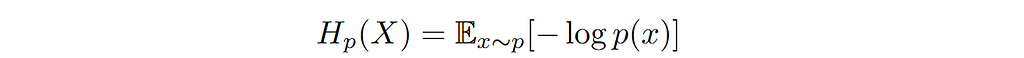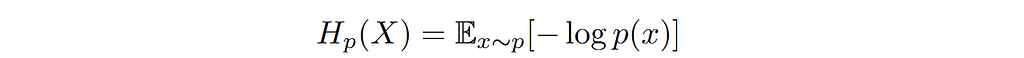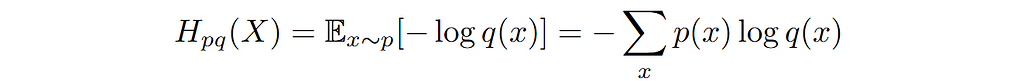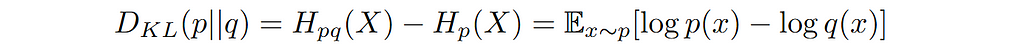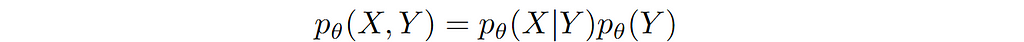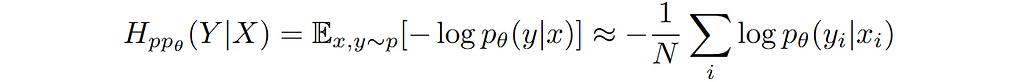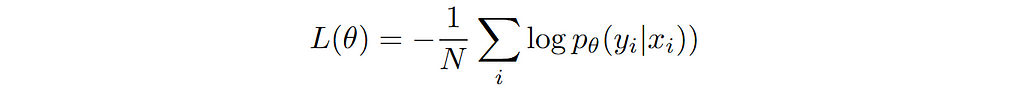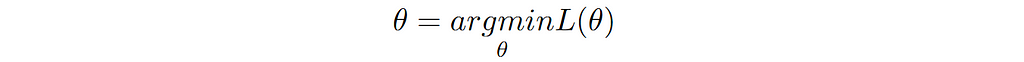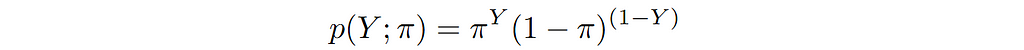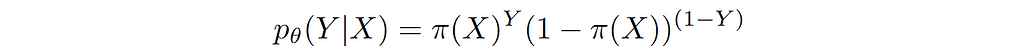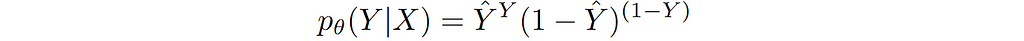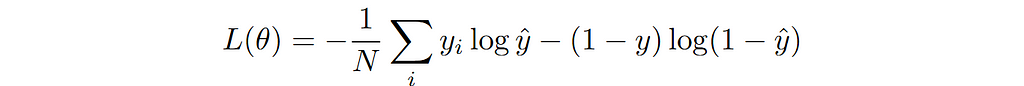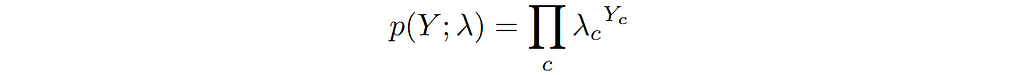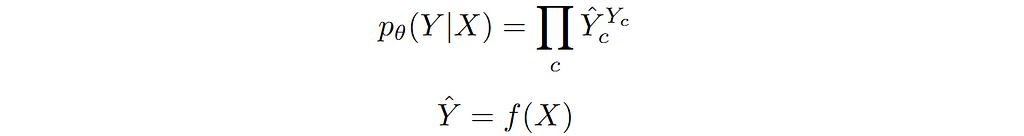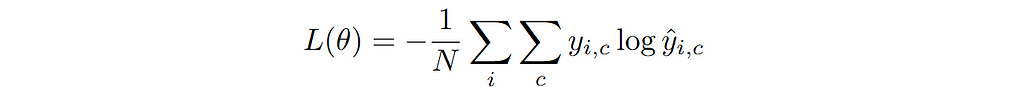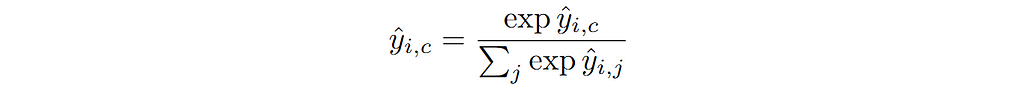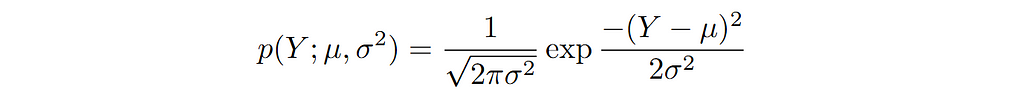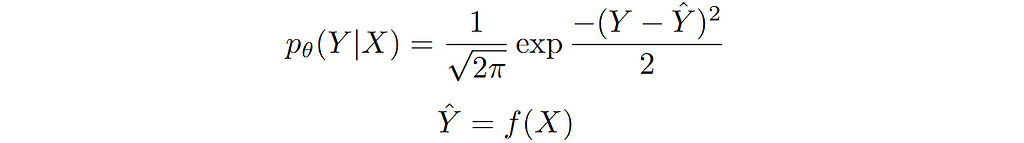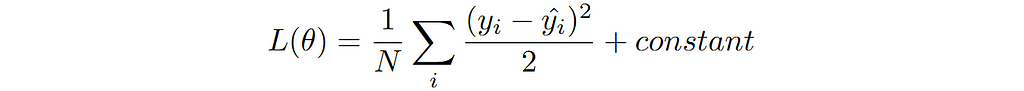It looks like we won’t have to wait long to find out what happens in the next installment of Netflix’s addictive and deadly drama Squid Game. The Netflix-owned blog Tudum announced the South Korean drama will return next year for its third and final season.
The first season ended with winner Seong Gi-hun, played by Emmy winner Lee Jung-Jae, leaving his newfound wealth to dismantle the titular game. Since then, we’ve learned in sneak previews and the Season 2 trailer that Seong’s plan is to rejoin the deadly competition and convince the players to vote for the games to stop. Something tells me it’s not going to be that simple.
The second season of Squid Game just landed today on Netflix after a three-year wait.
This article originally appeared on Engadget at https://www.engadget.com/entertainment/streaming/squid-game-will-have-a-third-and-final-season-in-2025-192216881.html?src=rss
Since the release of iOS 18.2 on December 11, ChatGPT integration has been an integral part of Apple Intelligence. Provided you own a recent iPhone, iPad or Mac, you can access OpenAI’s chatbot directly from your device, with no need to go through the ChatGPT app or web client.
