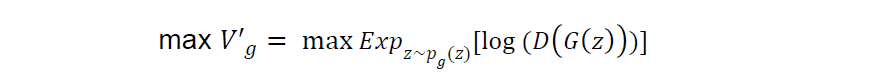Japan is an innovative country that leads the way on many technological fronts. But the wheels of bureaucracy often turn incredibly slowly there. So much so, that the government still requires businesses to provide information on floppy disks and CD-ROMs when they submit certain official documents.
That’s starting to change. Back in 2022, Minister of Digital Affairs Taro Kono urged various branches of the government to stop requiring businesses to submit information on outdated forms of physical media. The Ministry of Economy, Trade and Industry (METI) is one of the first to make the switch. “Under the current law, there are many provisions stipulating the use of specific recording media such as floppy disks regarding application and notification methods,” METI said last week, according to The Register.
After this calendar year, METI will no longer require businesses to submit data on floppy disks under 34 ordinances. The same goes for CD-ROMs when it comes to an unspecified number of procedures. There’s still quite some way to go before businesses can stop using either format entirely, however.
Kono’s staff identified some 1,900 protocols across several government departments that still require the likes of floppy disks, CD-ROMs and even MiniDiscs. The physical media requirements even applied to key industries such as utility suppliers, mining operations and aircraft and weapons manufacturers.
There are a couple of main reasons why there’s a push to stop using floppy disks, as SoraNews24 points out. One major factor is that floppy disks can be hard to come by. Sony, the last major manufacturer, stopped selling them in 2011. Another is that some data types just won’t fit on a floppy disk. A single photo can easily be larger than the format’s 1.4MB storage capacity.
There are some other industries that still rely on floppy disks. Some older planes need them for avionics, as do and some aging medical devices. It also took the US government until 2019 to stop using floppy disks to coordinate nuclear weapon launches.
This article originally appeared on Engadget at https://www.engadget.com/japan-will-no-longer-require-floppy-disks-for-submitting-some-official-documents-212048844.html?src=rss
Embracer Group, the Swedish holding company undergoing restructuring, has reportedly canceled a Deus Ex game. Bloombergsays developers had been working on the unannounced title for two years. Neither Embracer nor developer Eidos addressed the reported cancellation specifically, but they confirmed they were laying off 97 employees at Deus Ex developer Eidos Montreal.
Eidos will reportedly focus instead on “an original franchise.” Bloomberg’s sources say the Deus Ex game was scheduled to start production later this year. The franchise’s most recent mainline installment was 2016’s Deus Ex: Mankind Divided.
Embracer says the restructuring phase will run until the end of March. The company claims it will provide regular updates on the process, including when it publishes its next quarterly report on February 15.
Alongside the alleged Deus Ex cancellation, Eidos confirmed it let go of 97 employees from development teams, administration and support services. “The global economic context, the challenges of our industry and the comprehensive restructuring announced by Embracer have finally impacted our studio,” Eidos wrote in a statement.
This article originally appeared on Engadget at https://www.engadget.com/a-new-deus-ex-game-was-reportedly-canceled-amid-embracers-crisis-194919207.html?src=rss
Faries, a former National Football League executive, joined Activision as the head of Call of Duty esports in 2018. She started overseeing all things Call of Duty in 2021 and officially starts her new role on February 5.
Blizzard has largely operated independently since it merged with Activision in 2008. As such, Blizzard workers may be forgiven for being concerned at someone from the Activision side taking control. Former Activision Blizzard CEO Bobby Kotick often meddled in Blizzard’s affairs, reportedly resulting in Overwatch 2 delays, among other things.
In an attempt to soothe any worries, Faries wrote in an email to staff that “Activision, Blizzard, and King are decidedly different companies with distinct games, cultures and communities. It is important to note that Call of Duty’s way of waking up in the morning to deliver for players can often differ from the stunning games in Blizzard’s realm: each with different gameplay experiences, communities that surround them, and requisite models of success. I’ve discussed this with the Blizzard leadership team and I’m walking into this role with sensitivity to those dynamics, and deep respect for Blizzard, as we begin to explore taking our universes to even higher heights.”
Faries added that she is “committed to doing everything I can to help Blizzard thrive, with care and consideration for you and for our games, each unique and special in their own right.” Meanwhile, on X, Faries wrote that Blizzard’s Diablo 4 was part of her current rotation of games, alongside Call of Duty and Baldur’s Gate 3.
This article originally appeared on Engadget at https://www.engadget.com/former-call-of-duty-chief-johanna-faries-is-blizzards-new-president-193852238.html?src=rss
“Generative Adversarial Nets” (GANs) demonstrated outstanding performance in generating realistic synthetic data which are indistinguishable from the real data in the past. Unfortunately, GANs caught the public’s attention because of its unethical applications, deepfakes (Knight, 2018).
This article illustrates a case with a good motive in the application of GANs in the context of fraud detection.
Fraud detection is an application of binary classification prediction. Fraud cases, which account for only a small fraction of the transaction universe, constitute a minority class that makes the dataset highly imbalanced. In general, the resulting model tends to be biased towards the majority class and tends to underfit to the minority class. Thus, the less balanced the dataset, the poorer the performance of the classification predictor would be.
My motive here is to use GANs as a data augmentation tool in an attempt to address this classical problem of fraud detection associated with the imbalanced dataset. More specifically, GANs can generate realistic synthetic data of the minority fraud class and transform the imbalanced dataset perfectly balanced.
And, I am hoping that this sophisticated algorithm could materially contribute to the performance of fraud detection. In other words, my initial expectation is: the better sophisticated algorithm, the better performance.
A relevant question is if the use of GANs will guarantee a promising improvement in the performance of fraud detection and satisfy my motive. Let’s see.
Introduction
In principle, fraud detection is an application of binary classification algorithm: to classify each transaction whether it is a fraud case or not.
Fraud cases account for only a small fraction of the transaction universe. In general, fraud cases constitute the minority class, thus, make the dataset highly imbalanced.
The fewer fraud cases, the more sound the transaction system would be.
Very simple and intuitive.
Paradoxically, that sound condition was one of the primary reasons that made fraud detection challenging in the past, if not impossible. It is simply because it was difficult for a classification algorithm to learn the probability distribution of the minority class of fraud.
In general, the more balanced the dataset, the better the performance of the classification predictor. In other words, the less balanced (or the more imbalanced) the dataset, the poorer the performance of classifier.
This paints the classical problem of fraud detection: a binary classification application with highly imbalanced dataset.
In this setting, we can use Generative Adversarial Nets (GANs) as a data augmentation tool to generate realistic synthetic data of the minority fraud class to transform the entire dataset more balanced in an attempt to improve the performance of the classifier model of fraud detection.
