Taking model explainability beyond images and text
In the rapidly evolving landscape of artificial intelligence, recent advancements have propelled the field to astonishing heights, enabling models to mimic human-like capabilities in handling both images and text. From crafting images with an artist’s finesse to generating captivating captions, answering questions and composing entire essays, AI has become an indispensable tool in our digital arsenal.
However, despite these extraordinary feats, the full-scale adoption of this potent technology is not universal. The black-box nature of AI models raises significant concerns, particularly in industries where transparency is paramount. The lack of insight into “why did the model say that?” introduces risks, such as toxicity and unfair biases, particularly against marginalized groups. In high-stakes domains like healthcare and finance, where the consequences of erroneous decisions are costly, the need for explainability becomes crucial. This means that it’s not enough for the model to arrive at the correct decision, but it’s also equally important to explain the rationale behind those decisions.
The Tabular Data Challenge
While models that can ingest, understand and generate more images or text has been the new frenzy among many people, many high-stake domains make decisions from data compiled into tables like user profile information, posts the user has liked, purchase history, watch history etc.,
Tabular data is no new phenomena. It has been around as long as internet has been there like user’s browser history with visited pages, click interactions, products viewed online, products bought online etc., These informations are often used by advertisers to show you relevant ads.
Many critical use cases in the high-stake domains like finance, healthcare, legal etc., also heavily rely on data organized in tabular format. Here are some examples:
- Consider a hospital trying to figure out the likelihood of a patient recovering well after a certain treatment. They might use tables of patient data, including factors like age, previous health issues, and treatment details. If the models used are too complex or “black-box,” doctors may have a hard time trusting or understanding the predictions.
- Similarly, in the financial world, banks analyze various factors in tables to decide if someone is eligible for a loan and what interest rate to offer. If the models they use are too complex, it becomes challenging to explain to customers why a decision was made, potentially leading to a lack of trust in the system.
In the real world, many critical decision-making tasks like diagnosing illnesses from medical tests, approving loans based on financial statements, optimizing investments according to risk profiles on robo-advisors, identifying fake profiles on social media, and targeting the right audience for tailored advertisements all involve making decisions from tabular data. While deep neural networks, such as convolutional neural networks and transformer models like GPT, excel in grasping unstructured inputs like images, text, and voice, Tree Ensemble models like XGBoost still remain the unmatched champions for handling tabular data. This might be surprising in the era of deep neural networks, but it is true! Deep Models for tabular data like TabTansformer, TabNet etc., only perform as good as XGBoost models, though they use lot more parameters.
Explaining XGBoost models on Tabular Data
In this blog post, we take up explaining the binary classification decisions made by an XGBoost model. An intuitive approach to explain such models is by using human understandable rules. For instance, consider a model deciding whether a user account is that of a robot. If the model labels a user as “robot,” an interpretable explanation based on model features might be that the “number of connections with other robots ≥ 100 and number of API calls per day ≥ 10k”.
TE2Rules is an algorithm designed exactly for this purpose. TE2Rules stands for Tree Ensembles to Rules, and its primary function is to explain any binary classification-oriented tree ensemble model by generating rules derived from combinations of input features. This algorithm combines decision paths extracted from multiple trees within the XGBoost Model, using a subset of unlabeled data. The data used for extracting rules from the XGBoost model need not be same as the training data and does not require any ground truth labels. The algorithm uses this data to uncover implicit correlations present in the dataset. Notably, the rules extracted by TE2Rules exhibit a high precision against the model predictions (with a default of 95%). The algorithm systematically identifies all potential rules from the XGBoost model to explain the positive instances and subsequently condenses them into a concise set of rules that effectively cover the majority of positive cases in the data. This condensed set of rules serves as a comprehensive global explainer for the model. Additionally, TE2Rules retains the longer set of all conceivable rules, which can be employed to explain specific instances through the use of succinct rules.
Demo: Show and Tell
TE2Rules has demonstrated its effectiveness in various medical domains by providing insights into the decision-making process of models. Here are a few instances:
- Multiple Sclerosis: An Explainable AI model in the assessment of Multiple Sclerosis using clinical data and Brain MRI lesion texture features
- Depression: Using Machine Learning to identify profiles of individuals with depression
In this section, we show how we can use TE2Rules to explain a model trained to predict whether an individual’s income exceeds $50,000. The model is trained using Adult Income Dataset from UCI Repository. The Jupyter notebook used in this blog is available here: XGBoost-Model-Explanation-Demo. The dataset is covered by CC BY 4.0 license, permitting both academic and commercial use.