What is ChatGPT?
ChatGPT is a generative AI chatbot created by OpenAI and powered by a large language machine-learning model. In addition to the capability to interact with people using natural language, ChatGPT can search the web, solve complex math and coding problems, as well as generate text, images and audio. As of the writing of this article, the current version of ChatGPT is based on OpenAI’s GPT-4o and 4o mini models.
In June 2024, Apple announced it was partnering with OpenAI to integrate ChatGPT into Apple Intelligence. While some of ChatGPT’s signature features are available directly within iOS, iPadOS and macOS, many, such as Advanced Voice Mode, can only be accessed through the ChatGPT app or the OpenAI website.
Where can you use ChatGPT on your iPhone?
Igor Bonifacic for Engadget
On iPhone, ChatGPT is primarily available through three surfaces. First, Siri can turn to ChatGPT to answer your questions. In instances where Apple’s digital assistant determines ChatGPT can help it assist you better, it will ask you for your permission to share your request with OpenAI. You can also use ChatGPT to identify places and objects through the iPhone 16’s Camera Control menu.
Lastly, you can get ChatGPT’s help when using Apple’s new “Writing Tools.” Essentially, anytime you’re typing with the iPhone’s built-in keyboard, including in first-party apps like Notes, Mail and Messages, ChatGPT can help you compose text. Finding this feature can be a bit tricky, so here’s how to access it:
Long press on a section of text to bring up iOS 18’s text selection tool.
Tap Writing Tools. You may need to tap the arrow icon for the option to appear.
Select Compose.
Tap Compose with ChatGPT, and write a prompt describing what you’d like ChatGPT to write for you.