This article is divided into the following sections:
Section 1: Algorithm Overview: Bi-level Optimization Architecture of GANs
Section 2: Fraud Dataset
Section 3: Python Code breakdown of GANs for data augmentation
Section 4: Fraud Detection Overview (Benchmark Scenario vs GANs Scenario)
Section 5: Conclusion
Overall, I will primarily focus on the topic of GANs (both the algorithm and the code). For the remaining topics of the model development other than GANs, such as data preprocessing and classifier algorithm, I will only outline the process and refrain from going into their details. In this context, this article assumes that the readers have a basic knowledge about the binary classifier algorithm (especially, Ensemble Classifier that I selected for fraud detection) as well as general understanding of data cleaning and preprocessing.
Section 1: Algorithm Overview: Bi-level Optimization Architecture of GANs
GANs is a special type of generative algorithm. As its name suggests, Generative Adversarial Nets (GANs) is composed of two neural networks: the generative network (the generator) and the adversarial network (the discriminator). GANs pits these two agents against each other to engage in a competition, where the generator attempts to generate realistic synthetic data and the discriminator to distinguish the synthetic data from the real data.
The original GANs was introduced in a seminal paper: “Generative Adversarial Nets” (Goodfellow, et al., Generative Adversarial Nets, 2014). The co-authors of the original GANs portrayed GANs with a counterfeiter-police analogy: an iterative game, where the generator acts as a counterfeiter and the discriminator plays the role of the police to detect the counterfeit that the generator forged.
The original GANs was innovative in a sense that it addressed and overcame conventional difficulties in training deep generative algorithm in the past. And as its core, it was designed with bi-level optimization framework with an equilibrium seeking objective setting (vs maximum likelihood oriented objective setting).
Ever since, many variant architectures of GANs have been explored. As a precaution, this article refers solely to the prototype architecture of the original GANs.
Generator and Discriminator
Repeatedly, in the architecture of GANs, the two neural networks — the generator and the discriminator — compete against each other. In this context, the competition takes place through the iteration of forward propagation and backward propagation (according to the general framework of neural networks).
On one hand, it is straight-forward that the discriminator is a binary classifier by design: it classifies whether each sample is real (label: 1) or fake/synthetic (label:0). And the discriminator is fed with both the real samples and the synthetic samples during the forward propagation. Then, during the backpropagation, it learns to detect the synthetic data from the mixed data feed.
On the other hand, the generator is a noise distribution by design. The generator is fed with the real samples during the forward propagation. Then, during the backward propagation, the generator learns the probability distribution of the real data in order to better simulate its synthetic samples.
And these two agents are trained alternately via “bi-level optimization” framework.
Bi-level Training Mechanism (bi-level optimization method)
In the original GAN paper, in order to train these two agents that pursue their diametrically opposite objectives, the co-authors designed a “bi-level optimization (training)” architecture, in which one internal training block (training of the discriminator) is nested within another high-level training block (training of the generator).
The image below illustrates the structure of “bi-level optimization” in the nested training loops. The discriminator is trained within the nested inner loop, while the generator is trained in the main loop at the higher level.
Image by Author
And GANs trains these two agents alternately in this bi-level training architecture (Goodfellow, et al., Generative Adversarial Nets, 2014, p. 3). In other words, while training one agent during the alternation, we need to freeze the learning process of the other agent (Goodfellow I. , 2015, p. 3).
Mini-Max Optimization Objective
In addition to the “bi-level optimization” mechanism which enables the alternate training of these two agents, another unique feature that differentiates GANs from the conventional prototype of neural network is its mini-max optimization objective. Simply put, in contrast to the conventional maximum seeking approach (such as maximum-likelihood) , GANs pursues an equilibrium-seeking optimization objective.
What is an equilibrium-seeking optimization objective?
Let’s break it down.
GANs’ two agents have two diametrically opposite objectives. While the discriminator, as a binary classifier, aims at maximizing the probability of correctly classifying the mixture of the real samples and the synthetic samples, the generator’s objective is to minimize the probability that the discriminator correctly classifies the synthetic data: simply because the generator needs to fool the discriminator.
In this context, the co-authors of the original GANs called the overall objective a “minimax game”. (Goodfellow, et al., 2014, p. 3)
Overall, the ultimate mini-max optimization objective of GANs is not to search for the global maximum/minimum of either of these objective functions. Instead, it is set to seek an equilibrium point which can be interpreted as:
“a saddle point that is a local maximum for the classifier and a local minimum for the generator” (Goodfellow I. , 2015, p. 2)
where neither of agents can improve their performance any longer.
where the synthetic data that the generator learned to create has become realistic enough to fool the discriminator.
And the equilibrium point could be conceptually represented by the probability of random guessing, 0.5 (50%), for the discriminator: D(z) => 0.5 .
Let’s transcribe the conceptual framework of GANs’ minimax optimization in terms of their objective functions.
The objective of the discriminator is to maximize the objective function in the following image:
Image by Author
In order to resolve a potential saturation issue, they converted the second term of the original log-likelihood objective function for the generator as follows and recommended to maximize the converted version as the generator’s objective:
Image by Author
Overall, the architecture of GANs’ “bi-level optimization” can be translated in to the following algorithm.
The dataset contains 284,807 transactions. In the dataset, we have only 492 fraud cases (including 29 duplicated cases).
Since the fraud class accounts for only 0.172% of all transactions, it constitutes an extremely small minority class. This dataset is an appropriate one for illustrating the classical problem of fraud detection associated with the imbalanced dataset.
It has the following 30 features:
V1, V2, … V28: 28 principal components obtained by PCA. The source of the data is not disclosed for the privacy protection purpose.
‘Time’: the seconds elapsed between each transaction and the first transaction of the dataset.
‘Amount’: the amount of the transaction.
The label is set as ‘Class’.
‘Class’: 1 in case of fraud; and 0 otherwise.
Data Preprocessing: Feature Selection
Since the dataset has already been pretty much, if not perfectly, cleaned, I only had to do few things for the data cleaning: elimination of duplicated data and removal of outliers.
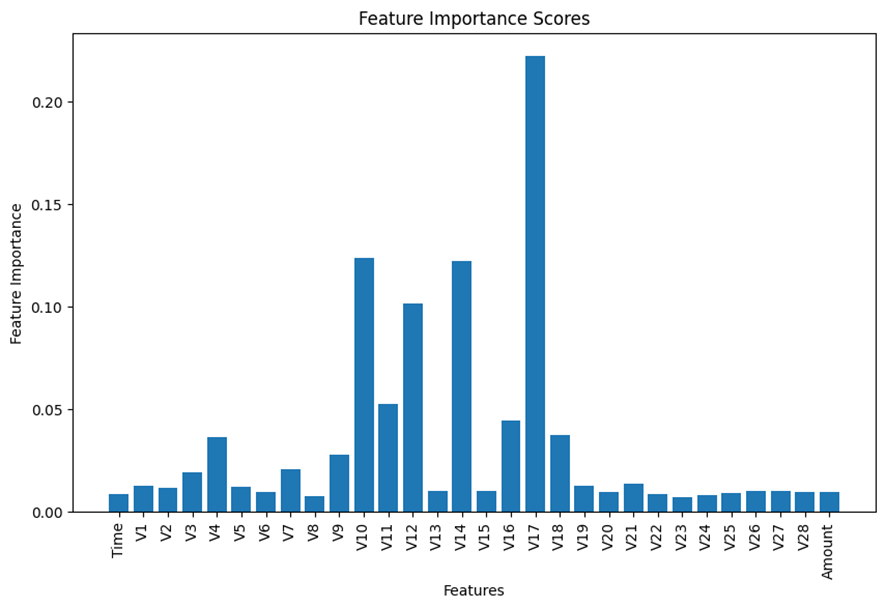
Thereafter, given 30 features in the dataset, I decided to run the feature selection to reduce the number of the features by eliminating less important features before the training process. I selected the built-in feature importance scoreof the scikit-learn Random Forest Classifier to estimate the scores of all the 30 features.
