Clickbait videos have always been annoying, but there are times when they can be downright harmful. YouTube has vowed to strengthen its enforcement efforts when it comes to dealing with “egregious clickbait” on its website, particularly those that cover — or pretend to cover — breaking news and current events. The website describes egregious clickbait as “videos where the title or thumbnail promises viewers something that the video doesn’t deliver.”
YouTube says these videos leave viewers “feeling tricked, frustrated, or even misled” if they come to the website looking for truthful and timely information on important issues. If you’ve ever watched a clickbait video, you’d know that’s definitely true. You may have trained yourself on being able to spot and skip them over the years, but some people might still not know the difference between clickbait and legitimate content.
One example of egregious clickbait, according to YouTube, is if a video says “the president resigned!” without actually addressing the president’s resignation. Misleading thumbails are considered egregious clickbait, as well. If a thumbnail reads “top political news” and the video doesn’t contain any political news, then it will also be subjected to YouTube’s enforcement action.
The website will start cracking down on clickbait videos in India — it didn’t say how it will expand from there, but we’ve asked it for more information. For now, it will delete any video that violates this policy without issuing strikes. After it goes through old videos, it will then prioritize new uploads, presumably so that they don’t reach more people that they should.
This article originally appeared on Engadget at https://www.engadget.com/entertainment/youtube/youtube-will-crack-down-on-egregious-clickbait-starting-in-india-130010064.html?src=rss
We at Engadget are in the unique position to test out many more gadgets than we actually use on a regular basis. It just comes with the territory of reviewing the newest smartphones or testing out dozens of power banks to find the best ones. But we still have to buy things for ourselves, and there are winners and losers just like there are when we test things out for professional purposes only. And similar to when we find a new top-tier tablet or VR headset, we like to sing the praises of the tech we bought ourselves to anyone who will listen. These are the best things Engadget staffers purchased this year that will continue to get lots of use in 2025.
This article originally appeared on Engadget at https://www.engadget.com/our-favorite-tech-we-bought-in-2024-130006482.html?src=rss
This week, we’re looking back at our hellish 2024 and trying to figure out where to go from here. We began the year with enormous hype around artificial intelligence, but that’s cooled off after seeing how useless many AI features have been. It’s also clear that many companies, including Microsoft and Apple, are trying to push half-baked AI concepts onto users. Looking forward, we’re expecting a rough few years for the tech industry (not to mention the world as a whole).
Listen below or subscribe on your podcast app of choice. If you’ve got suggestions or topics you’d like covered on the show, be sure to email us or drop a note in the comments! And be sure to check out our other podcast, Engadget News!
2024 in review: AI hype hasn’t led to much and the social media vibes are in flux – 1:12
What we’re looking forward to in 2025 – 21:43
Tiktok appeals its ban all the way to the US Supreme Court – 29:53
TP-Link routers are being investigated by US authorities – 32:39
Quick thoughts from last week’s Game Awards – 35:35
Working on – 38:26
Pop culture picks – 39:17
Interview with Tim Miller and Dave Wilson of Prime’s Secret Level – 49:20
Credits
Hosts: Devindra Hardawar and Cherlynn Low Producer: Ben Ellman Music: Dale North and Terrence O’Brien
This article originally appeared on Engadget at https://www.engadget.com/big-tech/engadget-podcast-the-ai-hype-train-stalled-in-2024-123042348.html?src=rss
Last week, Google allegedly instructed contract workers evaluating Gemini not to skip any prompts, regardless of their expertise, TechCrunch reports based on internal guidance it viewed.
Now, contractors have allegedly been instructed not to skip prompts that “require specialized domain knowledge” and to “rate the parts of the prompt you understand,” adding a note that it’s not an area they have knowledge in. Apparently, the only times contractors can skip now are if a big chunk of the information is missing or if it has harmful content.
Google filed a statement to Engadget, saying its raters “perform a wide range of tasks across many different Google products and platforms. They provide valuable feedback on more than just the content of the answers, but also on the style, format and other factors.”
