X has allowed dozens of sanctioned individuals and groups to pay for its premium service, according to a new report from the Tech Transparency Project (TTP). The report raises questions about whether X is running afoul of US sanctions.
The report found 28 verified accounts belonging to people and groups the US government considers to be a national security threat. The group includes two leaders of Hezbollah, accounts associated with Houthis in Yemen and state-run media accounts from Iran and Russia. Of those, 18 of the accounts were verified after X began charging for verification last spring.
“The fact that X requires users to pay a monthly or annual fee for premium service suggests that X is engaging in financial transactions with these accounts, a potential violation of U.S. sanctions,” the report says. As the TTP points out, X’s own policies state that sanctioned individuals are prohibited from paying for premium services. Some of the accounts identified by the TTP also had ads in their replies, according to the group, “raising the possibility that they could be profiting from X’s revenue-sharing program.”
Changing up Twitter’s verification policy was one of the most significant changes implemented by Elon Musk after he took over the company. Under the new rules, anyone can pay for a blue checkmark if they subscribe to X Premium. X doesn’t require users to submit identification, and the company has at times scrambled to shut down impersonators.
X also offers gold checkmarks to advertisers as part of its “verified organizations” tier, which starts at $200 a month. The TTP report found that accounts belonging to Iran’s Press TV and Russia’s Tinkoff Bank — both sanctioned entities — had gold checks. X has also given away gold checks to at least 10,000 companies. As the report points out, even giving away the gold badge to sanctioned groups could violate US government policies.
X didn’t immediately respond to a request for comment, but it appears that the company has removed verification from some of the accounts named in the TTP’s report. “X, formerly known as Twitter, has removed the blue check and suspended the paid subscriptions of several Iranian outlets,” Press TV tweeted from its account, which still has a gold check. The Hezbollah leaders’ accounts are also no longer verified.
This article originally appeared on Engadget at https://www.engadget.com/x-let-terrorist-groups-pay-for-verification-report-says-201254824.html?src=rss
In an absolutely bananas turn of events, a typo in an earnings report caused Lyft shares to skyrocket nearly 70 percent after Tuesday’s closing stock market bell, as reported by CBS. There was an extra zero in the report that suggested a five percent margin expansion in 2024, instead of a .5 percent margin. This sent investors into a tizzy, as the company has long struggled to turn a profit.
The mistake was even present in Lyft’s slide deck, which was part of that earnings report, and an accompanying press release. The company quickly corrected the mistake, calling it a clerical error, but the stock surge had already begun. Lyft CFO Erin Brewer addressed the issue in an earnings call yesterday evening which caused the stocks to reverse course. It’s worth noting that the earnings report was still good news for Lyft, even without that mistake, so the stock price experienced a more stable increase of around 35 percent.
Now, onto the blame game. Lyft CEO David Risher appeared on CNBC’sSquawk Box to take responsibility for the mistake, saying “look, it was a bad error, and that’s on me.” Risher went on to note that it was “super frustrating” for everyone on the team and said that he could see a fellow employee’s “jaw drop” when discovering the issue.
The good news? Even with that adjustment, this is Lyft’s best day since the company’s initial IPO offering back in 2019. Yesterday’s earnings report indicated $1.22 billion in revenue for the quarter, an increase of four percent from last year. Bookings increased 17 percent for the quarter, accounting for $3.7 billion. Risher called it a “great quarter.”
A misplaced zero on a spreadsheet isn’t the ridesharing giant’s only concern. Thousands of Lyft and Uber drivers are going on strike today to demand better pay and safer working conditions. The striking workers are primarily clustered around ten major US airports, though it’s only planned to last for a few hours.
This article originally appeared on Engadget at https://www.engadget.com/an-earnings-typo-sent-lyfts-stock-price-into-the-stratosphere-193904095.html?src=rss
A simple and effective framework to build confidence in your data presentations
“If you can’t explain it simply, you don’t understand it well enough. “ — Albert Einstein
If you are a Data Person, it’s very much possible that you spend a substantial amount of time in your career going through various phases of lowered confidence levels in creating effective data presentations. We all get trained extensively in college, grad schools and boot camps on the various steps required to perform Data mining and gather insights from complex datasets. By the book, we know that you start with the Data Cleaning and preparation, then move on Data exploration and eventually to mining and finding patterns. But often times when we’re thrown into the real world with very real business problems we end up spending hours doubting our methodologies and sometimes the entire premise. Or even worse, get stuck in hours and hours of Analysis Paralysis. I’m sharing a simple framework to tackle this state of mind.
Note : Throughout the article, instead of interchangeably using the terms Data Analyst, Data Scientist, Data specialist, Data Subject Matter Expert etc. I’ll be using the term “Data Person”. No matter what our titles are, after all we’re curious humans with access to rich information trying to create impact with the data resources available to us.
Image by Author
Frame the Business Questions in your own terms :
As a Data person, you will learn many data manipulation and scripting languages throughout your career. But understanding business questions and being able to interpret them in plain English is a skill that is much more essential. A Data person has the unique capability to dissect the problem statement and map them into data points available, make the connections and find answers. Here’s an example :
Question from stakeholder :”I don’t know why my customers aren’t converting more to subscription plans anymore since last quarter.”
