Education is tied with manufacturing as the #1 target for criminals, Cisco Talos report finds.
Originally appeared here:
Ransomware remains the most pressing security issue worldwide — but even schools are being targeted now
Originally appeared here:
Ransomware remains the most pressing security issue worldwide — but even schools are being targeted now
Originally appeared here:
World of Demons will soon be unavailable to play less than three years after its release

Graphs, in which objects and their relations are represented as nodes (or vertices) and edges (or links) between pairs of nodes, are ubiquitous in computing and machine learning (ML). For example, social networks, road networks, and molecular structure and interactions are all domains in which underlying datasets have a natural graph structure. ML can be used to learn the properties of nodes, edges, or entire graphs.
A common approach to learning on graphs are graph neural networks (GNNs), which operate on graph data by applying an optimizable transformation on node, edge, and global attributes. The most typical class of GNNs operates via a message-passing framework, whereby each layer aggregates the representation of a node with those of its immediate neighbors.
Recently, graph transformer models have emerged as a popular alternative to message-passing GNNs. These models build on the success of Transformer architectures in natural language processing (NLP), adapting them to graph-structured data. The attention mechanism in graph transformers can be modeled by an interaction graph, in which edges represent pairs of nodes that attend to each other. Unlike message passing architectures, graph transformers have an interaction graph that is separate from the input graph. The typical interaction graph is a complete graph, which signifies a full attention mechanism that models direct interactions between all pairs of nodes. However, this creates quadratic computational and memory bottlenecks that limit the applicability of graph transformers to datasets on small graphs with at most a few thousand nodes. Making graph transformers scalable has been considered one of the most important research directions in the field (see the first open problem here).
A natural remedy is to use a sparse interaction graph with fewer edges. Many sparse and efficient transformers have been proposed to eliminate the quadratic bottleneck for sequences, however, they do not generally extend to graphs in a principled manner.
In “Exphormer: Sparse Transformers for Graphs”, presented at ICML 2023, we address the scalability challenge by introducing a sparse attention framework for transformers that is designed specifically for graph data. The Exphormer framework makes use of expander graphs, a powerful tool from spectral graph theory, and is able to achieve strong empirical results on a wide variety of datasets. Our implementation of Exphormer is now available on GitHub.
A key idea at the heart of Exphormer is the use of expander graphs, which are sparse yet well-connected graphs that have some useful properties — 1) the matrix representation of the graphs have similar linear-algebraic properties as a complete graph, and 2) they exhibit rapid mixing of random walks, i.e., a small number of steps in a random walk from any starting node is enough to ensure convergence to a “stable” distribution on the nodes of the graph. Expanders have found applications to diverse areas, such as algorithms, pseudorandomness, complexity theory, and error-correcting codes.
A common class of expander graphs are d-regular expanders, in which there are d edges from every node (i.e., every node has degree d). The quality of an expander graph is measured by its spectral gap, an algebraic property of its adjacency matrix (a matrix representation of the graph in which rows and columns are indexed by nodes and entries indicate whether pairs of nodes are connected by an edge). Those that maximize the spectral gap are known as Ramanujan graphs — they achieve a gap of d – 2*√(d-1), which is essentially the best possible among d-regular graphs. A number of deterministic and randomized constructions of Ramanujan graphs have been proposed over the years for various values of d. We use a randomized expander construction of Friedman, which produces near-Ramanujan graphs.
 |
| Expander graphs are at the heart of Exphormer. A good expander is sparse yet exhibits rapid mixing of random walks, making its global connectivity suitable for an interaction graph in a graph transformer model. |
Exphormer replaces the dense, fully-connected interaction graph of a standard Transformer with edges of a sparse d-regular expander graph. Intuitively, the spectral approximation and mixing properties of an expander graph allow distant nodes to communicate with each other after one stacks multiple attention layers in a graph transformer architecture, even though the nodes may not attend to each other directly. Furthermore, by ensuring that d is constant (independent of the size of the number of nodes), we obtain a linear number of edges in the resulting interaction graph.
Exphormer combines expander edges with the input graph and virtual nodes. More specifically, the sparse attention mechanism of Exphormer builds an interaction graph consisting of three types of edges:
 |
| Exphormer builds an interaction graph by combining three types of edges. The resulting graph has good connectivity properties and retains the inductive bias of the input dataset graph while still remaining sparse. |
Each component serves a specific purpose: the edges from the input graph retain the inductive bias from the input graph structure (which typically gets lost in a fully-connected attention module). Meanwhile, expander edges allow good global connectivity and random walk mixing properties (which spectrally approximate the complete graph with far fewer edges). Finally, virtual nodes serve as global “memory sinks” that can directly communicate with every node. While this results in additional edges from each virtual node equal to the number of nodes in the input graph, the resulting graph is still sparse. The degree of the expander graph and the number of virtual nodes are hyperparameters to tune for improving the quality metrics.