Elevation Lab has released an accessory for the Apple AirTag that extends its battery life by up to 10 years and makes it waterproof. The TimeCapsule contains your AirTag and two AA batteries. You don’t need to open your AirTag and tinker with it — you only have to remove its backplate and coin battery before attaching it to the case. As you can see, it will make your tracking device a lot bigger and considerably heftier, so it’s mostly ideal for use with large objects, such as vehicles and big suitcases. Peace of mind for $20 — plus two AAs.
Honda is officially introducing two Series 0 electric vehicle prototypes at CES next year, and the company says they’ll be available for purchase around the world sometime in 2026. The vehicles will be based on the futuristic-looking concepts the company presented at CES 2024, including a flagship model called the Saloon, which featured a low profile and aerodynamic design.
The company teased a rollable laptop concept in 2022.
Lenovo
According to images shared by leaker Evan Blass, Lenovo’s sixth-generation ThinkBook Plus will have an extendable rolling display. The company first teased a “rollable” laptop concept in 2022. The display can extend and unroll until you effectively have two screens stacked on top of each other. Lenovo’s images show a video call open on the top part of the display, and what looks like a PowerPoint presentation on the bottom. It looks a little weird.
A novel approach for lightweight safety classification using pruned language models
Leveraging the hidden state from an intermediate Transformer layer for efficient and robust content safety and prompt injection classification
Image by author and GPT-4o meant to represent the robust language understanding provided by Large Language Models.
Introduction
As the adoption of Language Models (LMs) grows, it’s more and more important to detect inappropriate content in both the user’s input and the generated outputs of the language model. With each new model release from any major model provider, one of the first things people try to do is find ways to “jailbreak” or otherwise manipulate the model to respond in ways it shouldn’t. A quick search on Google or X reveals many examples of how people have found ways around model alignment tuning to get models to respond to inappropriate requests. Furthermore, many companies have released Generative AI based chatbots publicly for tasks like customer service, which often end up suffering from prompt injection attacks and responding to tasks both inappropriate and far beyond their intended use. Detecting and classifying these instances is extremely important for businesses so that they don’t end up with a system that can be easily manipulated by their users, especially if they deploy their chat systems publicly.
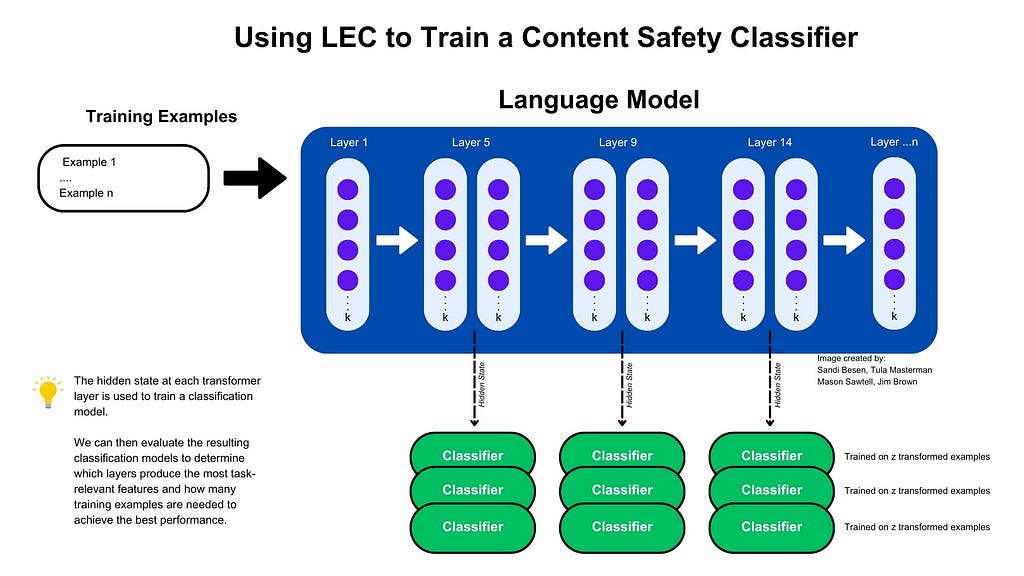
My team, Mason Sawtell, Sandi Besen, Jim Brown, and I recently published our paper Lightweight Safety Classification using Pruned Language Modelsas an ArXiv preprint. Our work introduces a new approach, Layer Enhanced Classification (LEC), and demonstrates that using LEC it is possible to effectively classify both content safety violations and prompt injection attacks by using the hidden state(s) from the intermediate transformer layer(s) of a Language Model to train a penalized logistic regression classifier with very few trainable parameters (769 on the low end) and a small number of training examples, often fewer than 100. This approach combines the computational efficiency of a simple classification model with the robust language understanding of a Language Model.
