AI could be evolving faster than we can learn from it, which could be putting businesses at risk.
Originally appeared here:
The security implications of AI integration — Azeria Labs CEO explores the future of AI and its threat landscape
Originally appeared here:
The security implications of AI integration — Azeria Labs CEO explores the future of AI and its threat landscape
Originally appeared here:
Storage startup uses your GPU to create virtual super fast SSD — but for some reason, it is not yet compatible with Intel and AMD tech


Standout features of the M2 MacBook Pro are the 14.2″ Liquid Retina XDR display with a resolution of 3024×1964, as well as the M2 chip with a 10-core CPU and 16-core GPU. From crisp, vibrant visuals to Apple Silicon performance, there’s a lot to love about the closeout model.
Go Here to Read this Fast! Grab an M2 MacBook Pro for just $1,579 today only
Originally appeared here:
Grab an M2 MacBook Pro for just $1,579 today only
Go Here to Read this Fast! Vision Pro headset proves buggy for prominent Apple tipster
Originally appeared here:
Vision Pro headset proves buggy for prominent Apple tipster
Go Here to Read this Fast! Russian cosmonaut breaks record for time spent in space
Originally appeared here:
Russian cosmonaut breaks record for time spent in space
This poses a problem because most Machine Learning algorithms use only numerical data as input. However, categorical data is usually not a challenge to deal with, thanks to simple, well-defined functions that transform them into numerical values. If you have taken any data science course, you will be familiar with the one hot encoding strategy for categorical features. This strategy is great when your features have limited categories. However, you will run into some issues when dealing with high cardinal features (features with many categories)
Here is how you can use target encoding to transform Categorical features into numerical values.

Early in any data science course, you are introduced to one hot encoding as a key strategy to deal with categorical values, and rightfully so, as this strategy works really well on low cardinal features (features with limited categories).
In a nutshell, One hot encoding transforms each category into a binary vector, where the corresponding category is marked as ‘True’ or ‘1’, and all other categories are marked with ‘False’ or ‘0’.
import pandas as pd
# Sample categorical data
data = {'Category': ['Red', 'Green', 'Blue', 'Red', 'Green']}
# Create a DataFrame
df = pd.DataFrame(data)
# Perform one-hot encoding
one_hot_encoded = pd.get_dummies(df['Category'])
# Display the result
print(one_hot_encoded)

While this works great for features with limited categories (Less than 10–20 categories), as the number of categories increases, the one-hot encoded vectors become longer and sparser, potentially leading to increased memory usage and computational complexity, let’s look at an example.
The below code uses Amazon Employee Access data, made publicity available in kaggle: https://www.kaggle.com/datasets/lucamassaron/amazon-employee-access-challenge
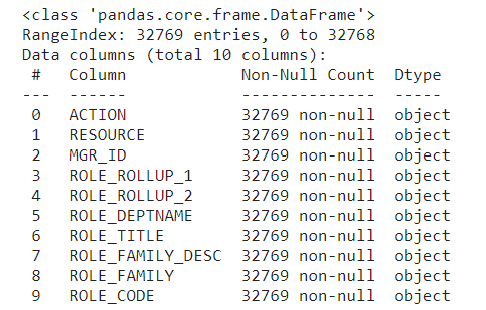
The data contains eight categorical feature columns indicating characteristics of the required resource, role, and workgroup of the employee at Amazon.
data.info()
# Display the number of unique values in each column
unique_values_per_column = data.nunique()
print("Number of unique values in each column:")
print(unique_values_per_column)
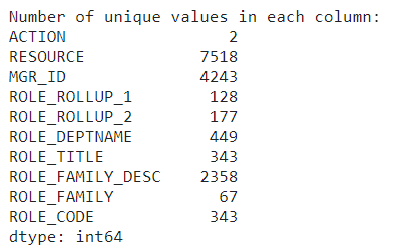
Using one hot encoding could be challenging in a dataset like this due to the high number of distinct categories for each feature.
