Santa isn’t going to come give you a heaping of coal. If you need some fuel, here is how you get coal in Palworld.
Go Here to Read this Fast! How to get Coal in Palworld
Originally appeared here:
How to get Coal in Palworld
Go Here to Read this Fast! How to get Coal in Palworld
Originally appeared here:
How to get Coal in Palworld
Go Here to Read this Fast! How to get Rainbow Geodes in Like a Dragon: Infinite Wealth
Originally appeared here:
How to get Rainbow Geodes in Like a Dragon: Infinite Wealth
The original Erae Touch was one of the more interesting MPE controllers to come out in the last few years. But it’s been on the market for less than three years. So it was something of a surprise when Embodme showed up to NAMM 2024 with Erae II, the next iteration of its customizable controller with significant upgrades and one unexpected new feature.
Now, it’s important to note that the version of the Erae II I was able to test out was very early prototype. There were a few bugs, the construction definitely had some rough edges. But the company has plenty of time to iron those out. The Kickstarter campaign opens on February 15 with an expect ship date sometime in June.
But the vision is already clear. The main surface is largely the same, a singular smooth expanse with RGB lights underneath it. Those are used to illustrate various layouts that can be customized. It can be a standard keyboard, a grid, faders, a step sequencer, et cetera. The design is definitely more refined, even at this early stage. It also acknowledges that while the customizability of the controller was a big draw, it perhaps relied too much on the desktop app and the playing surface for handling settings.
The updated version has a number of buttons across the top for quickly swapping layouts, controlling the new MIDI looper and accessing other settings. There’s also a small, but high resolution screen tucked in the top righthand corner next to a jog wheel. The viewing angles on the screen were solid and it’s plenty sharp, but its size could pose some challenges. I’m not going to judge it by this very early version of the firmware, but I had to squint pretty hard to make out the tiny text laying out all the MIDI assignments.
The controller itself was very responsive, though. The new sensors (16,000 of them to be specific) were able to track my glides and subtle shifts in pressure with incredible accuracy. The company claims the playing surface has sub-millimeter accuracy. Obviously there’s no way I could truly put that to the test on the show floor but, suffice it to say, it was accurate.
I can already tell that the Erae requires quite a bit of nuance, though, to get truly expressive results from the aftertouch. The surface doesn’t have a lot of give, so tiny changes in pressure can result in big changes to the sound.
One of the surprising things is that the Erae II will have swappable skins, kind of like the Sensel Morph (RIP) or the Joué Play, but also, not. The unit I played had a silicone cover like the original that the company says is meant for those who want to play the Erae II with drum stick. It will will ship with a white fabric one though, which was specifically meant to improve the feel and responsiveness for those playing with their fingers.
Changing the skins is a little involved, however. Because Embodme sees the Erae not simply as a tool for the studio, but as a live performance device it wanted to make sure the covers would be secure and standup to abuse. So you actually have to unscrew the frame to pop on a new skin. And since the display on the Erae is already customizable, it’s not bothering to have skins with particular layouts, just different materials.
Embodme also added a ton of new connectivity options. The original simply had a USB-C port and a TRS MIDI out. But the Erae II will have two MIDI out ports, a MIDI in jack, two USB ports, with the ability to be either a host or a device, and 24 configurable analog outs that can send gate, trigger and CV to external gear.
Obviously it’s way to early to know for sure how well the Erae II will standup to real world use. But it’s got a promising feature set and an intriguing design. If you want to be among the first to get your hands on one you’ll be able to back it on Kickstarter starting February 15 with early bird prices of $549 or $649, depending on how early you hop on. When it reaches retail later in the year, however, it will be going for $799.
This article originally appeared on Engadget at https://www.engadget.com/embodme-erae-ii-hands-on-a-customizable-mpe-midi-controller-for-your-soft-synths-and-analog-gear-213059410.html?src=rss
Originally appeared here:
Embodme Erae II hands-on: A customizable MPE MIDI controller for your soft synths and analog gear


