
A case study on iterative, confidence-based pseudo-labeling for classification
In machine learning, more data leads to better results. But labeling data can be expensive and time-consuming. What if we could use the huge amounts of unlabeled data that’s usually easy to get? This is where pseudo-labeling comes in handy.
TL;DR: I conducted a case study on the MNIST dataset and boosted my model’s accuracy from 90 % to 95 % by applying iterative, confidence-based pseudo-labeling. This article covers the details of what pseudo-labeling is, along with practical tips and insights from my experiments.
How Does it Work?
Pseudo-labeling is a type of semi-supervised learning. It bridges the gap between supervised learning (where all data is labeled) and unsupervised learning (where no data is labeled).
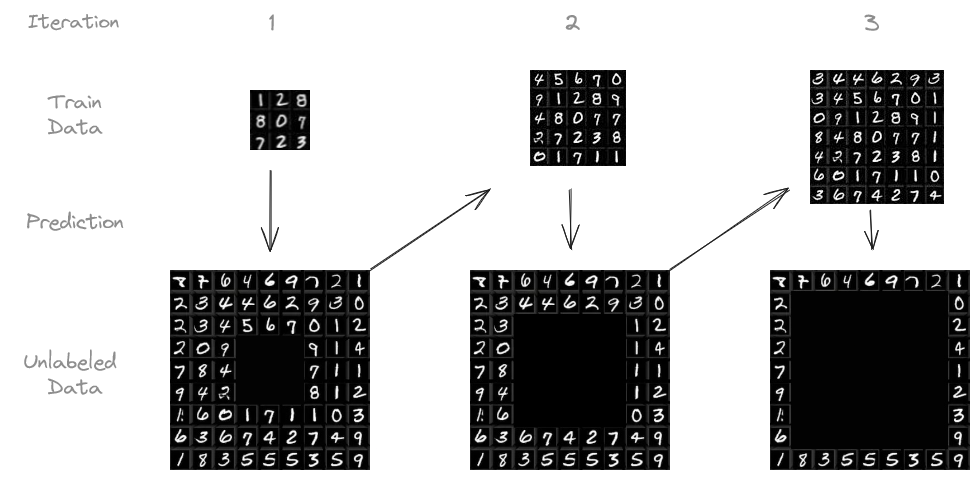
The exact procedure I followed goes as follows:
- We start with a small amount of labeled data and train our model on it.
- The model makes predictions on the unlabeled data.
- We pick the predictions the model is most confident about (e.g., above 95 % confidence) and treat them as if they were actual labels, hoping that they are reliable enough.
- We add this “pseudo-labeled” data to our training set and retrain the model.
- We can repeat this process several times, letting the model learn from the growing pool of pseudo-labeled data.
While this approach may introduce some incorrect labels, the benefit comes from the significantly increased amount of training data.
The Echo Chamber Effect: Can Pseudo-Labeling Even Work?
The idea of a model learning from its own predictions might raise some eyebrows. After all, aren’t we trying to create something from nothing, relying on an “echo chamber” where the model simply reinforces its own initial biases and errors?
This concern is valid. It may remind you of the legendary Baron Münchhausen, who famously claimed to have pulled himself and his horse out of a swamp by his own hair — a physical impossibility. Similarly, if a model solely relies on its own potentially flawed predictions, it risks getting stuck in a loop of self-reinforcement, much like people trapped in echo chambers who only hear their own beliefs reflected back at them.
So, can pseudo-labeling truly be effective without falling into this trap?
The answer is yes. While this story of Baron Münchhausen is obviously a fairytale, you may imagine a blacksmith progressing through the ages. He starts with basic stone tools (the initial labeled data). Using these, he forges crude copper tools (pseudo-labels) from raw ore (unlabeled data). These copper tools, while still rudimentary, allow him to work on previously unfeasible tasks, eventually leading to the creation of tools that are made of bronze, iron, and so on. This iterative process is crucial: You cannot forge steel swords using a stone hammer.
Just like the blacksmith, in machine learning, we can achieve a similar progression by:
- Rigorous thresholds: The model’s out-of-sample accuracy is bounded by the share of correct training labels. If 10 % of labels are wrong, the model’s accuracy won’t exceed 90 % significantly. Therefore it is important to allow as few wrong labels as possible.
