If you’re over Kik — the free, anonymous messaging app — and intent on parting ways, wave goodbye to the app with our guide on how to delete your account.
The ability to capture screenshots may not be the iPad’s most glamorous feature, but it’s one of its most useful. Here’s how to take a screenshot on an iPad.
Amazon allows users to download select movies and shows, assuming you live in certain territories. Here’s how to get started, regardless of what device you use.
Universal Music Group (UMG) is threatening to pull all of its music from TikTok today following a breakdown in negotiations over royalties, the company wrote in an open letter. That would mean TikTok creators would lose access to songs from stars including Taylor Swift, Billy Eilish, The Weeknd, Drake and others.
With UMG’s deal with TikTok set to expire, the sides have reportedly been in negotiations for the past year. Such deals are worth billions annually to music publishing firms and are typically negotiated every few years. Universal is the world’s largest record label, and if does pull it’s music from TikTok, it would be the first time this has happened in recent memory.
Universal said TikTok wanted to pay a “fraction” of the rate paid by other social media sites. “As our negotiations continued, TikTok attempted to bully us into accepting a deal worth less than the previous deal, far less than fair market value and not reflective of their exponential growth.”
In its own post, TikTok said that it serves as a valuable marketing tool for artists and publishers. “Despite Universal’s false narrative and rhetoric, the fact is they have chosen to walk away from the powerful support of a platform with well over a billion users that serves as a free promotional and discovery vehicle for their talent.”
TikTok also benefits greatly from access to Universal’s catalog and being cut off from access to ultra-popular artists like Taylor Swift would be a blow to creators and users. TikTok’s Chinese parent ByteDance has more than 3 billion monthly active users and made $29 billion in revenue in a single quarter ending June 2023, according to The Financial Times. Warner Bros. Music, the number three record label behind Sony Music and UMG, recently struck a deal with TikTok.
Universal said it does “not underestimate what this will mean for artists and their fans” but that it will not shirk its responsibilities. “TikTok’s tactics are obvious: use its platform power to hurt vulnerable artists and try to intimidate us into conceding to a bad deal that undervalues music and shortchanges artists and songwriters as well as their fans.” The company added that payments from TikTok amount to “only about 1 percent of our total revenue.”
This article originally appeared on Engadget at https://www.engadget.com/universal-music-threatens-to-pull-songs-from-tiktok-over-payment-terms-101528365.html?src=rss
Lingua Franca — Entity-Aware Machine Translation Approach for Question Answering over Knowledge Graphs
Towards a lingua franca for knowledge graph question answering systems
TLDR
Machine Translation (MT) can enhance existing Question Answering (QA) systems, which have limited language capabilities, by enabling them to support multiple languages. However, there is one major drawback of MT — often, it fails at translating named entities that are not translatable word-by-word. For example, the German title of the movie “The Pope Must Die” is “Ein Papst zum Küssen”, which has the literal translation: “A Pope to Kiss”. As the correctness of the named entities is crucial for QA systems, such a challenge has to be handled properly. In this article, we present our entity-aware MT approach called “Lingua Franca”. It takes advantage of knowledge graphs in order to use information stored there to ensure the correctness of named entities’ translations. And yes, it works!
The Challenge
Achieving high-quality translations depends significantly on accurately translating named entities (NEs) within sentences. Various methods have been proposed to enhance the translation of NEs, including approaches that integrate knowledge graphs (KGs) to improve entity translation, recognizing the pivotal role of entities in overall translation quality within the context of QA. It is important to note that the quality of NE translation is not an isolated objective; it has broader implications for systems involved in tasks such as information retrieval (IR) or knowledge graph-based question answering (KGQA). In this article, we will delve into a detailed discussion of machine translation (MT) and KGQA.