The following chart displays the summary of the result. If interested in the detailed process, please visit my code listed above.
Image by Author
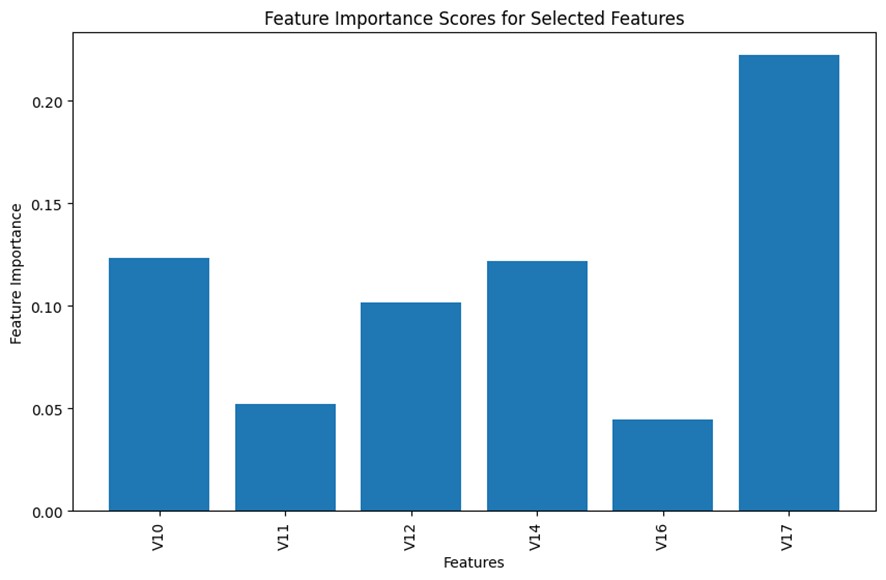
Based on the results displayed in the bar chart above, I made my subjective judgement to select the top 6 features for the analysis and remove all the remaining insignificant features from the model building process.
Here is the selected top 6 important features.
Image by Author
For the model building purpose going forward, I focused on these 6 selected features. After the data preprocessing, we have the working dataframe, df, of the following shape:
df.shape = (282513, 7)
Hopefully, the feature selection would reduce the complexity of the resulting model and stabilize its performance, while retaining critical information for optimizing a binary classifier.
Scenario 3: Code breakdown of GANs for data augmentation
Finally, it’s time for us to use GANs for data augmentation.
So how many synthetic data do we need to create?
First of all, our interest for the data augmentation is only for the model training. Since the test dataset is out-of-sample data, we want to preserve the original form of the test dataset. Secondly, because our intention is to transform the imbalanced dataset perfectly, we do not want to augment the majority class of non-fraud cases.
Simply put, we want to augment only the train dataset of the minority fraud class, nothing else.
Now, let’s split the working dataframe into the train dataset and the test dataset in 80/20 ratio, using a stratified data split method.
# Separate features and target variable X = df.drop('Class', axis=1) y = df['Class']
# Splitting data into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
# Combine the features and the label for the train dataset train_df = pd.concat([X_train, y_train], axis=1)
As a result, the shape of the train dataset is as follows:
train_df.shape = (226010, 7)
Let’s see the composition (the fraud cases and the non-fraud cases) of the train dataset.
# Load the dataset (fraud and non-fraud data) fraud_data = train_df[train_df['Class'] == 1].drop('Class', axis=1).values non_fraud_data = train_df[train_df['Class'] == 0].drop('Class', axis=1).values
# Calculate the number of synthetic fraud samples to generate num_real_fraud = len(fraud_data) num_synthetic_samples = len(non_fraud_data) - num_real_fraud print("# of non-fraud: ", len(non_fraud_data)) print("# of Real Fraud:", num_real_fraud) print("# of Synthetic Fraud required:", num_synthetic_samples)
# of non-fraud: 225632 # of Real Fraud: 378 # of Synthetic Fraud required: 225254
This tells us that the train dataset (226,010) is comprised of 225,632 non-fraud data and 378 fraud data. In other words, the difference between them is 225,254. This number is the number of the synthetic fraud data (num_synthetic_samples) that we need to augment in order to perfectly match the numbers of these two classes within the train dataset: as a reminder, we do preserve the original test dataset.
Next, let’s code GANs.
First, let’s create custom functions to determine the two agents: the discriminator and the generator.
For the generator, I create a noise distribution function, build_generator(), which requires two parameters: latent_dim (the dimension of the noise) as the shape of its input; and the shape of its output, output_dim, which corresponds to the number of the features.
# Define the generator network def build_generator(latent_dim, output_dim): model = Sequential() model.add(Dense(64, input_shape=(latent_dim,))) model.add(Dense(128, activation='sigmoid')) model.add(Dense(output_dim, activation='sigmoid')) return model
For the discriminator, I create a custom function build_discriminator() that takes input_dim, which corresponds to the number of the features.
# Define the discriminator network def build_discriminator(input_dim): model = Sequential() model.add(Input(input_dim)) model.add(Dense(128, activation='sigmoid')) model.add(Dense(1, activation='sigmoid')) return model
Then, we can call these function to create the generator and the discriminator. Here, for the generator I arbitrarily set latent_dim to be 32: you can try other value here, if you like.
# Dimensionality of the input noise for the generator latent_dim = 32
At this stage, we need to compile the discriminator, which is going to be nested in the main (higher) optimization loop later. And we can compile the discriminator with the following argument setting.
the loss function of the discriminator: the generic cross-entropy loss function for a binary classifier
the evaluation metrics: precision and recall.
# Compile the discriminator model from keras.metrics import Precision, Recall discriminator.compile(optimizer=Adam(learning_rate=0.0002, beta_1=0.5), loss='binary_crossentropy', metrics=[Precision(), Recall()])
For the generator, we will compile it when we construct the main (upper) optimization loop.
At this stage, we can define the custom objective function for the generator as follows. Remember, the recommended objective was to maximize the following formula:
Above, the negative sign is required, since the loss function by default is designed to be minimized.
Then, we can construct the main (upper) loop, build_GANs(generator, discriminator), of the bi-level optimization architecture. In this main loop, we compile the generator implicitly. In this context, we need to use the custom objective function of the generator, generator_loss_log_d, when we compile the main loop.