Do you need an OpenAI account to use ChatGPT on an iPhone?
No, an OpenAI account is not required to use ChatGPT on iPhone. However, if you have a paid subscription, you can use ChatGPT features on your device more often. Signing into your account will also save any requests to your ChatGPT history.
How to set up ChatGPT
If your iPhone hasn’t prompted you to enable ChatGPT already, you can manually turn on the extension by following these steps:
Go to Settings.
Tap Apple Intelligence & Siri.
Tap ChatGPT, then select Set Up.
Tap either Enable ChatGPT or Use ChatGPT with an Account. Select the latter if you have an OpenAI account.
What Apple devices offer ChatGPT integration?
An iPhone with Apple Intelligence is required to use ChatGPT. As of the writing of this article, Apple Intelligence is available on the following devices:
iPhone 16
iPhone 16 Plus
iPhone 16 Pro
iPhone 16 Pro Max
iPhone 15 Pro
iPhone 15 Pro Max
iPad mini with A17 Pro
iPad Air with M1 and later
iPad Pro with M1 and later
MacBook Air with M1 and later
MacBook Pro with M1 and later
iMac with M1 and later
Mac mini with M1 and later
Mac Studio with M1 Max and later
Mac Pro with M2 Ultra
This article originally appeared on Engadget at https://www.engadget.com/mobile/how-to-use-chatgpt-on-your-iphone-190317336.html?src=rss
In recent years, reflecting on the past 12 months has seemed to bring back nothing but woe. Surprisingly, though, 2024 saw a higher number of candidates for good things in tech than bad. In spite of the continued AI onslaught, widespread dissatisfaction and worldwide political conflict, there were some bright spots this year that put smiles on faces and took minds off things. As we get ready to start saying “2025” when making plans, here’s hoping that reminiscing about the best things in tech in 2024 can help us remember joyful times.
LocalThunk
You likely don’t know the name LocalThunk, which is the handle of a Canadian game developer who has yet to share his real identity. You do, however, know his handywork. LocalThunk made a little game called Balatro, which has been the indie success story of the year. The massive cultural footprint of this game instantly put him on the Mount Rushmore of solo developers, alongside Daisuke Amaya (Cave Story), Markus Persson (Minecraft), Lucas Pope (Papers, Please) and Eric Barone (Stardew Valley), among others.
Balatro — which can justly be described as a wacky full-fledged sequel to poker —came out back in February, and has since sold millions of copies across multiple platforms. It has popped up on numerous 2024 best-of lists and even nabbed a nomination for GOTY at The Game Awards. To call it a hit is something of an understatement. Balatro has become so popular that it has crossed over with other gaming franchises and inspired a physical deck of cards.
LocalThunk is now, very likely, worth a whole lot of money. Good for him. He created something new that everyone wanted, a venture that took three years. Despite the similarities to poker, the developer is extremely committed to keeping Balatro pure and out of the hands of gambling platforms. He recently revealed that he created a will that stipulated that the IP never be sold or licensed to any gambling company or casino.
I highly recommend checking out the game, which is available for both consoles and mobile devices. It will likely burn into your brain, leaving you unable to think or talk about anything else. Actually, wait until you have some time off work before giving it a download. — Lawrence Bonk, contributing writer
Bluesky
After several months in an invitation-only beta, Bluesky finally ditched its waitlist and opened to everyone at the start of 2024. At the time, it had just over 3 million users, a handful of employees and a lot of ideas about how to build a better space for public conversations. Since then, the service has grown to more than 25 million users, including a number of celebrities, politicians and other prominent figures who were once active on X.
Bluesky is still very much an underdog. Meta’s Threads has more than 10 times as many total users and far more resources. Even so, Bluesky has notched some significant wins. The open source service nearly tripled in size in the last few months of the year, thanks to a surge in new users following the election. The platform has also had an outsized influence when it comes to features, with Meta already copying unique ideas like starter packs and custom feeds.