#Initial data memory usage
memory_usage = data.memory_usage(deep=True)
total_memory_usage = memory_usage.sum()
print(f"nTotal memory usage of the DataFrame: {total_memory_usage / (1024 ** 2):.2f} MB")

#one-hot encoding categorical features
data_encoded = pd.get_dummies(data,
columns=data.select_dtypes(include='object').columns,
drop_first=True)
data_encoded.shape
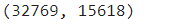

# Memory usage for the one-hot encoded dataset
memory_usage = data_encoded.memory_usage(deep=True)
total_memory_usage = memory_usage.sum()
print(f"nTotal memory usage of the DataFrame: {total_memory_usage / (1024 ** 2):.2f} MB")

As you can see, one-hot encoding is not a viable solution to deal with high cardinal categorical features, as it significantly increases the size of the dataset.
In cases with high cardinal features, target encoding is a better option.
Target encoding transforms a categorical feature into a numeric feature without adding any extra columns, avoiding turning the dataset into a larger and sparser dataset.
Target encoding works by converting each category of a categorical feature into its corresponding expected value. The approach to calculating the expected value will depend on the value you are trying to predict.
For Regression problems, the expected value is simply the average value for that category.
For Classification problems, the expected value is the conditional probability given that category.
In both cases, we can get the results by simply using the ‘group_by’ function in pandas.
#Example of how to calculate the expected value for Target encoding of a Binary outcome
expected_values = data.groupby('ROLE_TITLE')['ACTION'].value_counts(normalize=True).unstack()
expected_values
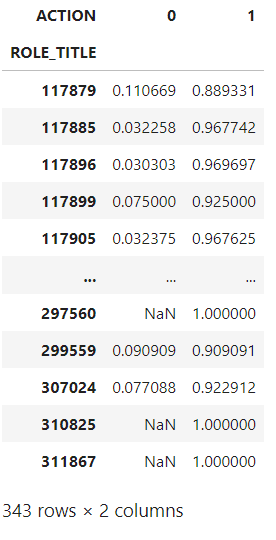
The resulting table indicates the probability of each “ACTION” outcome by unique “ROLE_TITLE” id. All that is left to do is replace the “ROLE_TITLE” id with the values from the probability of “ACTION” being 1 in the original dataset. (i.e instead of category 117879 the dataset will show 0.889331)
While this can give us an intuition of how target encoding works, using this simple method runs the risk of overfitting. Especially for rare categories, as in those cases, target encoding will essentially provide the target value to the model. Also, the above method can only deal with seen categories, so if your test data has a new category, it won’t be able to handle it.
To avoid those errors, you need to make the target encoding transformer more robust.
To make target encoding more robust, you can create a custom transformer class and integrate it with scikit-learn so that it can be used in any model pipeline.
NOTE: The below code is taken from the book “The Kaggle Book” and can be found in Kaggle: https://www.kaggle.com/code/lucamassaron/meta-features-and-target-encoding
import numpy as np
import pandas as pd
from sklearn.base import BaseEstimator, TransformerMixin
class TargetEncode(BaseEstimator, TransformerMixin):
def __init__(self, categories='auto', k=1, f=1,
noise_level=0, random_state=None):
if type(categories)==str and categories!='auto':
self.categories = [categories]
else:
self.categories = categories
self.k = k
self.f = f
self.noise_level = noise_level
self.encodings = dict()
self.prior = None
self.random_state = random_state
def add_noise(self, series, noise_level):
return series * (1 + noise_level *
np.random.randn(len(series)))
def fit(self, X, y=None):
if type(self.categories)=='auto':
self.categories = np.where(X.dtypes == type(object()))[0]
temp = X.loc[:, self.categories].copy()
temp['target'] = y
self.prior = np.mean(y)
for variable in self.categories:
avg = (temp.groupby(by=variable)['target']
.agg(['mean', 'count']))
# Compute smoothing
smoothing = (1 / (1 + np.exp(-(avg['count'] - self.k) /
self.f)))
# The bigger the count the less full_avg is accounted
self.encodings[variable] = dict(self.prior * (1 -
smoothing) + avg['mean'] * smoothing)
return self
def transform(self, X):
Xt = X.copy()
for variable in self.categories:
Xt[variable].replace(self.encodings[variable],
inplace=True)
unknown_value = {value:self.prior for value in
X[variable].unique()
if value not in
self.encodings[variable].keys()}
if len(unknown_value) > 0:
Xt[variable].replace(unknown_value, inplace=True)
Xt[variable] = Xt[variable].astype(float)
if self.noise_level > 0:
if self.random_state is not None:
np.random.seed(self.random_state)
Xt[variable] = self.add_noise(Xt[variable],
self.noise_level)
return Xt
def fit_transform(self, X, y=None):
self.fit(X, y)
return self.transform(X)
It might look daunting at first, but let’s break down each part of the code to understand how to create a robust Target encoder.