Furthermore, since we use an expander graph of constant degree and a small constant number of virtual nodes for the global attention, the resulting sparse attention mechanism is linear in the size of the original input graph, i.e., it models a number of direct interactions on the order of the total number of nodes and edges.
We additionally show that Exphormer is as expressive as the dense transformer and obeys universal approximation properties. In particular, when the sparse attention graph of Exphormer is augmented with self loops (edges connecting a node to itself), it can universally approximate continuous functions [1, 2].
It is interesting to compare Exphormer to sparse attention methods for sequences. Perhaps the architecture most conceptually similar to our approach is BigBird, which builds an interaction graph by combining different components. BigBird also uses virtual nodes, but, unlike Exphormer, it uses window attention and random attention from an Erdős-Rényi random graph model for the remaining components.
Window attention in BigBird looks at the tokens surrounding a token in a sequence — the local neighborhood attention in Exphormer can be viewed as a generalization of window attention to graphs.
The Erdős-Rényi graph on n nodes, G(n, p), which connects every pair of nodes independently with probability p, also functions as an expander graph for suitably high p. However, a superlinear number of edges (Ω(n log n)) is needed to ensure that an Erdős-Rényi graph is connected, let alone a good expander. On the other hand, the expanders used in Exphormer have only a linear number of edges.
Earlier works have shown the use of full graph Transformer-based models on datasets with graphs of size up to 5,000 nodes. To evaluate the performance of Exphormer, we build upon the celebrated GraphGPS framework [3], which combines both message passing and graph transformers and achieves state-of-the-art performance on a number of datasets. We show that replacing dense attention with Exphormer for the graph attention component in the GraphGPS framework allows one to achieve models with comparable or better performance, often with fewer trainable parameters.
Furthermore, Exphormer notably allows graph transformer architectures to scale well beyond the usual graph size limits mentioned above. Exphormer can scale up to datasets of 10,000+ node graphs, such as the Coauthor dataset, and even beyond to larger graphs such as the well-known ogbn-arxiv dataset, a citation network, which consists of 170K nodes and 1.1 million edges.
 |
| Results comparing Exphormer to standard GraphGPS on the five Long Range Graph Benchmark datasets. We note that Exphormer achieved state-of-the-art results on four of the five datasets (PascalVOC-SP, COCO-SP, Peptides-Struct, PCQM-Contact) at the time of the paper’s publication. |
Finally, we observe that Exphormer, which creates an overlay graph of small diameter via expanders, exhibits the ability to effectively learn long-range dependencies. The Long Range Graph Benchmark is a suite of five graph learning datasets designed to measure the ability of models to capture long-range interactions. Results show that Exphormer-based models outperform standard GraphGPS models (which were previously state-of-the-art on four out of five datasets at the time of publication).
Graph transformers have emerged as an important architecture for ML that adapts the highly successful sequence-based transformers used in NLP to graph-structured data. Scalability has, however, proven to be a major challenge in enabling the use of graph transformers on datasets with large graphs. In this post, we have presented Exphormer, a sparse attention framework that uses expander graphs to improve scalability of graph transformers. Exphormer is shown to have important theoretical properties and exhibit strong empirical performance, particularly on datasets where it is crucial to learn long range dependencies. For more information, we point the reader to a short presentation video from ICML 2023.
We thank our research collaborators Hamed Shirzad and Danica J. Sutherland from The University of British Columbia as well as Ali Kemal Sinop from Google Research. Special thanks to Tom Small for creating the animation used in this post.
Originally appeared here:
Exphormer: Scaling transformers for graph-structured data
Go Here to Read this Fast! Exphormer: Scaling transformers for graph-structured data

In the fast-evolving landscape of artificial intelligence, large language models (LLMs) have revolutionized the way we interact with machines, pushing the boundaries of natural language understanding and generation to unprecedented heights. Yet, the leap into high-stakes decision-making applications remains a chasm too wide, primarily due to the inherent uncertainty of model predictions. Traditional LLMs generate responses recursively, yet they lack an intrinsic mechanism to assign a confidence score to these responses. Although one can derive a confidence score by summing up the probabilities of individual tokens in the sequence, traditional approaches typically fall short in reliably distinguishing between correct and incorrect answers. But what if LLMs could gauge their own confidence and only make predictions when they’re sure?
