Was your EV that cold?

Atmospheric temperature is not just a weather condition but a crucial determinant of EV battery performance. Recent events have underscored the severe impact of extremely low temperatures on EV battery performance, reducing vehicle ranges and causing potential charging issues. The role of temperature reconstruction in post-mortem analyses of electric fleet performance is not just a theoretical concept but a practical tool that can significantly enhance our understanding and improve EV battery performance, a key concern in the EV industry.
In this article, I present a practical method for historic temperature reconstruction. This method, which uses spatiotemporal interpolation and a reduced set of measurement points, can be applied to enhance and improve our understanding of EV battery performance.
The Problem
We want to reconstruct the historic atmospheric temperature of over twenty-two million timestamped locations without issuing the same amount of queries to the data provider [1]. The Open-Meteo provider limits the number of daily requests for its free access tier, so it is in our best interest to devise a solution to limit the number of data queries while retaining good precision.
This article uses the Extended Vehicle Energy Dataset [2] in its raw CSV format. The dataset contains vehicle telematics collected around Ann Arbor, Michigan, between November 2017 and November 2018. The dataset includes samples of the outside temperature measured by the vehicles, but as we will see, they are noisy and inadequate for calibration.
Our problem is to devise an interpolation model that uses a reduced set of ground-truth temperatures from the data provider and derive high-accuracy predictions over the target data.
The Solution
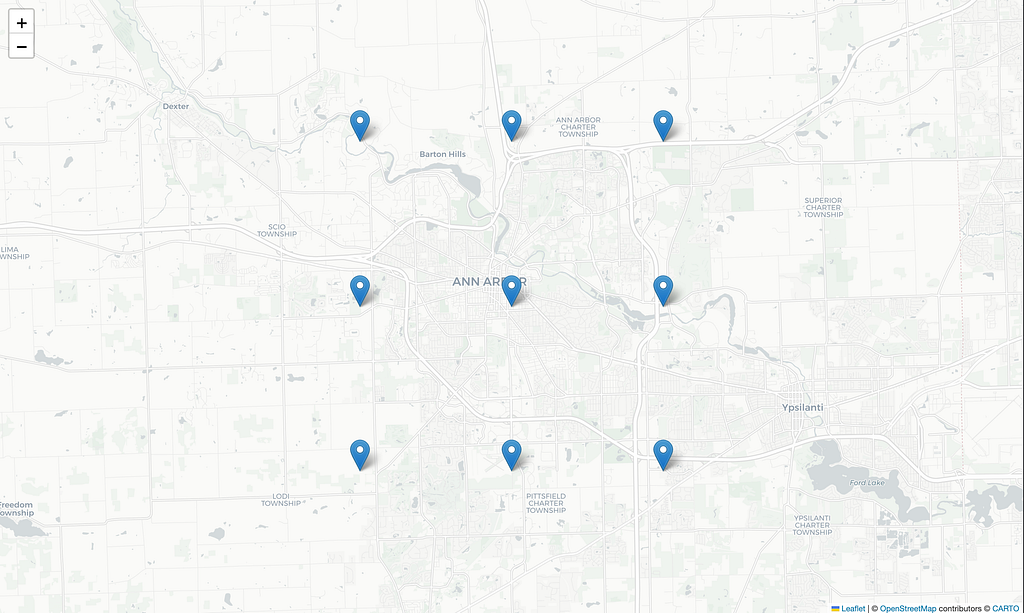
Due to the limited data we can source from the meteorological provider, we will collect the historic temperatures from nine locations in the geo-fenced area where telematics were sampled. We collect a year-long time series of temperatures sampled hourly for each of the nine locations and use them as the interpolation ground truth.
The interpolation occurs in three dimensions: two in the map plane and the third in time. The time interpolation is the simplest as we assume a linear temperature progression between each hourly sample. A sinusoid might be a better model, but it is probably too costly to improve marginal accuracy. We use the Inverse Distance Weighting (IDW) [3,4] algorithm for geospatial interpolation, which estimates the target temperature using the inverted distance between each temperature source and the target point. The IDW formula is depicted below in Figure 1.

