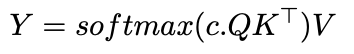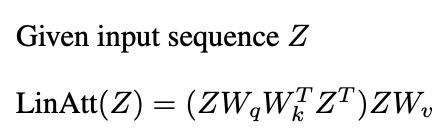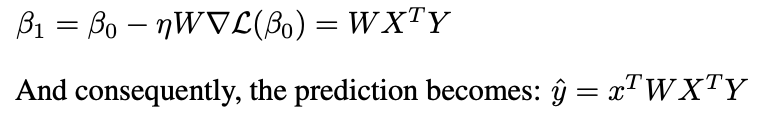But a few areas this year stood out as particularly troubling. Specifically, AI and dedicated AI gadgets proliferated more than ever, spreading not only to our digital assistants and search engines but to our wearables as well. We also saw more deterioration in Intel’s standing and bid farewell to a robot maker, as well as Lightning cables. I’m pretty happy about that last one, though.
Our annual collection of the worst tech developments each year is shorter than usual, but that might be because we’re all exhausted. And also because most of the bad things can be attributed to AI, social media or misinformation. Still, we journey down this nightmarish memory lane, hopefully so we can avoid similar pitfalls in future.
Generative AI in every possible crevice
2024 was a year in which consumer-facing AI tools became harder and harder to ignore. That’s thanks to the tech giants Google, Meta and finally Apple baking AI tools into some of the most-used software on the planet. And in this push to get AI in front of everyone, I cannot help but stop and wonder who exactly is asking for this, and is anyone actually using it?
In the past few months, I’ve been testing a Samsung Chromebook with a host of AI tools built-in as well as trying the various Apple Intelligence features that have rolled out through the autumn. It all came to a head in one of Engadget’s Slack channels in early December, just after Apple launched its generative emoji and Image Playground features. Getting Image Playground to spit out AI-created pictures was easy enough, and Genmoji does feel like the logical next step after Apple introduced its personalized Memoji back in 2018. But across the board, the results felt uninspired, off-putting and -— perhaps worst of all -— extremely lame.
Since I take so many pictures on my iPhone, there are tons of images categorized under my name in the Photos app (it will group together similar faces for years, if you let it). With hundreds of images to pick from, Image Playground should have no problem making a convincing facsimile of me… playing the guitar on the moon, right? Well, yes and no.
In this image, as well as ones created of my colleagues Cherlynn Low, Valentina Palladino and Sam Rutherford, there are a few facial characteristics that made me feel that the AI-generated cartoon I was looking at was at the very least inspired by these people. But they all gave off serious uncanny valley vibes; rather than being a cute digital cartoon like we all built with Bitmoji back in the day, these results are soulless representations with no charm and mangled fingers.
In a totally different vein, I just had occasion to try out Google’s “help me read” summarization features on a 250-page government report. I knew I did not have time to read the entire document and was just curious what AI could do for me here. Turns out, not much. The summary was so brief that it was essentially meaningless — not unreasonable, as it tried to parse 250 pages into about 100 words. I tried this trick on a review I was writing recently, and it did a much better job of capturing the gist of the article, and it also accurately answered follow-up questions. But given that the final product amounted to maybe four pages, my impression is that AI does a decent job of summarizing things that most people can probably read themselves in the span of five minutes. If you have something more complex, forget it.
I could go on — I’ve been having a blast laughing at the ridiculous notification summaries I get from Apple Intelligence with my co-workers — but I think I’ve made my point. We’re in the middle of an AI arms race, where massive companies are desperate to get out ahead of the curve with these products well before they’re ready for primetime or even all that useful. And to what end? I don’t think any AI company is meaningfully answering a consumer need or finding a way to make people’s lives better or easier. They’re releasing this stuff because AI is the buzzword of the decade, and to ignore it is to disappoint shareholders. — Nathan Ingraham, deputy editor
Photo by Cherlynn Low / Engadget
Humane AI Pin and other AI gadgets
This year, no two devices arrived with more manufactured hype than the Humane AI Pin and Rabbit R1. And no two devices were more disappointing either. Both Humane and Rabbit made the argument that people were ready to drop their phones for something smarter and more personal, but neither of their devices were actually good or useful.