Selective prediction aims to do this by enabling LLMs to output an answer along with a selection score, which indicates the probability that the answer is correct. With selective prediction, one can better understand the reliability of LLMs deployed in a variety of applications. Prior research, such as semantic uncertainty and self-evaluation, has attempted to enable selective prediction in LLMs. A typical approach is to use heuristic prompts like “Is the proposed answer True or False?” to trigger self-evaluation in LLMs. However, this approach may not work well on challenging question answering (QA) tasks.
 |
| The OPT-2.7B model incorrectly answers a question from the TriviaQA dataset: “Which vitamin helps regulate blood clotting?” with “Vitamin C”. Without selective prediction, LLMs may output the wrong answer which, in this case, could lead users to take the wrong vitamin. With selective prediction, LLMs will output an answer along with a selection score. If the selection score is low (0.1), LLMs will further output “I don’t know!” to warn users not to trust it or verify it using other sources. |
In “Adaptation with Self-Evaluation to Improve Selective Prediction in LLMs“, presented at Findings of EMNLP 2023, we introduce ASPIRE — a novel framework meticulously designed to enhance the selective prediction capabilities of LLMs. ASPIRE fine-tunes LLMs on QA tasks via parameter-efficient fine-tuning, and trains them to evaluate whether their generated answers are correct. ASPIRE allows LLMs to output an answer along with a confidence score for that answer. Our experimental results demonstrate that ASPIRE significantly outperforms state-of-the-art selective prediction methods on a variety of QA datasets, such as the CoQA benchmark.
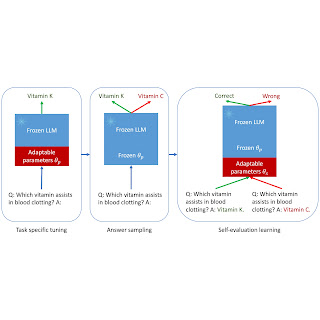
Imagine teaching an LLM to not only answer questions but also evaluate those answers — akin to a student verifying their answers in the back of the textbook. That’s the essence of ASPIRE, which involves three stages: (1) task-specific tuning, (2) answer sampling, and (3) self-evaluation learning.
Task-specific tuning: ASPIRE performs task-specific tuning to train adaptable parameters (θp) while freezing the LLM. Given a training dataset for a generative task, it fine-tunes the pre-trained LLM to improve its prediction performance. Towards this end, parameter-efficient tuning techniques (e.g., soft prompt tuning and LoRA) might be employed to adapt the pre-trained LLM on the task, given their effectiveness in obtaining strong generalization with small amounts of target task data. Specifically, the LLM parameters (θ) are frozen and adaptable parameters (θp) are added for fine-tuning. Only θp are updated to minimize the standard LLM training loss (e.g., cross-entropy). Such fine-tuning can improve selective prediction performance because it not only improves the prediction accuracy, but also enhances the likelihood of correct output sequences.
Answer sampling: After task-specific tuning, ASPIRE uses the LLM with the learned θp to generate different answers for each training question and create a dataset for self-evaluation learning. We aim to generate output sequences that have a high likelihood. We use beam search as the decoding algorithm to generate high-likelihood output sequences and the Rouge-L metric to determine if the generated output sequence is correct.
Self-evaluation learning: After sampling high-likelihood outputs for each query, ASPIRE adds adaptable parameters (θs) and only fine-tunes θs for learning self-evaluation. Since the output sequence generation only depends on θ and θp, freezing θ and the learned θp can avoid changing the prediction behaviors of the LLM when learning self-evaluation. We optimize θs such that the adapted LLM can distinguish between correct and incorrect answers on their own.
 |
| The three stages of the ASPIRE framework. |
In the proposed framework, θp and θs can be trained using any parameter-efficient tuning approach. In this work, we use soft prompt tuning, a simple yet effective mechanism for learning “soft prompts” to condition frozen language models to perform specific downstream tasks more effectively than traditional discrete text prompts. The driving force behind this approach lies in the recognition that if we can develop prompts that effectively stimulate self-evaluation, it should be possible to discover these prompts through soft prompt tuning in conjunction with targeted training objectives.
 |
| Implementation of the ASPIRE framework via soft prompt tuning. We first generate the answer to the question with the first soft prompt and then compute the learned self-evaluation score with the second soft prompt. |
After training θp and θs, we obtain the prediction for the query via beam search decoding. We then define a selection score that combines the likelihood of the generated answer with the learned self-evaluation score (i.e., the likelihood of the prediction being correct for the query) to make selective predictions.