The AppleInsider staff combs the web for massive savings at e-commerce retailers to curate a list of top-notch deals on trending tech products, including deals on MacBook Air laptops, TVs, accessories, and other gadgets. We post the best deals daily to help you upgrade your tech stack while saving money.
Originally appeared here:
Daily deals Jan. 27: $200 off M2 MacBook Air 24GB RAM, Mac Studio for $1,199, $50 off Beats Studio Pro, more
Go Here to Read this Fast! How to get Squid Tentacles in Like a Dragon: Infinite Wealth
Originally appeared here:
How to get Squid Tentacles in Like a Dragon: Infinite Wealth
We were so close to finally drifting on the cobblestone streets of Yharnam, but it looks like we’ll have to wait a little longer for Bloodborne Kart. And, it’ll be called something else when it does arrive. Lilith Walther, the developer behind the project, said the team has to “scrub the branding” off of the game and delay its release after Sony intervened. It was supposed to be released on January 31 for PC. The outcome isn’t exactly surprising, but it means the game will take shape a bit differently than planned — in a thread posted on X, Walther said, “This is a fan game no more!”
Bloodborne Kart, a retro-style racing game that started out as a meme, has generated a ton of support from fans who have been yearning for new Bloodborne content. In response to the latest development, many have joked that the whole saga has forced Sony, which owns the IP, to actually acknowledge the title for the first time in years. Walther previously released a free Bloodborne “demake” in the style of a PS1 game.
“So Sony contacted us,” Walther wrote in an update on Friday. “Long story short, we need to scrub the branding off of what was previously known as Bloodborne Kart. We will do this, but that requires a short delay. Don’t worry, the game is still coming out! It’ll just look slightly different.”
The developers planned to feature 12 racers styled after familiar Bloodborne characters, including The Hunter and The Doll from the Hunter’s Dream, with single-player and multiplayer modes. There were to be 16 maps and boss fights, so you could race against the likes of Father Gascoigne. It really sucks that they won’t be able to follow through with the original idea, because it looked awesome, but I have no doubt they’ll spin it into something equally great.
“We were honestly expecting something like this to happen and the idea of having full creative control is kind of exciting!” Walther wrote. There’s no new release date just yet, but in the meantime, you can rewatch the Bloodborne Kart trailer on a loop and dream of what we almost had.
This article originally appeared on Engadget at https://www.engadget.com/fan-made-bloodborne-kart-catches-heat-from-sony-forcing-developers-to-shift-gears-183652390.html?src=rss