Data person’s interpretation : “I’m looking for a downward trend in number of customers opting for subscription plans compared to one time purchases for the past three months.”
Data person’s Analysis Plan: “I can look into the mix of new vs. returning customers for the past few months and see what acquisition channels they’re coming from. I should also look if there are any drop offs in the subscription flow in our website, page by page. I should also check what regions stand out in the drop off rate.”
2. Identify the Stakeholders
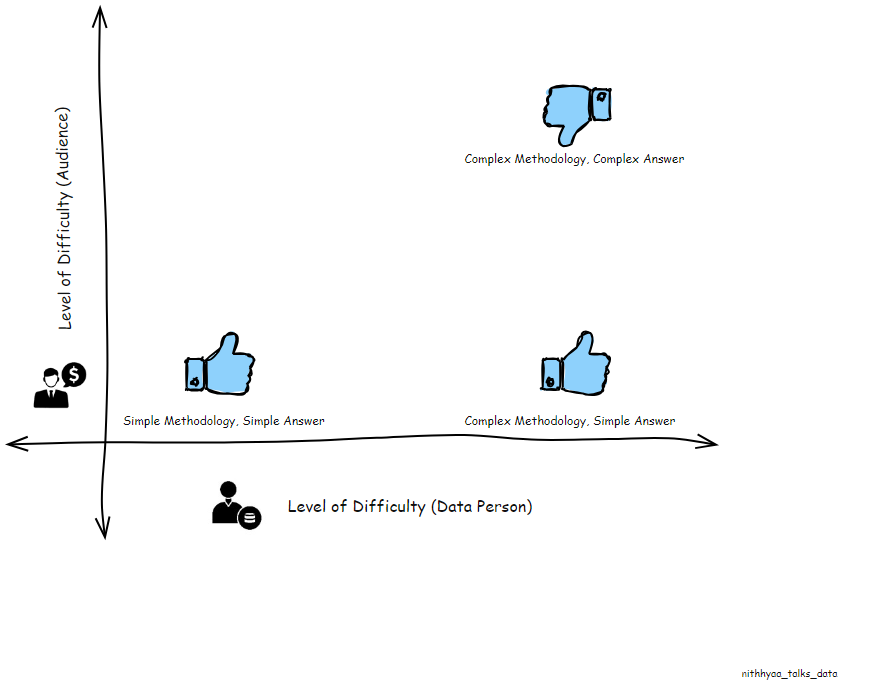
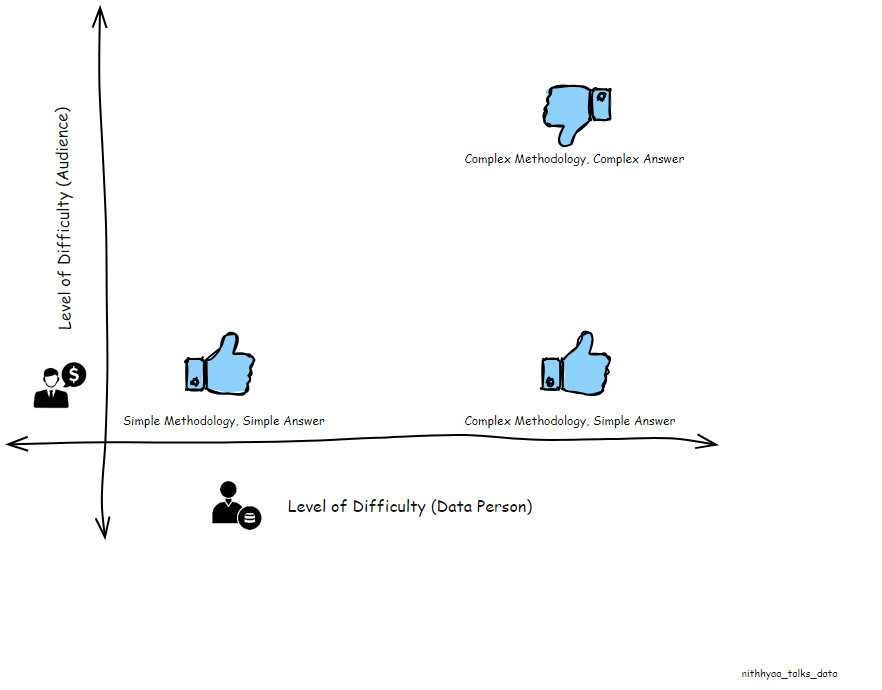
Your main stakeholder is the person with the business question, but depending on what the data unveils there might be several other stakeholder groups that need to be included in your presentation audience. The Data literacy levels of your audience also dictates the language you use in your presentations. More importantly, you’d want to make sure that this group is willing to listen to your recommendations, so your data work can create the organization level impact it deserves.
