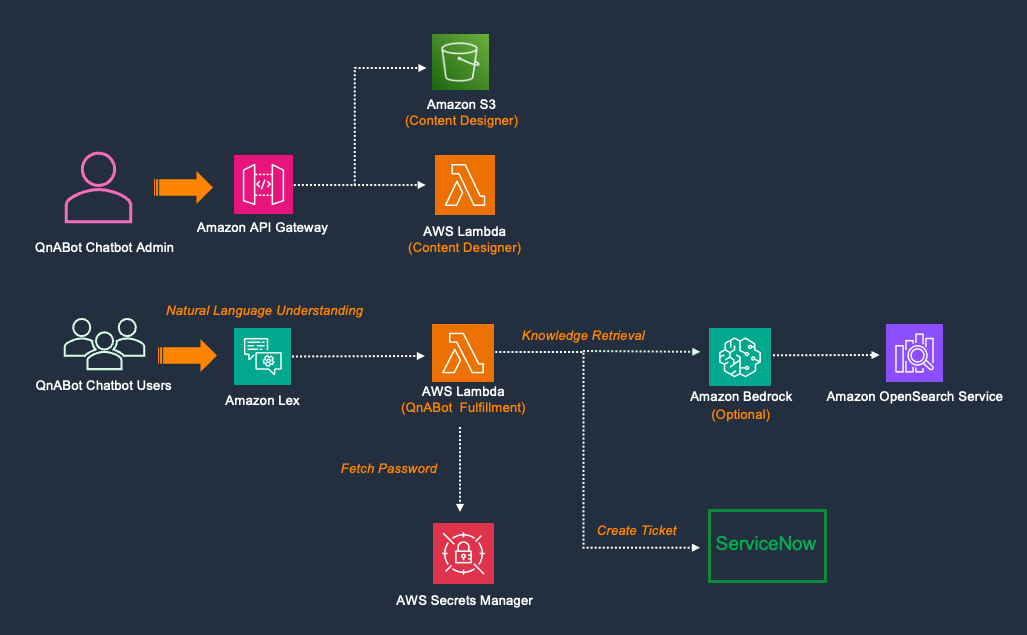
For a data engineer building analytics from transactional systems such as ERP (enterprise resource planning) and CRM (customer relationship management), the main challenge lies in navigating the gap between raw operational data and domain knowledge. ERP and CRM systems are designed and built to fulfil a broad range of business processes and functions. This generalisation makes their data models complex and cryptic and require domain expertise.
Even harder to manage, a common setup within large organisations is to have several instances of these systems with some underlaying processes in charge of transmitting data among them, which could lead to duplications, inconsistencies, and opacity.
The disconnection between the operational teams immersed in the day-to-day functions and those extracting business value from data generated in the operational processes still remains a significant friction point.
Searching for data
Imagine being a data engineer/analyst tasked with identifying the top-selling products within your company. Your first step might be to locate the orders. Then you begin researching database objects and find a couple of views, but there are some inconsistencies between them so you do not know which one to use. Additionally, it is really hard to identify the owners, one of them has even recently left the company. As you do not want to start your development with uncertainty, you decide to go for the operational raw data directly. Does it sound familiar?
Accessing Operational Data
I used to connect to views in transactional databases or APIs offered by operational systems to request the raw data.
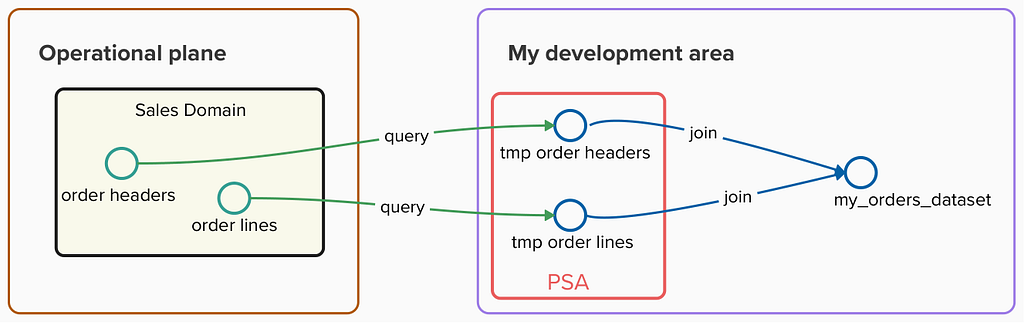
Order snapshots are stored in my own development area (image by the author)
To prevent my extractions from impacting performance on the operational side, I queried this data regularly and stored it in a persistent staging area (PSA) within my data warehouse. This allowed me to execute complex queries and data pipelines using these snapshots without consuming any resource from operational systems, but could result in unnecessary duplication of data in case I was not aware of other teams doing the same extraction.
