Another day, another Tesla recall. This time, the National Highway Traffic Safety Administration (NHTSA) informed the owners of almost 700,000 Tesla vehicles warning them of a problem with a warning light for the tire pressure monitoring system as reported by the Associated Press.
The recall affects the 2024 Cybertruck, 2017-2025 Model 3 and 2020-2025 Model Y Vehicles. The NHTSA says the warning light for the tire pressure monitoring system may not stay illuminated between drives.
Tesla says it will send out an over-the-road (OTR) update to vehicles affected by the warning light issue. Owner notification letters are expected to be mailed on Feb. 15, 2025.
The past year has seen more than a few Tesla recalls and OTRs. The NHTSA recorded seven recalls in the last year for the Cybertruck to address problems involving the rear-view camera, faulty windshield wipers and loose trunk beds. Tesla issued an over-the-air update in June for 1.8 million vehicles including select 2021-2024 Model 3, S and X vehicles and 2020-2024 Model Y vehicles to fix hoods that could come loose during drives if closed improperly.
This article originally appeared on Engadget at https://www.engadget.com/transportation/evs/tesla-is-recalling-almost-700000-vehicles-over-a-tire-pressure-monitor-issue-223639361.html?src=rss
LEC surpasses best in class models, like GPT-4o, by combining the efficiency of a ML classifier with the language understanding of an LLM
Imagine sitting in a boardroom, discussing the most transformative technology of our time — artificial intelligence — and realizing we’re riding a rocket with no reliable safety belt. The Bletchley Declaration, unveiled during the AI Safety Summit hosted by the UK government and backed by 29 countries, captures this sentiment perfectly [1]:
“There is potential for serious, even catastrophic, harm, either deliberate or unintentional, stemming from the most significant capabilities of these AI models”.
Source: Dalle3
However, existing AI safety approaches force organizations into an un-winnable trade-off between cost, speed, and accuracy. Traditional machine learning classifiers struggle to capture the subtleties of natural language and LLM’s, while powerful, introduce significant computational overhead — requiring additional model calls that escalate costs for each AI safety check.
Image by : Sandi Besen, Tula Masterman, Mason Sawtell, Jim Brown
We prove LEC combines the computational efficiency of a machine learning classifier with the sophisticated language understanding of an LLM — so you don’t have to choose between cost, speed, and accuracy. LEC surpasses best in class models like GPT-4o and models specifically trained for identifying unsafe content and prompt injections. What’s better yet, we believe LEC can be modified to tackle non AI safety related text classification tasks like sentiment analysis, intent classification, product categorization, and more.
The implications are profound. Whether you’re a technology leader navigating the complex terrain of AI safety, a product manager mitigating potential risks, or an executive charting a responsible innovation strategy, our approach offers a scalable and adaptable solution.
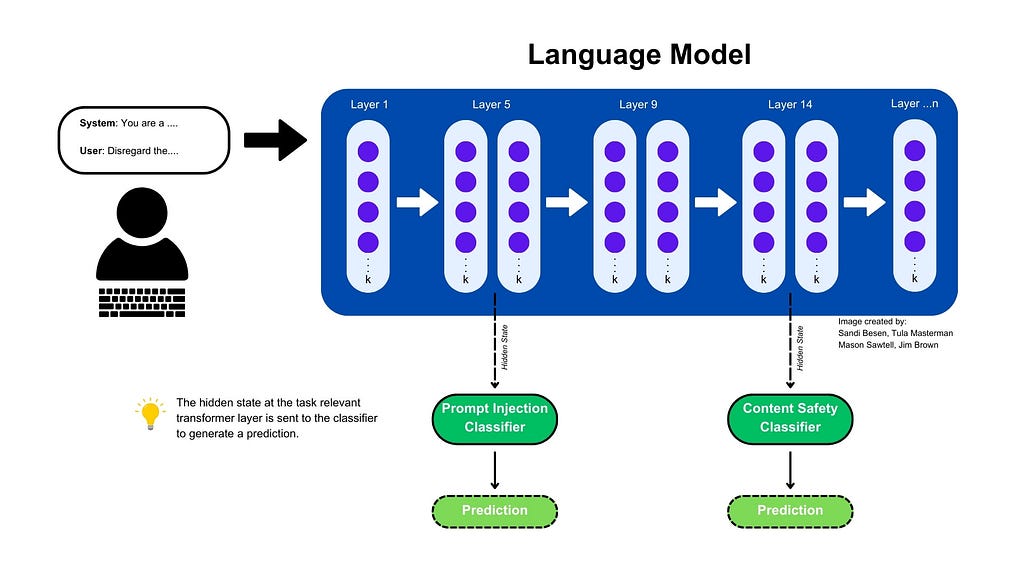
Figure 1: An example of an adapted model inference pipeline to include LEC Classifiers. Image by : Sandi Besen, Tula Masterman, Mason Sawtell, Jim Brown
Responsible AI has become a critical priority for technology leaders across the ecosystem — from model developers like Anthropic, OpenAI, Meta, Google, and IBM to enterprise consulting firms and AI service providers. As AI adoption accelerates, its importance becomes even more pronounced.