All of the models trained using our approach, LEC, outperform special-purpose models designed for each task as well as GPT-4o. We find that there are optimal intermediate transformer layers that produce the necessary features for both content safety and prompt injection classification tasks. This is important because it suggests you can use the same model to simultaneously classify content safety violations, prompt injections, and generate the output tokens. Alternatively, you could use a very small LM, prune it to the optimal intermediate layer, and use the outputs from this layer as the features for the classification task. This would allow for an incredibly compute efficient and lightweight classifier that integrates well with an existing LM inference pipeline.
This is the first of several articles I plan to share on this topic. In this article I will summarize the goals, approach, key results, and implications of our research. In a future article, I plan to share how we applied our approach to IBM’s Granite-8B model and an open-source model without any guardrails, allowing both models to detect content safety & prompt injection violations and generate output tokens all in one pass through the model. For further details on our research feel free to check out the full paper or reach out with questions.
Goals & Approach
Overview: Our research focuses on understanding how well the hidden states of intermediate transformer layers perform when used as the input features for classification tasks. We wanted to understand if small general-purpose models and special-purpose models for content safety and prompt injection classification tasks would perform better on these tasks if we could identify the optimal layer to use for the task instead of using the entire model / the last layer for classification. We also wanted to understand how small of a model, in terms of the total number of parameters, we could use as a starting point for this task. Other research has shown that different layers of the model focus on different characteristics of any given prompt input, our work finds that the intermediate layers tend to best capture the features that are most important for these classification tasks.
Datasets: For both content safety and prompt injection classification tasks we compare the performance of models trained using our approach to baseline models on task-specific datasets. Previous work indicated our classifiers would only see small performance improvements after a few hundred examples so for both classification tasks we used a task-specific dataset with 5,000 randomly sampled examples, allowing for enough data diversity while minimizing compute and training time. For the content safety dataset we use a combination of the SALAD Data dataset from OpenSafetyLab and the LMSYS-Chat-1M dataset from LMSYS. For the prompt injection dataset we use the SPML dataset since it includes system and user prompt pairs. This is critical because some user requests might seem “safe” (e.g., “help me solve this math problem”) but they ask the model to respond outside of the system’s intended use as defined in the system prompt (e.g. “You are a helpful AI assistant for Company X, you only respond to questions about our company”).
Model Selection: We use GPT-4o as a baseline model for both tasks since it is widely considered one of the most capable LLMs and in some cases outperformed the baseline special-purpose model(s). For content safety classification we use Llama Guard 3 1B and 8B models and for prompt injection classification we use Protect AI’s DeBERTA v3 Base Prompt Injection v2 model since these models are considered leaders in their respective areas. We apply our approach, LEC, to the baseline special purpose models (Llama Guard 3 1B, Llama Guard 3 8B, and DeBERTa v3 Base Prompt Injection) and general-purpose models. For general-purpose models we selected Qwen 2.5 Instruct in sizes 0.5B, 1.5B, and 3B since these models are relatively close in size to the special-purpose models.
This setup allows us to compare 3 key things:
How well our approach performs when applied to a small general-purpose model compared to both baseline models (GPT-4o and the special-purpose model).
How much applying our approach improves the performance of the special-purpose model relative to its own baseline performance on that task.
How well our approach generalizes across model architectures, by evaluating its performance on both general-purpose and special-purpose models.