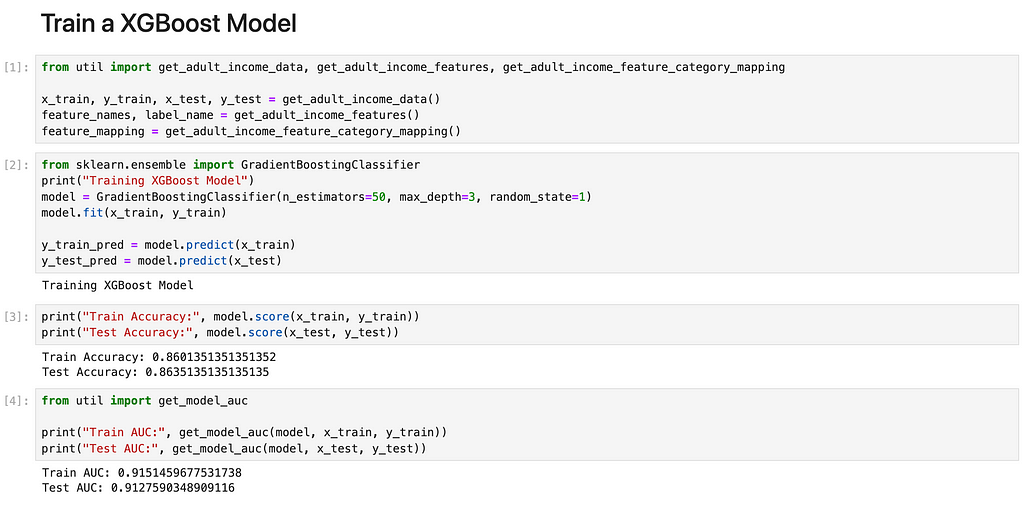
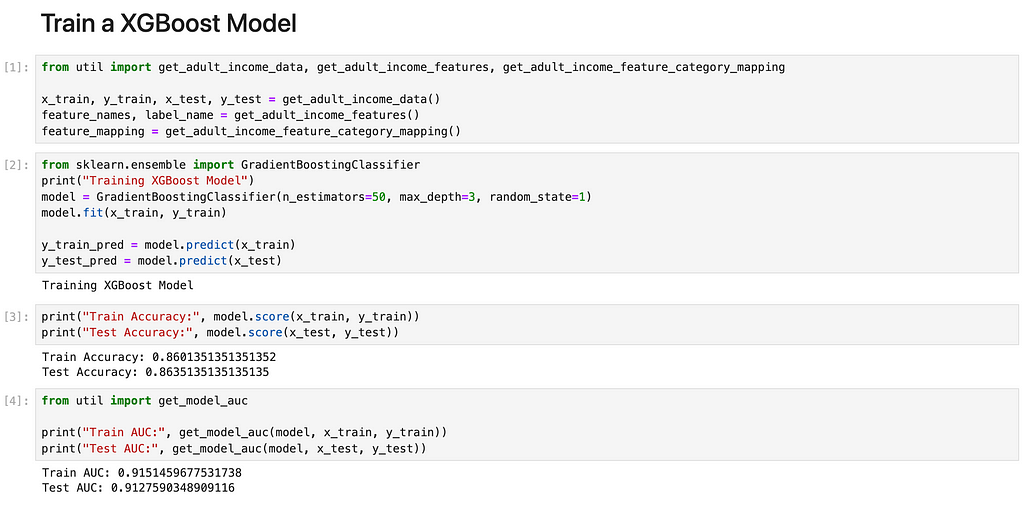
Step 1: Train the XGBoost model
We train a XGBoost model with 50 trees each of depth 3 on Adult Income dataset. We note that the XGBoost Model, once trained, exhibits an accuracy of approximately 86% and an AUC of 0.91 in both the training and testing datasets. This demonstrates the model’s effective training and its ability to generalize well across the test data.