Our research specifically targets two pivotal challenges in AI safety — content safety and prompt injection detection. Content safety refers to the process of identifying and preventing the generation of harmful, inappropriate, or potentially dangerous content that could pose risks to users or violate ethical guidelines. Prompt injection involves detecting attempts to manipulate AI systems by crafting input prompts designed to bypass safety mechanisms or coerce the model into producing unethical outputs.
To advance the field of ethical AI, we applied LEC’s capabilities to real-world responsible AI use cases. Our hope is that this methodology will be adopted widely, helping to make every AI system less vulnerable to exploitation.
Using LEC for Content Safety Tasks
We curated a content safety dataset of 5,000 examples to test LEC on both binary (2 categories) and multi-class (>2 categories) classification. We used the SALAD Data dataset from OpenSafetyLab [3] to represent unsafe content and the “LMSYS-Chat-1M” dataset from LMSYS, to represent safe content [4].
For binary classification the content is either “safe” or “unsafe”. For multi-class classification, content is either categorized as “safe” or assigned to a specific specific “unsafe” category.
We compared model’s trained using LEC to GPT-4o (widely recognized as an industry leader), Llama Guard 3 1B and Llama Guard 3 8B (special purpose models specifically trained to tackle content safety tasks). We found that the models using LEC outperformed all models we compared them to using as few as 20 training examples for binary classification and 50 training examples for multi-class classification.
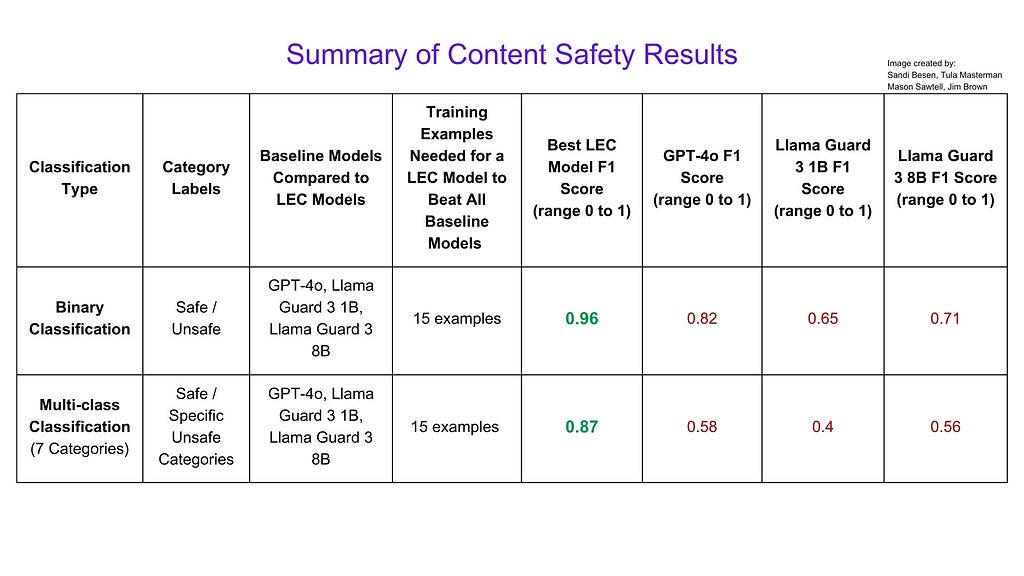
The highest performing LEC model achieved a weighted F1 score (measures how well a system balances making correct predictions while minimizing mistakes) of .96 of a maximum score of 1 on the binary classification task compared to GPT-4o’s score of 0.82 or LlamaGuard 8B’s score of 0.71.
This means that with as few as 15 examples, using LEC you can train a model to outperform industry leaders in identifying safe or unsafe content at a fraction of the computational cost.