Understanding Operational Data
Once the raw operational data was available, then I needed to deal with the next challenge: deciphering all the cryptic objects and properties and dealing with the labyrinth of dozens of relationships between them (i.e. General Material Data in SAP documented https://leanx.eu/en/sap/table/mara.html)
Even though standard objects within ERP or CRM systems are well documented, I needed to deal with numerous custom objects and properties that require domain expertise as these objects cannot be found in the standard data models. Most of the time I found myself throwing ‘trial-and-error’ queries in an attempt to align keys across operational objects, interpreting the meaning of the properties according to their values and checking with operational UI screenshots my assumptions.
Operational data management in Data Mesh
A Data Mesh implementation improved my experience in these aspects:
Knowledge: I could quickly identify the owners of the exposed data. The distance between the owner and the domain that generated the data is key to expedite further analytical development.
Discoverability: A shared data platform provides a catalog of operational datasets in the form of source-aligned data products that helped me to understand the status and nature of the data exposed.
Accessibility: I could easily request access to these data products. As this data is stored in the shared data platform and not in the operational systems, I did not need to align with operational teams for available windows to run my own data extraction without impacting operational performance.
Source-aligned Data Products
According to the Data Mesh taxonomy, data products built on top of operational sources are named Source-aligned Data Products:
Source domain datasets represent closely the raw data at the point of creation, and are not fitted or modelled for a particular consumer — Zhamak Dehghani
Source-aligned data products aim to represent operational sources within a shared data platform in a one-to-one relationship with operational entities and they should not hold any business logic that could alter any of their properties.
Ownership
In a Data Mesh implementation, these data products should strictlybe owned by the business domain that generates the raw data. The owner is responsible for the quality, reliability, and accessibility of their data and data is treated as a product that can be used by the same team and other data teams in other parts of the organisation.
This ownership ensures domain knowledge is close to the exposed data. This is critical to enabling the fast development of analytical data products, as any clarification needed by other data teams can be handled quickly and effectively.
Implementation
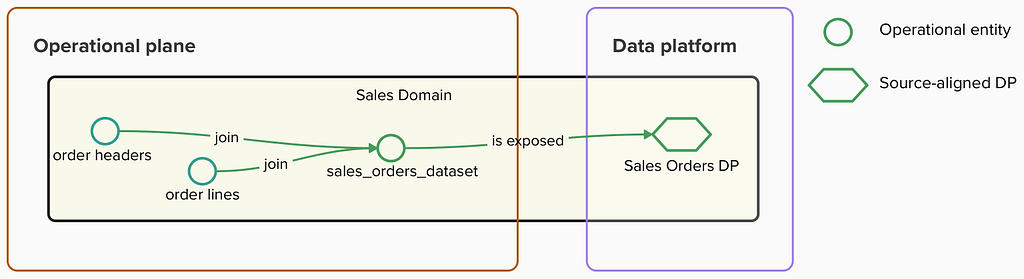
Following this approach, the Sales domain is responsible for publishing a ‘sales_orders’ data product and making it available in a shared data catalog.