Of the two, Humane was easily the biggest loser of 2024. The company achieved the ignominious honor of reaching net negative sales because former buyers began returning the AI Pin faster than new units could be sold. I wish I could say its troubles stopped there, but they didn’t. After Humane first warned customers that the AI Pin’s charging case was a fire risk, it issued a formal recall in October. In the intervening months, the company has reportedly tried to find a buyer without success.
Rabbit has certainly faced its own share of troubles, too. After being roundly panned by reviewers in May, a hacker group announced in June that the R1 had huge security holes. In July, it came to light that user chats with the R1 were logged with no option for deleting.
Last I checked, Humane has since pivoted to making an operating system that it expects other companies will want to add to their devices, but here’s the thing: poor software was a big part of what made the AI Pin bad in the first place. You have to give the company points for trying, but at this point, I would be surprised if Humane is still in business by this time next year. — Igor Bonifacic, senior reporter
Google Search and AI Overviews
This observation has been making the rounds all year long, but if you compare Google from 10 years ago to what it is now, the difference is stark. With the introduction of AI Overviews this year, it felt like Google finally made search results utterly impossible to use without scrolling. Forget sponsored results, newsboxes and discovery panels and all the different modules taking up the top half of the results page for any given query — in 2024, Google decided to add yet another section above everything, pushing the actual list of websites even further down.
Not only that, it also began to add ads to Overviews, meaning that in addition to the unreliable AI-generated results at the top, people could pay to put what they want to promote in that precious real estate, too. Throw in the fact that the actual results boxes and rankings are all susceptible to SEO gaming by websites trying everything they can to garner a higher spot on the list, and you’ll find that Google’s search results are basically pay-for-play at this point. And while that will continue to earn the company billions of dollars, it makes finding actually good, high-quality results much more arduous for the discerning user.
It gets worse when you consider the priority Google’s search engine has on iPhones and Android devices. This year, the US government declared Google a search monopoly, saying the company paid the likes of Apple, Samsung and Mozilla billions of dollars a year to be the default search engine on their devices and browsers. Then there’s Chrome, which is the world’s most popular browser with its own dubious history around tracking users in Incognito mode. Can we even trust what we see on Google Search any more?
People have begun to quit using Google Search altogether, with the rise of alternatives like DuckDuckGo and Kagi, a search engine you’d pay $10 a month to use, as well as OpenAI’s SearchGPT, which launched this year. But I’m not convinced that the vast majority of users will switch to these options, especially since one of them costs money and another involves more AI. I can understand that it’s hard to make a product that adapts to your users’ needs while also keeping your shareholders happy. If only Google (or any big company, really) could re-rank its priorities and bring back a search engine that simply connects people to the best that the internet has to offer. — Cherlynn Low, deputy editor
Intel
The road to every great tragedy is paved with people making the most self-serving decisions at the worst possible times. Which brings us neatly to Intel as it burns through its last remaining chances to avoid becoming a business school case study in failure.
Earlier this month, it fired CEO Pat Gelsinger halfway through his ambitious plan to save the chip giant from its own worst instincts. Gelsinger was an engineer, brought in to fix a culture too beholdened to finance types who can’t see beyond the next quarter.
Sadly, despite telling everyone that fixing two decades’ worth of corporate fuck-ups would take a while and cost money, it came as a surprise to Intel’s board. It ditched Gelsinger, likely because he was trying to take a longer-term view on how to restore the storied manufacturer’s success.
It’s likely the accursed MBA-types will now get their way, flogging off the company’s foundry arm, kneecapping its design team in the process. It’ll take Intel a decade or more to actually feel the consequences of ignoring Gelsinger’s Cassandra-like warnings. But when TSMC reigns alone and we’re all paying more for chips, it’ll be easy to point to this moment and say this was Intel’s last chance to steer out of its own skid. — Daniel Cooper, senior editor
Photo by Cherlynn Low / Engadget
Fans of Apple’s Lightning connectors
We knew the writing was on the wall when the iPhone 15 debuted with USB-C in 2023, but this year put Lightning’s shambling corpse in the grave. The Apple-only connector was a revelation when it debuted in 2012’s iPhone 5, replacing the gigantic iPod-era 30-pin connector. Unlike the then-ascendant micro-USB port that dominated Android phones and other small devices in the early 2010s, Lightning was thinner and — this was key — reversible, so there was no wrong way to plug it in.