class TargetEncode(BaseEstimator, TransformerMixin):
This first step ensures that you can use this transformer class in scikit-learn pipelines for data preprocessing, feature engineering, and machine learning workflows. It achieves this by inheriting the scikit-learn classes BaseEstimator and TransformerMixin.
Inheritance allows the TargetEncode class to reuse or override methods and attributes defined in the base classes, in this case, BaseEstimator and TransformerMixin
BaseEstimator is a base class for all scikit-learn estimators. Estimators are objects in scikit-learn with a “fit” method for training on data and a “predict” method for making predictions.
TransformerMixin is a mixin class for transformers in scikit-learn, it provides additional methods such as “fit_transform”, which combines fitting and transforming in a single step.
Inheriting from BaseEstimator & TransformerMixin, allows TargetEncode to implement these methods, making it compatible with the scikit-learn API.
def __init__(self, categories='auto', k=1, f=1,
noise_level=0, random_state=None):
if type(categories)==str and categories!='auto':
self.categories = [categories]
else:
self.categories = categories
self.k = k
self.f = f
self.noise_level = noise_level
self.encodings = dict()
self.prior = None
self.random_state = random_state
This second step defines the constructor for the “TargetEncode” class and initializes the instance variables with default or user-specified values.
The “categories” parameter determines which columns in the input data should be considered as categorical variables for target encoding. It is Set by default to ‘auto’ to automatically identify categorical columns during the fitting process.
The parameters k, f, and noise_level control the smoothing effect during target encoding and the level of noise added during transformation.
This next step is very important to avoid overfitting.
def add_noise(self, series, noise_level):
return series * (1 + noise_level *
np.random.randn(len(series)))
The “add_noise” method adds random noise to introduce variability and prevent overfitting during the transformation phase.
“np.random.randn(len(series))” generates an array of random numbers from a standard normal distribution (mean = 0, standard deviation = 1).
Multiplying this array by “noise_level” scales the random noise based on the specified noise level.”
This step contributes to the robustness and generalization capabilities of the target encoding process.
This part of the code trains the target encoder on the provided data by calculating the target encodings for categorical columns and storing them for later use during transformation.
def fit(self, X, y=None):
if type(self.categories)=='auto':
self.categories = np.where(X.dtypes == type(object()))[0]
temp = X.loc[:, self.categories].copy()
temp['target'] = y
self.prior = np.mean(y)
for variable in self.categories:
avg = (temp.groupby(by=variable)['target']
.agg(['mean', 'count']))
# Compute smoothing
smoothing = (1 / (1 + np.exp(-(avg['count'] - self.k) /
self.f)))
# The bigger the count the less full_avg is accounted
self.encodings[variable] = dict(self.prior * (1 -
smoothing) + avg['mean'] * smoothing)
The smoothing term helps prevent overfitting, especially when dealing with categories with small samples.
The method follows the scikit-learn convention for fit methods in transformers.
It starts by checking and identifying the categorical columns and creating a temporary DataFrame, containing only the selected categorical columns from the input X and the target variable y.