Sales Orders DP exposing sales_orders_dataset (image by the author)
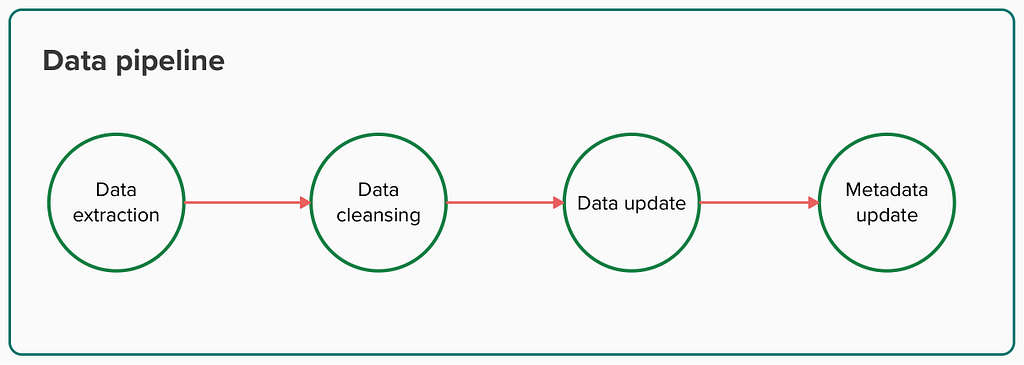
The data pipeline in charge of maintaining the data product could be defined like this:
Data pipeline steps (image by the author)
Data extraction
The first step to building source-aligned data products is to extract the data we want to expose from operational sources. There are a bunch of Data Integration tools that offer a UI to simplify the ingestion. Data teams can create a job there to extract raw data from operational sources using JDBC connections or APIs. To avoid wasting computational work, and whenever possible, only the updated raw data since the last extraction should be incrementally added to the data product.
Data cleansing
Now that we have obtained the desired data, the next step involves some curation, so consumers do not need to deal with existing inconsistencies in the real sources. Although any business logic should not not be implemented when building source-aligned data products, basic cleansing and standardisation is allowed.
-- Example of property standardisation in a sql query used to extract data case when lower(SalesDocumentCategory) = 'invoice' then 'Invoice' when lower(SalesDocumentCategory) = 'invoicing' then 'Invoice' else SalesDocumentCategory end as SALES_DOCUMENT_CATEGORY
Data update
Once extracted operational data is prepared for consumption, the data product’s internal dataset is incrementally updated with the latest snapshot.
One of the requirements for a data product is to be interoperable. This means that we need to expose global identifiers so our data product might be universally used in other domains.
Metadata update
Data products need to be understandable. Producers need to incorporate meaningful metadata for the entities and properties contained. This metadata should cover these aspects for each property:
Business description: What each property represents for the business. For example, “Business category for the sales order”.
Source system: Establish a mapping with the original property in the operational domain. For instance, “Original Source: ERP | MARA-MTART table BIC/MARACAT property”.
Data characteristics: Specific characteristics of the data, such as enumerations and options. For example, “It is an enumeration with these options: Invoice, Payment, Complaint”.
Data products also need to be discoverable. Producers need to publish them in a shared data catalog and indicate how the data is to be consumed by defining output port assets that serve as interfaces to which the data is exposed.
And data products must be observable. Producers need to deploy a set of monitors that can be shown within the catalog. When a potential consumer discovers a data product in the catalog, they can quickly understand the health of the data contained.
Consumer experience
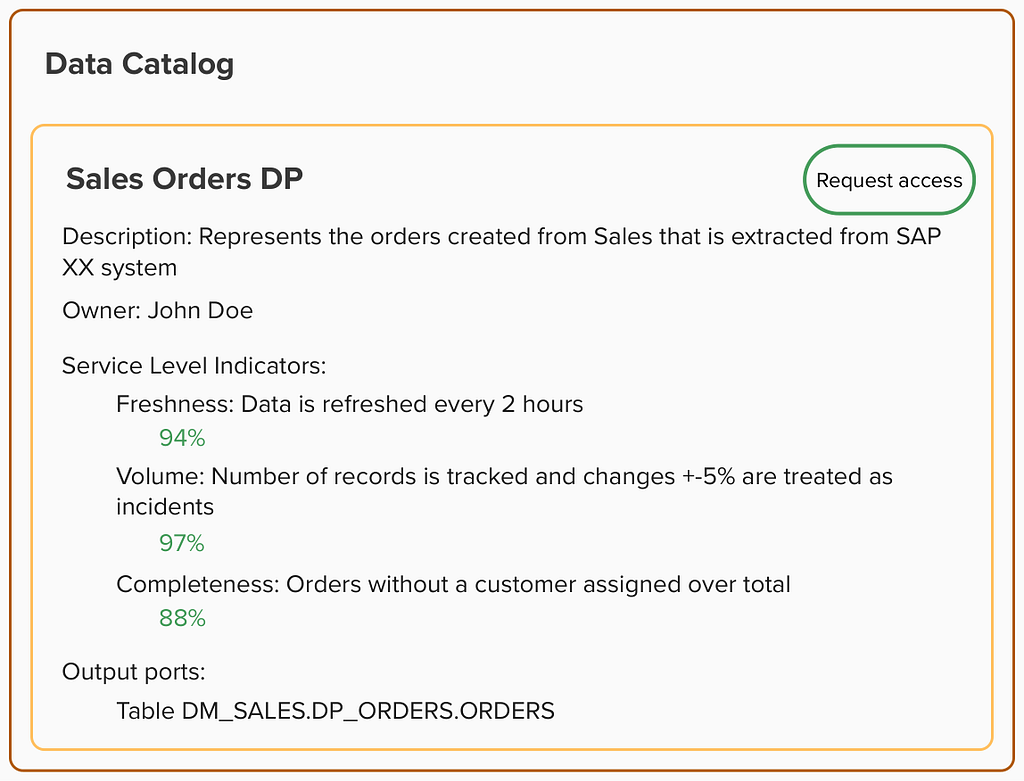
Now, again, imagine being a data engineer tasked with identifying the top-selling products within your company. But this time, imagine that you have access to a data catalog that offers data products that represent the truth of each domain shaping the business. You simply input ‘orders’ into the data product catalog and find the entry published by the Sales data team. And, at a glance, you can assess the quality and freshness of the data and read a detailed description of its contents.
Entry for Sales Orders DP within the Data Catalog example (image by the author)