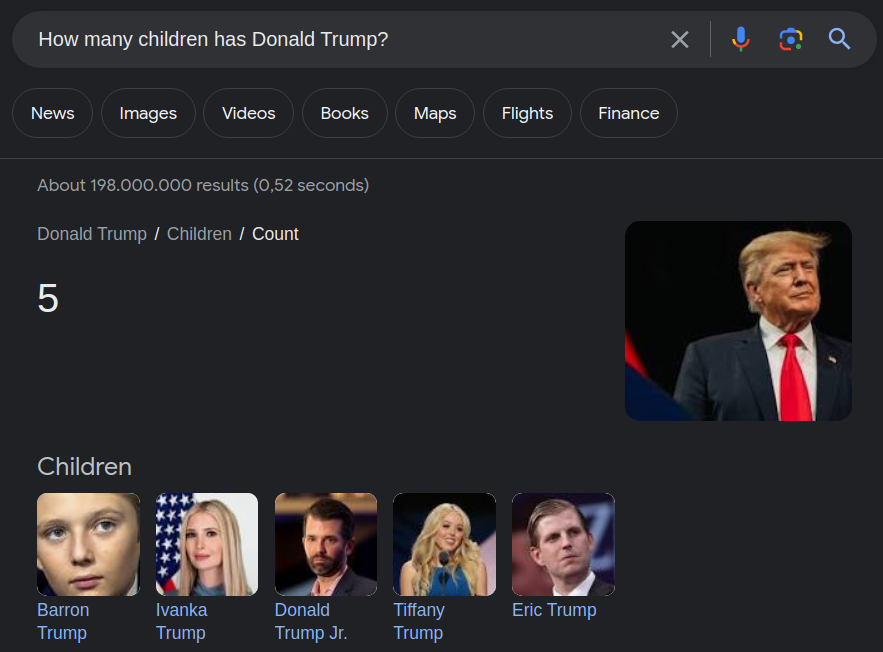
The significance of KGQA systems lies in their ability to provide factual answers to users based on structured data (see figure below).
Screenshot of Google’s direct answer functionality (by author)
KGQA systems are core components in modern search engines enabling them to give direct answers to their users (Google Search, screenshot by author).
Additionally, multilingual KGQA systems play a crucial role in addressing the “digital language divide” on the Web. For instance, Germany-related Wikipedia articles, especially those dedicated to cities or people, contain more information in the German language than in other languages — this information imbalance can be handled by the multilingual KGQA system that is, by the way, the core of all modern search engines.
One of the options for enabling the KGQA system to answer questions in different languages is to use MT. However, an off-the-shelf MT faces notable challenges when it comes to translating NEs, as numerous entities are not readily translatable and demand background knowledge for accurate interpretation. For instance, consider the German title of the movie “The Pope Must Die,” which is “Ein Papst zum Küssen.” The literal translation, “A Pope to Kiss,” underscores the need for contextual understanding beyond a straightforward translation approach.
Given the limitations of conventional MT methods in translating entities, the combination of KGQA systems with MT often results in distorted NEs, significantly reducing the likelihood of accurate question answering. Therefore, there is a need for an enhanced approach to incorporate background knowledge about NEs in multiple languages.
Our Approach
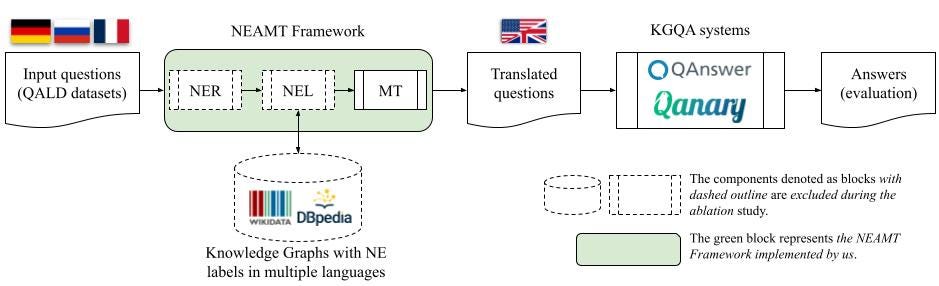
This article introduces and implements a novel approach for Named-Entity Aware Machine Translation (NEAMT) aimed at enhancing the multilingual capabilities of KGQA systems. The central concept of NEAMT involves augmenting the quality of MT by incorporating information from a knowledge graph (e.g. Wikidata and DBpedia). This is achieved through the utilization of the “entity-replacement” technique.
As the data for the evaluation, we use the QALD-9-plus and QALD-10 datasets. Then, we use multiple components within our NEAMT framework, which are available in our repository. Finally, the approach is evaluated on two KGQA systems: QAnswer and Qanary. The detailed description of the approach is available at the figure below.