Summary of Content safety Results. Image by : Sandi Besen, Tula Masterman, Mason Sawtell, Jim Brown
Using LEC for Identifying Prompt Injections
We curated a prompt injection dataset using the SPML Chatbot Prompt Injection Dataset. We chose the SPML dataset because of its diversity and complexity in representing real-world chat bot scenarios. This dataset contained pairs of system and user prompts to identify user prompts that attempt to defy or manipulate the system prompt. This is especially relevant for businesses deploying public facing chatbots that are only meant to answer questions about specific domains.
We compared model’s trained using LEC to GPT-4o (an industry leader) and deBERTa v3 Prompt Injection v2 (a model specifically trained to identify prompt injections). We found that the models using LEC outperformed both GPT-4o using 55 training examples and the the special purpose model using as few as 5 training examples.
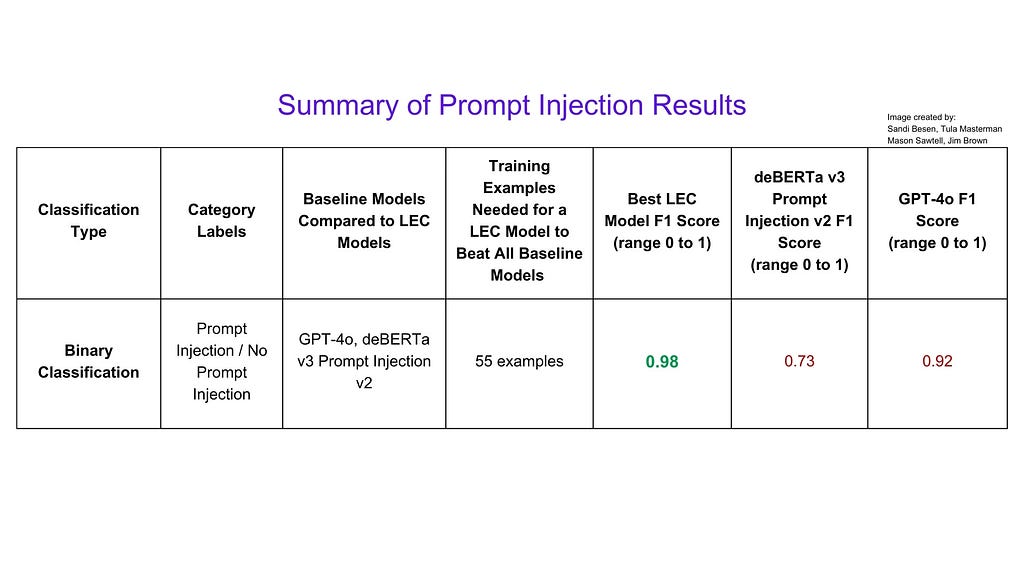
The highest performing LEC model achieved a weighted F1 score of .98 of a maximum score of 1 compared to GPT-4o’s score of 0.92 or deBERTa v2 Prompt Injection v2’s score of 0.73.
This means that with as few as 5 examples, using LEC you can train a model to outperform industry leaders in identifying prompt injection attacks.
Summary of Prompt Injection Results. Image by : Sandi Besen, Tula Masterman, Mason Sawtell, Jim Brown
Full results and experimentation implementation details can be found in the Arxiv preprint.
How Your Business Can Benefit From using LEC
As organizations increasingly integrate AI into their operations, ensuring the safety and integrity of AI-driven interactions has become mission-critical. LEC provides a robust and flexible way to ensure that potentially unsafe information is being detected — resulting in reduce operational risk and increased end user trust. There are several ways that a LEC models can be incorporated into your AI Safety Toolkit to prevent unwanted vulnerabilities when using your AI tools including during LM inference, before/after LM inference, and even in multi-agent scenarios.
During LM Inference
If you are using an open-source model or have access to the inner workings of the closed-source model, you can use LEC as part of your inference pipeline for AI safety in near real time. This means that if any safety concerns arise while information is traveling through the language model, generation of any output can be halted. An example of what this might look like can be seen in figure 1.
Before / After LM Inference
If you don’t have access to the inner workings of the language model or want to check for safety concerns as a separate task you can use a LEC model before or after calling a language model. This makes LEC compatible with closed source models like the Claude and GPT families.
Building a LEC Classifier into your deployment pipeline can save you from passing potentially harmful content into your LM and/or check for harmful content before an output is returned to the user.
