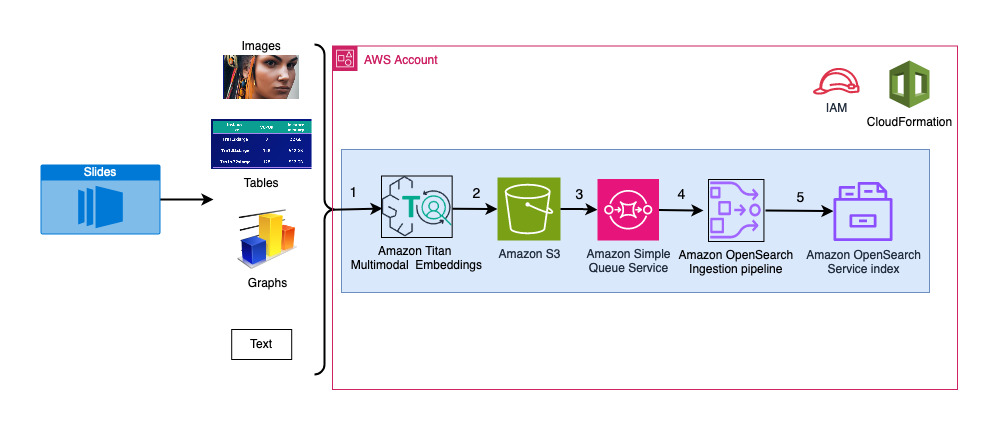

With the advent of generative AI, today’s foundation models (FMs), such as the large language models (LLMs) Claude 2 and Llama 2, can perform a range of generative tasks such as question answering, summarization, and content creation on text data. However, real-world data exists in multiple modalities, such as text, images, video, and audio. Take […]
Originally appeared here:
Talk to your slide deck using multimodal foundation models hosted on Amazon Bedrock and Amazon SageMaker – Part 1