As aforementioned, we need to freeze the discriminator when we train the generator.
# Build and compile the GANs upper optimization loop combining generator and discriminator def build_gan(generator, discriminator): discriminator.trainable = False model = Sequential() model.add(generator) model.add(discriminator) model.compile(optimizer=Adam(learning_rate=0.0002, beta_1=0.5), loss=generator_loss_log_d)
return model
# Call the upper loop function gan = build_gan(generator, discriminator)
As a reminder, while we train the discriminator, we need to freeze the training of the generator; and while we train the generator, we need to freeze the training of the discriminator.
Here is the batch training code incorporating the alternating training process of these two agents under the bi-level optimization framework.
# Set hyperparameters epochs = 10000 batch_size = 32
# Training loop for the GANs for epoch in range(epochs): # Train discriminator (freeze generator) discriminator.trainable = True generator.trainable = False
# Random sampling from the real fraud data real_fraud_samples = fraud_data[np.random.randint(0, num_real_fraud, batch_size)]
# Generate fake fraud samples using the generator noise = np.random.normal(0, 1, size=(batch_size, latent_dim)) fake_fraud_samples = generator.predict(noise)
# Create labels for real and fake fraud samples real_labels = np.ones((batch_size, 1)) fake_labels = np.zeros((batch_size, 1))
# Train the discriminator on real and fake fraud samples d_loss_real = discriminator.train_on_batch(real_fraud_samples, real_labels) d_loss_fake = discriminator.train_on_batch(fake_fraud_samples, fake_labels) d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# Generate synthetic fraud samples and create labels for training the generator noise = np.random.normal(0, 1, size=(batch_size, latent_dim)) valid_labels = np.ones((batch_size, 1))
# Train the generator to generate samples that "fool" the discriminator g_loss = gan.train_on_batch(noise, valid_labels)
# Print the progress if epoch % 100 == 0: print(f"Epoch: {epoch} - D Loss: {d_loss} - G Loss: {g_loss}")
Here, I have a quick question for you.
Below we have an excerpt associated with the generator training from the code above.
Can you explain what this code is doing?
# Generate synthetic fraud samples and create labels for training the generator noise = np.random.normal(0, 1, size=(batch_size, latent_dim)) valid_labels = np.ones((batch_size, 1))
In the first line, noise generates the synthetic data. In the second line, valid_labels assigns the label of the synthetic data.
Why do we need to label it with 1, which is supposed to be the label for the real data? Didn’t you find the code counter-intuitive?
Ladies and gentlemen, welcome to the world of counterfeiters.
This is the labeling magic that trains the generator to create samples that can fool the discriminator.
Now, let’s use the trained generator to create the synthetic data for the minority fraud class.
# After training, use the generator to create synthetic fraud data noise = np.random.normal(0, 1, size=(num_synthetic_samples, latent_dim)) synthetic_fraud_data = generator.predict(noise)
# Convert the result to a Pandas DataFrame format fake_df = pd.DataFrame(synthetic_fraud_data, columns=features.to_list())
Finally, the synthetic data is created.
In the next section, we can combine this synthetic fraud data with the original train dataset to make the entire train dataset perfectly balanced. I hope that the perfectly balanced training dataset would improve the performance of the fraud detection classification model.
Section 4: Fraud Detection Overview (with and without GANs data augmentation)
Repeatedly, the use of GANs in this project is exclusively for data augmentation, but not for classification.
First of all, we would need the benchmark model as the basis of the comparison in order for us to evaluate the improvement made by the GANs based data augmentation on the performance of the fraud detection model.
As a binary classifier algorithm, I selected Ensemble Method for building the fraud detection model. As the benchmark scenario, I developed a fraud detection model only with the original imbalanced dataset: thus, without data augmentation. Then, for the second scenario with data augmentation by GANs, I can train the same algorithm with the perfectly balanced train dataset, which contains the synthetic fraud data created by GANs.
Benchmark Scenario: Ensemble Classifier without data augmentation
GANs Scenario: Ensemble Classifier with data augmentation by GANs
Benchmark Scenario: Ensemble without data augmentation
Next, let’s define the benchmark scenario (without data augmentation). I decided to select Ensemble Classifier: voting method as the meta learner with the following 3 base learners.
Gradient Boosting
Decision Tree
Random Forest
Since the original dataset is highly imbalanced, rather than accuracy I shall select evaluation metrics from the following 3 options: precision, recall, and F1-Score.
The following custom function, ensemble_training(X_train, y_train), defines the training and validation process.
# Define the base models base_models = { 'RandomForest': random_forest, 'DecisionTree': decision_tree, 'GradientBoosting': gradient_boosting }
# Initialize the meta learner meta_learner = VotingClassifier(estimators=[(name, model) for name, model in base_models.items()], voting='soft')
# Lists to store training and validation metrics train_f1_scores = [] val_f1_scores = []
# Splitting the train set further into training and validation sets X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=42, stratify=y_train)
# Training and validation for model_name, model in base_models.items(): model.fit(X_train, y_train)
# Validation metrics using the validation set val_predictions = model.predict(X_val) val_f1 = f1_score(y_val, val_predictions) val_f1_scores.append(val_f1)
# Training the meta learner on the entire training set meta_learner.fit(X_train, y_train)
The next function block, ensemble_evaluations(meta_learner, X_train, y_train, X_test, y_test), calculates the performance evaluation metrics at the meta learner level.
def ensemble_evaluations(meta_learner,X_train, y_train, X_test, y_test): # Metrics for the ensemble model on both traininGANsd test datasets ensemble_train_predictions = meta_learner.predict(X_train) ensemble_test_predictions = meta_learner.predict(X_test)
# Calculating metrics for the ensemble model ensemble_train_f1 = f1_score(y_train, ensemble_train_predictions) ensemble_test_f1 = f1_score(y_test, ensemble_test_predictions)
# Calculate precision and recall for both training and test datasets precision_train = precision_score(y_train, ensemble_train_predictions) recall_train = recall_score(y_train, ensemble_train_predictions)
# Output precision, recall, and f1 score for both training and test datasets print("Ensemble Model Metrics:") print(f"Training Precision: {precision_train:.4f}, Recall: {recall_train:.4f}, F1-score: {ensemble_train_f1:.4f}") print(f"Test Precision: {precision_test:.4f}, Recall: {recall_test:.4f}, F1-score: {ensemble_test_f1:.4f}")
Below, let’s look at the performance of the benchmark Ensemble Classifier.
Training Precision: 0.9811, Recall: 0.9603, F1-score: 0.9706 Test Precision: 0.9351, Recall: 0.7579, F1-score: 0.8372
At the meta-learner level, the benchmark model generated F1-Score at a reasonable level of 0.8372.
Next, let’s move on to the scenario with data augmentation using GANs . We want to see if the performance of the scenario with GAN can outperform the benchmark scenario.
