A set of new requirements proposed by the US Department of Health and Human Services’ (HHS) Office for Civil Rights could bring healthcare organizations up to par with modern cybersecurity practices. The proposal, posted to the Federal Register on Friday, includes requirements for multifactor authentication, data encryption and routine scans for vulnerabilities and breaches. It would also make the use of anti-malware protection mandatory for systems handling sensitive information, along with network segmentation, the implementation of separate controls for data backup and recovery, and yearly audits to check for compliance.
HHS also shared a fact sheet outlining the proposal, which would update the Health Insurance Portability and Accountability Act of 1996 (HIPAA) Security Rule. A 60-day public comment period is expected to open soon. In a press briefing, US deputy national security advisor for cyber and emerging technology Anne Neuberger said the plan would cost $9 billion in the first year to execute, and $6 billion over the subsequent four years, Reuters reports. The proposal comes in light of a marked increase in large-scale breaches over the past few years. Just this year, the healthcare industry was hit by multiple major cyberattacks, including hacks into Ascension and UnitedHealth systems that caused disruptions at hospitals, doctors’ offices and pharmacies.
“From 2018-2023, reports of large breaches increased by 102 percent, and the number of individuals affected by such breaches increased by 1002 percent, primarily because of increases in hacking and ransomware attacks,” according to the Office for Civil Rights. “In 2023, over 167 million individuals were affected by large breaches — a new record.”
This article originally appeared on Engadget at https://www.engadget.com/cybersecurity/healthcare-organizations-in-the-us-may-soon-get-a-cybersecurity-overhaul-220933165.html?src=rss
Consumer electronics and iPhone accessory maker Zagg is letting customers know that credit card transactions between October 26 and November 7, 2024 may have been compromised due to a hack of a third-party payment processor.
Zagg’s customer information has been compromised via a third-party hack.
Zagg, based in Utah, makes products such as keyboards, phone cases, screen protectors, power banks, and other accessories. It uses BigCommerce to process credit card transactions on its website, which also provides an app called FreshClicks for creating commerce-friendly websites.
It was discovered that an attacker was able to breach the FreshClicks app, injecting malicious code that stole customers’ card details, reportsBeepingComputer.
The recent crop of Google Pixel phones can be located on the Find My Device map even if they’ve gone offline. Samsung’s flagship could skip on the convenience.
NASA said on Friday that it received a signal from the Parker Solar Probe confirming that the spacecraft had survived its closest ever flyby of the sun. The approach took it just 3.8 million miles from the surface, passing within the sun’s corona and allowing for unprecedented data collection in the vicinity of a star. A few million miles might seem like a pretty great distance, but to put things in perspective, NASA explains, “If the solar system was scaled down with the distance between the sun and Earth the length of a football field, Parker Solar Probe would be just four yards from the end zone.”
The probe’s current orbit takes it closest to the sun about every three months. It’ll swing back around for two more close flybys in 2025, on March 22 and June 19. The probe is expected to transmit the data from its latest close approach soon, once it’s in a better location to do so. “The data that will come down from the spacecraft will be fresh information about a place that we, as humanity, have never been,” said Joe Westlake, the director of the Heliophysics Division at NASA Headquarters. “It’s an amazing accomplishment.”
This article originally appeared on Engadget at https://www.engadget.com/science/space/parker-solar-probe-survived-its-close-approach-to-the-sun-and-will-make-two-more-in-2025-180350510.html?src=rss
Netflix? More like Netfix – world’s most popular streaming service is tied at the neck with its biggest rival, and doesn’t even know how much it spends on cloud computing
Originally appeared here:
Netflix? More like Netfix – world’s most popular streaming service is tied at the neck with its biggest rival, and doesn’t even know how much it spends on cloud computing
Python provides three main approaches to handle multiple tasks simultaneously: multithreading, multiprocessing, and asyncio.
Choosing the right model is crucial for maximising your program’s performance and efficiently using system resources. (P.S. It is also a common interview question!)
Without concurrency, a program processes only one task at a time. During operations like file loading, network requests, or user input, it stays idle, wasting valuable CPU cycles. Concurrency solves this by enabling multiple tasks to run efficiently.
But which model should you use? Let’s dive in!
Contents
Fundamentals of concurrency – Concurrency vs parallelism – Programs – Processes – Threads – How does the OS manage threads and processes?