3.Prepare your slides before you dive into the data
This seems counterintuitive and out of order, but preparing your slides with placeholders will ensure that you have a tentative list of the required data points ready before you venture out looking for them in your organization’s data sphere. This will also keep you focused on the problem statement without getting distracted by other interesting data points you discover. If something interesting comes up that doesn’t really align the with the problem statement, you can always save them for the appendix. Personally, I found this mindset shift game changing. Doing this step prior to Data exploration ensures that:
You have a coherent data story in place that’s aligned with the problem statement can be edited later based on your findings from the analysis.
You save yourself from getting into too many tangents and getting distracted by new and shiny data things. ( Yes, rich and clean datasets are a privilege. But it can lead to time consuming data rabbit holes when it prevents us from being focused on the purpose. )
A more in depth view of this step is being illustrated in the latter half of the article.
4.Resist the urge to include all the details from the Analysis and Methodology
This is the hardest step of all in my opinion. No matter how straightforward, the question is, the Data person spends a substantial amount of time in Data prep and exploration, before narrowing down the answer to a specific set of data points. It might have taken you several days or weeks to get a clean dataset prepared, your exploration steps may have involved several failed hypotheses and assumptions before landing on the answer. New and more interesting correlations may have emerged, but resist the urge to include it in your presentation if it doesn’t add any useful details to the data story you’re presenting.
5.Populate the slides
If you’ve gone through all the previous steps, it should be very easy to just the plug the numbers and findings in your slides.
I like to arrange them in the order of Problem, Problem’s Impact, Findings, Recommendations and Next steps. This ensures that your data story is easy to follow and speaks for itself even when you’re not around to narrate and walkthrough the whole deck.
The order may look different in other use cases such as routine performance updates or retrospective summaries. But for a typical request requiring data insights to aid decision making, this order is a great starting point. The main thing to ensure in this step is to have accurate and relevant data points that clearly supports your story. Apart from that, I have a few tips to help wrap up your Analysis solution neatly. These little details go a long way in presentation delivery and helping the audience remember the key insights.
Clearly indicate if the key data point being shared is a good sign or bad sign by using arrows and colors. (Example : A low bounce rate is a good thing, but a low conversion rate is a bad sign.)
Always add context for any number (data point) shared in the slide by including benchmarking details or trend analyses. ( Example : Conversion rate for this month was 12%, this is in line with other SKUs in the same product line and higher compared to the average conversion rate for the same months in the past three years.)
Tie back the insights to the some part of the original business question in each slide.
Including details such as sample size, analysis time frames and important annotations in the footnote will help build trust and credibility.
In addition to all of this, finding ways to create your own style of data story telling will help your work stand out among all other templated analysis deliveries.
You can’t always watermark your presentations you produce, but your story telling style along with the credibility you build using the techniques above will help people associate you with data excellence.
6.Document learnings
The easy and effective way to get better is by failing and documenting the learnings. As you get more opportunities to present your data work, don’t forget to document what worked and what did not. Soon enough, you’ll have a little inventory of types of visualizations, analyses and recommendations to include based on your audience and stakeholder group. The bigger this list gets, the more impactful your data presentations will become.
During my first few weeks as an Analytics intern, I felt very much out of place since most of the acquaintances I made in my cohort during the orientation chose a rotation track completely unrelated to data science. This was back in 2012, so I didn’t know enough to label my feelings as “Imposter syndrome”, but I started a little section on One Note to document all instances where my analyses were well received and the ones where I had to spend a lot of time on back and forth emails to explain what I meant in some of the slides. This exercise helped me understand that:
If you’re not well aligned with the organizational priorities the stuff that you ( the data person) gets excited about are probably not the same stuff the audience get excited about.
(Almost a decade ago, I spent several weeks tracking down a data source that will gave me the ability to connect records from two different product lines and perform Look alike modeling. I was way too excited about it and spent several slides talking about how great that is and dedicated time to analyze it. But ultimately, since it did not have a direct tie to the company’s priorities for that quarter, none of my audience were able to share my level of enthusiasm. I now want to wrap a blanket on my past Junior Analyst self and tell them to zoom out and pay attention to the business briefings. )
The audience for your Analyses presentations are not just the people in the meeting, it’s all the people to whom your presentation will get forwarded to in the organization. A data backed presentation with clear and concise observations and recommendation speaks for itself and has the potential to reach more decision makers.
These two learnings I documented during my beginner Analyst days has stayed with me for over a decade. What started as a simple habit has now grown into a big list of personal rules tailored towards specific audience in my organization which helps me make impactful presentations.
Let’s put this framework into action with an Example Scenario
Let’s look at a hypothetical business question and how the analysis solution-ing process would look like with and without these tactics.
Business Question : The Desktop and Mobile web experiences for an ecommerce office supplies store are disparate. (Let’s assume that this was the late 2000s and responsive web design wasn’t a thing. ) Your department leadership is wondering which redesign effort they should prioritize first and if that decision will affect revenue metrics.