Bluesky isn’t without issues — it needs to come up with a better approach to verification for example — but it’s still our best hope for an open, decentralized platform not controlled by a multibillion dollar advertising company. While Meta is reportedly preparing to point its ad machine at Threads and has already throttled the reach of political content, Bluesky’s leaders have made it clear they want to take a different approach. And while it’s hard to imagine Bluesky’s growth eclipsing Threads anytime soon, Bluesky feels more relevant than ever. — Karissa Bell, senior reporter
Sam Rutherford for Engadget
Google Pixel 9 Pro Fold
We’ve seen so many competing designs on foldable phones over the years. Samsung started out with an inward folding hinge on the original Galaxy Fold and stuck with it as the Z Fold line has morphed into the long, skinny baton-like devices we have today. Then there were others like the Huawei Mate X which featured outward folding builds. More recently, companies have teased the first generation of gadgets with tri-folding displays. But after testing out Google’s Pixel 9 Pro Fold this year, it feels like keeping things simple was the winning formula all along.
That’s because instead of trying to create a foldable with a unique aspect ratio or screen size, Google basically took the exterior display from the standard Pixel 9 and then installed a flexible display almost exactly twice the size on the inside. So when it’s closed, you have a phone that looks, feels and operates just like a typical glass-brick but when opened can also expand to become a mini tablet. The Pixel 9 Pro Fold also has the best cameras on any foldable on sale today while not being much thicker or heavier than its more traditional siblings. But perhaps the biggest victory is just seeing how much of a jump in build quality and usability the Pro Fold offers over its predecessor without making any major sacrifices. I just wish it was a bit more affordable so more people could experience the magic of a big foldable phone. — Sam Rutherford, senior reviewer
AR Glasses
For years, companies like Meta and Snap have hyped up the promise of augmented reality — not just the animated selfie lenses and other effects we can see on our phones, but standalone hardware capable of overlaying information onto the world around us. But despite these promises, actual AR glasses felt just out of reach.
This year, that finally started to change. Snap released its second pair of AR Spectacles, and Meta finally showed off its Orion AR glasses prototype. After trying out both, it’s easy to see why these companies have invested so much time and money on these projects. To be clear, both companies still have a lot of work ahead of them if they want their AR glasses to turn into a product their users will want to actually buy. Right now, the components are still too expensive, and the glasses are way too bulky (this is especially true for Snap, if the social media reactions to my selfies are any indication). But after years of hearing little more than lofty promises and sporadic research updates, we finally saw real progress.
Snap has lined up dozens of developers, including Niantic, Lego and Industrial Light and Magic who are already building apps for AR. Meta is, for now, keeping its AR work internal, but its neural wristband — which may be coming to a future pair of its RayBan-branded glasses — feels like a game-changer for next-gen controllers. So while AR glasses aren’t ready to replace our phones just yet, it’s getting a lot easier to imagine a world in which they might. — K.B.
ASUS Zenbook Duo
The classic clamshell with a screen up top and a physical keyboard down below isn’t going away anytime soon. But this year, the Zenbook Duo showed that laptops still have plenty of room for improvement. That’s because after multiple attempts by various manufacturers to refine and streamline dual-screen laptops, ASUS finally put everything together into a single cohesive package with the Zenbook Duo. It packs not one but two 14-inch OLED displays with 120Hz refresh rates, solid performance, a surprisingly good selection of ports (including full-size HDMI) and a built-in kickstand. And weighing 3.6 pounds and measuring 0.78 inches at its thickest, it’s not much bigger or heftier than more traditional rivals.
You also get a physical keyboard, except this one connects wirelessly via Bluetooth and can be either placed on top of the lower screen like a normal laptop or moved practically anywhere you want. This allows the Zenbook Duo to transform into something like a portable all-in-one complete with two stacked displays, which are truly excellent for multitasking. And because the keyboard also charges wirelessly, you never have to worry about keeping it topped off. But the best part is that starting at $1,500, it doesn’t cost that much more than a typical premium notebook either, so even when you’re traveling you never have to be limited to a single, tiny display. — S.R.
DJI Neo
DJI’s tiny $200 Neo drone blew into the content creator market like a tornado. It was relatively cheap and simple to use, allowing beginners to create stunning aerial video at the touch of a button, while taking off and landing on their palms. At the same time, the Neo offered advanced features like manual piloting with a phone or controller, subject tracking and even impressive acrobatics.
Weighing just 156 grams and equipped with people-safe propeller guards, DJI’s smallest drone can be piloted nearly anywhere with no permit needed. And unlike Snap’s Pixy drone, it’s far more than a toy.. It can fly at speeds up to 36 mph and perform tricks like flips and slides. It also offers reasonably high-quality 4K 30p video. All of that allows creators to track themselves when walking, biking or vlogging, adding high-quality aerial video that was previously inaccessible for most.