It eventually made its way to a large swath of devices in the Apple universe, including AirPods, iPads, Mac accessories and even a Beats product or two. But even Apple relented and started flipping new products to the similarly sized (and likewise reversible) USB-C, albeit years after it had become the dominant standard for data and power connections worldwide. With even holdouts like the AirPods Max and the Mac input devices getting USB-C retrofits in 2024, only a handful of legacy Lightning devices — the iPhone SE, iPhone 14 and old Apple Pencil — are left on Apple’s virtual shelves, and all will doubtless be gone by this time next year. That’s OK: Lightning served us well, but its time has passed. All hail our universal Type-C overlords.
So while the death of Lightning is a flat-out win for cross-device charging for the whole world going forward, anyone whose home is still bristling with soon-to-be-replaced Lightning charging stations can be forgiven for feeling a pang of nostalgia in the meantime. — John Falcone, executive editor
Moxie the robot dies
When I wrote about Moxie, the child-friendly robot from Embodied, I was charmed by its adorable design and chatty demeanor. It was meant to serve as a companion to children, something that could help them read or simply have conversations. I was less charmed by its $1,499 to $1,699 price, alongside an eventual $60 a month subscription. And now Moxie is officially dead, as Embodied announced it’s shutting down operations due to “financial challenges” after a failed funding round.
Dead home robots aren’t exactly a new phenomenon (remember Jibo?), but Moxie’s demise feels particularly rough, since it was a device mainly meant to help kids. Imagine having to tell your child that their robot friend had to shut down because of “financial challenges.” Embodied said it would offer customers age appropriate guidance to help discuss the shutdown, but no matter how you spin it, it’ll be a tough (and possibly traumatizing) conversation for your youngin. Perhaps it’s good to learn early though that all of your smart devices will die. (Not our pets though, they are immortal.) — Devindra Hardawar, senior editor
This article originally appeared on Engadget at https://www.engadget.com/techs-biggest-losers-in-2024-140039822.html?src=rss
We’re wrapping up 2024, so why not do it with some frivolous CES announcements? Like this premium (it has to be premium!) microwave from LG, with a touchscreen bigger than your iPad. I’m not sure what you’ll watch in the three-and-a-half minutes it takes to heat that butter chicken curry, but you can do it in glorious full HD resolution.
LG
The touchscreen integrates with LG’s ThinQ Smart Home Dashboard if you think it’s the right time to change channels on your TV or tinker with compatible Matter and Thread devices, like smart lights and er, and other things. It can also pair with the company’s induction range oven to display cooking progress if you struggle to crane your neck from your microwave to your kitchen burners. It’s no washing machine inside a washing machine, but still, you gotta love CES.
Documents and workstations at the US Treasury Department were accessed during a cyberattack linked to a “China state-sponsored Advanced Persistent Threat actor.” The attack was pretty bad, and it’s been cited as “a major cybersecurity incident.” The Treasury Department said it has worked with the Cybersecurity and Infrastructure Security Agency (CISA) and the FBI to understand the full scope of the breach but hasn’t shared how long files and workstations were accessible or what was accessed. Beijing has denied any involvement.
DJI’s Neo made aerial video accessible for everyone.
Engadget
Honesty? 2024 was a dull year for cameras, with new devices offering small tweaks and minor improvements. But drones? Specifically, entry-level ones? DJI made it an intriguing year, spitting out multiple models, including the versatile, easy-to-use Neo, all while fending off the US government’s plans to ban sales from the company.
LLMs requires some subtle, conceptually simple, yet important changes in the way we think about evaluation
I’ve been building evaluation for ML systems throughout my career. As head of data science at Quora, we built eval for feed ranking, ads, content moderation, etc. My team at Waymo built eval for self-driving cars. Most recently, at our fintech startup Coverbase, we use LLMs to ease the pain of third-party risk management. Drawing from these experiences, I’ve come to recognize that LLMs requires some subtle, conceptually simple, yet important changes in the way we think about evaluation.