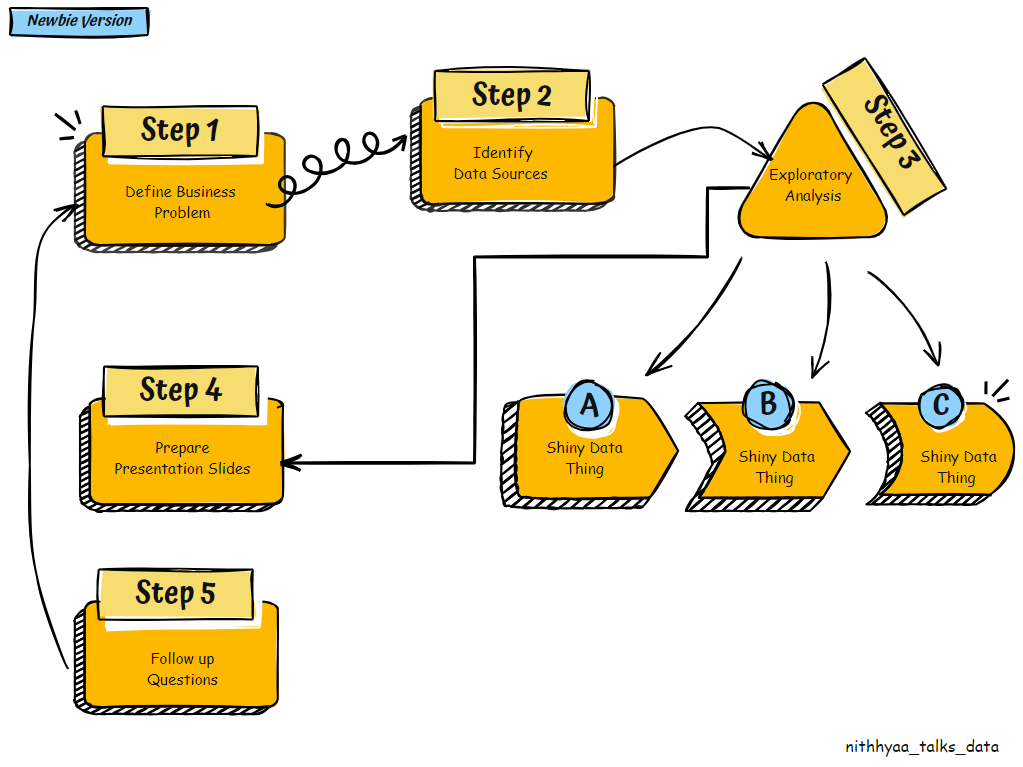
Newbie Data Person’s Version :
Data person picks up the question.
Scours the company data warehouse to identify data sources that contain details about each website visit. They have found a rich dataset which has about 30 attributes.
They spend time exploring the dataset, and they find several new shiny data attributes.
Shiny thing 1: Mobile Device brands- Gets curious and looks for purchase patterns by Mobile Device brand. Secretly judges them. (No eye rolls, we’ve all done it.)
Shiny thing 2: Screen resolution — Gets curious to find out if User Engagement metrics are affected screen resolution.
Shiny thing 3: Mobile Device Brand — Gets curious to find out if “time to purchase” is lower for certain device brands.
Shiny thing 4: Demographic data — Gets curious to see purchase patterns through the lens of seven different user attributes.
4.Prepares the presentation slides : Proceeds to include all their learnings and analysis methodologies in the slides.
5.Business has more follow up questions since clear recommendations were not provided. Start again at step 1 for each follow up question.
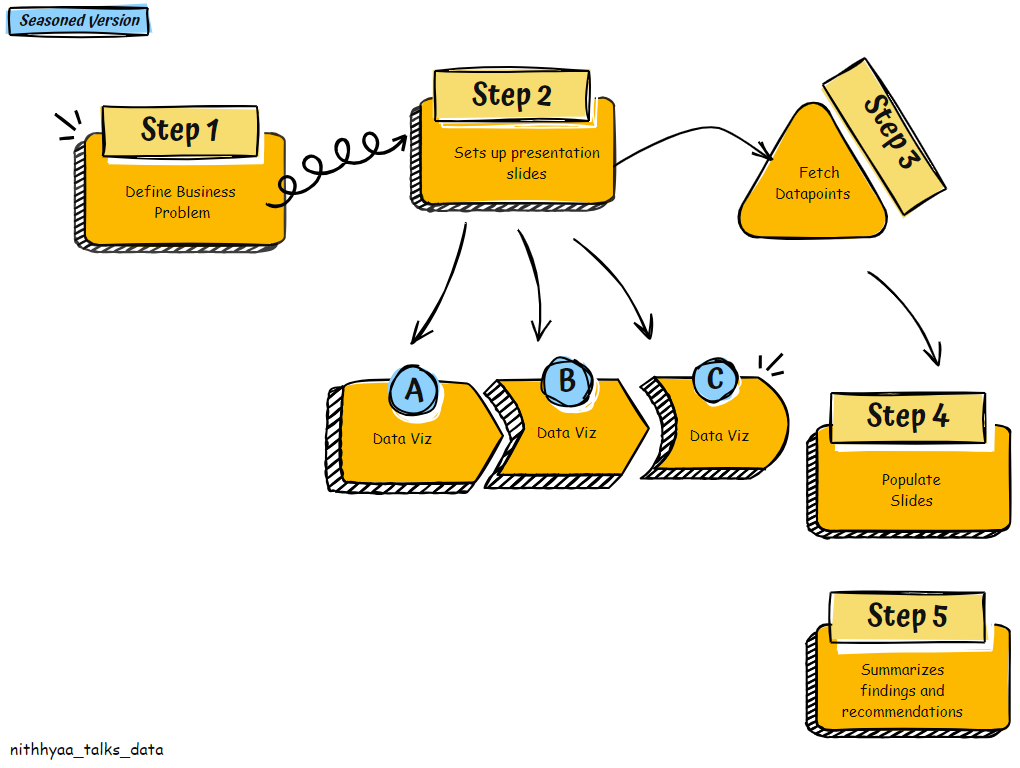
Seasoned Data Person’s Version:
Data person picks up the question.