The prior mean of the target variable is calculated and stored in the prior attribute. This represents the overall mean of the target variable across the entire dataset.
Then, it calculates the mean and count of the target variable for each category using the group-by method, as seen previously.
There is an additional smoothing step to prevent overfitting on categories with small numbers of samples. Smoothing is calculated based on the number of samples in each category. The larger the count, the less the smoothing effect.
The calculated encodings for each category in the current variable are stored in the encodings dictionary. This dictionary will be used later during the transformation phase.
This part of the code replaces the original categorical values with their corresponding target-encoded values stored in self.encodings.
def transform(self, X):
Xt = X.copy()
for variable in self.categories:
Xt[variable].replace(self.encodings[variable],
inplace=True)
unknown_value = {value:self.prior for value in
X[variable].unique()
if value not in
self.encodings[variable].keys()}
if len(unknown_value) > 0:
Xt[variable].replace(unknown_value, inplace=True)
Xt[variable] = Xt[variable].astype(float)
if self.noise_level > 0:
if self.random_state is not None:
np.random.seed(self.random_state)
Xt[variable] = self.add_noise(Xt[variable],
self.noise_level)
return Xt
This step has an additional robustness check to ensure the target encoder can handle new or unseen categories. For those new or unknown categories, it replaces them with the mean of the target variable stored in the prior_mean variable.
If you need more robustness against overfitting, you can set up a noise_level greater than 0 to add random noise to the encoded values.
The fit_transform method combines the functionality of fitting and transforming the data by first fitting the transformer to the training data and then transforming it based on the calculated encodings.
Now that you understand how the code works, let’s see it in action.
#Instantiate TargetEncode class
te = TargetEncode(categories='ROLE_TITLE')
te.fit(data, data['ACTION'])
te.transform(data[['ROLE_TITLE']])
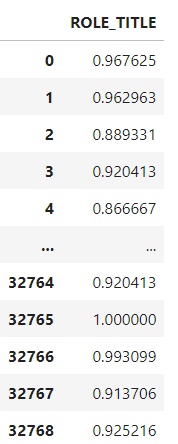
The Target encoder replaced each “ROLE_TITLE” id with the probability of each category. Now, let’s do the same for all features and check the memory usage after using Target Encoding.
y = data['ACTION']
features = data.drop('ACTION',axis=1)
te = TargetEncode(categories=features.columns)
te.fit(features,y)
te_data = te.transform(features)
te_data.head()
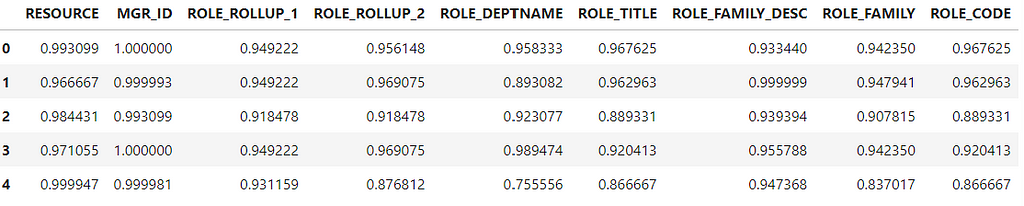
memory_usage = te_data.memory_usage(deep=True)
total_memory_usage = memory_usage.sum()
print(f"nTotal memory usage of the DataFrame: {total_memory_usage / (1024 ** 2):.2f} MB")

Target encoding successfully transformed the categorical data into numerical without creating extra columns or increasing memory usage.
So far we have created our own target encoder class, however you don’t have to do this anymore.