GANs Scenario: Fraud Detection with data augmentation by GANs
Finally, we have constructed a perfectly balanced dataset by combining the original imbalanced train dataset (both non-fraud and fraud cases), train_df, and the synthetic fraud dataset generated by GANs, fake_df. Here, we will preserve the test dataset as original by not involving it in this process.
wdf = pd.concat([train_df, fake_df], axis=0)
We will train the same ensemble method with the mixed balanced dataset to see if it will outperform the benchmark model.
Now, we need to split the mixed balanced dataset into the features and the label.
Remember, when I ran the benchmark scenario earlier, I already defined the necessary custom function blocks to train and evaluate the ensemble classifier. I can use those custom functions here as well to train the same Ensemble algorithm with the combined balanced data.
We can pass the features and the label (X_mixed, y_mixed) into the custom Ensemble Classifier function ensemble_training().
Ensemble Model Metrics: Training Precision: 1.0000, Recall: 0.9999, F1-score: 0.9999 Test Precision: 0.9714, Recall: 0.7158, F1-score: 0.8242
Conclusion
Finally, we can assess whether the data augmentation by GANs improved the performance of the classifier, as I expected.
Let’s compare the evaluation metrics between the benchmark scenario and GANs scenario.
Here is the result from the benchmark scenario.
# The Benchmark Scenrio without data augmentation by GANs Training Precision: 0.9811, Recall: 0.9603, F1-score: 0.9706 Test Precision: 0.9351, Recall: 0.7579, F1-score: 0.8372
Here is the result from GANs scenario.
Training Precision: 1.0000, Recall: 0.9999, F1-score: 0.9999 Test Precision: 0.9714, Recall: 0.7158, F1-score: 0.8242
When we review the evaluation results on the training dataset, clearly GANs scenario outperformed the benchmark scenario over all the three evaluation metrics.
Nevertheless, when we focus on the results on the out-of-sample test data, GANs scenario outperformed the benchmark scenario only for precision (Benchmark: 0.935 vs GANs Scenario: 0.9714): it failed do so for recall and F1-Score (Benchmark: 0.7579; 0.8372 vs GANs Scenario: 0.7158; 0.8242).
A higher precision means that the model’s prediction of fraud cases did include less proportion of non-fraud cases than the benchmark scenario.
A lower recall means that the model failed to detect certain varieties of the actual fraud cases.
These two comparisons indicate: while the data augmentation by GANs was successful in simulating the realistic fraud data within the training dataset, it has failed to capture the diversity of the actual fraud cases included in the out-of-sample test dataset.
GANs was too good in simulating the particular probability distribution of the train data. Ironically, as a result, the use of GANs as the data augmentation tool, accounting for overfitting to the train data, resulted in a poor generalization of the resulting fraud detection (classification) model.
Paradoxically, this particular example made a counter-intuitive case that a better sophisticated algorithm might not necessarily guarantee a better performance when compared with simpler conventional algorithms.
In addition, we could also take into account of another unintended consequence, wasteful carbon footprint: adding energy demanding algorithms into your model development could increase the carbon footprint in the use of the machine learning in our daily life. This case could illustrate an example of an unnecessarily wasteful case which wasted energy unnecessarily without delivering a better performance.
Here I leave you some links regarding energy consumption of machine learning.
Today, we have many variants of GANs. In the future article, I would like to explore other variants of GANs to see if any variant can capture a wider diversity of the original samples so that it can improve the performance of a fraud detector.
Weather prediction is a very complex problem to solve. Numerical Weather Predictions (NWP) models, Weather Research and Forecasting (WRF) models, have been used to solve the problem, however, the accuracy and precision sometimes are found to be lacking.
Being the complex problem it is, it has attracted interest and the pursuit of solutions from data scientists to data science enthusiasts to meteorological engineers. Solutions have been found, however consistency and uniformity has not. The solution varies from area to area, from mountain to plateau, from swamps to tundra. From my own personal experience and I am sure from others’ experiences too, weather prediction has been found to be a tough cookie to crack. Quoting a certain shrimp billionaire:
It is like a box of chocolates, you never know what you’re gonna get.
Recently, Deepmind released a new tool: Graphcast, an AI model for faster and more accurate global weather forecasting, taking a shot at making this particular bag of chocolates tastier and more efficient. On a Google TPU v4 machine, using Graphcast, one can fetch predictions at a 0.25 degree spatial resolution in less than a minute. It solves a lot of issues one might face when predicting using conventional methods:
predictions are generated for all coordinates all at once,
editing the logic depending on the coordinate is now redundant,
mind boggling efficiency and response time.
What isn’t so mind boggling is the data preparation required to fetch predictions using the aforementioned tool.
However, worry not, I shall be your knight in a dark and gloomy armor and explain, in this article, the steps required to prepare and format data and finally, fetch predictions using Graphcast.
Note: The usage of the word “AI” nowadays reminds me very much of how “quantum” is used in Marvel movies.
Getting the predictions is a process which can be divided into the below sections:
Fetching the input data.
Creating the targets.
Creating the forcing data.
Processing and formatting the data into a suitable format.
Bringing them all together and making predictions.
Graphcast states that using the current weather data and the data from 6 hours ago, one can make predictions 6 hours into the future. Taking an example to put it simply:
if predictions are required for: 2024–01–01 18:00,
then input data to be put forth: 2024–01–01 12:00 & 2024–01–01 06:00.
It is important to note that 2024–01–01 18:00 will be the first prediction fetched. Graphcast can additionally fetch data for 10 days, with a 6 hour gap between each prediction. So, the other timestamps for which predictions can be fetched are:
2024–01–02 00:00, 06:00, 12:00, 18:00,
2024–01–03 00:00, 06:00 and similarly till,
2024–01–10 06:00, 12:00.
To summarize, data for 40 timestampscan be predictedusing the input of two timestamps.
Assumptions and important parameters
For the code I will present in this article, I have assigned the following values to certain parameters that dictate how fast you can get the predictions and the memory used.
Input timestamp: 2024–01–01 6:00, 12:00.
First prediction timestamp: 2024–01–01 18:00.
Number of predictions: 4.
Spatial resolution: 1 degree.
Pressure levels: 13.
Below is the code for importing the required packages, initializing arrays for fields required for input and prediction purposes and other variables that will come in handy.
import cdsapi import datetime import functools from graphcast import autoregressive, casting, checkpoint, data_utils as du, graphcast, normalization, rollout import haiku as hk import isodate import jax import math import numpy as np import pandas as pd from pysolar.radiation import get_radiation_direct from pysolar.solar import get_altitude import pytz import scipy from typing import Dict import xarray
client = cdsapi.Client() # Making a connection to CDS, to fetch data.