Sets up their presentation slides in the following order
Slide 1 : Business Question , Decision being influenced, Stakeholders
Slide 2: Data Visualizations representing the share of Visits by Desktop vs. Mobile and share of Conversions by Desktop vs. Mobile.
Slide 3 : Data Visualizations representing the share of New Customers vs. Returning Customers Overall and by each Device Type.
Slide 4: Data Visualizations representing the Device used on subsequent visits by the same user.
Slide 5: Place holders for Learnings and Recommendations
3.Identifies data sources and necessary attributes to populate the slides.
4. Populates the slides :Based on observations from slides 1–4, Data person illustrates that Returning users make up the major portion of their customer base. >70% of Returning orders are placed in a Desktop. While first orders are placed in Mobile devices, reorder requests are often processed via Desktop. So keeping an outdated Desktop experience would affect a major share of loyal customers. This helps the leadership conclude that they need to prioritize Desktop redesign efforts.
Conclusion :
In summary, Effective Data story telling is all about making difficult things look easy, so your data skills can empower decision making across the organization despite varying Data literacy levels.
About the Author :
Nithhyaa Ramamoorthy is a Data Subject matter Expert with over 12 years’ worth of experience in Analytics and Big Data, specifically in the intersection of healthcare and consumer behavior. She holds a Master’s Degree in Information Sciences and more recently a CSPO along with several other certifications. She is passionate about leveraging her analytics skills to drive business decisions that create inclusive and equitable digital products rooted in empathy. She currently serves as an Analytics Lead at the Mayo Clinic — Center for Digital Health.
Posted by Nishant Jain, Pre-doctoral Researcher, and Pradeep Shenoy, Research Scientist, Google Research
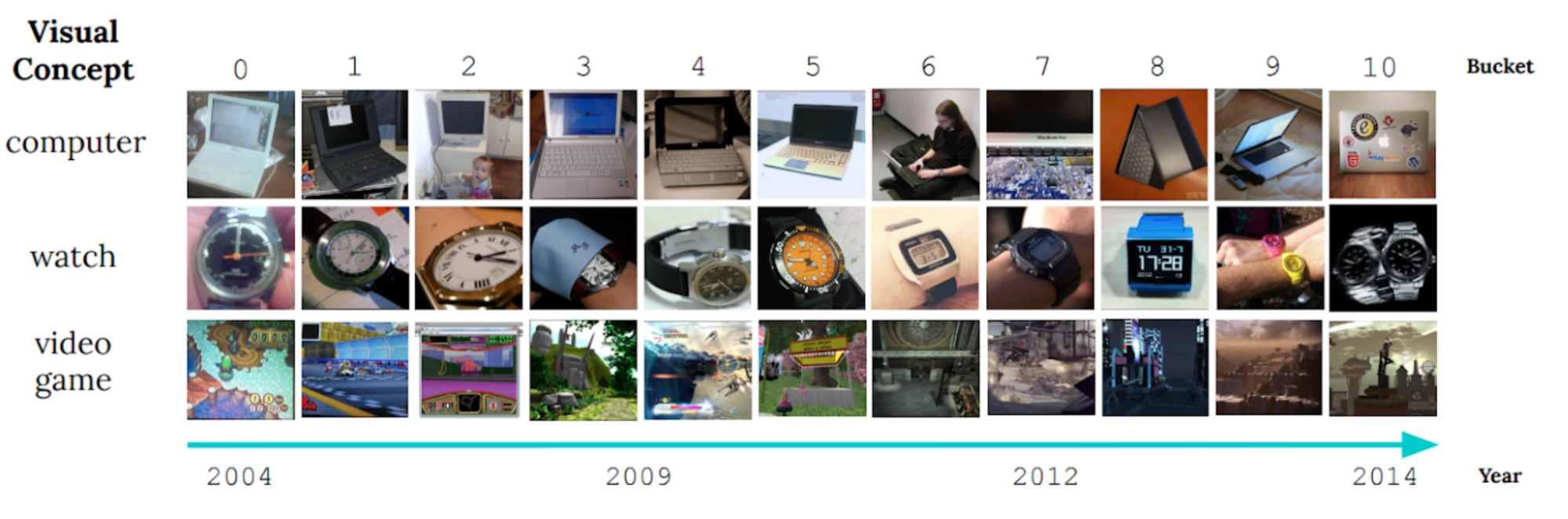
The constantly changing nature of the world around us poses a significant challenge for the development of AI models. Often, models are trained on longitudinal data with the hope that the training data used will accurately represent inputs the model may receive in the future. More generally, the default assumption that all training data are equally relevant often breaks in practice. For example, the figure below shows images from the CLEAR nonstationary learning benchmark, and it illustrates how visual features of objects evolve significantly over a 10 year span (a phenomenon we refer to as slow concept drift), posing a challenge for object categorization models.