To demonstrate ASPIRE’s efficacy, we evaluate it across three question-answering datasets — CoQA, TriviaQA, and SQuAD — using various open pre-trained transformer (OPT) models. By training θp with soft prompt tuning, we observed a substantial hike in the LLMs’ accuracy. For example, the OPT-2.7B model adapted with ASPIRE demonstrated improved performance over the larger, pre-trained OPT-30B model using the CoQA and SQuAD datasets. These results suggest that with suitable adaptations, smaller LLMs might have the capability to match or potentially surpass the accuracy of larger models in some scenarios.
 |
When delving into the computation of selection scores with fixed model predictions, ASPIRE received a higher AUROC score (the probability that a randomly chosen correct output sequence has a higher selection score than a randomly chosen incorrect output sequence) than baseline methods across all datasets. For example, on the CoQA benchmark, ASPIRE improves the AUROC from 51.3% to 80.3% compared to the baselines.
An intriguing pattern emerged from the TriviaQA dataset evaluations. While the pre-trained OPT-30B model demonstrated higher baseline accuracy, its performance in selective prediction did not improve significantly when traditional self-evaluation methods — Self-eval and P(True) — were applied. In contrast, the smaller OPT-2.7B model, when enhanced with ASPIRE, outperformed in this aspect. This discrepancy underscores a vital insight: larger LLMs utilizing conventional self-evaluation techniques may not be as effective in selective prediction as smaller, ASPIRE-enhanced models.
 |
Our experimental journey with ASPIRE underscores a pivotal shift in the landscape of LLMs: The capacity of a language model is not the be-all and end-all of its performance. Instead, the effectiveness of models can be drastically improved through strategic adaptations, allowing for more precise, confident predictions even in smaller models. As a result, ASPIRE stands as a testament to the potential of LLMs that can judiciously ascertain their own certainty and decisively outperform larger counterparts in selective prediction tasks.
In conclusion, ASPIRE is not just another framework; it’s a vision of a future where LLMs can be trusted partners in decision-making. By honing the selective prediction performance, we’re inching closer to realizing the full potential of AI in critical applications.
Our research has opened new doors, and we invite the community to build upon this foundation. We’re excited to see how ASPIRE will inspire the next generation of LLMs and beyond. To learn more about our findings, we encourage you to read our paper and join us in this thrilling journey towards creating a more reliable and self-aware AI.
We gratefully acknowledge the contributions of Sayna Ebrahimi, Sercan O Arik, Tomas Pfister, and Somesh Jha.
Originally appeared here:
Introducing ASPIRE for selective prediction in LLMs
Go Here to Read this Fast! Introducing ASPIRE for selective prediction in LLMs
Go Here to Read this Fast! Can I sideload apps on iPhone without jailbreaking?
Originally appeared here:
Can I sideload apps on iPhone without jailbreaking?
Sony’s WH-1000XM5 headphones are some of the most popular on the market, thanks to the improved sound quality, comfortable fit and highly effective active noise cancellation (ANC). If you’ve been looking at buying a pair, now is a good time to act. They’re currently on sale at Amazon in black, midnight blue and silver for $328, a solid 18 percent off the list price.
The WH-1000XM5 scored an excellent 95 in our Engadget review, thanks to improvements in nearly every way over our previous favorite headphones, the WH-1000XM4. Perhaps the biggest is in fit and comfort thanks to the more optimal weight distribution, synthetic leather ear cups and slightly reduced weight.
Sound quality also went up, due to the new 30mm carbon fiber drivers that deliver punchier bass. We also saw more clarity that helps you hear fine detail, along with improved depth that makes music more immersive. And Sony’s DSEE Extreme sound processing recovers detail lost to compression, without any noticeable impact on sound quality.
The ANC is equally impressive. With double the number of noise cancellation microphones found in the M4, along with a new dedicated V1 chip, the M5 does a better job at minimizing background noise. And in terms of the microphone, we found that the M5 offers superior call quality over its predecessor. Moreover, you get 30 hours of listening time with ANC enabled, enough for the longest of flights.
The main drawbacks of the WH-1000XM5 headphones compared to the previous model is that they no longer fold up, and don’t have the granular ANC adjustment found on other models like Bose’s QuietComfort Ultra. The other issue is the $400 price tag, but at $328, they’re a solid deal — and that price applies to all the main colorways.
Follow @EngadgetDeals on Twitter and subscribe to the Engadget Deals newsletter for the latest tech deals and buying advice.
This article originally appeared on Engadget at https://www.engadget.com/sonys-wh-1000xm5-anc-headphones-fall-back-to-328-091611120.html?src=rss
Go Here to Read this Fast! How to watch SpaceX launch Cygnus cargo ship to ISS for first time
Originally appeared here:
How to watch SpaceX launch Cygnus cargo ship to ISS for first time
Go Here to Read this Fast! Japan’s SLIM lunar lander is back in contact following blackout
Originally appeared here:
Japan’s SLIM lunar lander is back in contact following blackout
Go Here to Read this Fast! How to clear ‘Other’ storage/system data on an iPhone
Originally appeared here:
How to clear ‘Other’ storage/system data on an iPhone