The goal of this blog post is not to offer specific eval techniques to your LLM application, but rather to suggest these 3 paradigm shifts:
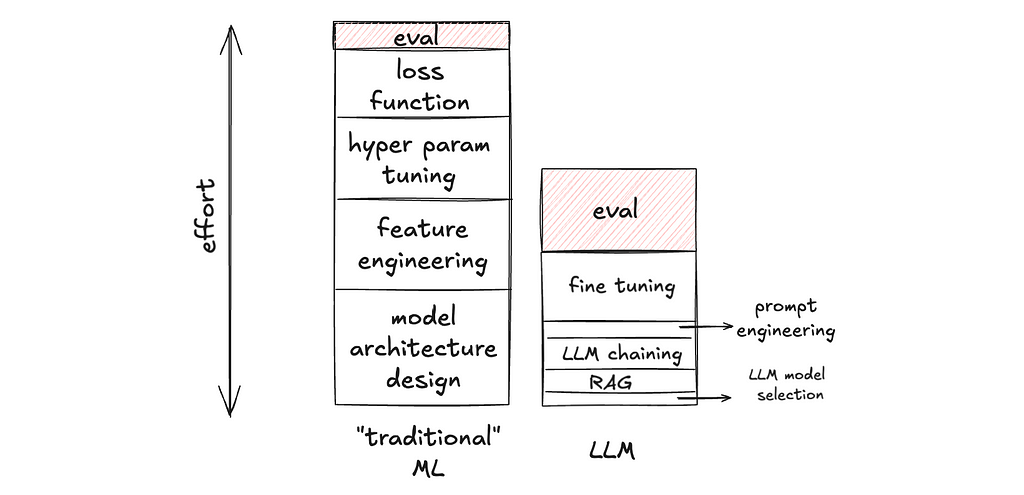
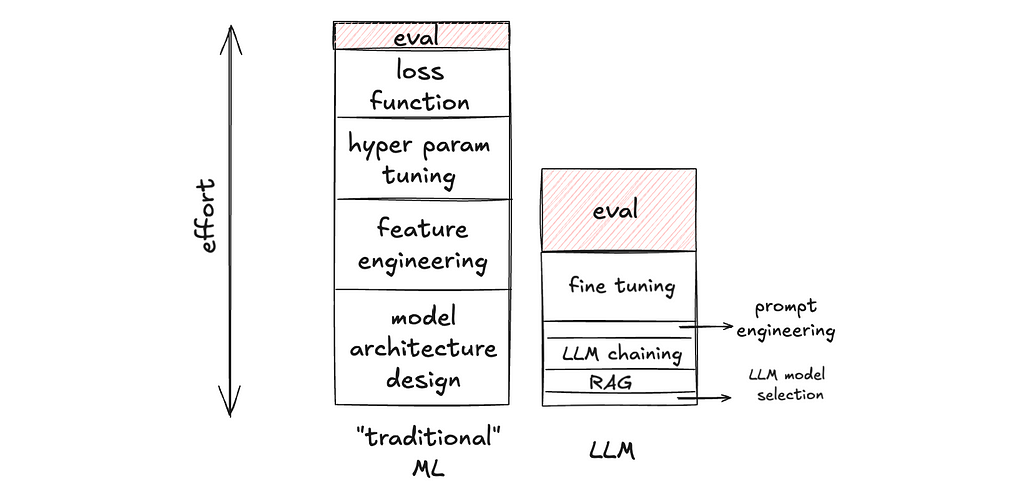
Evaluation is the cake, no longer the icing.
Benchmark the difference.
Embrace human triage as an integral part of eval.
I should caveat that my discussion is focused on LLM applications, not foundational model development. Also, despite the title, much of what I discuss here is applicable to other generative systems (inspired by my experience in autonomous vehicles), not just LLM applications.