There are some negative points. The Neo lacks any obstacle detection sensors, so you need to be careful when flying it to avoid crashes. Video quality isn’t quite as good as slightly more expensive drones like the DJI Mini 3. And the propeller noise is pretty offensive if you plan to operate it around a lot of people. Perhaps the biggest problem is that DJI’s products might be banned in the US by 2026, even though it escaped that fate this year.
For $200, though, it offers excellent value and opens up new creative possibilities for content creators. Much like the company’s incredibly popular Osmo Pocket 3, the Neo shows how DJI is innovating in the creator space to a higher level than rivals like Sony or Canon. — Steve Dent, contributing writer
reMarkable Paper Pro
reMarkable’s distraction-free writing slates have always offered an elegant alternative to other tablets. The second generation model is great, but the advent of the Paper Pro has highlighted where that device was lacking. It’s certainly one of the best pieces of hardware I’ve tested this year and, if I owned one, I’d likely make it a key part of my daily workflow. The bigger display, faster internals and the fact it can now render colors elevates it above the competition. It’s gone from a useful tool to an essential one, especially if you need to wrench yourself away from the distractions of the internet.
It’s still far too expensive for what it is, and qualifies as a luxury purchase in these straightened times. It won’t stack up in a spec-for-spec comparison to an iPad, even if they’re clearly catering for two very different audiences. But, judging it on its merits as a piece of technology, it does the job it was built to do far better than anything else on the market. What can I say, I just think it’s neat. — Daniel Cooper, senior reporter
NotebookLM
Maybe my AI dalliances are far too mundane – I spend more time trying to get worthwhile shopping advice from Claude and ChatGPT, for instance, rather than playing around with music generators like Suno or even image creators like Dall-E. But for this podcast fan, it’s Google’s NotebookLM that was the big AI revelation of 2024.
The audio offshoot of Google’s Project Tailwind, an AI-infused notebook application, NotebookLM synthesizes a full-on podcast that summarizes the documents, videos or links you feed it. Delivered as a dialogue between male and female co-hosts, it feels like a next-gen two-person version of the Duplex software agent that Google unveiled in 2018. The resulting audio stories (just a few minutes in length) wouldn’t sound terribly out of place on your local NPR station, right down to copious use of “ums,” “ahs,” pauses and co-hosts talking over each other with a relevant detail or two. Yes, it doesn’t have any more depth than the chatter on the average TV morning show, occasionally botches pronunciation – sometimes spelling out common acronyms letter by letter, for instance – and it’s just as prone to hallucinations as any other current AI model. And I certainly don’t think real podcast hosts have anything to fear here (at least, not yet.)
But to me, NotebookLM doesn’t feel like the rest of the AI slop that’s invading the web these days. It’s a win on three fronts: The baseline version is free, it’s dead simple to use (just feed it one or more links, or a blob of text) – and it can be downright fun. This was the system’s take when I fed it the full text of Moby Dick, for example – and that’s small potatoes compared to, say, the hosts “discovering” they’re not human. Thankfully, unlike the plethora of projects that Google summarily kills off, NotebookLM seems to be flourishing. I haven’t tried the new “phone in” feature or the paid Plus subscription, but both suggest that we’ll be hearing more from Audio Overviews in 2025. — John Falcone, executive editor
PC CPU competition heats up
For the past decade, the story around laptop and desktop CPUs has basically been a back and forth between Intel and AMD. At times, AMD’s sheer ambition and aggressive pricing would make its chips the PC enthusiast choice, but then Intel would also hit back with innovations like its 12th-gen hybrid processors. When Apple decided to move away from Intel’s chips in 2020, and proved that its own mobile Arm architecture could dramatically outpace x86 and x64 designs, it was clear that the industry was ready to shift beyond the AMD and Intel rivalry.
So it really was only a matter of time until Qualcomm followed in Apple’s footsteps and released its Snapdragon X Elite chips, which powered the new Surface Pro, Surface Laptop and other Copilot+ PCs. Those mobile chips were faster than ever before, far more efficient than Intel and AMD’s best, and they were aided by some timely Windows on Arm improvements. While you may still run into some older Windows apps that don’t run on Arm machines, the experience today is dramatically better than it was just a few years ago.