Using LEC Classifiers with Agents
Agentic AI systems can amplify any existing unintended actions, leading to a compounding effect of unintended consequences. LEC Classifiers can be used at different times throughout an agentic scenario to can safeguard the agent from either receiving or producing harmful outputs. For instance, by including LEC models into your agentic architecture you can:
Check that the request is ok to start working on
Ensure an invoked tool call does not violate any AI safety guidelines (e.g., generating inappropriate search topics for a keyword search)
Make sure information returned to an agent is not harmful (e.g., results returned from RAG search or google search are “safe”)
Validating the final response of an agent before passing it back to the user
How to Implement LEC Based on Language Model Access
Enterprises with access to the internal workings of models can integrate LEC directly within the inference pipeline, enabling continuous safety monitoring throughout the AI’s content generation process. When using closed-source models via API (as is the case with GPT-4), businesses do not have direct access to the underlying information needed to train a LEC model. In this scenario, LEC can be applied before and/or after model calls. For example, before an API call, the input can be screened for unsafe content. Post-call, the output can be validated to ensure it aligns with business safety protocols.
No matter which way you choose to implement LEC, using its powerful abilities provides you with superior content safety and prompt injection protection than existing techniques at a fraction of the time and cost.
Conclusion
Layer Enhanced Classification (LEC) is the safety belt for that AI rocket ship we’re on.
The value proposition is clear: LEC’s AI Safety models can mitigate regulatory risk, help ensure brand protection, and enhance user trust in AI-driven interactions. It signals a new era of AI development where accuracy, speed, and cost aren’t competing priorities and AI safety measures can be addressed both at inference time, before inference time, or after inference time.
In our content safety experiments, the highest performing LEC model achieved a weighted F1 score of 0.96 out of 1 on binary classification, significantly outperforming GPT-4o’s score of 0.82 and LlamaGuard 8B’s score of 0.71 — and this was accomplished with as few as 15 training examples. Similarly, in prompt injection detection, our top LEC model reached a weighted F1 score of 0.98, compared to GPT-4o’s 0.92 and deBERTa v2 Prompt Injection v2’s 0.73, and it was achieved with just 55 training examples. These results not only demonstrate superior performance, but also highlight LEC’s remarkable ability to achieve high accuracy with minimal training data.
Although our work focused on using LEC Models for AI safety use cases, we anticipate that our approach can be used for a wider variety of text classification tasks. We encourage the research community to use our work as a stepping stone for exploring what else can be achieved — further open new pathways for more intelligent, safer, and more trustworthy AI systems.
Note: The opinions expressed both in this article and paper are solely those of the authors and do not necessarily reflect the views or policies of their respective employers.
Interested in connecting? Drop me a DM on Linkedin! I‘m always eager to engage in food for thought and iterate on my work.
Large language models are fantastic tools for unstructured text, but what if your text doesn’t fit in the context window? Bazaarvoice faced exactly this challenge when building our AI Review Summaries feature: millions of user reviews simply won’t fit into the context window of even newer LLMs and, even if they did, it would be prohibitively expensive.
In this post, I share how Bazaarvoice tackled this problem by compressing the input text without loss of semantics. Specifically, we use a multi-pass hierarchical clustering approach that lets us explicitly adjust the level of detail we want to lose in exchange for compression, regardless of the embedding model chosen. The final technique made our Review Summaries feature financially feasible and set us up to continue to scale our business in the future.
The Problem
Bazaarvoice has been collecting user-generated product reviews for nearly 20 years so we have a lot of data. These product reviews are completely unstructured, varying in length and content. Large language models are excellent tools for unstructured text: they can handle unstructured data and identify relevant pieces of information amongst distractors.
LLMs have their limitations, however, and one such limitation is the context window: how many tokens (roughly the number of words) can be put into the network at once. State-of-the-art large language models, such as Athropic’s Claude version 3, have extremely large context windows of up to 200,000 tokens. This means you can fit small novels into them, but the internet is still a vast, every-growing collection of data, and our user-generated product reviews are no different.
We hit the context window limit while building our Review Summaries feature that summarizes all of the reviews of a specific product on our clients website. Over the past 20 years, however, many products have garnered thousands of reviews that quickly overloaded the LLM context window. In fact, we even have products with millions of reviews that would require immense re-engineering of LLMs to be able to process in one prompt.
Even if it was technically feasible, the costs would be quite prohibitive. All LLM providers charge based on the number of input and output tokens. As you approach the context window limits for each product, of which we have millions, we can quickly run up cloud hosting bills in excess of six figures.