1. Evaluation is the cake, no longer the icing.
Evaluation has always been important in ML development, LLM or not. But I’d argue that it is extra important in LLM development for two reasons:
a) The relative importance of eval goes up, because there are lower degrees of freedom in building LLM applications, making time spent non-eval work go down. In LLM development, building on top of foundational models such as OpenAI’s GPT or Anthropic’s Claude models, there are fewer knobs available to tweak in the application layer. And these knobs are much faster to tweak (caveat: faster to tweak, not necessarily faster to get it right). For example, changing the prompt is arguably much faster to implement than writing a new hand-crafted feature for a Gradient-Boosted Decision Tree. Thus, there is less non-eval work to do, making the proportion of time spent on eval go up.
b) The absolute importance of eval goes up, because there are higher degrees of freedom in the output of generative AI, making eval a more complex task. In contrast with classification or ranking tasks, generative AI tasks (e.g. write an essay about X, make an image of Y, generate a trajectory for an autonomous vehicle) can have an infinite number of acceptable outputs. Thus, the measurement is a process of projecting a high-dimensional space into lower dimensions. For example, for an LLM task, one can measure: “Is output text factual?”, “Does the output contain harmful content?”, “Is the language concise?”, “Does it start with ‘certainly!’ too often?”, etc. If precision and recall in a binary classification task are loss-less measurements of those binary outputs (measuring what you see), the example metrics I listed earlier for an LLM task are lossy measurements of the output text (measuring a low-dimensional representation of what you see). And that is much harder to get right.
This paradigm shift has practical implications on team sizing and hiring when staffing a project on LLM application.
2. Benchmark the difference.
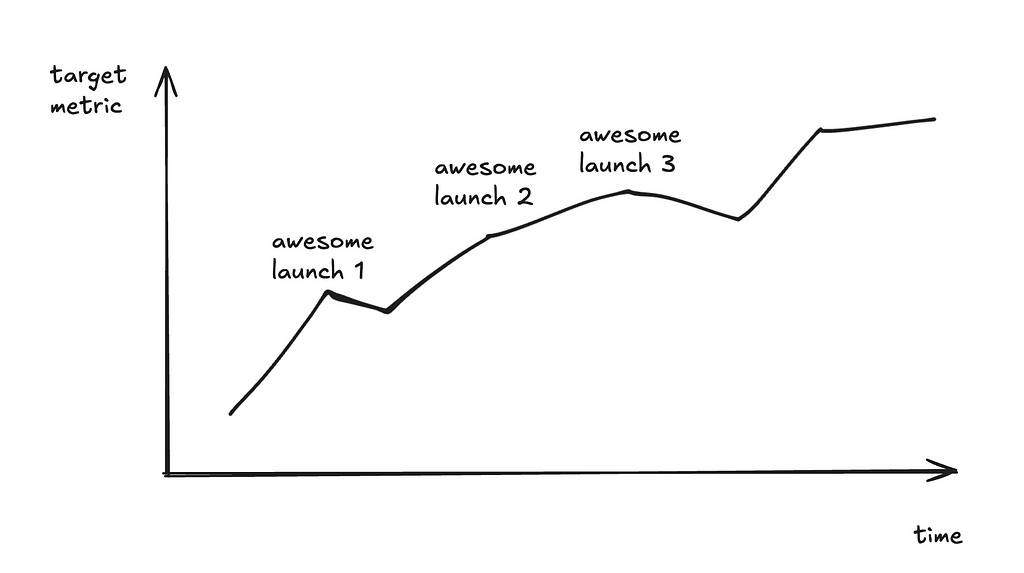
This is the dream scenario: we climb on a target metric and keep improving on it.
The reality?
You can barely draw more than 2 consecutive points in the graph!
These might sound familiar to you:
After the 1st launch, we acquired a much bigger dataset, so the new metric number is no longer an apple-to-apple comparison with the old number. And we can’t re-run the old model on the new dataset — maybe other parts of the system have upgraded and we can’t check out the old commit to reproduce the old model; maybe the eval metric is an LLM-as-a-judge and the dataset is huge, so each eval run is prohibitively expensive, etc.
After the 2nd launch, we decided to change the output schema. For example, previously, we instructed the model to output a yes / no answer; now we instruct the model to output yes / no / maybe / I don’t know. So the previously carefully curated ground truth set is no longer valid.