This upgraded experience eliminates the uncertainties of traditional discovery, allowing you to start working with the data right away. But what’s more, you know who is accountable for the data in case further information is needed. And whenever there is an issue with the Sales orders data product, you will receive a notification so that you can take actions in advance.
Conclusion
We have identified several benefits of enabling operational data through source-aligned data products, especially when they are owned by data producers:
Curated operational data accessibility: In large organisations, source-aligned data products represent a bridge between operational and analytical planes.
Collision reduction with operational work: Operational systems accesses are isolated within source-aligned data products pipelines.
Source of truth: A common data catalog with a list of curated operational business objects reducing duplication and inconsistencies across the organisation.
Clear data ownership: Source-aligned data products should be owned by the domain that generates the operational data to ensure domain knowledge is close to the exposed data.
Based on my own experience, this approach works exceptionally well in scenarios where large organisations struggle with data inconsistencies across different domains and friction when building their own analytics on top of operational data. Data Mesh encourages each domain to build the ‘source of truth’ for the core entities they generate and make them available in a shared catalog allowing other teams to access them and create consistent metrics across the whole organisation. This enables analytical data teams to accelerate their work in generating analytics that drive real business value.
Posted by Dustin Zelle, Software Engineer, Google Research, and Arno Eigenwillig, Software Engineer, CoreML
Objects and their relationships are ubiquitous in the world around us, and relationships can be as important to understanding an object as its own attributes viewed in isolation — take for example transportation networks, production networks, knowledge graphs, or social networks. Discrete mathematics and computer science have a long history of formalizing such networks as graphs, consisting of nodes connected by edges in various irregular ways. Yet most machine learning (ML) algorithms allow only for regular and uniform relations between input objects, such as a grid of pixels, a sequence of words, or no relation at all.
Graph neural networks, or GNNs for short, have emerged as a powerful technique to leverage both the graph’s connectivity (as in the older algorithms DeepWalk and Node2Vec) and the input features on the various nodes and edges. GNNs can make predictions for graphs as a whole (Does this molecule react in a certain way?), for individual nodes (What’s the topic of this document, given its citations?) or for potential edges (Is this product likely to be purchased together with that product?). Apart from making predictions about graphs, GNNs are a powerful tool used to bridge the chasm to more typical neural network use cases. They encode a graph’s discrete, relational information in a continuous way so that it can be included naturally in another deep learning system.
We are excited to announce the release of TensorFlow GNN 1.0 (TF-GNN), a production-tested library for building GNNs at large scales. It supports both modeling and training in TensorFlow as well as the extraction of input graphs from huge data stores. TF-GNN is built from the ground up for heterogeneous graphs, where types of objects and relations are represented by distinct sets of nodes and edges. Real-world objects and their relations occur in distinct types, and TF-GNN’s heterogeneous focus makes it natural to represent them.