In scikit-learn version 1.3 release, somewhere around June 2023, they introduced the Target Encoder class to their API. Here is how you can use target encoding with Scikit Learn
from sklearn.preprocessing import TargetEncoder
#Splitting the data
y = data['ACTION']
features = data.drop('ACTION',axis=1)
#Specify the target type
te = TargetEncoder(smooth="auto",target_type='binary')
X_trans = te.fit_transform(features, y)
#Creating a Dataframe
features_encoded = pd.DataFrame(X_trans, columns = features.columns)
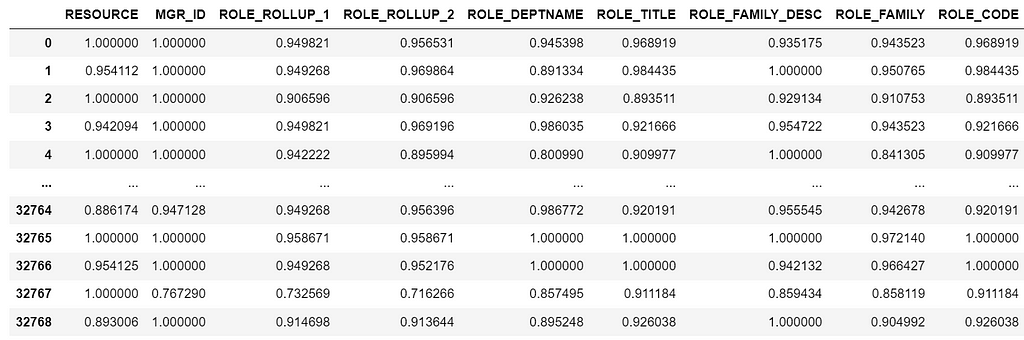
Note that we are getting slightly different results from the manual Target encoder class because of the smooth parameter and randomness on the noise level.
As you see, sklearn makes it easy to run target encoding transformations. However, it is important to understand how the transformation works under the hood first to understand and explain the output.
While Target encoding is a powerful encoding method, it’s important to consider the specific requirements and characteristics of your dataset and choose the encoding method that best suits your needs and the requirements of the machine learning algorithm you plan to use.
[1] Banachewicz, K. & Massaron, L. (2022). The Kaggle Book: Data Analysis and Machine Learning for Competitive Data Science. Packt>
[2] Massaron, L. (2022, January). Amazon Employee Access Challenge. Retrieved February 1, 2024, from https://www.kaggle.com/datasets/lucamassaron/amazon-employee-access-challenge
[3] Massaron, L. Meta-features and target encoding. Retrieved February 1, 2024, from https://www.kaggle.com/luca-massaron/meta-features-and-target-encoding
[4] Scikit-learn.sklearn.preprocessing.TargetEncoder. In scikit-learn: Machine learning in Python (Version 1.3). Retrieved February 1, 2024, from https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.TargetEncoder.html
Encoding Categorical Variables: A Deep Dive into Target Encoding was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Encoding Categorical Variables: A Deep Dive into Target Encoding
Go Here to Read this Fast! Encoding Categorical Variables: A Deep Dive into Target Encoding

Tagging mountaineering accident reports with problem types and exploring tag coverage to determine the need for more tags.
Originally appeared here:
Tagging Mountaineering Accident Reports Using bart-large-mnli
Go Here to Read this Fast! Tagging Mountaineering Accident Reports Using bart-large-mnli


Illustration of Python Threading, Processing and GIL by Diagrams
Originally appeared here:
Don’t Know What is Python GIL? This May be the Easiest Tutorial
Go Here to Read this Fast! Don’t Know What is Python GIL? This May be the Easiest Tutorial
Before diving into the technical aspect of the article let’s set the context and answer the question that you might have, What is a knowledge graph ?
And to answer this, imagine instead of storing the knowledge in cabinets we store them in a fabric net. Each fact, concept, piece of information about people, places, events, or even abstract ideas are knots, and the line connecting them together is the relationship they have with each other. This intricate web, my friends, is the essence of a knowledge graph.

Think of it like a bustling city map, not just showing streets but revealing the connections between landmarks, parks, and shops. Similarly, a knowledge graph doesn’t just store cold facts; it captures the rich tapestry of how things are linked. For example, you might learn that Marie Curie discovered radium, then follow a thread to see that radium is used in medical treatments, which in turn connect to hospitals and cancer research. See how one fact effortlessly leads to another, painting a bigger picture?