Sample images from the CLEAR benchmark. (Adapted from Lin et al.)
Alternative approaches, such as online and continual learning, repeatedly update a model with small amounts of recent data in order to keep it current. This implicitly prioritizes recent data, as the learnings from past data are gradually erased by subsequent updates. However in the real world, different kinds of information lose relevance at different rates, so there are two key issues: 1) By design they focus exclusively on the most recent data and lose any signal from older data that is erased. 2) Contributions from data instances decay uniformly over time irrespective of the contents of the data.
In our recent work, “Instance-Conditional Timescales of Decay for Non-Stationary Learning”, we propose to assign each instance an importance score during training in order to maximize model performance on future data. To accomplish this, we employ an auxiliary model that produces these scores using the training instance as well as its age. This model is jointly learned with the primary model. We address both the above challenges and achieve significant gains over other robust learning methods on a range of benchmark datasets for nonstationary learning. For instance, on a recent large-scale benchmark for nonstationary learning (~39M photos over a 10 year period), we show up to 15% relative accuracy gains through learned reweighting of training data.
The challenge of concept drift for supervised learning
To gain quantitative insight into slow concept drift, we built classifiers on a recent photo categorization task, comprising roughly 39M photographs sourced from social media websites over a 10 year period. We compared offline training, which iterated over all the training data multiple times in random order, and continual training, which iterated multiple times over each month of data in sequential (temporal) order. We measured model accuracy both during the training period and during a subsequent period where both models were frozen, i.e., not updated further on new data (shown below). At the end of the training period (left panel, x-axis = 0), both approaches have seen the same amount of data, but show a large performance gap. This is due to catastrophic forgetting, a problem in continual learning where a model’s knowledge of data from early on in the training sequence is diminished in an uncontrolled manner. On the other hand, forgetting has its advantages — over the test period (shown on the right), the continual trained model degrades much less rapidly than the offline model because it is less dependent on older data. The decay of both models’ accuracy in the test period is confirmation that the data is indeed evolving over time, and both models become increasingly less relevant.
Comparing offline and continually trained models on the photo classification task.
Time-sensitive reweighting of training data
We design a method combining the benefits of offline learning (the flexibility of effectively reusing all available data) and continual learning (the ability to downplay older data) to address slow concept drift. We build upon offline learning, then add careful control over the influence of past data and an optimization objective, both designed to reduce model decay in the future.
Suppose we wish to train a model, M,given some training data collected over time. We propose to also train a helper model that assigns a weight to each point based on its contents and age. This weight scales the contribution from that data point in the training objective for M. The objective of the weights is to improve the performance of M on future data.
In our work, we describe how the helper model can be meta-learned, i.e., learned alongside M in a manner that helps the learning of the model M itself. A key design choice of the helper model is that we separated out instance- and age-related contributions in a factored manner. Specifically, we set the weight by combining contributions from multiple different fixed timescales of decay, and learn an approximate “assignment” of a given instance to its most suited timescales. We find in our experiments that this form of the helper model outperforms many other alternatives we considered, ranging from unconstrained joint functions to a single timescale of decay (exponential or linear), due to its combination of simplicity and expressivity. Full details may be found in the paper.
Instance weight scoring
The top figure below shows that our learned helper model indeed up-weights more modern-looking objects in the CLEAR object recognition challenge; older-looking objects are correspondingly down-weighted. On closer examination (bottom figure below, gradient-based feature importance assessment), we see that the helper model focuses on the primary object within the image, as opposed to, e.g., background features that may spuriously be correlated with instance age.
Sample images from the CLEAR benchmark (camera & computer categories) assigned the highest and lowest weights respectively by our helper model.
Feature importance analysis of our helper model on sample images from the CLEAR benchmark.
Results
Gains on large-scale data
We first study the large-scale photo categorization task (PCAT) on the YFCC100M dataset discussed earlier, using the first five years of data for training and the next five years as test data. Our method (shown in red below) improves substantially over the no-reweighting baseline (black) as well as many other robust learning techniques. Interestingly, our method deliberately trades off accuracy on the distant past (training data unlikely to reoccur in the future) in exchange for marked improvements in the test period. Also, as desired, our method degrades less than other baselines in the test period.
Comparison of our method and relevant baselines on the PCAT dataset.