# The fields to be fetched from the single-level source. singlelevelfields = [ '10m_u_component_of_wind', '10m_v_component_of_wind', '2m_temperature', 'geopotential', 'land_sea_mask', 'mean_sea_level_pressure', 'toa_incident_solar_radiation', 'total_precipitation' ]
# The fields to be fetched from the pressure-level source. pressurelevelfields = [ 'u_component_of_wind', 'v_component_of_wind', 'geopotential', 'specific_humidity', 'temperature', 'vertical_velocity' ]
# Initializing other required constants. pi = math.pi gap = 6 # There is a gap of 6 hours between each graphcast prediction. predictions_steps = 4 # Predicting for 4 timestamps. watts_to_joules = 3600 first_prediction = datetime.datetime(2024, 1, 1, 18, 0) # Timestamp of the first prediction. lat_range = range(-180, 181, 1) # Latitude range. lon_range = range(0, 360, 1) # Longitude range.
# A utility function used for ease of coding. # Converting the variable to a datetime object. def toDatetime(dt) -> datetime.datetime: if isinstance(dt, datetime.date) and isinstance(dt, datetime.datetime): return dt
elif isinstance(dt, datetime.date) and not isinstance(dt, datetime.datetime): return datetime.datetime.combine(dt, datetime.datetime.min.time())
elif isinstance(dt, str): if 'T' in dt: return isodate.parse_datetime(dt) else: return datetime.datetime.combine(isodate.parse_date(dt), datetime.datetime.min.time())
Inputs
When it comes to machine learning, in order to get some predictions, you have to give the ML model some data using which it spits out a prediction. For example, when predicting whether a person is Batman, the input data might be:
How much sleep do they get?
Do they have a tan line on their face?
Do they sleep during early morning meetings?
How much is their net worth?
Similarly, Graphcast too takes certain inputs, which we obtain from CDS, using its python library: cdsapi. Currently, the data publisher uses the Creative Commons Attribution 4.0 License, which means that anyone can copy, distribute, transmit, and adapt the work as long as the original author is given credit.
However, authentication is required before making requests to fetch data using cdsapi, the instructions for which are provided by CDS and is pretty straightforward.
Assuming you are now CDS-approved, inputs can be created, which involves the following steps:
Getting the single-level values: These are dependent on the coordinates and time. One of the input fields required is total_precipitation_6hr.As the name suggests, it is the cumulation of the previous 6 hours of rainfall from that particular timestamp. Hence, instead of getting the values for just the two input timestamps, we have to get values for timestamps ranging from, in our case: 2024–01–01 00:00 to 12:00.
Getting the pressure-level values: In addition to being dependent on the coordinates, they also depend on the pressure-level. Hence, when requesting data, we mention the pressure levels we need the data for. In this case, we get values for the two input timestamps only.
Merging the single and pressure values: An inner-merge operation is carried out on the aforementioned data on the basis of time, latitude and longitude.
Integrating year and day progress: In addition to the single and pressure fields, four more fields need to be added to the input data: year_progress_sin, year_progress_cos, day_progress_sin and day_progress_cos. This can be done using functions provided by the graphcast package.
Other small steps include:
Renaming the columns after they are fetched from CDS because CDS outputs a shortened form of the weather variables.
Renaming geopotential variable to geopotential_at_surface for the single-level data, since pressure-level has the same field name.
Using mathfunctions to calculate the sin and cos values after the progress value is obtained from graphcast.
Renaming latitude to lat, longitude to lon and introducing another index: batch, which is assigned the value 0.
The code for creating the input data is as follows.
# Getting the single and pressure level values. def getSingleAndPressureValues():
# Calculating the sum of the last 6 hours of rainfall. singlelevel = singlelevel.sort_index() singlelevel['total_precipitation_6hr'] = singlelevel.groupby(level=[0, 1])['total_precipitation'].rolling(window = 6, min_periods = 1).sum().reset_index(level=[0, 1], drop=True) singlelevel.pop('total_precipitation')
# Adding sin and cos of the year progress. def addYearProgress(secs, data):
progress = du.get_year_progress(secs) data['year_progress_sin'] = math.sin(2 * pi * progress) data['year_progress_cos'] = math.cos(2 * pi * progress)
return data
# Adding sin and cos of the day progress. def addDayProgress(secs, lon:str, data:pd.DataFrame):
lons = data.index.get_level_values(lon).unique() progress:np.ndarray = du.get_day_progress(secs, np.array(lons)) prxlon = {lon:prog for lon, prog in list(zip(list(lons), progress.tolist()))} data['day_progress_sin'] = data.index.get_level_values(lon).map(lambda x: math.sin(2 * pi * prxlon[x])) data['day_progress_cos'] = data.index.get_level_values(lon).map(lambda x: math.cos(2 * pi * prxlon[x]))
return data
# Adding day and year progress. def integrateProgress(data:pd.DataFrame):
for dt in data.index.get_level_values('time').unique(): seconds_since_epoch = toDatetime(dt).timestamp() data = addYearProgress(seconds_since_epoch, data) data = addDayProgress(seconds_since_epoch, 'longitude' if 'longitude' in data.index.names else 'lon', data)
return data
# Adding batch field and renaming some others. def formatData(data:pd.DataFrame) -> pd.DataFrame:
data = data.rename_axis(index = {'latitude': 'lat', 'longitude': 'lon'}) if 'batch' not in data.index.names: data['batch'] = 0 data = data.set_index('batch', append = True)
return data
if __name__ == '__main__':
values:Dict[str, xarray.Dataset] = {}
single, pressure = getSingleAndPressureValues() values['inputs'] = pd.merge(pressure, single, left_index = True, right_index = True, how = 'inner') values['inputs'] = integrateProgress(values['inputs']) values['inputs'] = formatData(values['inputs'])
# Creating an array consisting of unique values of each index. lat, lon, levels, batch = sorted(data.index.get_level_values('lat').unique().tolist()), sorted(data.index.get_level_values('lon').unique().tolist()), sorted(data.index.get_level_values('level').unique().tolist()), data.index.get_level_values('batch').unique().tolist() time = [deltaTime(dt, hours = days * gap) for days in range(4)]
# Creating an empty dataset using latitude, longitude, the pressure levels and each prediction timestamp. target = xarray.Dataset({field: (['lat', 'lon', 'level', 'time'], nans(len(lat), len(lon), len(levels), len(time))) for field in predictionFields}, coords = {'lat': lat, 'lon': lon, 'level': levels, 'time': time, 'batch': batch})
As was the case with the targets, forcings too contains values for every coordinate and prediction timestamp but not the pressure level. The fields in forcings are:
total_incident_solar_radiation,
year_progress_sin,
year_progress_cos,
day_progress_sin,
day_progress_cos.
It is important to note that the above values are assigned wrt the prediction timestamp. As was the case when processing the inputs, yearandday progress depends only on the timestamp and the solar radiation was fetched from the single-level source. However, since one is making predictions, i.e., getting values for the future, the solar values, in the case of forcings, will not be available in the CDS dataset. For this we simulate the solar radiation values using the pysolar library.
# Includes the packages imported and constants assigned. # The functions created for the inputs and targets also go here.