After the 3rd launch, we decided to break the single LLM calls into a composite of two calls, and we need to evaluate the sub-component. We need new datasets for sub-component eval.
….
The point is the development cycle in the age of LLMs is often too fast for longitudinal tracking of the same metric.
So what is the solution?
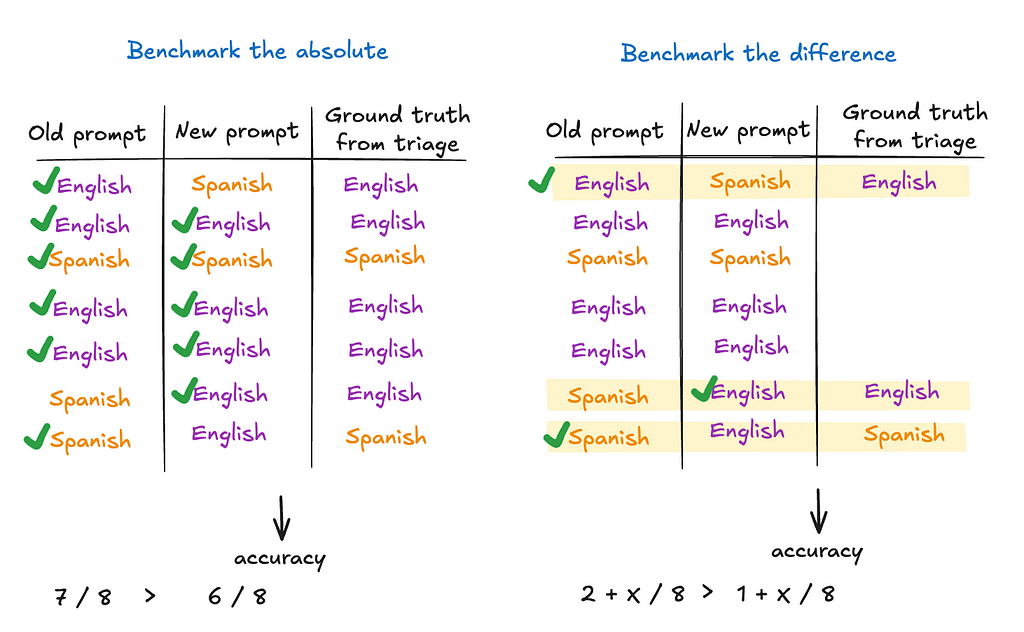
Measure the delta.
In other words, make peace with having just two consecutive points on that graph. The idea is to make sure each model version is better than the previous version (to the best of your knowledge at that point in time), even though it is quite hard to know where its performance stands in absolute terms.
Suppose I have an LLM-based language tutor that first classifies the input as English or Spanish, and then offers grammar tips. A simple metric can be the accuracy of the “English / Spanish” label. Now, say I made some changes to the prompt and want to know whether the new prompt improves accuracy. Instead of hand-labeling a large data set and computing accuracy on it, another way is to just focus on the data points where the old and new prompts produce different labels. I won’t be able to know the absolute accuracy of either model this way, but I will know which model has higher accuracy.
I should clarify that I am not saying benchmarking the absolute has no merits. I am only saying we should be cognizant of the cost of doing so, and benchmarking the delta — albeit not a full substitute — can be a much more cost-effective way to get a directional conclusion. One of the more fundamental reasons for this paradigm shift is that if you are building your ML model from scratch, you often have to curate a large training set anyway, so the eval dataset can often be a byproduct of that. This is not the case with zero-shot and few-shots learning on pre-trained models (such as LLMs).
As a second example, perhaps I have an LLM-based metric: we use a separate LLM to judge whether the explanation produced in my LLM language tutor is clear enough. One might ask, “Since the eval is automated now, is benchmarking the delta still cheaper than benchmarking the absolute?” Yes. Because the metric is more complicated now, you can keep improving the metric itself (e.g. prompt engineering the LLM-based metric). For one, we still need to eval the eval; benchmarking the deltas tells you whether the new metric version is better. For another, as the LLM-based metric evolves, we don’t have to sweat over backfilling benchmark results of all the old versions of the LLM language tutor with the new LLM-based metric version, if we only focus on comparing two adjacent versions of the LLM language tutor models.