General overview of the Lingua Franca approach in the KGQA process (figure by author)
In essence, our approach, during the translation process, preserves known NEs using the entity-replacement technique. Subsequently, these entities are substituted with their corresponding labels from a knowledge graph in the target translation language. This meticulous process ensures the precise translation of questions before they are addressed by a KGQA system.
Adhering to the insights from our previous article, we designate English as the common target translation language, leading to the nomenclature of our approach as “Lingua Franca” (inspired by the meaning of “bridge” or “link” language). It is essential to note that our framework is versatile and can seamlessly adapt to any other language as the target language. Importantly, Lingua Franca extends beyond the scope of KGQA and finds applicability in various entity-oriented search applications.
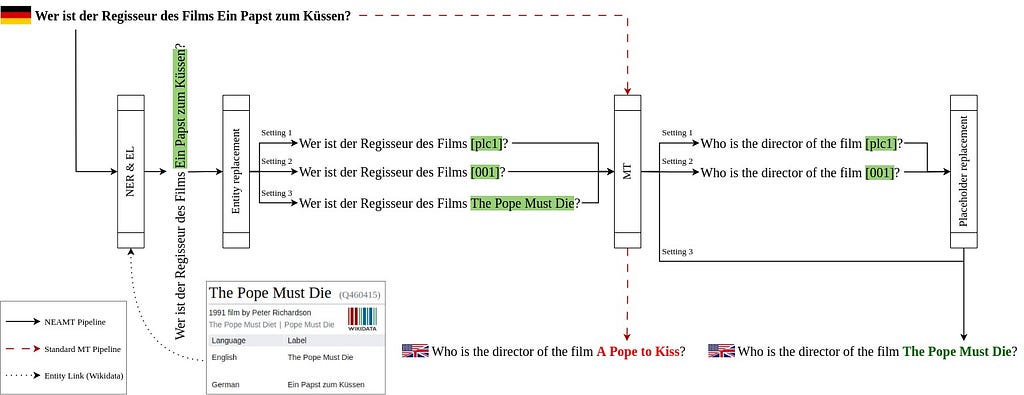
The Lingua Franca approach comprises three main steps: (1) Named Entity Recognition (NER) and Named Entity Linking (NEL), (2) the application of the entity-replacement technique based on identified named entities, and (3) utilizing a machine translation tool to generate text in a target language while considering information from the preceding steps. Here, English is consistently used as the target language, aligning with related research that deems it the most optimal strategy for Question Answering (QA) quality. However, the approach is not limited to English, and other languages can be employed if necessary.
The approach is implemented as an open-source framework, allowing users to build their Named-Entity Aware Machine Translation (NEAMT) pipelines by integrating custom NER, NEL, and MT components (see our GitHub). The details of the Lingua Franca approach for all settings are illustrated in the provided example, as shown in the figure below.
A detailed representation of the Lingua Franca approach following multiple settings (figure by author)
The experimental findings in this study strongly advocate for the superiority of Lingua Franca over standard MT tools when combined with KGQA systems.
Experimental Results
In evaluating each entity-replacement setting, the rate of corrupted placeholders or NE labels after processing through an MT tool was calculated. This rate serves as an indicator of the actual NE translation quality for the approach-related pipelines. The updated statistics are as follows:
Setting 1 (string-like placeholders): 6.63% of the placeholders were lost or corrupted.
Setting 2 (numerical placeholders): 2.89% of the placeholders were lost or corrupted.
Setting 3 (replacing the NEs with their English labels before translation): 6.16% of the labels were corrupted.
As a result, with our approach, we can confidently assert that up to 97.11% (Setting 2) of the recognized NEs in a text were translated correctly.