# Adding a timezone to datetime.datetime variables. def addTimezone(dt, tz = pytz.UTC) -> datetime.datetime: dt = toDatetime(dt) if dt.tzinfo == None: return pytz.UTC.localize(dt).astimezone(tz) else: return dt.astimezone(tz)
# Getting the solar radiation value wrt longitude, latitude and timestamp. def getSolarRadiation(longitude, latitude, dt):
# Calculating the solar radiation values for timestamps to be predicted. def integrateSolarRadiation(data:pd.DataFrame):
dates = list(data.index.get_level_values('time').unique()) coords = [[lat, lon] for lat in lat_range for lon in lon_range] values = []
# For each data, getting the solar radiation value at a particular coordinate. for dt in dates: values.extend(list(map(lambda coord:{'time': dt, 'lon': coord[1], 'lat': coord[0], 'toa_incident_solar_radiation': getSolarRadiation(coord[1], coord[0], dt)}, coords)))
# The forcings dataset will now contain the solar radiation values. return pd.merge(data, values, left_index = True, right_index = True, how = 'inner')
def getForcings(data:pd.DataFrame):
# Since forcings data does not contain batch as an index, it is dropped. # So are all the columns, since forcings data only has 5, which will be created. forcingdf = data.reset_index(level = 'level', drop = True).drop(labels = predictionFields, axis = 1)
# Keeping only the unique indices. forcingdf = pd.DataFrame(index = forcingdf.index.drop_duplicates(keep = 'first'))
# Adding the sin and cos of day and year progress. # Functions are included in the creation of inputs data section. forcingdf = integrateProgress(forcingdf)
# Integrating the solar radiation values. forcingdf = integrateSolarRadiation(forcingdf)
return forcingdf
if __name__ == '__main__':
# The code for creating inputs and targets will be here.
Now that the three pillars of Graphcast is created, we enter the home stretch. Like in a NBA final, having won 3 games, we now proceed to the nittiest grittiest part, to get it done.
When it comes to an xarray, there are two main types of data:
Coordinates, the indices: lat, lon, time….. and
Data variables, the columns: land_sea_mask, geopotential et cetera.
Every value that a data variable contains, has certain coordinates assigned to it. The coordinates are those on which the value of the data variable depends on. Taking an example out of our own data,
land_sea_mask depends solely on the latitude and longitude, which are its coordinates.
geopotential’s coordinates are batch, latitude, longitude, time and pressure level.
In a stark contrast, but while making sense, the coordinates of geopotential_at_surface are latitude and longitude.
Hence, before we proceed to predicting the weather, we make sure each data variable is assigned to its right coordinates, the code for which is presented below.
# Includes the packages imported and constants assigned. # The functions created for the inputs, targets and forcings also go here.
# A dictionary created, containing each coordinate a data variable requires. class AssignCoordinates:
# Parsing through each data variable and removing unneeded indices. for var in list(data.data_vars): varArray:xarray.DataArray = data[var] nonIndices = list(set(list(varArray.coords)).difference(set(AssignCoordinates.coordinates[var]))) data[var] = varArray.isel(**{coord: 0 for coord in nonIndices}) data = data.drop_vars('batch')
The relative paths of the aforementioned files wrt the prediction file is depicted below. It is important to maintain the structure so that the required files can be imported and read successfully.
Above, I have provided the code for each process that will be undertaken:
creating the inputs, targets and forcings,
processing the above data to a viable format and then finally
bringing them together and making predictions.
While executing, it is important to bring all the processes together for a seamless implementation.
For simplicity, I have uploaded the code along with the docker image and container files, which can be used to create an environment to execute the prediction program.
In the universe of weather prediction, we currently have contributors like Accuweather, IBM, multiple meteomatics models. Graphcast proves to be an interesting and in many cases, a more efficient addition to this collection. However it also has some attributes that are far from optimal. In a rare moment of thought, I came up with the following insights:
Graphcast is far more efficient and faster compared to other weather prediction services, fetching predictions for the whole world in a matter of minutes.
This makes making hundreds of calls for hundreds of geographies using APIs redundant.
However to do the above in minutes, one needs to have a very powerful machine, either a Google TPU v4 or better. That is something that isn’t readily available. Even if one chooses to make use of a VM from AWS or Google or Azure, the costs can rack up.
Currently, there are no provisions to use data for a small geography or a subset of coordinates and get predictions for the same. Data for all the coordinates is always required.
CDS provides data with a 5 day latency period, which means at ‘x’ date, CDS can provide data only till ‘x-5’ date. This makes future weather prediction a little complicated since one has to cover the latency period before predictions can be made for the future.
It is important to note that Graphcast is a fairly new addition to the weather prediction scene, changes and additions will definitely be made to improve the ease of access and usability. Given the lead they have wrt efficiency and performance, they are sure to capitalize on it.
Did you know that for most common types of things, you don’t necessarily need data anymore to train object detection or even instance segmentation models?
Let’s get real on a given example. Let’s assume you have been given the task to build an instance segmentation model for the following classes:
Lion
Horse
Zebra
Tiger
Arguably, data would be easy to find for such classes: plenty of images of those animals are available on the internet. But if we need to build a commercially viable product for instance segmentation, we still need two things:
Make sure we have collected images with commercial use license
Label the data
Both of these tasks can be very time consuming and/or cost some significant amount of money.
Let’s explore another path: the use of free, available models. To do so, we’ll use a 2-step process to generate both the data and the associated labels:
First, we’ll generate images with Stable Diffusion, a very powerful, Generative AI model
Note that, at the date of publication of this article, images generated with Stable Diffusion are kind of in a grey area, and can be used for commercial use. But the regulation may change in the future.
I generated the data with Stable Diffusion. Before actually generating the data, let’s quickly give a few information about stable diffusion and how to use it.
It is very complete and frequently updated, allowing to use a lot of tools and plugins. It is very easy to install, on any distribution, by following the instructions in the readme. You can also find some very useful tutorials on how to use effectively Stable Diffusion:
For more advanced usage, I would suggest this tutorial
Without going into the details of how the stable diffusion model is trained and works (there are plenty of good resources for that), it’s good to know that actually there is more than one model.
There are several “official” versions of the model released by Stability AI, such as Stable Diffusion 1.5, 2.1 or XL. These official models can be easily downloaded on the HuggingFace of Stability AI.
But since Stable Diffusion is open source, anyone can train their own model. There is a huge number of available models on the website Civitai, sometimes trained for specific purposes, such as fantasy images, punk images or realistic images.
Generating the data
For our need, I will use two models including one specifically trained for realistic image generation, since I want to generate realistic images of animals.
The used models and hyperparameters are the following:
Prompt: “a realistic picture of a lion sitting on the grass”
To automate image generation with different settings, I used a specific feature script called X/Y/Z plot with prompt S/R for each axis.
The “prompt S/R” means search and replace, allowing to search for a string in the original prompt and replace it with other strings. Using X/Y/Z plot and prompt S/R on each axis, it allows to generate images for any combination of the possible given values (just like a hyperparameter grid search).
Here are the parameters I used on each axis:
lion, zebra, tiger, horse
sitting, sleeping, standing, running, walking
on the grass, in the wild, in the city, in the jungle, from the back, from side view
Using this, I can easily generate in one go images of the following prompt “a realistic picture of a <animal> <action> <location>” with all the values proposed in the parameters.