LG is bringing a lamp that doubles as a small garden to CES 2025. The “indoor gardening appliance” is designed for apartment dwellers or anyone whose otherwise backyard-challenged to enjoy the benefits of homegrown produce.
During the day, LG says the lamp with a circular lampshade shines LEDs in five different intensities on whichever plants you want to grow. Then, at night, the lights fire upwards to create cozy mood lighting in whatever room you put the lamp in. If you’d prefer something that’s more compact and armchair-height, LG also has a version that the size of a side table.
LG
The taller, standing lamp can hold up to 20 plants at a time, according to LG, and the whole setup is height adjustable so that you can accommodate larger leafy greens or small herbs and flowers. The real beauty of LG’s design, though, is that you don’t need to worry about watering. There’s a 1.5 gallon tank built in to the base of the lamp that can disperse the appropriate amount of liquid for whatever you have planted. Both lamps are also connected to LG’s ThinQ app so you can adjust lighting and watering schedules remotely.
LG introduced its previous take on an indoor gardening tool, the LG Tiiun, at CES 2022. That larger, fridge-shaped appliance could also automatically grow and water plants, but was far less aesthetically-pleasing than the company’s new lamp. With all of the features it has on board, LG’s new lamp is really just one Sonos speaker away from being the ultimate living room appliance. At least until tech companies find another use for lamps.
LG’s new indoor gardening appliance doesn’t have a release date or an official price, but expect the company to share more details once CES 2025 officially starts.
This article originally appeared on Engadget at https://www.engadget.com/home/smart-home/lg-found-a-new-job-for-your-standing-lamp-173446654.html?src=rss
Understanding loss functions for training neural networks
Machine learning is very hands-on, and everyone charts their own path. There isn’t a standard set of courses to follow, as was traditionally the case. There’s no ‘Machine Learning 101,’ so to speak. However, this sometimes leaves gaps in understanding. If you’re like me, these gaps can feel uncomfortable. For instance, I used to be bothered by things we do casually, like the choice of a loss function. I admit that some practices are learned through heuristics and experience, but most concepts are rooted in solid mathematical foundations. Of course, not everyone has the time or motivation to dive deeply into those foundations — unless you’re a researcher.
I have attempted to present some basic ideas on how to approach a machine learning problem. Understanding this background will help practitioners feel more confident in their design choices. The concepts I covered include:
Quantifying the difference in probability distributions using cross-entropy.
A probabilistic view of neural network models.
Deriving and understanding the loss functions for different applications.
Entropy
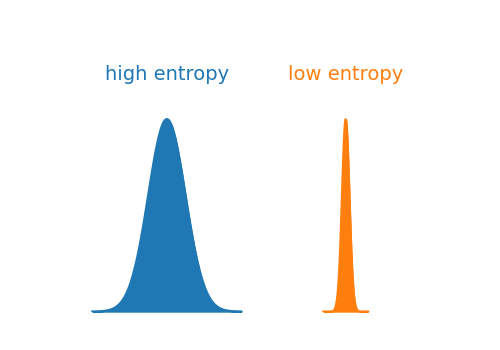
In information theory, entropy is a measure of the uncertainty associated with the values of a random variable. In other words, it is used to quantify the spread of distribution. The narrower the distribution the lower the entropy and vice versa. Mathematically, entropy of distribution p(x) is defined as;
It is common to use log with the base 2 and in that case entropy is measured in bits. The figure below compares two distributions: the blue one with high entropy and the orange one with low entropy.
Visualization examples of distributions having high and low entropy — created by the author using Python.