Originally appeared here:
Fan-made Bloodborne Kart catches heat from Sony, forcing developers to shift gears
NAMM is packed to the gills with synths, guitars, saxophones, et cetera. But, I promise you right now, the Dimension Tripper from Casio is the only wireless expression controller on the floor that you operate with your guitar strap.
The concept is simple. It’s an expression pedal. Just, not in pedal form. Now we’ve seen expression controllers in all sorts of shapes and sizes: Faders, rollers, even lasers. The Dimension Tripper does the same thing, except instead of rocking a pedal back and forth with your foot or sliding a fader back and forth with your hand, you pull down on your guitar itself.
There are two parts to the system. The transmitter goes between the end of your strap and the strap button on your guitar. One end of it is retractable and, as you stretch it out it sends information over Bluetooth to the receiver. Under ideal conditions there is about 20ms of lag, but even on the floor at NAMM with all of the interference it was barely noticeable.
The receiver is a relatively standard looking box that sits on your pedalboard and connects to your target pedal. A row of lights in the middle gives you visual feedback as you stretch out the sensor on the transmitter.
The two parts are a bit bulkier than I would have expected, though. The receiver has two foot switches and is basically the size of a standard guitar pedal. The transmitter is nearly 5 inches long and is 1 inch thick. You will notice it when you play, and will need to shorten your strap significantly.
Other than that, it works like any other expression controller. You can use it for energetic wah wah effects, or gentle volume swells or to crank up the weirdness on a ring modulator. It can even be used in place of a foot switch to turn on and off effect. So you could yank down hard at the start of the chorus to kick in an overdrive.
The concept is definitely gimmicky. But I have to admit it’s fun and actually felt kind of natural. Most players move their guitar a bit when anyway, and this just felt like an extension of that. I had to be a little more emphatic and move with more conviction than I might normally, but I adapted pretty quickly. Is it practical? Probably not. But kudos to Casio for trying something different.
What’s not clear is whether or not this will become an actual retail product. Right now Casio is running a crowdfunding campaign where you back the Dimension Tripper for 32,736 yen, or about $221. If the wireless expression controller has a life beyond that however is still up in the air.
This article originally appeared on Engadget at https://www.engadget.com/casios-dimension-tripper-lets-you-control-your-guitar-pedals-with-your-guitar-strap-200039380.html?src=rss
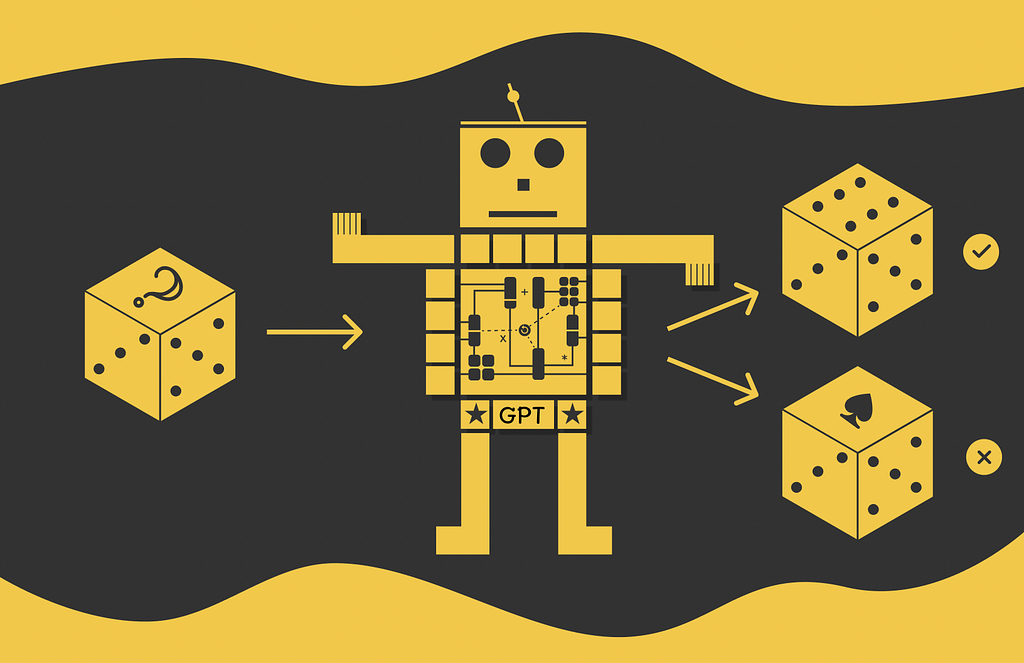