Important Implementation Details: For both Qwen 2.5 Instruct models and task-specific special-purpose models we prune individual layers and capture the hidden state of the transformer layer to train a Penalized Logistic Regression (PLR) model with L2 regularization. The PLR model has the same number of trainable parameters as the size of the model’s hidden state plus one for the bias in binary classification tasks, this ranges from 769 for the smallest model (Protect AI’s DeBERTa) to 4097 for the largest model (Llama Guard 3 8B). We train the classifier with varying numbers of examples for each layer allowing us to understand the impact of individual layers on the task and how many training examples are necessary to surpass the baseline models’ performance or achieve optimal performance in terms of F1 score. We run our entire test set through the baseline models to establish their performance on each task.
Image by author and team demonstrating the LEC training process at a high level. Training examples are independently passed through a model and the hidden state at each transformer layer is captured. These hidden states are then used to train classifiers. Each classifier is trained with a varying number of examples. The results allow us to determine which layers produce the most task-relevant features and how many examples are needed to achieve the best performance.
Key Results
In this section I’ll cover the important results across both tasks and for each task, content safety classification and prompt injection classification, individually.
Key findings across both tasks:
Overall, our approach results in a higher F1 score across all evaluated tasks, models, and number of of training examples, typically surpassing baseline model performance within 20–100 examples.
The intermediate layers tend to show the largest improvement in F1 score compared to the final layer when trained on fewer examples. These layers also tend to have the best performance relative to the baseline models. This indicates that local features important to both classification tasks are represented early on in the transformer network and suggests that use cases with fewer training examples can especially benefit from our approach.
Furthermore, we found that applying our approach to the special-purpose models outperforms the models own baseline performance, typically within 20 examples, by identifying and using the most task-relevant layer.
Both general-purpose Qwen 2.5 Instruct models and task-specific special-purpose models achieve higher F1 scores within fewer examples with our approach. This suggests that our approach generalizes across architectures and domains.
In the Qwen 2.5 Instruct models, we find that the intermediate model layers attain higher F1 scores with fewer examples for both content safety and prompt injection classification tasks. This suggests that it’s feasible to use one model for both classification tasks and generate the outputs in one pass. The additional compute time for these extra classification steps would be almost negligible given the small size of the classifiers.
Content safety classification results:
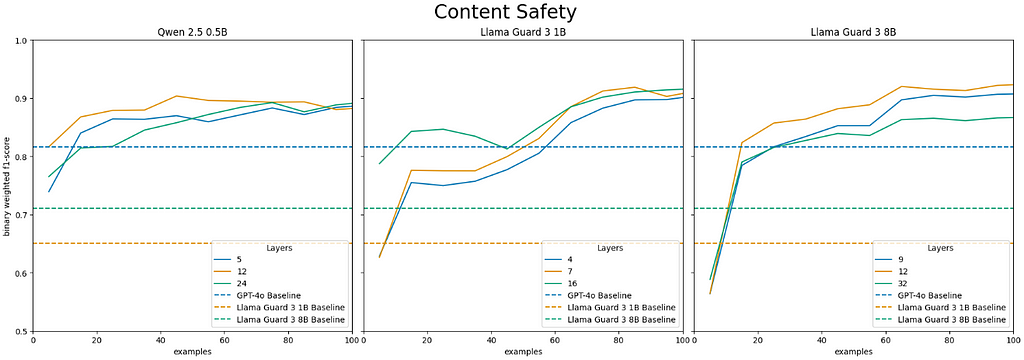
Image by author and team demonstrating LEC performance at select layers on the binary content safety classification task for Qwen 2.5 Instruct 0.5B, Llama Guard 3 1B, and Llama Guard 3 8b. The x-axis shows the number of training examples, and the Y-axis reflects the weighted F1-score.
For both binary and multi-class classification, the general and special purpose models trained using our approach typically outperform the baseline Llama Guard 3 models within 20 examples and GPT-4o in fewer than 100 examples.