Broad applicability
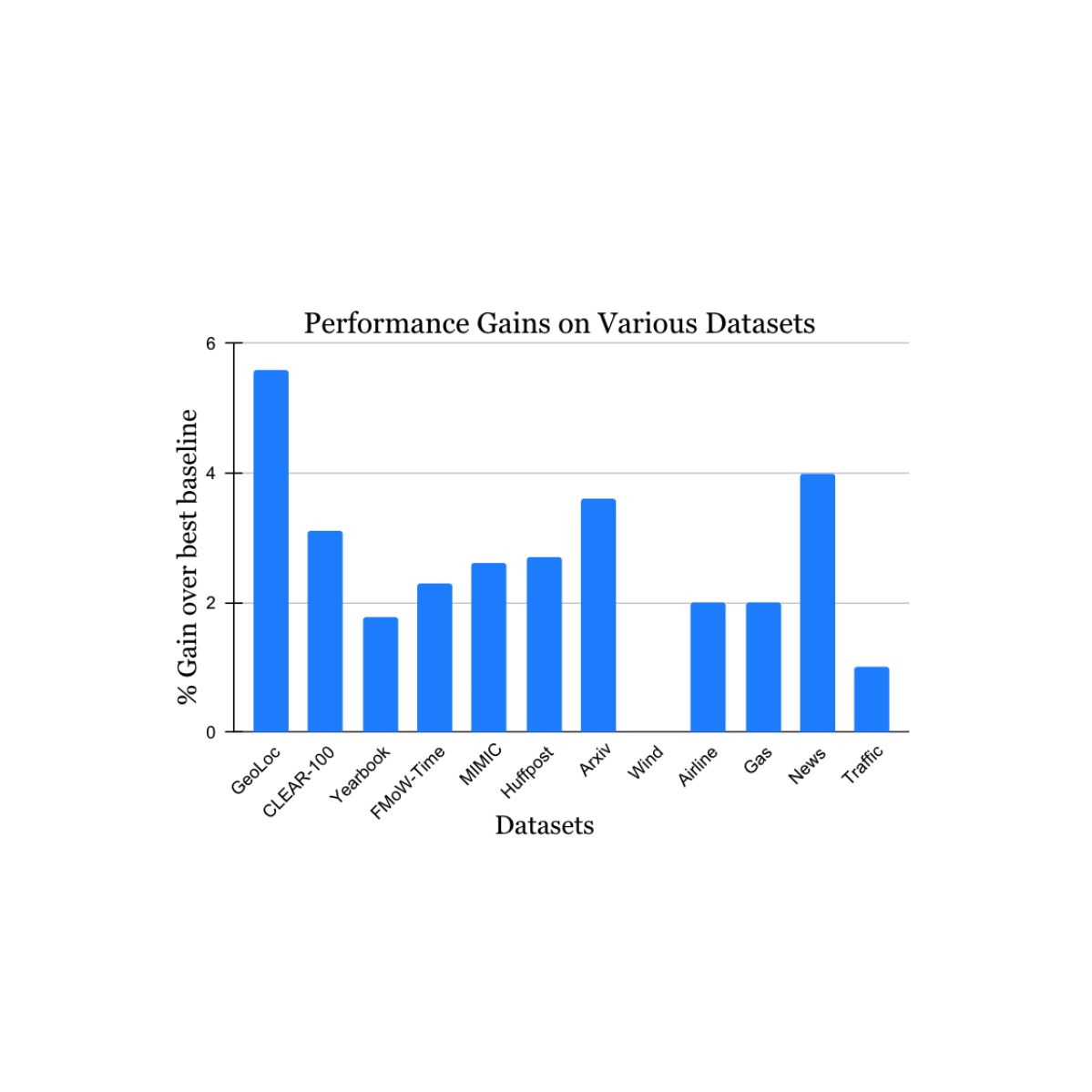
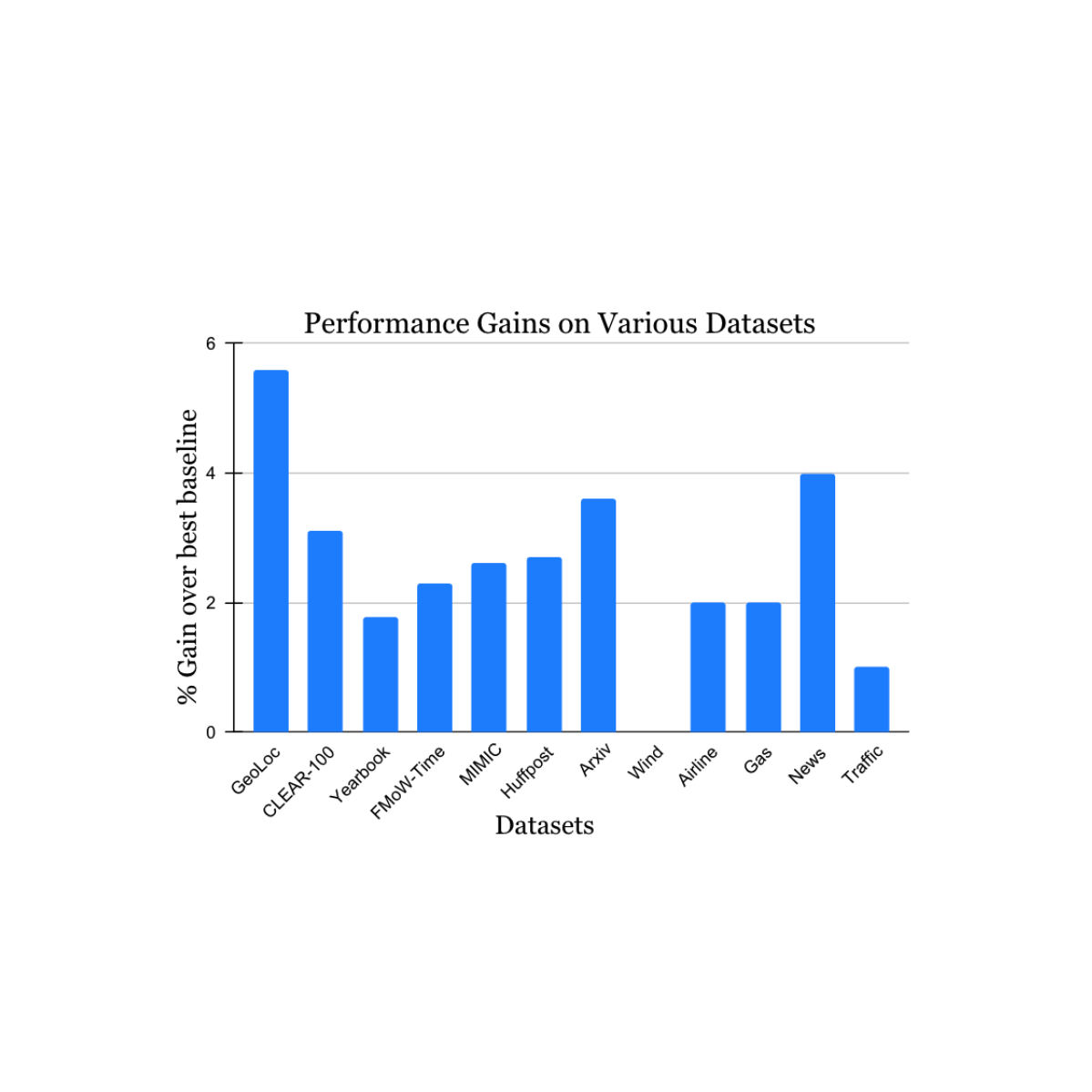
We validated our findings on a wide range of nonstationary learning challenge datasets sourced from the academic literature (see 1, 2, 3, 4 for details) that spans data sources and modalities (photos, satellite images, social media text, medical records, sensor readings, tabular data) and sizes (ranging from 10k to 39M instances). We report significant gains in the test period when compared to the nearest published benchmark method for each dataset (shown below). Note that the previous best-known method may be different for each dataset. These results showcase the broad applicability of our approach.
Performance gain of our method on a variety of tasks studying natural concept drift. Our reported gains are over the previous best-known method for each dataset.
Extensions to continual learning
Finally, we consider an interesting extension of our work. The work above described how offline learning can be extended to handle concept drift using ideas inspired by continual learning. However, sometimes offline learning is infeasible — for example, if the amount of training data available is too large to maintain or process. We adapted our approach to continual learning in a straightforward manner by applying temporal reweighting within the context of each bucket of data being used to sequentially update the model. This proposal still retains some limitations of continual learning, e.g., model updates are performed only on most-recent data, and all optimization decisions (including our reweighting) are only made over that data. Nevertheless, our approach