As depicted below in Figure 2, this solution uses nine temperature sources. We collect a year-long hourly-sampled time series of temperatures reported by the data provider for each location. The time-interpolated values of these nine sources will feed the geospatial interpolator for the final value of the estimated temperature at the target location.
To test the interpolation’s accuracy, we also collected a sample of the source data to create a validation data set by directly calling the meteorological provider at these sampled locations. We selected these samples from records with valid Outside Air Temperature (OAT) signals to test the quality of the vehicle’s reported temperature.
Setting Up
Start by cloning the article’s GitHub repository to your local machine. To install all the prerequisites (Python environment and required packages), run the installer with the following command from the project root:
make install
If you have access to a UNIX-based shell, you can just run the following command line (please make sure that you have write access to the parent directory as this script will try to create a sibling folder) to download the original CSV data files:
make download-data
If you are running on a Windows machine, please read the instructions in the README file. These require manually downloading the data from the source repository and expanding the compressed file into the appropriate data folder. After expansion, a data file also requires special handling due to a CSV encoding error.
Running The Code
The code consists of three Python scripts and shared common code. The running instructions are in the README file.
By running the code, you will be taken from the initial source dataset to an updated version where all twenty-two million plus rows are annotated with an outside temperature value that closely matches the ground truth values.
python collect-samples.py
We start with a script that establishes where to collect the ground-truth temperature data for the year and stores it in a file cache for later reuse (see Figure 2 above). It then samples the original dataset, one CSV file at a time, to collect a validation set to help tune the IDW algorithm’s power parameter. The script collects the ground-truth temperature for each sampled row, assuming that the Open-Meteo provider reports accurate data for the given location and date. The script ends by saving the sampled rows with the ground-truth temperature data to a CSV file for reuse in the second step.
python tune-idw-power.py
Next, we run the script that tunes the IDW algorithm’s power parameter by computing the interpolation over the sampled dataset, varying the parameter’s value from one to ten. By plotting the power value versus the computed RMSE, we find a minimum of five (see Figure 3 below), which we will use in the final script.

The RMSE value above is computed using the sampled temperatures as the ground truth and the interpolated ones. This script computes these RMSE values and also computes the Outside Air Temperature (OAT) signal RMSE when compared against the ground-truth temperatures. Using the same dataset that generated the chart above, we get a value of 7.11, a full order of magnitude above, confirming the inadequacy of the OAT signal as a ground truth measurement.
python update-temperatures.py
The final script iterates through the CSV input files, estimates the outside temperatures through interpolation, and saves the results to a new set of CSV files. The new files are the same as the input ones, with an added temperature column, and are ready for use.
Please note that this script takes a long time to run. If you decide to interrupt it, it will resume after the last generated file.
Date and Time Handling
The dataset has a very peculiar way of handling dates. According to the original paper’s GitHub repository documentation, each datapoint encodes date and time in two columns. The first column, DayNum, encodes the number of days since the beginning of data collection, where the value of one corresponds to the first day:
base_dt = datetime(year=2017, month=11, day=1,
tzinfo=timezone("America/Detroit"))
The second column, Timestamp(ms), encodes the millisecond offset into the beginning of the trip (please see the repository and paper for more information on this). To get the effective date from these two columns, one must add the base date to the two offsets, like so:
base_dt + timedelta(days=day_num-1) + timedelta(milliseconds=timestamp_ms)
You will see this date and time handling throughout the code whenever we need to convert from the original data format to the standard Python date and time format with explicit time zones.
When collecting temperature information from the meteorological data provider, we explicitly request that all dates and times be expressed in the local time zone.
Closing Remarks
Why did I choose Polars when implementing the code for this article? Pandas would have been an equally valid option, but I wanted my first go at this new technology. While I found it quite easy to learn, it felt like it was not a direct drop-in replacement for Pandas. Polars has some new and very interesting concepts, such as lazy processing, which helped a lot when parsing all the CSV files in parallel to extract the geospatial boundaries.
The lazy execution API of Polars feels like programming Spark, which was a nice throwback. I miss some of Pandas’s shortcuts, but the speed improvements and the apparent better API structure easily offset that.
Credits
I used Grammarly to review the writing and accepted several of its rewriting suggestions.
JetBrains’ AI assistant wrote some of the code, and I also used it to learn Polars. It has become a staple of my everyday work.
Licensing Information
The Extended Vehicle Energy Dataset is licensed under Apache 2.0, like its originator, the Vehicle Energy Dataset.
References
[1] Open-Meteo
[2] Zhang, S., Fatih, D., Abdulqadir, F., Schwarz, T., & Ma, X. (2022). Extended vehicle energy dataset (eVED): An enhanced large-scale dataset for deep learning on vehicle trip energy consumption. ArXiv. /abs/2203.08630
[3] Spatial Interpolation with Inverse Distance Weighting (IDW) Method Explained
[4] Inverse distance weighting. (2024, June 7). In Wikipedia. https://en.wikipedia.org/wiki/Inverse_distance_weighting
João Paulo Figueira is a Data Scientist at tb.lx by Daimler Truck in Lisbon, Portugal.
Temperature Reconstruction Through Geospatial Interpolation was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Temperature Reconstruction Through Geospatial Interpolation
Go Here to Read this Fast! Temperature Reconstruction Through Geospatial Interpolation