- Measurable feedback: Constantly evaluating the model’s performance on a separate test set acts as a reality check, ensuring we’re making actual progress, not just reinforcing existing errors.
- Human-in-the-loop: Incorporating human feedback in the form of manual review of pseudo-labels or manual labeling of low-confidence data can provide valuable course correction.
Pseudo-labeling, when done right, can be a powerful tool to make the most of small labeled datasets, as we will see in the following case study.
Case Study: MNIST Dataset
I conducted my experiments on the MNIST dataset, a classic collection of 28 by 28 pixel images of handwritten digits, widely used for benchmarking machine learning models. It consists of 60,000 training images and 10,000 test images. The goal is to, based on the 28 by 28 pixels, predict what digit is written.
I trained a simple CNN on an initial set of 1,000 labeled images, leaving 59,000 unlabeled. I then used the trained model to predict the labels for the unlabeled images. Predictions with confidence above a certain threshold (e.g., 95 %) were added to the training set, along with their predicted labels. The model was then retrained on this expanded dataset. This process was repeated iteratively, up to ten times or until there was no more unlabeled data.
This experiment was repeated with different numbers of initially labeled images and confidence thresholds.
Results
The following table summarizes the results of my experiments, comparing the performance of pseudo-labeling to training on the full labeled dataset.
Even with a small initial labeled dataset, pseudo-labeling may produce remarkable results, increasing the accuracy by 4.87 %pt. for 1,000 initial labeled samples. When using only 100 initial samples, this effect is even stronger. However, it would’ve been wise to manually label more than 100 samples.
Interestingly, the final test accuracy of the experiment with 100 initial training samples exceeded the share of correct training labels.



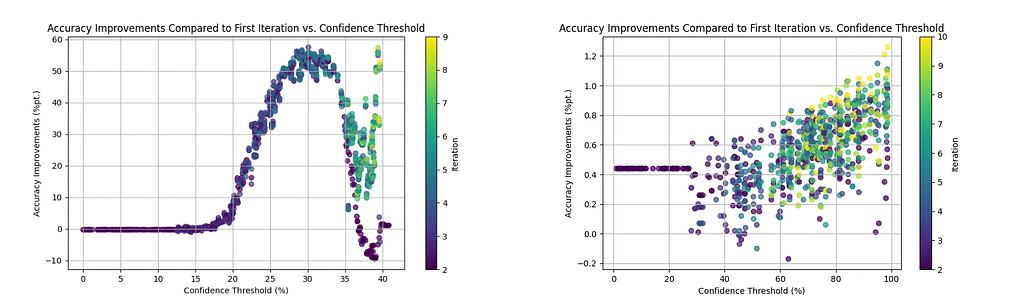
Looking at the above graphs, it becomes apparent that, in general, higher thresholds lead to better results — as long as at least some predictions exceed the threshold. In future experiments, one might try to vary the threshold with each iteration.
Furthermore, the accuracy improves even in the later iterations, indicating that the iterative nature provides a true benefit.
Key Findings and Lessons Learned
- Pseudo-labeling is best applied when unlabeled data is plentiful but labeling is expensive.
- Monitor the test accuracy: It’s important to keep an eye on the model’s performance on a separate test dataset throughout the iterations.
- Manual labeling can still be helpful: If you have the resources, focus on manually labeling the low confidence data. However, humans aren’t perfect either and labeling of high confidence data may be delegated to the model in good conscience.
- Keep track of what labels are AI-generated. If more manually labeled data becomes available later on, you’ll likely want to discard the pseudo-labels and repeat this procedure, increasing the pseudo-label accuracy.
- Be careful when interpreting the results: When I first did this experiment a few years ago, I focused on the accuracy on the remaining unlabeled training data. This accuracy falls with more iterations! However, this is likely because the remaining data is harder to predict — the model was never confident about it in previous iterations. I should have focused on the test accuracy, which actually improves with more iterations.
Links
The repository containing the experiment’s code can be found here.
Related paper: Iterative Pseudo-Labeling with Deep Feature Annotation and Confidence-Based Sampling
Teaching Your Model to Learn from Itself was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Teaching Your Model to Learn from Itself
Go Here to Read this Fast! Teaching Your Model to Learn from Itself