Before jumping into Python’s concurrency models, let’s recap some foundational concepts.
1. Concurrency vs Parallelism
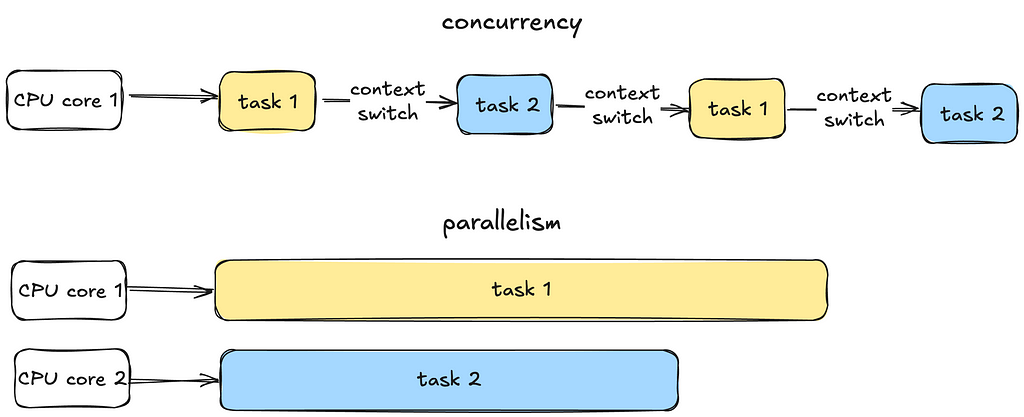
Visual representation of concurrency vs parallelism (drawn by me)
Concurrency is all about managing multiple tasks at the same time, not necessarily simultaneously. Tasks may take turns, creating the illusion of multitasking.
Parallelism is about running multiple tasks simultaneously, typically by leveraging multiple CPU cores.
2. Programs
Now let’s move on to some fundamental OS concepts — programs, processes and threads.
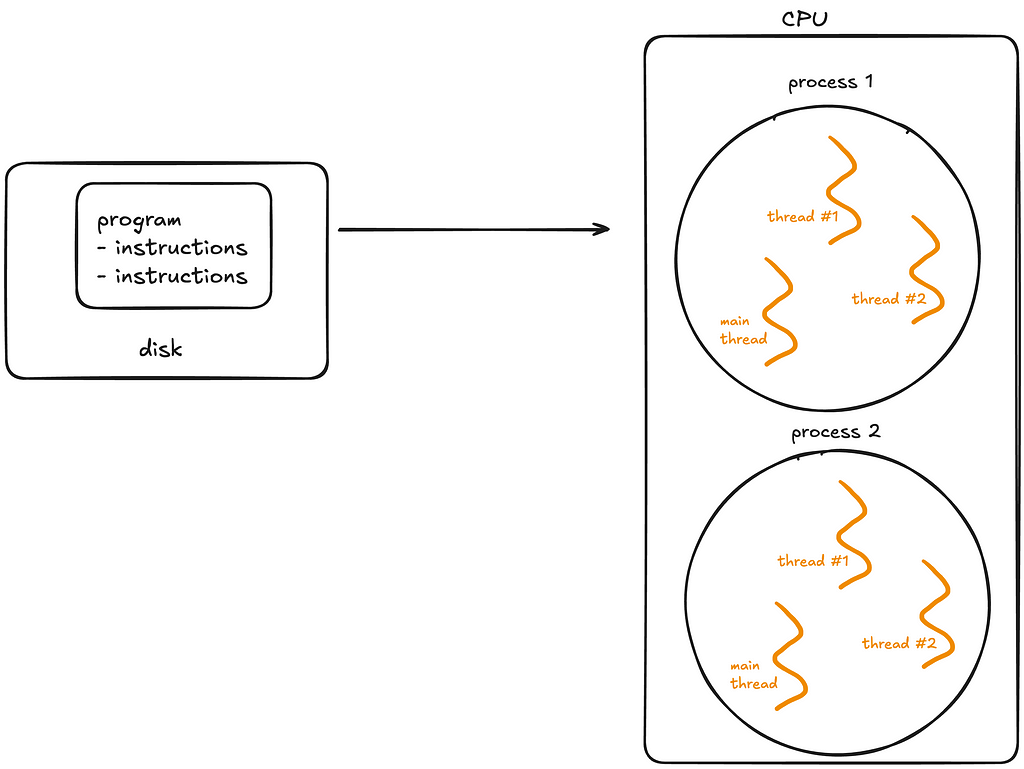
Multiple threads can exist simultaneously within the a single process — known as multithreading (drawn by me)
A program is simply a static file, like a Python script or an executable.