For both binary and multi-class classification, the general and special purpose LEC models typically surpass all baseline models performance for the intermediate layers if not all layers. Our results on binary content safety classification surpass the baselines by the widest margins attaining maximum F1-scores of 0.95 or 0.96 for both Qwen 2.5 Instruct and Llama Guard LEC models. In comparison, GPT-4o’s baseline F1 score is 0.82, Llama Guard 3 1B’s is 0.65 , and Llama Guard 3 8B’s is 0.71.
For binary classification our approach performs comparably when applied to Qwen 2.5 Instruct 0.5B, Llama Guard 3 1B, and Llama Guard 3 8B. The models attain a maximum F1 score of 0.95, 0.96, and 0.96 respectively. Interestingly, Qwen 2.5 Instruct 0.5B surpasses GPT-4o’s baseline performance in 15 examples for the middle layers while it takes both Llama Guard 3 models 55 examples to do so.
For multi-class classification, a very small LEC model using the hidden state from the middle layers of Qwen 2.5 Instruct 0.5B surpasses GPT-4o’s baseline performance within 35 training examples for all three difficulty levels of the multi-class classification task.
Prompt injection classification results:
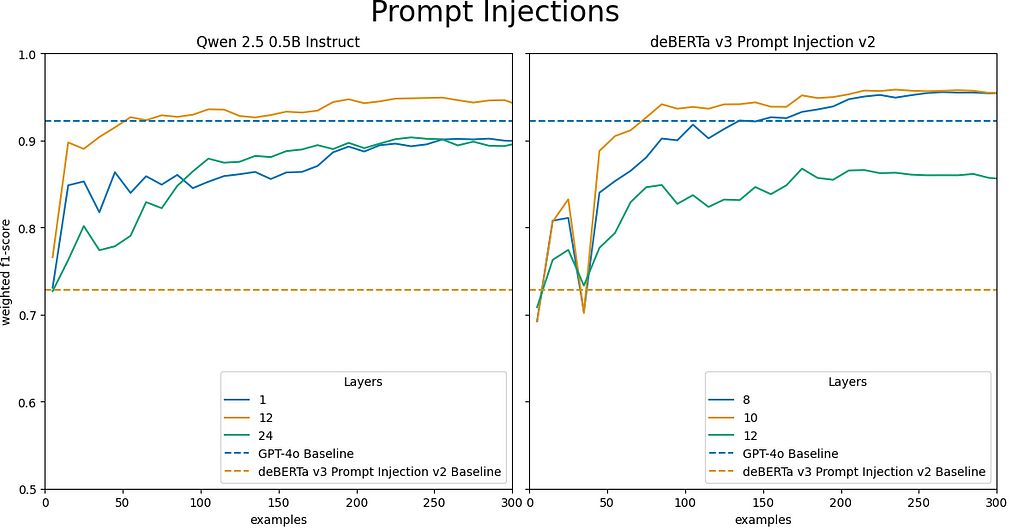
Image by author and team demonstrating LEC performance at select layers on the prompt injection classification task for Qwen 2.5 Instruct 0.5B and DeBERTa v3 Prompt Injection v2 models. The x-axis shows the number of training examples, and the Y-axis reflects the weighted F1-score. These graphs demonstrate how both LEC models outperform the baselines for the intermediate model layers with minimal training examples.
Applying our approach to both general-purpose Qwen 2.5 Instruct models and special-purpose DeBERTa v3 Prompt Injection v2 results in both models intermediate layers outperforming the baseline models in fewer than 100 training examples. This again indicates that our approach generalizes across model architectures and domains.
All three Qwen 2.5 Instruct model sizes surpass the baseline DeBERTa v3 Prompt Injection v2 model’s F1 score of 0.73 within 5 training examples for all model layers.
Qwen 2.5 Instruct 0.5B surpasses GPT-4o’s performance for the middle layer, layer 12 in 55 examples. Similar, but slightly better performance is observed for the larger Qwen 2.5 Instruct models.
Applying our approach to the DeBERTa v3 Prompt Injection v2 model results in a maximum F1 score of 0.98, significantly surpassing the model’s baseline performance F1 score of 0.73 on this task.
The intermediate layers achieve the highest weighted F1 scores for both the DeBERTa model and across Qwen 2.5 Instruct model sizes.