Benchmarking the deltas can be an effective inner-loop, fast-iteration mechanism, while saving the more expensive way of benchmarking the absolute or longitudinal tracking for the outer-loop, lower-cadence iterations.
3. Embrace human triage as an integral part of eval.
As discussed above, the dream of carefully triaging a golden set once-and-for-all such that it can be used as an evergreen benchmark can be unattainable. Triaging will be an integral, continuous part of the development process, whether it is triaging the LLM output directly, or triaging those LLM-as-judges or other kinds of more complex metrics. We should continue to make eval as scalable as possible; the point here is that despite that, we should not expect the elimination of human triage. The sooner we come to terms with this, the sooner we can make the right investments in tooling.
As such, whatever eval tools we use, in-house or not, there should be an easy interface for human triage. A simple interface can look like the following. Combined with the point earlier on benchmarking the difference, it has a side-by-side panel, and you can easily flip through the results. It also should allow you to easily record your triaged notes such that they can be recycled as golden labels for future benchmarking (and hence reduce future triage load).
A more advanced version ideally would be a blind test, where it is unknown to the triager which side is which. We’ve repeatedly confirmed with data that when not doing blind testing, developers, even with the best intentions, have subconscious bias, favoring the version they developed.
These three paradigm shifts, once spotted, are fairly straightforward to adapt to. The challenge isn’t in the complexity of the solutions, but in recognizing them upfront amidst the excitement and rapid pace of development. I hope sharing these reflections helps others who are navigating similar challenges in their own work.
From attention to gradient descent: unraveling how transformers learn from examples
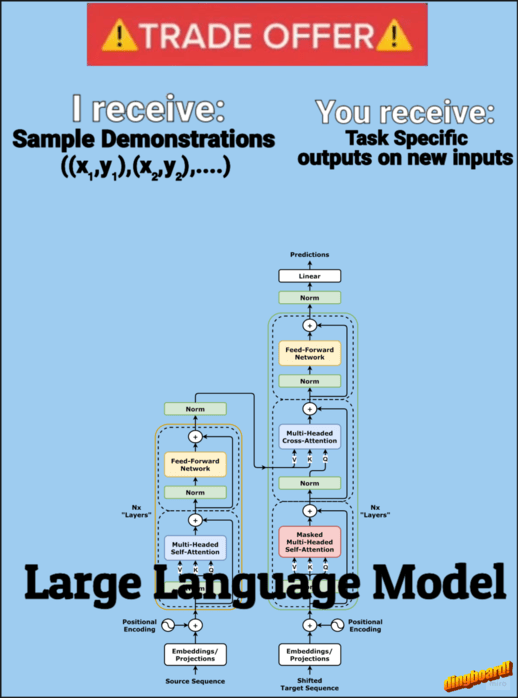
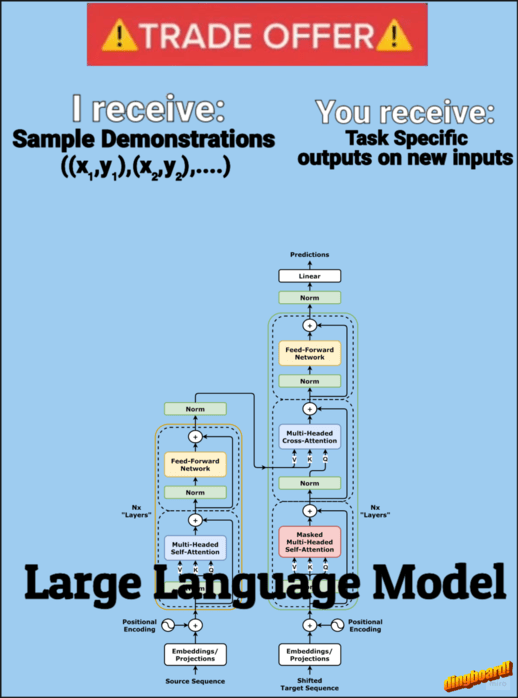
In-context learning (ICL) — a transformer’s ability to adapt its behavior based on examples provided in the input prompt — has become a cornerstone of modern LLM usage. Few-shot prompting, where we provide several examples of a desired task, is particularly effective at showing an LLM what we want it to do. But here’s the interesting part: why can transformers so easily adapt their behavior based on these examples? In this article, I’ll give you an intuitive sense of how transformers might be pulling off this learning trick.