A program sits on disk, and is passive until the operating system (OS) loads it into memory to run. Once this happens, the program becomes a process.
3. Processes
A process is an independent instance of a running program.
A process has its own memory space, resources, and execution state. Processes are isolated from each other, meaning one process cannot interfere with another unless explicitly designed to do so via mechanisms like inter-process communication (IPC).
Processes can generally be categorised into two types:
I/O-bound processes: Spend most of it’s time waiting for input/output operations to complete, such as file access, network communication, or user input. While waiting, the CPU sits idle.
CPU-bound processes: Spend most of their time doing computations (e.g video encoding, numerical analysis). These tasks require a lot of CPU time.
Lifecycle of a process:
A process starts in a new state when created.
It moves to the ready state, waiting for CPU time.
If the process waits for an event like I/O, it enters the waiting state.
Finally, it terminates after completing its task.
4. Threads
A thread is the smallest unit of execution within a process. A process acts as a “container” for threads, and multiple threads can be created and destroyed over the process’s lifetime.
Every process has at least one thread — the main thread— but it can also create additional threads.
Threads share memory and resources within the same process, enabling efficient communication. However, this sharing can lead to synchronisation issues like race conditions or deadlocks if not managed carefully. Unlike processes, multiple threads in a single process are not isolated — one misbehaving thread can crash the entire process.
5. How does the OS manage threads and processes?
The CPU can execute only one task per core at a time. To handle multiple tasks, the operating system uses preemptive context switching.
During a context switch, the OS pauses the current task, saves its state and loads the state of the next task to be executed.
This rapid switching creates the illusion of simultaneous execution on a single CPU core.
For processes, context switching is more resource-intensive because the OS must save and load separate memory spaces. For threads, switching is faster because threads share the same memory within a process. However, frequent switching introduces overhead, which can slow down performance.
True parallel execution of processes can only occur if there are multiple CPU cores available. Each core handles a separate process simultaneously.
Python’s concurrency models
Let’s now explore Python’s specific concurrency models.
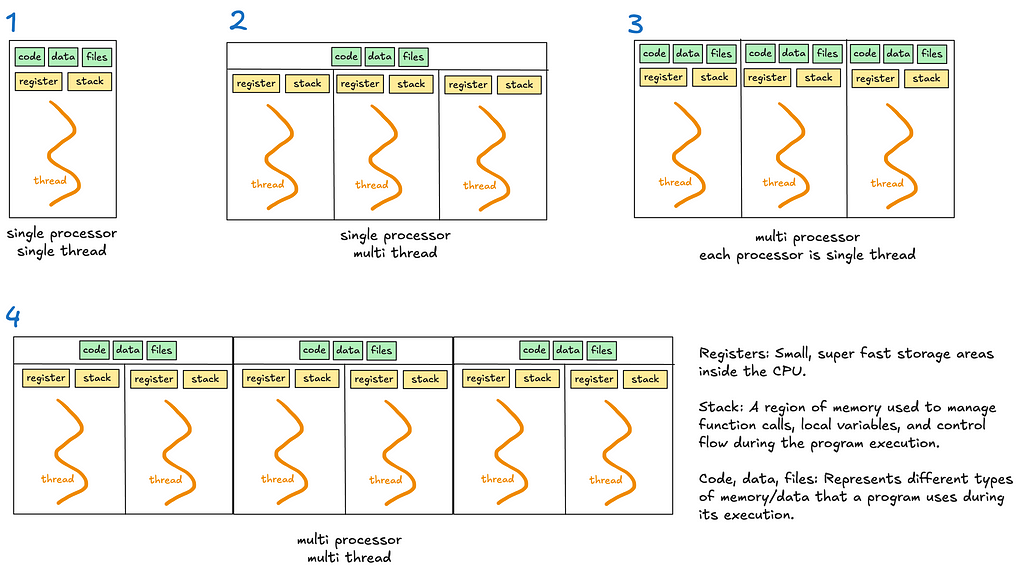
Summary of the different concurrency models (drawn by me)
1. Multithreading
Multithreading allows a process to execute multiple threads concurrently, with threads sharing the same memory and resources (see diagrams 2 and 4).