Conclusion
In our research we focused on two responsible AI related classification tasks but expect this approach to work for other classification tasks provided that the important features for the task can be detected by the intermediate layers of the model.
We demonstrated that our approach of training a classification model on the hidden state from an intermediate transformer layer creates effective content safety and prompt injection classification models with minimal parameters and training examples. Furthermore, we illustrated how our approach improves the performance of existing special-purpose models compared to their own baseline results.
Our results suggest two promising options for integrating top-performing content safety and prompt injection classifiers into existing LLM inference workflows. One option is to take a lightweight small model like the ones explored in our paper, prune it to the optimal layer and use it as a feature extractor for the classification task. The classification model could then be used to identify any content safety violations or prompt injections before processing the user input with a closed-source model like GPT-4o. The same classification model could be used to validate the generated response before sending it to the user. A second option is to apply our approach to an open-source, general-purpose model, like IBM’s Granite or Meta’s Llama models, identify which layers are most relevant to the classification task, then update the inference pipeline to simultaneously classify content safety and prompt injections while generating the output response. If content safety or prompt injections are detected you could easily stop the output generation, otherwise if there are no violations, the model can continue generating it’s response. Either of these options could be extended to apply to AI-agent based scenarios depending on the model used for each agent.
In summary, LEC provides a new promising and practical solution to safeguarding Generative AI based systems by identifying content safety and prompt injection attacks with better performance and fewer training examples compared to existing approaches. This is critical for any person or business building with Generative AI today to ensure their systems are operating both responsibly and as intended.
Note: The opinions expressed both in this article and the research paper are solely those of the authors and do not necessarily reflect the views or policies of their respective employers.
Interested in discussing further or collaborating? Reach out on LinkedIn!
Almost a year ago, I was prompted to look for another budgeting app. Intuit, parent company of Mint, the budgeting app I had been using for a long time, shut down the service in March 2024. The company encouraged Mint users to migrate to its other financial app, Credit Karma, but I found it to be a poor Mint replacement after trying it out. That sent me searching elsewhere to find an app to track all of my financial accounts, monitor my credit score, track spending and set goals like building a rainy-day fund and paying down my mortgage faster.
If you’re looking for a new budgeting app to get your finances straight, allow Engadget to help. I tried out Mint’s top competitors in the hopes that I’d be able to find a new budgeting app that could handle all of my financial needs, and to see which are actually worth the money.
How we tested budgeting apps
Before I dove in and started testing out budgeting apps, I had to do some research. To find a list of apps to try out, I consulted trusty ol’ Google (and even trustier Reddit); read reviews of popular apps on the App Store; and also asked friends and colleagues what budget tracking apps (or other budgeting methods) they might be using for money management. Some of the apps I found were free and these, of course, show loads of ads (excuse me, “offers”) to stay in business. But most of the available apps require paid subscriptions, with prices typically topping out around $100 a year, or $15 a month. (Spoiler: My top pick is cheaper than that.)
All of the services I chose to test needed to do several things: import all of your account data into one place; offer budgeting tools; and track your spending, net worth and credit score. Except where noted, all of these apps are available for iOS, Android and on the web.
Once I had my shortlist of six apps, I got to work setting them up. For the sake of thoroughly testing these apps, I made a point of adding every account to every budgeting app, no matter how small or immaterial the balance. What ensued was a veritable Groundhog Day of two-factor authentication. Just hours of entering passwords and one-time passcodes, for the same banks half a dozen times over. Hopefully, you only have to do this once.
Best budgeting apps of 2025
Budgeting app FAQs
What is Plaid and how does it work?
Each of the apps I tested uses the same underlying network, called Plaid, to pull in financial data, so it’s worth explaining what it is and how it works. Plaid was founded as a fintech startup in 2013 and is today the industry standard in connecting banks with third-party apps. Plaid works with over 12,000 financial institutions across the US, Canada and Europe. Additionally, more than 8,000 third-party apps and services rely on Plaid, the company claims.