Our Approach
To ship Review Summaries despite these technical, and financial, limitations, we focused on a rather simple insight into our data: Many reviews say the same thing. In fact, the whole idea of a summary relies on this: review summaries capture the recurring insights, themes, and sentiments of the reviewers. We realized that we can capitalize on this data duplication to reduce the amount of text we need to send to the LLM, saving us from hitting the context window limit and reducing the operating cost of our system.
To achieve this, we needed to identify segments of text that say the same thing. Such a task is easier said than done: often people use different words or phrases to express the same thing.
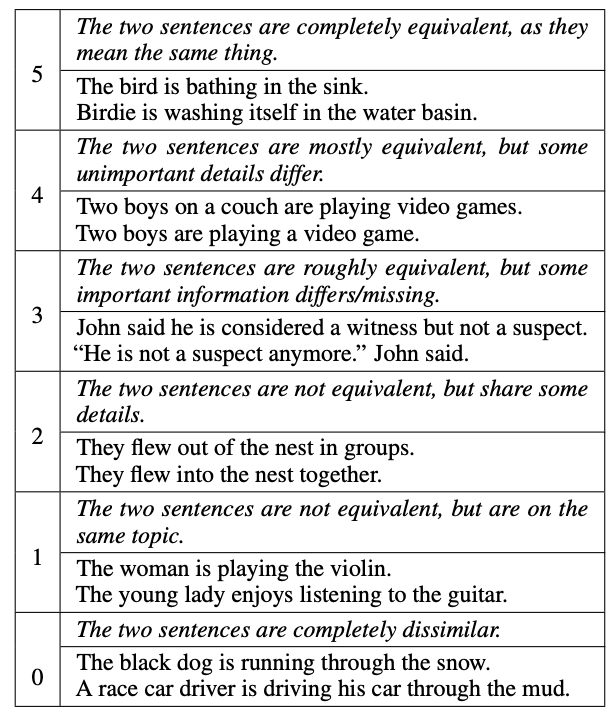
Fortunately, the task of identifying if text is semantically similar has been an active area of research in the natural language processing field. The work by Agirre et. al. 2013 (SEM 2013 shared task: Semantic Textual Similarity. In Second Joint Conference on Lexical and Computational Semantics) even published a human-labeled data of semantically similar sentences known as the STS Benchmark. In it, they ask humans to indicate if textual sentences are semantically similar or dissimilar on a scale of 1–5, as illustrated in the table below (from Cer et. al., SemEval-2017 Task 1: Semantic Textual Similarity Multilingual and Crosslingual Focused Evaluation):
The STSBenchmark dataset is often used to evaluate how well a text embedding model can associate semantically similar sentences in its high-dimensional space. Specifically, Pearson’s correlation is used to measure how well the embedding model represents the human judgements.
Thus, we can use such an embedding model to identify semantically similar phrases from product reviews, and then remove repeated phrases before sending them to the LLM.
Our approach is as follows:
First, product reviews are segmented the into sentences.
An embedding vector is computed for each sentence using a network that performs well on the STS benchmark
Agglomerative clustering is used on all embedding vectors for each product.
An example sentence — the one closest to the cluster centroid — is retained from each cluster to send to the LLM, and other sentences within each cluster are dropped.
Any small clusters are considered outliers, and those are randomly sampled for inclusion in the LLM.
The number of sentences each cluster represents is included in the LLM prompt to ensure the weight of each sentiment is considered.
This may seem straightforward when written in a bulleted list, but there were some devils in the details we had to sort out before we could trust this approach.
Embedding Model Evaluation
First, we had to ensure the model we used effectively embedded text in a space where semantically similar sentences are close, and semantically dissimilar ones are far away. To do this, we simply used the STS benchmark dataset and computed the Pearson correlation for the models we desired to consider. We use AWS as a cloud provider, so naturally we wanted to evaluate their Titan Text Embedding models.
Below is a table showing the Pearson’s correlation on the STS Benchmark for different Titan Embedding models:
So AWS’s embedding models are quite good at embedding semantically similar sentences. This was great news for us — we can use these models off the shelf and their cost is extremely low.
Semantically Similar Clustering
The next challenge we faced was: how can we enforce semantic similarity during clustering? Ideally, no cluster would have two sentences whose semantic similarity is less than humans can accept — a score of 4 in the table above. Those scores, however, do not directly translate to the embedding distances, which is what is needed for agglomerative clustering thresholds.