We can also measure entropy between two distributions. For example, consider the case where we have observed some data having the distribution p(x) and a distribution q(x) that could potentially serve as a model for the observed data. In that case we can compute cross-entropy Hpq(X) between data distribution p(x) and the model distribution q(x). Mathematically cross-entropy is written as follows:
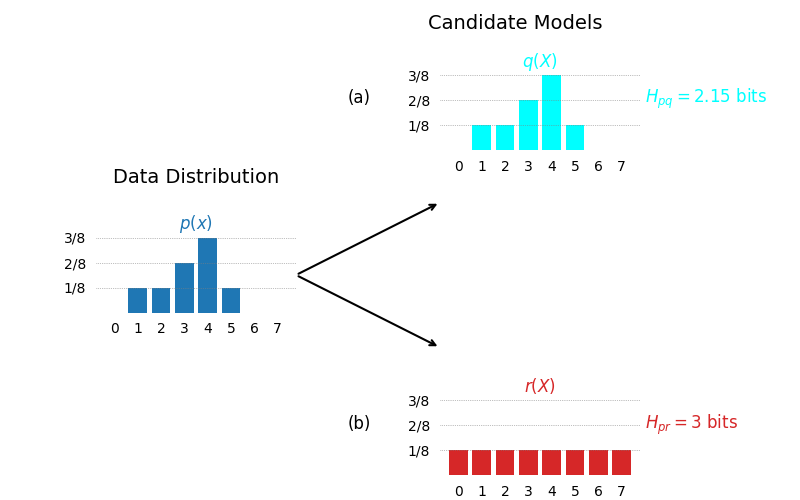
Using cross entropy we can compare different models and the one with lowest cross entropy is better fit to the data. This is depicted in the contrived example in the following figure. We have two candidate models and we want to decide which one is better model for the observed data. As we can see the model whose distribution exactly matches that of the data has lower cross entropy than the model that is slightly off.
Comparison of cross entropy of data distribution p(x) with two candidate models. (a) candidate model exactly matches data distribution and has low cross entropy. (b) candidate model does not match the data distribution hence it has high cross entropy — created by the author using Python.
There is another way to state the same thing. As the model distribution deviates from the data distribution cross entropy increases. While trying to fit a model to the data i.e. training a machine learning model, we are interested in minimizing this deviation. This increase in cross entropy due to deviation from the data distribution is defined as relative entropy commonly known as Kullback-Leibler Divergence of simply KL-Divergence.
Hence, we can quantify the divergence between two probability distributions using cross-entropy or KL-Divergence. To train a model we can adjust the parameters of the model such that they minimize the cross-entropy or KL-Divergence. Note that minimizing cross-entropy or KL-Divergence achieves the same solution. KL-Divergence has a better interpretation as its minimum is zero, that will be the case when the model exactly matches the data.
Another important consideration is how do we pick the model distribution? This is dictated by two things: the problem we are trying to solve and our preferred approach to solving the problem. Let’s take the example of a classification problem where we have (X, Y) pairs of data, with X representing the input features and Y representing the true class labels. We want to train a model to correctly classify the inputs. There are two ways we can approach this problem.
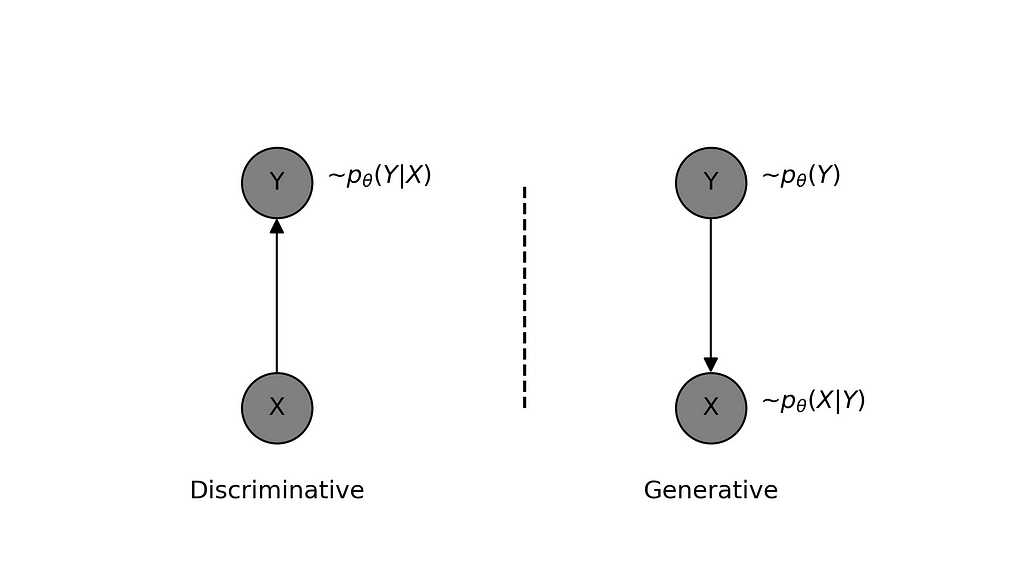
Discriminative vs Generative
The generative approach refers to modeling the joint distribution p(X,Y) such that it learns the data-generating process, hence the name ‘generative’. In the example under discussion, the model learns the prior distribution of class labels p(Y) and for given class label Y, it learns to generate features X using p(X|Y).