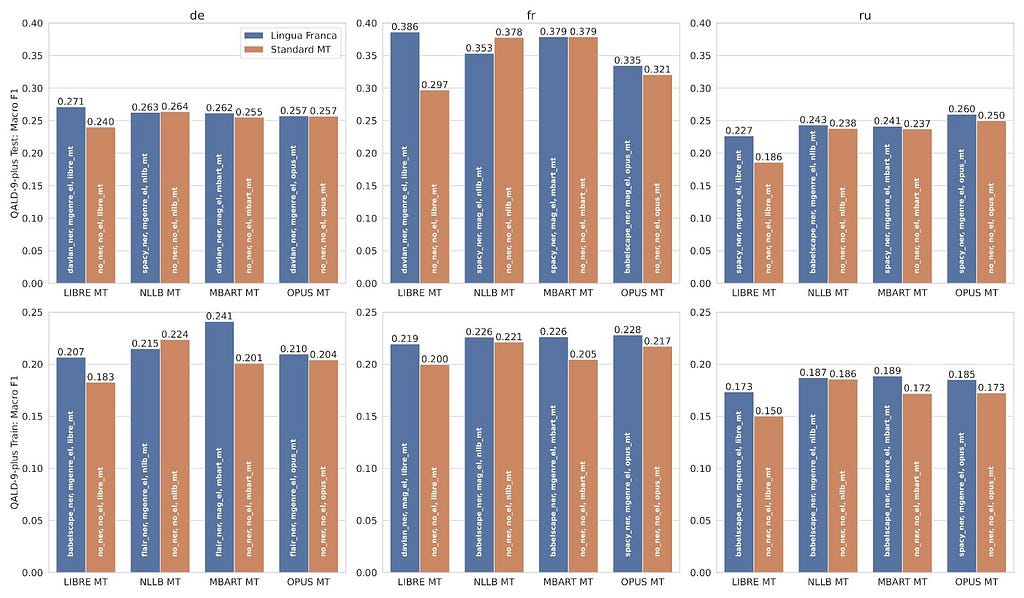
We analyzed the results regarding QA quality while taking into account the following experimental components: an approach pipeline or a standard MT tool, a source language, and a KGQA benchmark. The figure below illustrates the comparison between the approach and standard MT — these results can be interpreted as an ablation study.
Grouped bar plot of Macro F1 scores for our experiments (by author)
The grouped bar plot illustrates the Macro F1 score (obtained using Gerbil-QA) concerning each language and split. In the context of the ablation study, each group consists of two bars: the first one pertains to the best approach proposed by us, while the second bar reflects the performance of a standard MT tool (baseline).
We observed that in the majority of the experimental cases (19 out of 24) the KGQA systems that were using our approach outperformed the ones that used standard MT tools. To verify the statement above, we conducted the Wilcoxon signed-rank test on the same data. Based on the test results (p-value = 0.0008, with α = 0.01), we rejected the null hypothesis which denotes that the QA quality results have no difference, i.e., while combining KGQA with standard MT and while combining KGQA with the approach. Therefore, we conclude that the approach, which relies on our NEAMT framework, significantly improves the QA quality while answering multilingual questions in comparison to standard MT tools.
The reproducibility of the experiments was ensured by repeating them and calculating the Pearson’s correlation coefficient between all the QA quality metrics. The resulting coefficient of 0.794 corresponds to the borderline value between strong and very strong correlation. Therefore, we assume that our experiments are reproducible.
Conclusion
This paper introduces the NEAMT approach called Lingua Franca. Designed to enhance multilingual capabilities and improve QA quality in comparison to standard MT tools, Lingua Franca is tailored for use with KGQA systems in order to enlarge the scope of its possible users. The implementation and evaluation of Lingua Franca utilize a modular NEAMT framework developed by the authors, with detailed information provided in the section on Experiments. The key contributions of the paper include: (1) being the first, to the best of our knowledge, to combine the NEAMT approach (i.e., Lingua Franca) with KGQA; (2) presenting an open-source modular framework for NEAMT, allowing the research community to build their own MT pipelines; and (3) conducting a comprehensive evaluation and ablation study to demonstrate the effectiveness of the Lingua Franca approach.
For future work, we aim to expand our experimental setup to encompass a broader range of languages, benchmarks, and KGQA systems. To address damaged placeholders in the entity-replacement process, we plan to fine-tune the MT models using this data. Additionally, a more detailed error analysis, focusing on error propagation, will be conducted.