However, Python’s Global Interpreter Lock (GIL) limits multithreading’s effectiveness for CPU-bound tasks.
Python’s Global Interpreter Lock (GIL)
The GIL is a lock that allows only one thread to hold control of the Python interpreter at any time, meaning only one thread can execute Python bytecode at once.
The GIL was introduced to simplify memory management in Python as many internal operations, such as object creation, are not thread safe by default. Without a GIL, multiple threads trying to access the shared resources will require complex locks or synchronisation mechanisms to prevent race conditions and data corruption.
When is GIL a bottleneck?
For single threaded programs, the GIL is irrelevant as the thread has exclusive access to the Python interpreter.
For multithreaded I/O-bound programs, the GIL is less problematic as threads release the GIL when waiting for I/O operations.
For multithreaded CPU-bound operations, the GIL becomes a significant bottleneck. Multiple threads competing for the GIL must take turns executing Python bytecode.
An interesting case worth noting is the use of time.sleep, which Python effectively treats as an I/O operation. The time.sleep function is not CPU-bound because it does not involve active computation or the execution of Python bytecode during the sleep period. Instead, the responsibility of tracking the elapsed time is delegated to the OS. During this time, the thread releases the GIL, allowing other threads to run and utilise the interpreter.
2. Multiprocessing
Multiprocessing enables a system to run multiple processes in parallel, each with its own memory, GIL and resources. Within each process, there may be one or more threads (see diagrams 3 and 4).
Multiprocessing bypasses the limitations of the GIL. This makes it suitable for CPU bound tasks that require heavy computation.
However, multiprocessing is more resource intensive due to separate memory and process overheads.
3. Asyncio
Unlike threads or processes, asyncio uses a single thread to handle multiple tasks.
When writing asynchronous code with the asyncio library, you’ll use the async/await keywords to manage tasks.
Key concepts
Coroutines: These are functions defined with async def . They are the core of asyncio and represent tasks that can be paused and resumed later.
Event loop: It manages the execution of tasks.
Tasks: Wrappers around coroutines. When you want a coroutine to actually start running, you turn it into a task — eg. using asyncio.create_task()
await : Pauses execution of a coroutine, giving control back to the event loop.
How it works
Asyncio runs an event loop that schedules tasks. Tasks voluntarily “pause” themselves when waiting for something, like a network response or a file read. While the task is paused, the event loop switches to another task, ensuring no time is wasted waiting.
This makes asyncio ideal for scenarios involving many small tasks that spend a lot of time waiting, such as handling thousands of web requests or managing database queries. Since everything runs on a single thread, asyncio avoids the overhead and complexity of thread switching.
The key difference between asyncio and multithreading lies in how they handle waiting tasks.
Multithreading relies on the OS to switch between threads when one thread is waiting (preemptive context switching). When a thread is waiting, the OS switches to another thread automatically.
Asyncio uses a single thread and depends on tasks to “cooperate” by pausing when they need to wait (cooperative multitasking).
2 ways to write async code:
method 1: await coroutine
When you directly await a coroutine, the execution of the current coroutine pauses at the await statement until the awaited coroutine finishes. Tasks are executed sequentially within the current coroutine.
Use this approach when you need the result of the coroutineimmediately to proceed with the next steps.
Although this might sound like synchronous code, it’s not. In synchronous code, the entire program would block during a pause.
With asyncio, only the current coroutine pauses, while the rest of the program can continue running. This makes asyncio non-blocking at the program level.
Example:
The event loop pauses the current coroutine until fetch_data is complete.
async def main(): result = await fetch_data() # Current coroutine pauses here print(f"Result: {result}")
asyncio.run(main())
method 2: asyncio.create_task(coroutine)
The coroutine is scheduled to run concurrently in the background. Unlike await, the current coroutine continues executing immediately without waiting for the scheduled task to finish.
The scheduled coroutine starts running as soon as the event loop finds an opportunity, without needing to wait for an explicit await.