Inside TensorFlow, such graphs are represented by objects of type tfgnn.GraphTensor. This is a composite tensor type (a collection of tensors in one Python class) accepted as a first-class citizen in tf.data.Dataset, tf.function, etc. It stores both the graph structure and its features attached to nodes, edges and the graph as a whole. Trainable transformations of GraphTensors can be defined as Layers objects in the high-level Keras API, or directly using the tfgnn.GraphTensor primitive.
GNNs: Making predictions for an object in context
For illustration, let’s look at one typical application of TF-GNN: predicting a property of a certain type of node in a graph defined by cross-referencing tables of a huge database. For example, a citation database of Computer Science (CS) arXiv papers with one-to-many cites and many-to-one cited relationships where we would like to predict the subject area of each paper.
Like most neural networks, a GNN is trained on a dataset of many labeled examples (~millions), but each training step consists only of a much smaller batch of training examples (say, hundreds). To scale to millions, the GNN gets trained on a stream of reasonably small subgraphs from the underlying graph. Each subgraph contains enough of the original data to compute the GNN result for the labeled node at its center and train the model. This process — typically referred to as subgraph sampling — is extremely consequential for GNN training. Most existing tooling accomplishes sampling in a batch way, producing static subgraphs for training. TF-GNN provides tooling to improve on this by sampling dynamically and interactively.
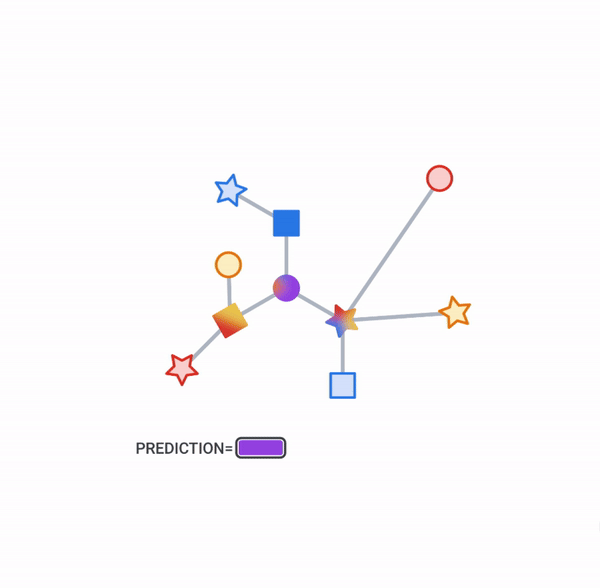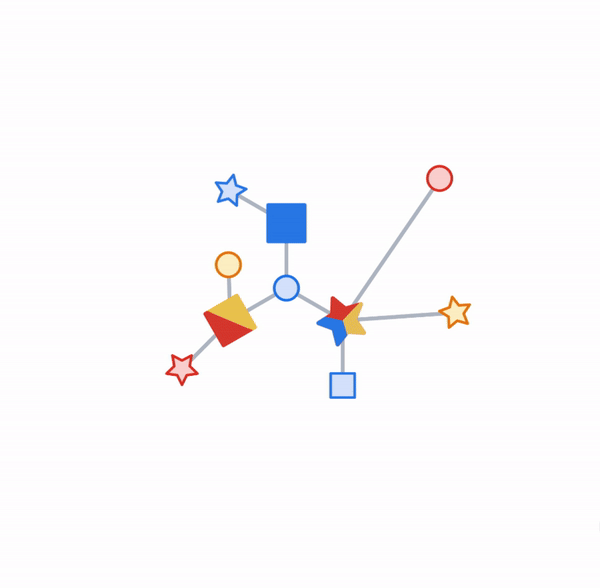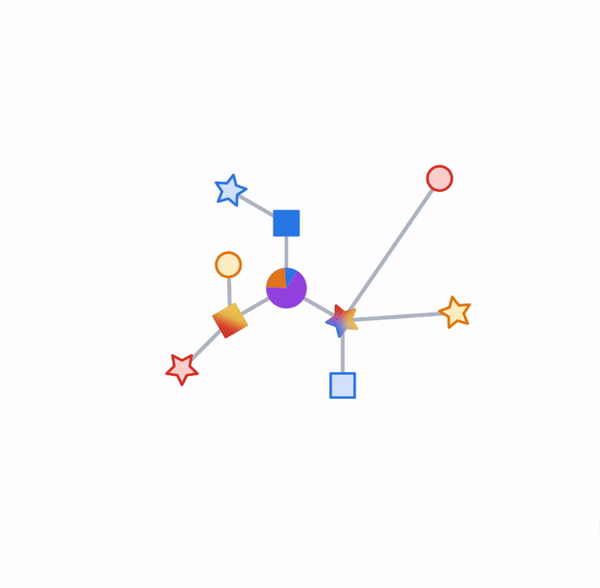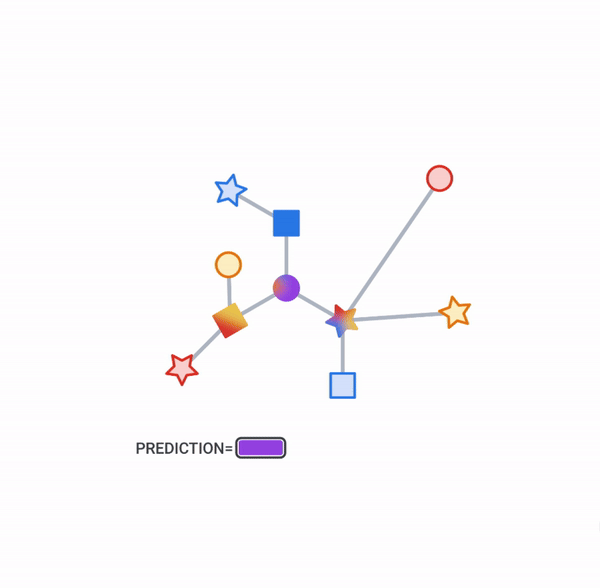
Pictured, the process of subgraph sampling where small, tractable subgraphs are sampled from a larger graph to create input examples for GNN training.
TF-GNN 1.0 debuts a flexible Python API to configure dynamic or batch subgraph sampling at all relevant scales: interactively in a Colab notebook (like this one), for efficient sampling of a small dataset stored in the main memory of a single training host, or distributed by Apache Beam for huge datasets stored on a network filesystem (up to hundreds of millions of nodes and billions of edges). For details, please refer to our user guides for in-memory and beam-based sampling, respectively.