consistently beats regular continual learning as well as a wide range of other continual learning algorithms on the photo categorization benchmark (see below). Since our approach is complementary to the ideas in many baselines compared here, we anticipate even larger gains when combined with them.
Results of our method adapted to continual learning, compared to the latest baselines.
Conclusion
We addressed the challenge of data drift in learning by combining the strengths of previous approaches — offline learning with its effective reuse of data, and continual learning with its emphasis on more recent data. We hope that our work helps improve model robustness to concept drift in practice, and generates increased interest and new ideas in addressing the ubiquitous problem of slow concept drift.
Acknowledgements
We thank Mike Mozer for many interesting discussions in the early phase of this work, as well as very helpful advice and feedback during its development.
It’s Valentine’s Day and digital romances are blossoming. Across the world, lonely hearts are opening up to virtual lovers. But their secrets aren’t as safe as they may seem. According to a new analysis by Mozilla, AI girlfriends harvest reams of private and intimate data. This information can then be shared with marketers, advertisers, and data brokers. It’s also vulnerable to leaks. The research team investigated 11 popular romantic chatbots, including Replika, Chai, and Eva. Around 100 million people have downloaded these apps on Google Play alone. Using AI, the chatbots simulate interactions with virtual girlfriends, soulmates, or friends. To…
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.