2017 was a historical year in machine learning. Researchers from the Google Brain team introduced Transformer which rapidly outperformed most of the existing approaches in deep learning. The famous attention mechanism became the key component in the future models derived from Transformer. The amazing fact about Transformer’s architecture is its vaste flexibility: it can be efficiently used for a variety of machine learning task types including NLP, image and video processing problems.
The original Transformer can be decomposed into two parts which are called encoder and decoder. As the name suggests, the goal of the encoder is to encode an input sequence in the form of a vector of numbers — a low-level format that is understood by machines. On the other hand, the decoder takes the encoded sequence and by applying a language modeling task, it generates a new sequence.
Encoders and decoders can be used individually for specific tasks. The two most famous models deriving their parts from the original Transformer are called BERT (Bidirectional Encoder Representations from Transformer) consisting of encoder blocks and GPT (Generative Pre-Trained Transformer) composed of decoder blocks.

In this article, we will talk about GPT and understand how it works. From the high-level perspective, it is necessary to understand that GPT architecture consists of a set of Transformer blocks as illustrated in the diagram above except for the fact that it does not have any input encoders.
Large Language Models: BERT — Bidirectional Encoder Representations from Transformer
As for most LLMs, GPT’s framework consists of two stages: pre-training and fine-tuning. Let us study how they are organised.
Loss function
As the paper states, “We use a standard language modeling objective to maximize the following likelihood”:

In this formula, at each step, the model outputs the probability distribution of all possible tokens being the next token i for the sequence consisting of the last k context tokens. Then, the logarithm of the probability for the real token is calculated and used as one of several values in the sum above for the loss function.
The parameter k is called the context window size.
The mentioned loss function is also known as log-likelihood.
Encoder models (e.g. BERT) predict tokens based on the context from both sides while decoder models (e.g. GPT) only use the previous context, otherwise they would not be able to learn to generate text.

The intuition behind the loss function
Since the expression for the log-likelihood might not be easy to comprehend, this section will explain in detail how it works.
As the name suggests, GPT is a generative model indicating that its ultimate goal is to generate a new sequence during inference. To achieve it, during training an input sequence is embedded and split by several substrings of equal size k. After that, for each substring, the model is asked to predict the next token by generating the output probability distribution (by using the final softmax layer) built for all vocabulary tokens. Each token in this distribution is mapped to the probability that exactly this token is the true next token in the subsequence.
To make the things more clear, let us look at the example below in which we are given the following string:

We split this string into substrings of length k = 3. For each of these substrings, the model outputs a probability distribution for the language modeling task. The predicted distrubitons are shown in the table below:

In each distribution, the probability corresponding to the true token in the sequence is taken (highlighted in yellow) and used for loss calculation. The final loss equals the sum of logarithms of true token probabilities.
GPT tries to maximise its loss, thus higher loss values correspond to better algorithm performance.
From the example distributions above, it is clear that high predicted probabilities corresponding to true tokens add up larger values to the loss function demonstrating better performance of the algorithm.
Subtlety behind the loss function
We have understood the intuition behind the GPT’s pre-training loss function. Nevertheless, the expression for the log-likelihood was originally derived from another formula and could be much easier to interpret!
Let us assume that the model performs the same language modeling task. However, this time, the loss function will maximize the product of all predicted probabilities. It is a reasonable choice as all of the output predicted probabilities for different subsequences are independent.


Since probability is defined in the range [0, 1], this loss function will also take values in that range. The highest value of 1 indicates that the model with 100% confidence predicted all the corrected tokens, thus it can fully restore the whole sequence. Therefore,
Product of probabilities as the loss function for a language modeling task, maximizes the probability of correctly restoring the whole sequence(-s).

If this loss function is so simple and seems to have such a nice interpretation, why it is not used in GPT and other LLMs? The problem comes up with computation limits:
As a consequence, a lot of tiny values are multiplied. Unfortunately, computer machines with their floating-point arithmetics are not good enough to precisely compute such expressions. That is why the loss function is slightly transformed by inserting a logarithm behind the whole product. The reasoning behind doing it is two useful logarithm properties:


We can notice that just by introducing the logarithmic transformation we have obtained the same formula used for the original loss function in GPT! Given that and the above observations, we can conclude an important fact:
The log-likelihood loss function in GPT maximizes the logarithm of the probability of correctly predicting all the tokens in the input sequence.
Text generation
Once GPT is pre-trained, it can already be used for text generation. GPT is an autoregressive model meaning that it uses previously predicted tokens as input for prediction of next tokens.
On each iteration, GPT takes an initial sequence and predicts the next most probable token for it. After that, the sequence and the predicted token are concatenated and passed as input to again predict the next token, etc. The process lasts until the [end] token is predicted or the maximum input size is reached.

After pre-training, GPT can capture linguistic knowledge of input sequences. However, to make it better perform on downstream tasks, it needs to be fine-tuned on a supervised problem.
For fine-tuning, GPT accepts a labelled dataset where each example contains an input sequence x with a corresponding label y which needs to be predicted. Every example is passed through the model which outputs their hidden representations h on the last layer. The resulting vectors are then passed to an added linear layer with learnable parameters W and then through the softmax layer.
The loss function used for fine-tuning is very similar to the one mentioned in the pre-training phase but this time, it evaluates the probability of observing the target value y instead of predicting the next token. Ultimately, the evaluation is done for several examples in the batch for which the log-likelihood is then calculated.