So why is this map-like way of storing knowledge so popular? Well, imagine searching for information online. Traditional methods often leave you with isolated bits and pieces, like finding only buildings on a map without knowing the streets that connect them. A knowledge graph, however, takes you on a journey, guiding you from one fact to another, like having a friendly guide whisper fascinating stories behind every corner of the information world. Interesting right? I know.
Since I discovered this magic, it captured my attention and I explored and played around with many potential applications. In this article, I will show you how to build a pipeline that extracts audio from video, then transcribes that audio, and from the transcription, build a knowledge graph allowing for a more nuanced and interconnected representation of information within the video.
I will be using Google Drive to upload the video sample. I will also use Google Colab to write the code, and finally, you need access to the GPT Plus API for this project. I will break this down into steps to make it clear and easy for beginners:
By the end of this article, you will construct a graph with the following schema.

Let’s dive right into it!
As mentioned, we will be using Google Drive and Colab. In the first cell, let’s connect Google Drive to Colab and create our directory folders (video_files, audio_files, text_files). The following code can get this done. (If you want to follow along with the code, I have uploaded all the code for this project on GitHub; you can access it from here.)
# installing required libraries
!pip install pydub
!pip install git+https://github.com/openai/whisper.git
!sudo apt update && sudo apt install ffmpeg
!pip install networkx matplotlib
!pip install openai
!pip install requests
# connecting google drive to import video samples
from google.colab import drive
import os
drive.mount('/content/drive')
video_files = '/content/drive/My Drive/video_files'
audio_files = '/content/drive/My Drive/audio_files'
text_files = '/content/drive/My Drive/text_files'
folders = [video_files, audio_files, text_files]
for folder in folders:
# Check if the output folder exists
if not os.path.exists(folder):
# If not, create the folder
os.makedirs(folder)
Or you can create the folders manually and upload your video sample to the “video_files” folder, whichever is easier for you.
Now we have our three folders with a video sample in the “video_files” folder to test the code.
The next thing we want to do is to import our video and extract the audio from it. We can use the Pydub library, which is a high-level audio processing library that can help us to do that. Let’s see the code and then explain it underneath.
from pydub import AudioSegment
# Extract audio from videos
for video_file in os.listdir(video_files):
if video_file.endswith('.mp4'):
video_path = os.path.join(video_files, video_file)
audio = AudioSegment.from_file(video_path, format="mp4")
# Save audio as WAV
audio.export(os.path.join(audio_files, f"{video_file[:-4]}.wav"), format="wav")
After installing our package pydub, we imported the AudioSegment class from the Pydub library. Then, we created a loop that iterates through all the video files in the “video_files” folder we created earlier and passes each file through AudioSegment.from_file to load the audio from the video file. The loaded audio is then exported as a WAV file using audio.export and saved in the specified “audio_files” folder with the same name as the video file but with the extension .wav.
At this point, you can go to the “audio_files” folder in Google Drive where you will see the extracted audio.