It should be clear that the learned model is capable of generating new data (X,Y). However, what might be less obvious is that it can also be used to classify the given features X using Bayes’ Rule, though this may not always be feasible depending on the model’s complexity. Suffice it to say that using this for a task like classification might not be a good idea, so we should instead take the direct approach.
Discriminative vs generative approach of modelling — created by the author using Python.
Discriminative approach refers to modelling the relationship between input features X and output labels Y directly i.e. modelling the conditional distribution p(Y|X). The model thus learnt need not capture the details of features X but only the class discriminatory aspects of it. As we saw earlier, it is possible to learn the parameters of the model by minimizing the cross-entropy between observed data and model distribution. The cross-entropy for a discriminative model can be written as:
Where the right most sum is the sample average and it approximates the expectation w.r.t data distribution. Since our learning rule is to minimize the cross-entropy, we can call it our general loss function.
Goal of learning (training the model) is to minimize this loss function. Mathematically, we can write the same statement as follows:
Let’s now consider specific examples of discriminative models and apply the general loss function to each example.
Binary Classification
As the name suggests, the class label Y for this kind of problem is either 0 or 1. That could be the case for a face detector, or a cat vs dog classifier or a model that predicts the presence or absence of a disease. How do we model a binary random variable? That’s right — it’s a Bernoulli random variable. The probability distribution for a Bernoulli variable can be written as follows:
where π is the probability of getting 1 i.e. p(Y=1) = π.
Since we want to model p(Y|X), let’s make π a function of X i.e. output of our model π(X) depends on input features X. In other words, our model takes in features X and predicts the probability of Y=1. Please note that in order to get a valid probability at the output of the model, it has to be constrained to be a number between 0 and 1. This is achieved by applying a sigmoid non-linearity at the output.
To simplify, let’s rewrite this explicitly in terms of true label and predicted label as follows:
We can write the general loss function for this specific conditional distribution as follows:
This is the commonly referred to as binary cross entropy (BCE) loss.
Multi-class Classification
For a multi-class problem, the goal is to predict a category from C classes for each input feature X.In this case we can model the output Y as a categorical random variable, a random variable that takes on a state c out of all possible C states. As an example of categorical random variable, think of a six-faced die that can take on one of six possible states with each roll.
We can see the above expression as easy extension of the case of binary random variable to a random variable having multiple categories. We can model the conditional distribution p(Y|X) by making λ’s as function of input features X. Based on this, let’s we write the conditional categorical distribution of Y in terms of predicted probabilities as follows:
Using this conditional model distribution we can write the loss function using the general loss function derived earlier in terms of cross-entropy as follows:
This is referred to as Cross-Entropy loss in PyTorch. The thing to note here is that I have written this in terms of predicted probability of each class. In order to have a valid probability distribution over all C classes, a softmax non-linearity is applied at the output of the model. Softmax function is written as follows:
Regression
Consider the case of data (X, Y) where X represents the input features and Y represents output that can take on any real number value. Since Y is real valued, we can model the its distribution using a Gaussian distribution.
Again, since we are interested in modelling the conditional distribution p(Y|X). We can capture the dependence on X by making the conditional mean of Y a function of X. For simplicity, we set variance equal to 1. The conditional distribution can be written as follows:
We can now write our general loss function for this conditional model distribution as follows:
This is the famous MSE loss for training the regression model. Note that the constant factor is irrelevant here as we are only interest in finding the location of minima and can be dropped.
Summary
In this short article, I introduced the concepts of entropy, cross-entropy, and KL-Divergence. These concepts are essential for computing similarities (or divergences) between distributions. By using these ideas, along with a probabilistic interpretation of the model, we can define the general loss function, also referred to as the objective function. Training the model, or ‘learning,’ then boils down to minimizing the loss with respect to the model’s parameters. This optimization is typically carried out using gradient descent, which is mostly handled by deep learning frameworks like PyTorch. Hope this helps — happy learning!
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.