Step 2: Explain the model using TE2Rules
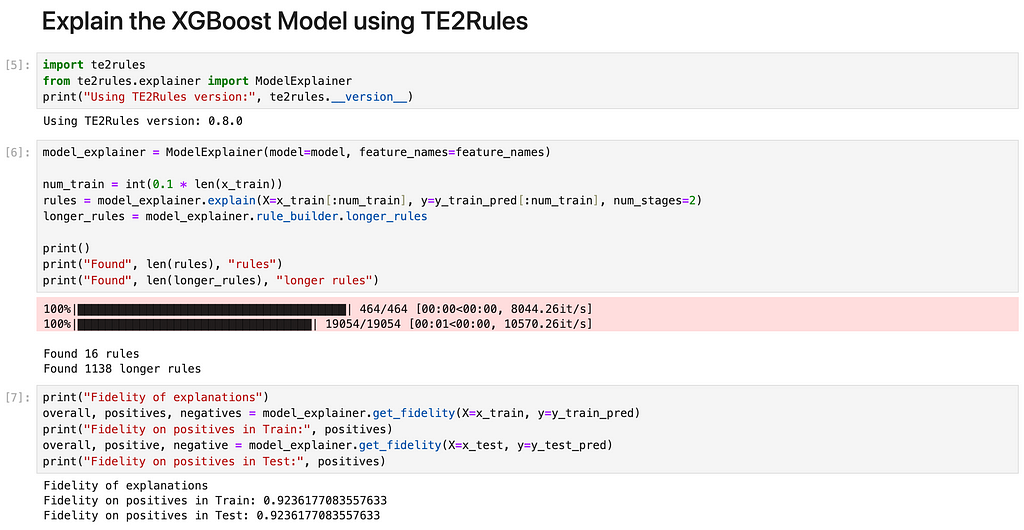
Using TE2Rules, we derive rules from the trained XGBoost model. To guide TE2Rules in generating explanation rules, we employ 10% of the training data. Notably, TE2Rules identifies a total of 1138 rules, where each rule, when met, ensures a positive prediction from the model. For enhanced usability, TE2Rules consolidates these rules into a concise set of 16 rules, effectively explaining the model with 50 trees, each having a depth of 3.
Here are the 16 rules that explain the model entirely:
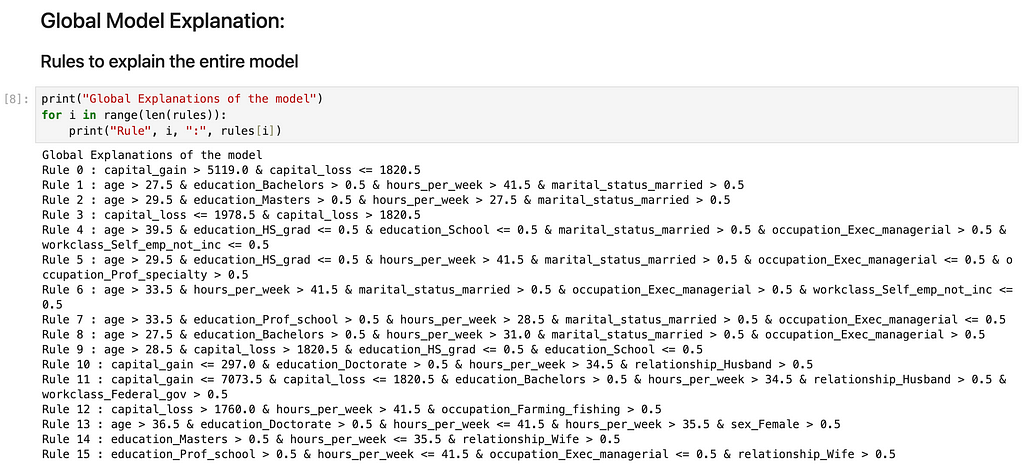
Each of these rule has a precision of more than 95%. The rules are arranged in decreasing order of support in the data.
Step 3: Explain specific input using TE2Rules
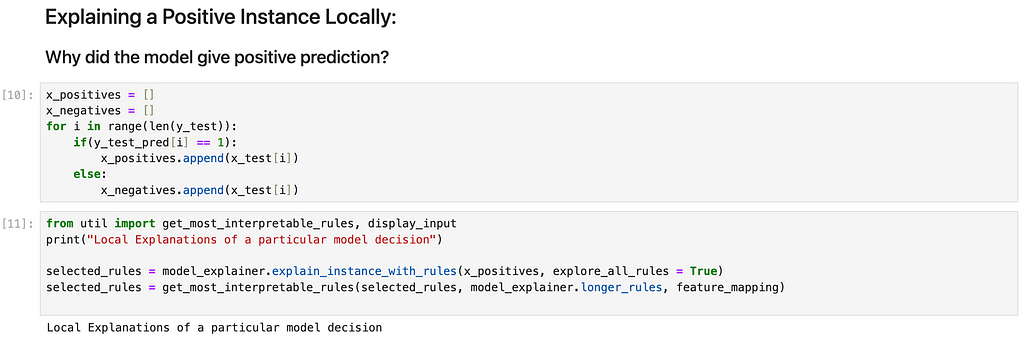
Using TE2Rules, we explain a specific positive instance by collecting all rules from the 1138 rules that are satisfied by the input and hence can explain the positive instance. Among these rules, we select the most interpretable rule using a custom logic to rank the possible explanations and choosing the most interpretable rule among the explanations.
