difference.
I think this is an interesting example of the complexity of the machinery around LLMs which make them such powerful tools and products today.
Temperature Scaling and Beam Search Text Generation in LLMs, for the ML-Adjacent was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Temperature Scaling and Beam Search Text Generation in LLMs, for the ML-Adjacent