In the third step, we will transcribe the audio file we have to a text file and save it as a .txt file in the “text_files” folder. Here I used the Whisper ASR (Automatic Speech Recognition) system from OpenAI to do this. I used it because it’s easy and fairly accurate, beside it has different models for different accuracy. But the more accurate the model is the larger the model the slower to load, hence I will be using the medium one just for demonstration. To make the code cleaner, let’s create a function that transcribes the audio and then use a loop to use the function on all the audio files in our directory
import re
import subprocess
# function to transcribe and save the output in txt file
def transcribe_and_save(audio_files, text_files, model='medium.en'):
# Construct the Whisper command
whisper_command = f"whisper '{audio_files}' --model {model}"
# Run the Whisper command
transcription = subprocess.check_output(whisper_command, shell=True, text=True)
# Clean and join the sentences
output_without_time = re.sub(r'[d+:d+.d+ --> d+:d+.d+] ', '', transcription)
sentences = [line.strip() for line in output_without_time.split('n') if line.strip()]
joined_text = ' '.join(sentences)
# Create the corresponding text file name
audio_file_name = os.path.basename(audio_files)
text_file_name = os.path.splitext(audio_file_name)[0] + '.txt'
file_path = os.path.join(text_files, text_file_name)
# Save the output as a txt file
with open(file_path, 'w') as file:
file.write(joined_text)
print(f'Text for {audio_file_name} has been saved to: {file_path}')
# Transcribing all the audio files in the directory
for audio_file in os.listdir(audio_files):
if audio_file.endswith('.wav'):
audio_files = os.path.join(audio_files, audio_file)
transcribe_and_save(audio_files, text_files)
Libraries Used:
We created a Whisper command and saved it as a variable to facilitate the process. After that, we used subprocess.check_output to run the Whisper command and save the resulting transcription in the transcription variable. But the transcription at this point is not clean (you can check it by printing the transcription variable out of the function; it has timestamps and a couple of lines that are not relevant to the transcription), so we added a cleaning code that removes the timestamp using re.sub and joins the sentences together. After that, we created a text file within the “text_files” folder with the same name as the audio and saved the cleaned transcription in it.
Now if you go to the “text_files” folder, you can see the text file that contains the transcription. Woah, step 3 done successfully! Congratulations!
This is the crucial part — and maybe the longest. I will follow a modular approach with 5 functions to handle this task, but before that, let’s begin with the libraries and modules necessary for making HTTP requests requests, handling JSON json, working with data frames pandas, and creating and visualizing graphs networkx and matplotlib. And setting the global constants which are variables used throughout the code. API_ENDPOINT is the endpoint for OpenAI’s API, API_KEY is where the OpenAI API key will be stored, and prompt_text will store the text used as input for the OpenAI prompt. All of this is done in this code
import requests
import json
import pandas as pd
import networkx as nx
import matplotlib.pyplot as plt
# Global Constants API endpoint, API key, prompt text
API_ENDPOINT = "https://api.openai.com/v1/chat/completions"
api_key = "your_openai_api_key_goes_here"
prompt_text = """Given a prompt, extrapolate as many relationships as possible from it and provide a list of updates.
If an update is a relationship, provide [ENTITY 1, RELATIONSHIP, ENTITY 2]. The relationship is directed, so the order matters.
Example:
prompt: Sun is the source of solar energy. It is also the source of Vitamin D.
updates:
[["Sun", "source of", "solar energy"],["Sun","source of", "Vitamin D"]]
prompt: $prompt
updates:"""
Then let’s continue with breaking down the structure of our functions:
The first function, create_graph(), the task of this function is to create a graph visualization using the networkx library. It takes a DataFrame df and a dictionary of edge labels rel_labels — which will be created on the following function — as input. Then, it uses the DataFrame to create a directed graph and visualizes it using matplotlib with some customization and outputs the beautiful graph we need
# Graph Creation Function
def create_graph(df, rel_labels):
G = nx.from_pandas_edgelist(df, "source", "target",
edge_attr=True, create_using=nx.MultiDiGraph())
plt.figure(figsize=(12, 12))
pos = nx.spring_layout(G)
nx.draw(G, with_labels=True, node_color='skyblue', edge_cmap=plt.cm.Blues, pos=pos)
nx.draw_networkx_edge_labels(
G,
pos,
edge_labels=rel_labels,
font_color='red'
)
plt.show()
The DataFrame df and the edge labels rel_labels are the output of the next function, which is: preparing_data_for_graph(). This function takes the OpenAI api_response — which will be created from the following function — as input and extracts the entity-relation triples (source, target, edge) from it. Here we used the json module to parse the response and obtain the relevant data, then filter out elements that have missing data. After that, build a knowledge base dataframe kg_df from the triples, and finally, create a dictionary (relation_labels) mapping pairs of nodes to their corresponding edge labels, and of course, return the DataFrame and the dictionary.