On those same sampled subgraphs, the GNN’s task is to compute a hidden (or latent) state at the root node; the hidden state aggregates and encodes the relevant information of the root node’s neighborhood. One classical approach is message-passing neural networks. In each round of message passing, nodes receive messages from their neighbors along incoming edges and update their own hidden state from them. After n rounds, the hidden state of the root node reflects the aggregate information from all nodes within n edges (pictured below for n = 2). The messages and the new hidden states are computed by hidden layers of the neural network. In a heterogeneous graph, it often makes sense to use separately trained hidden layers for the different types of nodes and edges
Pictured, a simple message-passing neural network where, at each step, the node state is propagated from outer to inner nodes where it is pooled to compute new node states. Once the root node is reached, a final prediction can be made.
The training setup is completed by placing an output layer on top of the GNN’s hidden state for the labeled nodes, computing the loss (to measure the prediction error), and updating model weights by backpropagation, as usual in any neural network training.
Beyond supervised training (i.e., minimizing a loss defined by labels), GNNs can also be trained in an unsupervised way (i.e., without labels). This lets us compute a continuous representation (or embedding) of the discrete graph structure of nodes and their features. These representations are then typically utilized in other ML systems. In this way, the discrete, relational information encoded by a graph can be included in more typical neural network use cases. TF-GNN supports a fine-grained specification of unsupervised objectives for heterogeneous graphs.
Building GNN architectures
The TF-GNN library supports building and training GNNs at various levels of abstraction.
At the highest level, users can take any of the predefined models bundled with the library that are expressed in Keras layers. Besides a small collection of models from the research literature, TF-GNN comes with a highly configurable model template that provides a curated selection of modeling choices that we have found to provide strong baselines on many of our in-house problems. The templates implement GNN layers; users need only to initialize the Keras layers.
At the lowest level, users can write a GNN model from scratch in terms of primitives for passing data around the graph, such as broadcasting data from a node to all its outgoing edges or pooling data into a node from all its incoming edges (e.g., computing the sum of incoming messages). TF-GNN’s graph data model treats nodes, edges and whole input graphs equally when it comes to features or hidden states, making it straightforward to express not only node-centric models like the MPNN discussed above but also more general forms of GraphNets. This can, but need not, be done with Keras as a modeling framework on the top of core TensorFlow. For more details, and intermediate levels of modeling, see the TF-GNN user guide and model collection.