This research has been funded by the Federal Ministry of Education and Research, Germany (BMBF) under Grant numbers 01IS17046 and 01QE2056C, as well as the Ministry of Culture and Science of North Rhine-Westphalia, Germany (MKW NRW) under Grant Number NW21–059D. This research also was funded within the research project QA4CB — Entwicklung von Question-Answering-Komponenten zur Erweiterung des Chatbot-Frameworks.
Samsung has failed to recover from the sharp decline in profit it experienced in 2022. In its latest earnings report, the Korean company has reported KRW 258.94 trillion ($194 billion) in annual revenue and KRW 6.57 trillion ($4.9 billion) in operating profit for the fiscal year of 2023. Those are markedly smaller numbers than the previous fiscal year’s, especially the latter’s — Samsung posted an operating profit of KRW 43.38 trillion ($35 billion) for 2022, which was already $6.9 billion smaller than the year before due to the weak demand for its chips and smartphones. According to The Wall Street Journal, these numbers represent Samsung’s weakest earnings in over a decade.
The company says its memory business showed signs of recovery, but not enough to stop it from incurring KRW 2.18 trillion ($1.63 billion) in operating losses for the fourth quarter of 2023. Its visual display and digital appliances division also posted KRW 0.05 trillion ($37.5 million) in operating losses despite TV sales doing well in the fourth quarter due to the holiday season. Samsung’s mobile business showed a a decline in sales and profit quarter-on-quarter, as well, due to lower smartphone sales and “the fading of new-product effects” from previous flagship models.
For the first quarter of 2024, Samsung’s game plan is to improve its profits “by increasing sales of high value-added products,” such as components meant for generative AI products. It expects stronger demand for its chips in the PC and mobile sectors this year, but it admits that its earnings may not significantly recover soon because its customers are still downsizing their inventories. Samsung has high hopes for the Galaxy S24 series, though, and believes the devices’ AI capabilities can help its mobile business achieve a a double-digit growth in 2024. The Galaxy S24 phones have already started shipping with prices starting at $800 for the most basic version and at $1,300 for the S24 Ultra.
This article originally appeared on Engadget at https://www.engadget.com/samsungs-annual-profits-continued-to-decline-in-2023-090500640.html?src=rss
In 2018, Tesla awarded Elon Musk a $56 billion pay package that helped propel him to the top of world’s richest lists. Now, a judge in Delaware has rendered the deal between the company and the CEO to be invalid and called the compensation an “unfathomable sum” that’s unfair to shareholders. As initially seen and reported by Chancery Daily on Threads, the court of Chancery in Delaware has released its decision on the lawsuit filed by Richard Tornetta. The Tesla shareholder accused the automaker of breaching its fiduciary duty by approving a package that unjustly enriches its chief executive.
Judge Kathaleen McCormick wrote in the decision that Musk “enjoyed thick ties” with the directors who were in charge of negotiating his pay package on behalf of Tesla, which means there “was no meaningful negotiation over any of the terms of the plan.” The judge also talked about how Musk owned 21.9 percent of the automaker when the package was negotiated. That gave him “every incentive to push Tesla to levels of transformative growth,” because he stood to gain $10 billion for every $50 billion in market capitalization increase.
“Swept up by the rhetoric of ‘all upside,’ or perhaps starry eyed by Musk’s superstar appeal, the board never asked the $55.8 billion question: Was the plan even necessary for Tesla to retain Musk and achieve its goals?” the judge wrote in the court document. As The Washington Post notes, she ruled that Tornetta is entitled to a “rescission” and has ordered Tesla and its shareholders to carry out her decision and undo the deal. Musk’s camp, however, can still appeal her ruling.
Musk has sold some of his Tesla stocks to help pay for his acquisition of Twitter, now X, from the time his pay package was approved. At the moment, he owns around 13 percent of Tesla, though he recently said that he wants 25 percent control over the company before he’s comfortable growing it to be a leader in AI and robotics.
In response to the court’s decision, Musk tweeted: “Never incorporate your company in the state of Delaware.” He also posted a poll asking followers whether Tesla should change its state of incorporation to Texas, where its physical headquarters are located.
This article originally appeared on Engadget at https://www.engadget.com/elon-musks-56-billion-tesla-pay-package-has-been-tossed-out-by-the-court-074235803.html?src=rss
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.