Additionally, the authors of the paper found it useful to include an auxiliary objective used for pre-training in the fine-tuning loss function as well. According to them, it:

Finally, the fine-tuning loss function takes the following form (α is a weight):

There exist a lot of approaches in NLP for fine-tuning a model. Some of them require changes in the model’s architecture. The obvious downside of this methodology is that it becomes much harder to use transfer learning. Furthermore, such a technique also requires a lot of customizations to be made for the model which is not practical at all.
On the other hand, GPT uses a traversal-style approach: for different downstream tasks, GPT does not require changes in its architecture but only in the input format. The original paper demonstrates visualised examples of input formats accepted by GPT on various downstream problems. Let us separately go through them.
This is the simplest downstream task. The input sequence is wrapped with [start] and [end] tokens (which are trainable) and then passed to GPT.

Textual entailment or natural language inference (NLI) is a problem of determining whether the first sentence (premise) is logically followed by the second (hypothesis) or not. For modeling that task, premise and hypothesis are concatenated and separated by a delimiter token ($).

The goal of similarity tasks is to understand how semantically close a pair of sentences are to each other. Normally, compared pairs sentences do not have any order. Taking that into account, the authors propose concatenating pairs of sentences in both possible orders and feeding the resulting sequences to GPT. The both hidden output Transformer layers are then added element-wise and passed to the final linear layer.

Multiple choice answering is a task of correctly choosing one or several answers to a given question based on the provided context information.
For GPT, each possible answer is concatenated with the context and the question. All the concatenated strings are then independently passed to Transformer whose outputs from the Linear layer are then aggregated and final predictions are chosen based on the resulting answer probability distribution.