No new threads are created; instead, the coroutine runs within the same thread as the event loop, which manages when each task gets execution time.
This approach enables concurrency within the program, allowing multiple tasks to overlap their execution efficiently. You will later need to await the task to get it’s result and ensure it’s done.
Use this approach when you want to run tasks concurrently and don’t need the results immediately.
Example:
When the line asyncio.create_task() is reached, the coroutine fetch_data() is scheduled to start running immediately when the event loop is available. This can happen even before you explicitly await the task. In contrast, in the first await method, the coroutine only starts executing when the await statement is reached.
Overall, this makes the program more efficient by overlapping the execution of multiple tasks.
async def main(): # Schedule fetch_data task = asyncio.create_task(fetch_data()) # Simulate doing other work await asyncio.sleep(5) # Now, await task to get the result result = await task print(result)
asyncio.run(main())
Other important points
You can mix synchronous and asynchronous code. Since synchronous code is blocking, it can be offloaded to a separate thread using asyncio.to_thread(). This makes your program effectively multithreaded. In the example below, the asyncio event loop runs on the main thread, while a separate background thread is used to execute the sync_task.
import asyncio import time
def sync_task(): time.sleep(2) return "Completed"
async def main(): result = await asyncio.to_thread(sync_task) print(result)
asyncio.run(main())
You should offload CPU-bound tasks which are computationally intensive to a separate process.
When should I use which concurrency model?
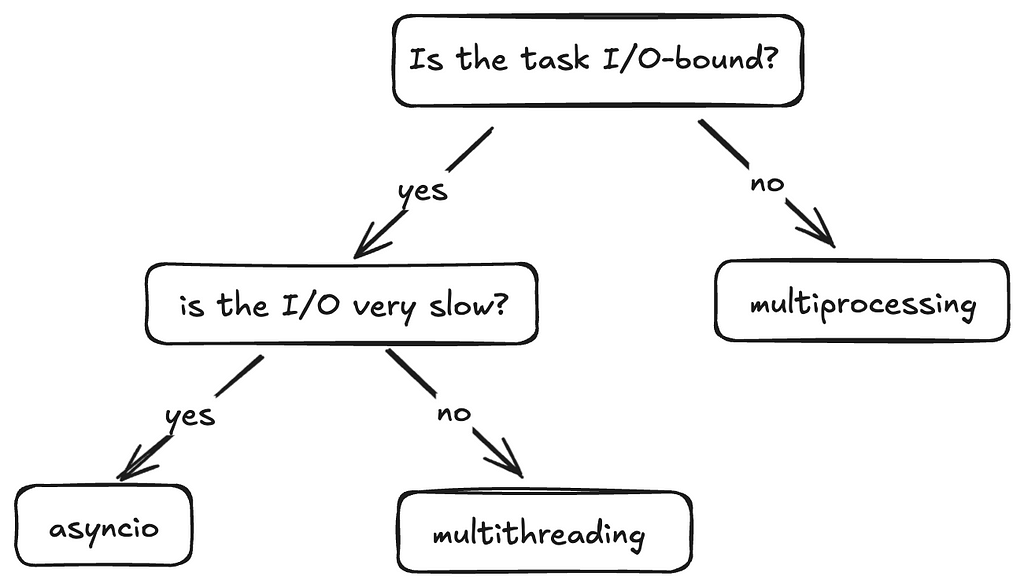
This flow is a good way to decide when to use what.
Flowchart (drawn by me), referencing this stackoverflow discussion
Multiprocessing – Best for CPU-bound tasks which are computationally intensive. – When you need to bypass the GIL — Each process has it’s own Python interpreter, allowing for true parallelism.
Multithreading – Best for fast I/O-bound tasks as the frequency of context switching is reduced and the Python interpreter sticks to a single thread for longer – Not ideal for CPU-bound tasks due to GIL.
Asyncio – Ideal for slow I/O-bound tasks such as long network requests or database queries because it efficiently handles waiting, making it scalable. – Not suitable for CPU-bound tasks without offloading work to other processes.
Wrapping up
That’s it folks. There’s a lot more that this topic has to cover but I hope I’ve introduced to you the various concepts, and when to use each method.
Thanks for reading! I write regularly on Python, software development and the projects I build, so give me a follow to not miss out. See you in the next article 🙂
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.