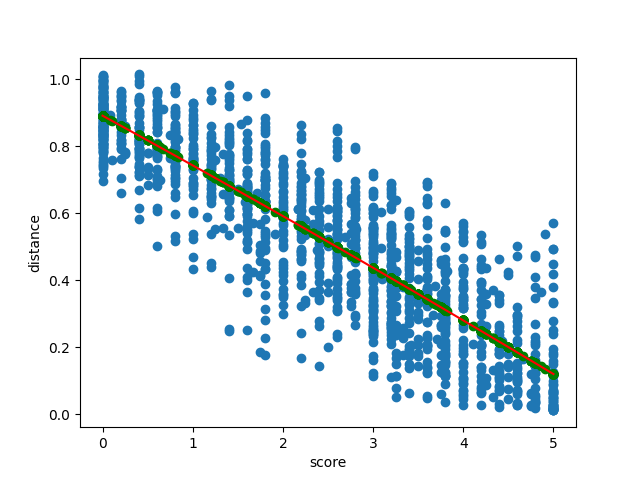
To deal with this issue, we again turned to the STS benchmark dataset. We computed the distances for all pairs in the training dataset, and fit a polynomial from the scores to the distance thresholds.
Image by author
This polynomial lets us compute the distance threshold needed to meet any semantic similarity target. For Review Summaries, we selected a score of 3.5, so nearly all clusters contain sentences that are “roughly” to “mostly” equivalent or more.
It’s worth noting that this can be done on any embedding network. This lets us experiment with different embedding networks as they become available, and quickly swap them out should we desire without worrying that the clusters will have semantically dissimilar sentences.
Multi-Pass Clustering
Up to this point, we knew we could trust our semantic compression, but it wasn’t clear how much compression we could get from our data. As expected, the amount of compression varied across different products, clients, and industries.
Without loss of semantic information, i.e., a hard threshold of 4, we only achieved a compression ratio of 1.18 (i.e., a space savings of 15%).
Clearly lossless compression wasn’t going to be enough to make this feature financially viable.
Our distance selection approach discussed above, however, provided an interesting possibility here: we can slowly increase the amount of information loss by repeatedly running the clustering at lower thresholds for remaining data.
The approach is as follows:
Run the clustering with a threshold selected from score = 4. This is considered lossless.
Select any outlying clusters, i.e., those with only a few vectors. These are considered “not compressed” and used for the next phase. We chose to re-run clustering on any clusters with size less than 10.
Run clustering again with a threshold selected from score = 3. This is not lossless, but not so bad.
Select any clusters with size less than 10.
Repeat as desired, continuously decreasing the score threshold.
So, at each pass of the clustering, we’re sacrificing more information loss, but getting more compression and not muddying the lossless representative phrases we selected during the first pass.
In addition, such an approach is extremely useful not only for Review Summaries, where we want a high level of semantic similarity at the cost of less compression, but for other use cases where we may care less about semantic information loss but desire to spend less on prompt inputs.
In practice, there are still a significantly large number of clusters with only a single vector in them even after dropping the score threshold a number of times. These are considered outliers, and are randomly sampled for inclusion in the final prompt. We select the sample size to ensure the final prompt has 25,000 tokens, but no more.
Ensuring Authenticity
The multi-pass clustering and random outlier sampling permits semantic information loss in exchange for a smaller context window to send to the LLM. This raises the question: how good are our summaries?
At Bazaarvoice, we know authenticity is a requirement for consumer trust, and our Review Summaries must stay authentic to truly represent all voices captured in the reviews. Any lossy compression approach runs the risk of mis-representing or excluding the consumers who took time to author a review.
To ensure our compression technique was valid, we measured this directly. Specifically, for each product, we sampled a number of reviews, and then used LLM Evals to identify if the summary was representative of and relevant to each review. This gives us a hard metric to evaluate and balance our compression against.
Results
Over the past 20 years, we have collected nearly a billion user-generated reviews and needed to generate summaries for tens of millions of products. Many of these products have thousands of reviews, and some up to millions, that would exhaust the context windows of LLMs and run the price up considerably.
Using our approach above, however, we reduced the input text size by 97.7% (a compression ratio of 42), letting us scale this solution for all products and any amount of review volume in the future. In addition, the cost of generating summaries for all of our billion-scale dataset reduced 82.4%. This includes the cost of embedding the sentence data and storing them in a database.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.