# Data Preparation Function
def preparing_data_for_graph(api_response):
#extract response text
response_text = api_response.text
entity_relation_lst = json.loads(json.loads(response_text)["choices"][0]["text"])
entity_relation_lst = [x for x in entity_relation_lst if len(x) == 3]
source = [i[0] for i in entity_relation_lst]
target = [i[2] for i in entity_relation_lst]
relations = [i[1] for i in entity_relation_lst]
kg_df = pd.DataFrame({'source': source, 'target': target, 'edge': relations})
relation_labels = dict(zip(zip(kg_df.source, kg_df.target), kg_df.edge))
return kg_df,relation_labels
The third function is call_gpt_api(), which is responsible for making a POST request to the OpenAI API and output the api_response. Here we construct the data payload with model information, prompt, and other parameters like the model (in this case: gpt-3.5-turbo-instruct), max_tokens, stop, and temperature. Then send the request using requests.post and return the response. I have also included simple error handling to print an error message in case an exception occurs. The try block contains the code that might raise an exception from the request during execution, so if an exception occurs during this process (for example, due to network issues, API errors, etc.), the code within the except block will be executed.
# OpenAI API Call Function
def call_gpt_api(api_key, prompt_text):
global API_ENDPOINT
try:
data = {
"model": "gpt-3.5-turbo",
"prompt": prompt_text,
"max_tokens": 3000,
"stop": "n",
"temperature": 0
}
headers = {"Content-Type": "application/json", "Authorization": "Bearer " + api_key}
r = requests.post(url=API_ENDPOINT, headers=headers, json=data)
response_data = r.json() # Parse the response as JSON
print("Response content:", response_data)
return response_data
except Exception as e:
print("Error:", e)
Then the function before the last is the main() function, which orchestrates the main flow of the script. First, it reads the text file contents from the “text_files” folder we had earlier and saves it in the variable kb_text. Bring the global variable prompt_text, which stores our prompt, then replace a placeholder in the prompt template ($prompt) with the text file content kb_text. Then call the call_gpt_api() function, give it the api_key and prompt_text to get the OpenAI API response. The response is then passed to preparing_data_for_graph() to prepare the data and get the DataFrame and the edge labels dictionary, finally pass these two values to the create_graph() function to build the knowledge graph.
# Main function
def main(text_file_path, api_key):
with open(file_path, 'r') as file:
kb_text = file.read()
global prompt_text
prompt_text = prompt_text.replace("$prompt", kb_text)
api_response = call_gpt_api(api_key, prompt_text)
df, rel_labels = preparing_data_for_graph(api_response)
create_graph(df, rel_labels)code
Finally, we have the start() function, which iterates through all the text files in our “text_files” folder — if we have more than one, gets the name and the path of the file, and passes it along with the api_key to the main function to do its job.
# Start Function
def start():
for filename in os.listdir(text_files):
if filename.endswith(".txt"):
# Construct the full path to the text file
text_file_path = os.path.join(text_files, filename)
main(text_file_path, api_key)
If you have correctly followed the steps, after running the start() function, you should see a similar visualization.
You can of course save this knowledge graph in the Neo4j database and take it further.
NOTE: This workflow ONLY applies to videos you own or whose terms allow this kind of download/processing.
Knowledge graphs use semantic relationships to represent data, enabling a more nuanced and context-aware understanding. This semantic richness allows for more sophisticated querying and analysis, as the relationships between entities are explicitly defined.
In this article, I outline detailed steps on how to build a pipeline that involves extracting audio from videos, transcribing with OpenAI’s Whisper ASR, and crafting a knowledge graph. As someone interested in this field, I hope that this article makes it easier to understand for beginners, demonstrating the potential and versatility of knowledge graph applications.
And as always the whole code is available in GitHub.
A Beginner’s Guide to Building Knowledge Graphs from Videos was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
A Beginner’s Guide to Building Knowledge Graphs from Videos
Go Here to Read this Fast! A Beginner’s Guide to Building Knowledge Graphs from Videos