Training orchestration
While advanced users are free to do custom model training, the TF-GNN Runner also provides a succinct way to orchestrate the training of Keras models in the common cases. A simple invocation may look like this:
The Runner provides ready-to-use solutions for ML pains like distributed training and tfgnn.GraphTensor padding for fixed shapes on Cloud TPUs. Beyond training on a single task (as shown above), it supports joint training on multiple (two or more) tasks in concert. For example, unsupervised tasks can be mixed with supervised ones to inform a final continuous representation (or embedding) with application specific inductive biases. Callers only need substitute the task argument with a mapping of tasks:
Additionally, the TF-GNN Runner also includes an implementation of integrated gradients for use in model attribution. Integrated gradients output is a GraphTensor with the same connectivity as the observed GraphTensor but its features replaced with gradient values where larger values contribute more than smaller values in the GNN prediction. Users can inspect gradient values to see which features their GNN uses the most.
Conclusion
In short, we hope TF-GNN will be useful to advance the application of GNNs in TensorFlow at scale and fuel further innovation in the field. If you’re curious to find out more, please try our Colab demo with the popular OGBN-MAG benchmark (in your browser, no installation required), browse the rest of our user guides and Colabs, or take a look at our paper.
Acknowledgements
The TF-GNN release 1.0 was developed by a collaboration between Google Research: Sami Abu-El-Haija, Neslihan Bulut, Bahar Fatemi, Johannes Gasteiger, Pedro Gonnet, Jonathan Halcrow, Liangze Jiang, Silvio Lattanzi, Brandon Mayer, Vahab Mirrokni, Bryan Perozzi, Anton Tsitsulin, Dustin Zelle, Google Core ML: Arno Eigenwillig, Oleksandr Ferludin, Parth Kothari, Mihir Paradkar, Jan Pfeifer, Rachael Tamakloe, and Google DeepMind:Alvaro Sanchez-Gonzalez and Lisa Wang.
Do your employees wait for hours on the telephone to open an IT ticket? Do they wait for an agent to triage an issue, which sometimes only requires restarting the computer? Providing excellent IT support is crucial for any organization, but legacy systems have relied heavily on human agents being available to intake reports and […]
In this post, we show how to develop an ML-driven solution using Amazon SageMaker for detecting adverse events using the publicly available Adverse Drug Reaction Dataset on Hugging Face. In this solution, we fine-tune a variety of models on Hugging Face that were pre-trained on medical data and use the BioBERT model, which was pre-trained on the Pubmed dataset and performs the best out of those tried.
Enterprise IT managers will be able to better control the Apple Vision Pro used by its employees, with visionOS 1.1 adding mobile device management to the headset.
Apple Vision Pro [Apple]
The Apple Vision Pro has the potential to be a multi-tasking powerhouse for workers at companies, but it introduces new challenges for IT departments to maintain and lock down. To help that, Apple’s introducing mobile device management.
The first beta of visionOS 1.1, now available to test brings the Apple Vision Pro to the Apple Device Management system, allowing IT teams to manage the headset in a similar way to the iPhone, iPad and Mac. This includes simplifying activation of the headset when onboarding employees, reportsTechCrunch.
Apple is on the second round of developer betas, with a fresh tvOS 17.4 build now available for testing.
Developers participating in the test program can acquire the latest build by visiting the Apple Developer Center, or by updating any Apple TV set-top boxes already running the beta. Public beta builds generally surface shortly after the developer counterparts, and the public can sign up to test them via the Apple Beta Software Program when they become available.
The second tvOS 17.4 developer beta takes place after the first, which arrived on January 25.
The second beta build is number 21L5206f, replacing the first build, number 21L5195h.
Following the release of the Apple Vision Pro, Apple has brought out its first developer beta for its operating system, visionOS 1.1.
visionOS
Before release, the developer betas for visionOS could be downloaded to the developer’s Mac, which also acts as the development platform for visionOS apps.
The beta can be installed directly from the Apple Vision Pro, by opening Settings then General, followed by Beta Updates and selecting visionOS Developer Beta. Users need a registered Apple developer account to access the beta.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.