To be clear, you don’t need a dedicated Plaid app to use it; the technology is baked into a wide array of apps, including all of the budgeting apps listed in this guide. Once you find the “add an account” option in whichever one you’re using, you’ll see a menu of commonly used banks. There’s also a search field you can use to look yours up directly. Once you find yours, you’ll be prompted to enter your login credentials. If you have two-factor authentication set up, you’ll need to enter a one-time passcode as well.
As the middleman, Plaid is a passthrough for information that may include your account balances, transaction history, account type and routing or account number. Plaid uses encryption, and says it has a policy of not selling or renting customer data to other companies. However, I would not be doing my job if I didn’t note that in 2022 Plaid was forced to pay $58 million to consumers in a class action suit for collecting “more financial data than was needed.” As part of the settlement, Plaid was compelled to change some of its business practices.
In a statement provided to Engadget, a Plaid spokesperson said the company continues to deny the allegations underpinning the lawsuit and that “the crux of the non-financial terms in the settlement are focused on us accelerating workstreams already underway related to giving people more transparency into Plaid’s role in connecting their accounts, and ensuring that our workstreams around data minimization remain on track.”
Why did Mint shut down?
When parent company Intuit announced in December 2023 that it would shut down Mint, it did not provide a reason why it made the decision to do so. It did say that Mint’s millions of users would be funneled over to its other finance app, Credit Karma. “Credit Karma is thrilled to invite all Minters to continue their financial journey on Credit Karma, where they will have access to Credit Karma’s suite of features, products, tools and services, including some of Mint’s most popular features,” Mint wrote on its product blog. In our testing, we found that Credit Karma isn’t an exact replacement for Mint — so if you’re still looking for a Mint alternative, you have some decent options.
What about Rocket Money?
Rocket Money is another free financial app that tracks spending and supports things like balance alerts and account linking. If you pay for the premium tier, the service can also help you cancel unwanted subscriptions. We did not test it for this guide, but we’ll consider it in future updates.
This article originally appeared on Engadget at https://www.engadget.com/best-budgeting-apps-120036303.html?src=rss
While there remain regular laptops and gaming laptops, the line that separates them has nearly disappeared. Today, if you have a fast CPU and graphics card, along with perks like a big screen and a good cooling system, you can play a decent number of games on your laptop. Besides, not everyone wants a big, garish gaming rig, nor does everyone want to spend the money required to get one of those. If you’re considering a new laptop for school, there are more options now than ever before that can both get you through your most challenging studies and keep up with your next AAA play through. These are our top picks for the best laptops for gaming and schoolwork — but if you’re looking for a dedicated gaming laptop rather than an all-in-one machine, check out our best gaming laptops list for our recommendations.
Best laptops for gaming and school in 2025
Are gaming laptops good for school?
As we’ve mentioned, gaming laptops are especially helpful if you’re doing any demanding work. Their big promise is powerful graphics performance, which isn’t just limited to PC gaming. Video editing and 3D rendering programs can also tap into their GPUs to handle laborious tasks. While you can find decent GPUs on some productivity machines, like Dell’s XPS 15, you can sometimes find better deals on gaming laptops. My general advice for any new workhorse: Pay attention to the specs; get at least 16GB of RAM and the largest solid state drive you can find (ideally 1TB or more). Those components are both typically hard to upgrade down the line, so it’s worth investing what you can up front to get the most out of your PC gaming experience long term. Also, don’t forget the basics like a webcam, which will likely be necessary for the schoolwork portion of your activities.
The one big downside to choosing a gaming notebook is portability. For the most part, we’d recommend 15-inch models to get the best balance of size and price. Those typically weigh in around 4.5 pounds, which is significantly more than a three-pound ultraportable. Today’s gaming notebooks are still far lighter than older models, though, so at least you won’t be lugging around a 10-pound brick. If you’re looking for something lighter, there are plenty of 14-inch options these days. And if you’re not into LED lights and other gamer-centric bling, keep an eye out for more understated models that still feature essentials like a webcam (or make sure you know how to turn those lights off).
This article originally appeared on Engadget at https://www.engadget.com/computing/laptops/best-laptops-for-gaming-and-school-132207352.html?src=rss
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.