Interpretability is highly subjective and can vary from one use case to another. In this example, we use the number of features used in a rule as a measure of interpretability of the rule. We choose the rule formed using the least number of features as the most interpretable explanation. Here is an example input with positive model prediction and an explanation behind the prediction generated by TE2Rules:
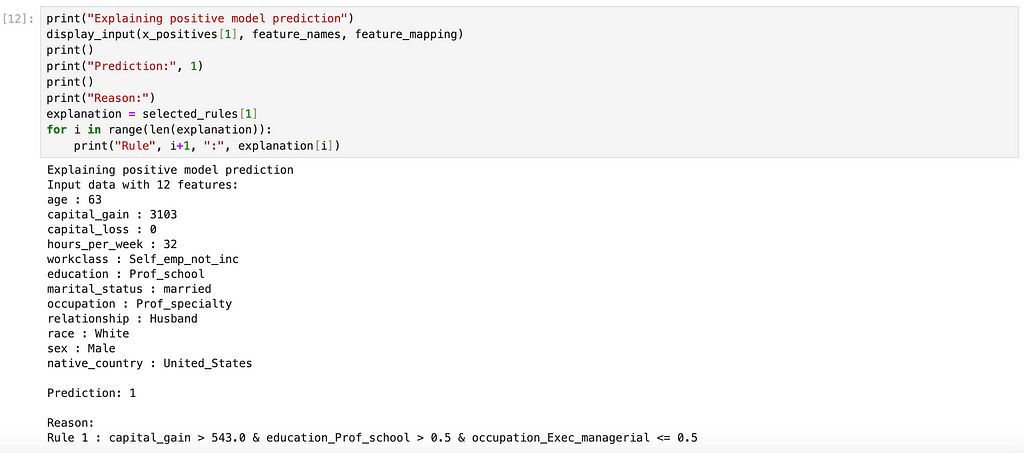
We note that in the above example, the model classified the input with 12 features to be a positive. TE2Rules explains this prediction with a rule with just 3 features: “capital_gain > 543 and education = Professional School and occupation != managerial”. Any other input that satisfies this rule (from the same data distribution) is guaranteed to be classified as positive by the model with probability > 95%.
Step 4: Counterfactual Explanations using TE2Rules
TE2Rules extracts rules that, when fulfilled, lead to a positive prediction by the model. These rules can be used for pinpointing the minimal alterations required in a negatively classified input to ensure that the model classifies it as positive. Consequently, TE2Rules proves valuable in generating counterfactual explanations, represented as rules specifying the conditions necessary for transforming a negative instance into a positive one.
Similar to the previous scenario, the acceptable minimal change varies depending on the context. In this example, certain features such as age, relationship status, and gender are deemed unalterable, while other features like education, occupation, and capital gain/loss are considered changeable. For any negative instance, we pinpoint a single feature among those deemed changeable, demonstrating the adjustment needed to prompt the model to score the instance positively.


We note that in the above example, the model classified the input to be a negative. TE2Rules identifies 5 different rules such that satisfying any one of these 5 rules is sufficient for the model to flip its prediction from negative to positive. Getting a different education like Professional School, Masters or Doctorate or getting more capital gains can help the individual make more money. However, it is surprising that the model has learnt that this individual would be rich even with high capital loss! This might be because such a change would result in a data sample that is very different from the data distribution of the training data, making the model not so reliable in such cases.
Conclusion
Explainability is vital for developing trust in AI models, particularly in high-stakes scenarios where model decisions can profoundly impact people’s lives, such as in healthcare, legal, and finance. Many of these critical use cases involve making decisions based on data organized in tabular formats. XGBoost tends to be the most poular choice of AI model on tabular data.
TE2Rules emerges as a versatile tool for explaining XGBoost models. TE2Rules has already gained traction in medical domains and is gradually gaining popularity in other fields as well. In this blog, we present a demonstration of how TE2Rules can effectively explain “Why did my model say that?”
As an open-source research project co-created by the author, the source code of TE2Rules can be found at [https://github.com/linkedin/TE2Rules]. Users are encouraged to integrate TE2Rules into their explainability projects. If you find TE2Rules useful for your projects, express your support by starring the repository. If any issues arise during the usage of TE2Rules, reach out to us at [https://github.com/linkedin/TE2Rules/issues] and we will do our best to address your issues.
TE2Rules: Explaining “Why did my model say that?” was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
TE2Rules: Explaining “Why did my model say that?”
Go Here to Read this Fast! TE2Rules: Explaining “Why did my model say that?”