All in all, it would generate images for 4 animals, 5 actions and 6 locations: so 120 possibilities. Adding to that, I used a batch count of 2 and 2 different models, increasing the generated images to 480 to create my dataset (120 for each animal class). Below are some examples of the generated images.
Samples of the generated images using Stable Diffusion. Image by author.
As we can see, most of the pictures are realistic enough. We will now get the instance masks, so that we can then train a segmentation model.
Getting the labels
To get the labels, we will use SAM model to generate masks, and we will then manually filter out masks that are not good enough, as well as unrealistic images (often called hallucinations).
Generating the raw masks
To generate the raw masks, let’s use SAM model. The SAM model requires input prompts (not a textual prompt): either a bounding box or a few point locations. This allows the model to generate the mask from this input prompt.
In our case, we will do the most simple input prompt: the center point. Indeed, in most images generated by Stable Diffusion, the main object is centered, allowing us to efficiently use SAM with always the same input prompt and absolutely no labeling. To do so, we use the following function:
This function will first instantiate a SAM predictor, given a model type and a checkpoint (to download here). It will then loop over the images in the input folder and do the following:
Load the image
Compute the mask thanks to SAM, with both the options multimask_output set to True and False
Apply closing to the mask before writing it as an image
A few things to note:
We use both options multimask_output set to True and False because no option gives consistently superior results
We apply closing to the masks, because raw masks sometimes have a few holes
Here are a few examples of images with their masks:
A few images with the generated SAM masks displayed as a yellowish overlay. Image by author.
As we can see, once selected, the masks are quite accurate and it took virtually no time to label.
Selecting the masks
Not all the masks were correctly computed in the previous subsection. Indeed, sometimes the object was not centered, thus the mask prediction was off. Sometimes, for some reason, the mask is just wrong and would need more input prompts to make it work.
One quick workaround is to simply either select the best mask between the 2 computed ones, or simply remove the image from the dataset if no mask was good enough. Let’s do that with the following code:
This code loops over all the generated images with Stable Diffusion and does the following for each image:
Load the two generated SAM masks
Display the image twice, one with each masks as an overlay, side by side
Waits for a keyboard event to make the selection
The expected keyboard events are the following:
Left arrow of the keyboard to select the left mask
Right arrow to select the left mask
Down arrow to discard this image
Running this script may take some time, since you have to go through all the images. Assuming 1 second per image, it would take about 10 minutes for 600 images. This is still much faster than actually labeling images with masks, that usually takes at least 30 second per mask for high quality masks. Moreover, this allows to effectively filter out any unrealistic image.
Running this script on the generated 480 images took me less than 5 minutes. I selected the masks and filtered unrealistic images, so that I ended up with 412 masks. Next step is to train the model.
Training the model
Before training the YOLO segmentation model, we need to create the dataset properly. Let’s go through these steps.
Creating the dataset
This code loops through all the image and does the following:
Randomly select the train or validation set
Convert the masks to polygons for YOLO expected input label
Copy the image and the label in the right folders
One tricky part in this code is in the mask to polygon conversion, done by the mask2yolo function. This makes use of shapely and rasterio libraries to make this conversion efficiently. Of course, you can find the fully working in the repository.
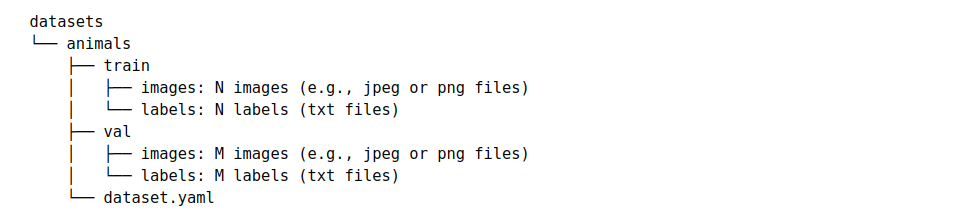
In the end, you would end up with the following structure in your datasets folder:
Folder structure after creating the dataset. Image by author.
This is the expected structure to train a model using the YOLOv8 library: it’s finally time to train the model!
Training the model
We can now train the model. Let’s use a YOLOv8 nano segmentation model. Training a model is just two lines of code with the Ultralytics library, as we can see in the following gist:
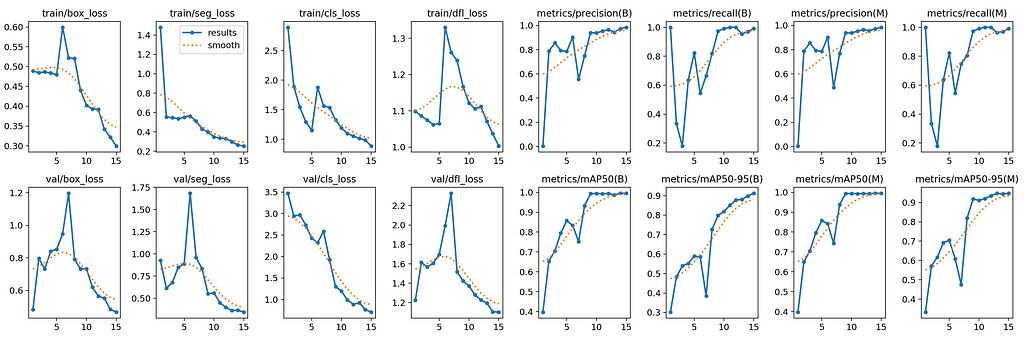
After 15 epochs of training on the previously prepared dataset, the results are the following:
Results generated by YOLOv8 library after 15 epochs.
As we can see, the metrics are quite high with a mAP50–95 close to 1, suggesting good performances. Of course, the dataset diversity being quite limited, those good performances are mostly likely caused by overfitting in some extent.
For a more realistic evaluation, next we’ll evaluate the model on a few real images.
Evaluating the model on real data
From Unsplash, I got a few images from each class and tested the model on this data. The results are right below:
Segmentation and class prediction results on real images from Unsplash.
On these 8 real images, the model performed quite well: the animal class is successfully predicted, and the mask seems quite accurate. Of course, to evaluate properly this model, we would need a proper labeled dataset images and segmentation masks of each class.
Conclusion
With absolutely no images and no labels, we could train a segmentation model for 4 classes: horse, lion, tiger and zebra. To do so, we leveraged three amazing tools:
Stable diffusion to generate realistic images
SAM to compute the accurate masks of the objects
YOLOv8 to efficiently train an instance segmentation model
While we couldn’t properly evaluate the trained model because we lack a labeled test dataset, it seems promising on a few images. Do not take this post as self-sufficient way to train any instance segmentation, but more as a method to speed up and boost the performances in your next projects. From my own experience, the use of synthetic data and tools like SAM can greatly improve your productivity in building production-grade computer vision models.
Of course, all the code to do this on your own is fully available in this repository, and will hopefully help you in your next computer vision project!
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.