GPT is pre-trained on the BookCorpus dataset containing 7k books. This dataset was chosen on purpose since it mostly consists of long stretches of text allowing the model to better capture language information on a long distance. Speaking of architecture and training details, the model has the following parameters:
Finally, GPT is pre-trained on 100 epochs tokens with a batch size of 64 on continuous sequences of 512 tokens.
Most of hyperparameters used for fine-tuning are the same as those used during pre-training. Nevertheless, for fine-tuning, the learning rate is decreased to 6.25e-5 with the batch size set to 32. In most cases, 3 fine-tuning epochs were enough for the model to produce strong performance.
Byte-pair encoding helps deal with unknown tokens: it iteratively constructs vocabulary on a subword level meaning that any unknown token can be then split into a combination of learned subword representations.
Combination of the power of Transformer blocks and elegant architecture design, GPT has become one of the most fundamental models in machine learning. It has established 9 out of 12 new state-of-the-art results on top benchmarks and has become a crucial foundation for its future gigantic successors: GPT-2, GPT-3, GPT-4, ChatGPT, etc.
All images are by the author unless noted otherwise
Large Language Models, GPT-1 — Generative Pre-Trained Transformer was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Large Language Models, GPT-1 — Generative Pre-Trained Transformer
Go Here to Read this Fast! Large Language Models, GPT-1 — Generative Pre-Trained Transformer
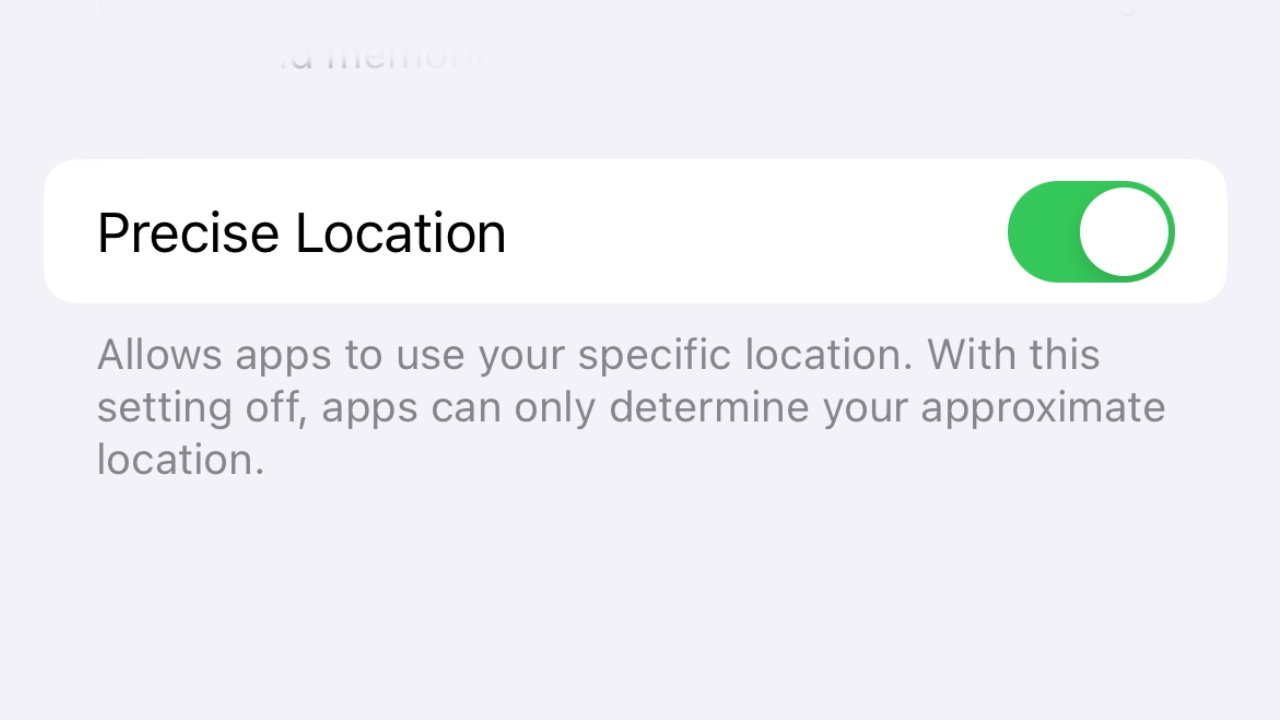
Your Precise Location on your iPhone or iPad does differ from general location tracking. General location tracking allows apps to know the general area you are in, such as being able to tell the city you’re in for accurate weather display. Precise Location, on the other hand, allows apps to narrow down your location to the exact address.
This allows for functions such as your phone switching Focus modes when it detects you’ve arrived at work or home. Still, there are many potential reasons you may want to hide your Precise Location on your iPhone, but whatever they may be, hiding it is no issue.
Go Here to Read this Fast! How to hide your Precise Location on iPhone and iPad
Originally appeared here:
How to hide your Precise Location on iPhone and iPad
Fossil is officially getting out of the smartwatch business. Following months of speculation about the future of its Wear OS smartwatch lineup, which hasn’t seen a new model since 2021’s Gen 6, the company confirmed to The Verge on Friday that it’s abandoning the category altogether. There won’t be a successor to the Gen 6, but existing Fossil smartwatches will still get updates “for the next few years.”
In a statement to The Verge, a spokesperson said Fossil Group has “made the strategic decision to exit the smartwatch business,” citing the industry’s evolving landscape. “Fossil Group is redirecting resources to support our core strength and the core segments of our business that continue to provide strong growth opportunities for us: designing and distributing exciting traditional watches, jewelry, and leather goods under our own as well as licensed brand names.”
Fossil has been pretty quiet about its smartwatch plans lately, after an initial few years of steady releases, and the decision is going to come as a disappointment to anyone who’s been holding out hope for a Gen 7. While they were known to struggle in the battery life department, Fossil smartwatches are some of the nicest looking out there.
This article originally appeared on Engadget at https://www.engadget.com/fossil-is-done-making-smartwatches-but-will-keep-releasing-updates-for-a-few-years-161958128.html?src=rss
Originally appeared here:
Fossil is done making smartwatches but will keep releasing updates for a few years