This will provide a high-level introduction to potential mechanisms behind in-context learning, which may help us better understand how these models process and adapt to examples.
The core goal of ICL can be framed as: given a set of demonstration pairs ((x,y) pairs), can we show that attention mechanisms can learn/implement an algorithm that forms a hypothesis from these demonstrations to correctly map new queries to their outputs?
Softmax Attention
Let’s recap the basic softmax attention formula,
Source: Image by Author
We’ve all heard how temperature affects model outputs, but what’s actually happening under the hood? The key lies in how we can modify the standard softmax attention with an inverse temperature parameter. This single variable transforms how the model allocates its attention — scaling the attention scores before they go through softmax changes the distribution from soft to increasingly sharp. This would slightly modify the attention formula as,
Source: Image by Author
Where c is our inverse temperature parameter. Consider a simple vector z = [2, 1, 0.5]. Let’s see how softmax(c*z) behaves with different values of c:
When c = 0:
softmax(0 * [2, 1, 0.5]) = [0.33, 0.33, 0.33]
All tokens receive equal attention, completely losing the ability to discriminate between similarities
When c = 1:
softmax([2, 1, 0.5]) ≈ [0.59, 0.24, 0.17]
Attention is distributed proportionally to similarity scores, maintaining a balance between selection and distribution
When c = 10000 (near infinite):
softmax(10000 * [2, 1, 0.5]) ≈ [1.00, 0.00, 0.00]
Attention converges to a one-hot vector, focusing entirely on the most similar token — exactly what we need for nearest neighbor behavior
Now here’s where it gets interesting for in-context learning: When c is tending to infinity, our attention mechanism essentially becomes a 1-nearest neighbor search! Think about it — if we’re attending to all tokens except our query, we’re basically finding the closest match from our demonstration examples. This gives us a fresh perspective on ICL — we can view it as implementing a nearest neighbor algorithm over our input-output pairs, all through the mechanics of attention.
But what happens when c is finite? In that case, attention acts more like a Gaussian kernel smoothing algorithm where it weights each token proportional to their exponential similarity.
We saw that Softmax can do nearest neighbor, great, but what’s the point in knowing that? Well if we can say that the transformer can learn a “learning algorithm” (like nearest neighbor, linear regression, etc.), then maybe we can use it in the field of AutoML and just give it a bunch of data and have it find the best model/hyperparameters; Hollmann et al. did something like this where they train a transformer on many synthetic datasets to effectively learn the entire AutoML pipeline. The transformer learns to automatically determine what type of model, hyperparameters, and training approach would work best for any given dataset. When shown new data, it can make predictions in a single forward pass — essentially condensing model selection, hyperparameter tuning, and training into one step.
In 2022, Anthropic released a paper where they showed evidence that induction head might constitute the mechanism for ICL. What are induction heads? As stated by Anthropic — “Induction heads are implemented by a circuit consisting of a pair of attention heads in different layers that work together to copy or complete patterns.”, simply put what the induction head does is given a sequence like — […, A, B,…, A] it will complete it with B with the reasoning that if A is followed by B earlier in the context, it is likely that A is followed by B again. When you have a sequence like “…A, B…A”, the first attention head copies previous token info into each position, and the second attention head uses this info to find where A appeared before and predict what came after it (B).
Recently a lot of research has shown that transformers could be doing ICL through gradient descent (Garg et al. 2022, Oswald et al. 2023, etc) by showing the relation between linear attention and gradient descent. Let’s revisit least squares and gradient descent,
Source: Image by Author
Now let’s see how this links with linear attention
Linear Attention
Here we treat linear attention as same as softmax attention minus the softmax operation. The basic linear attention formula,
Source: Image by Author
Let’s start with a single-layer construction that captures the essence of in-context learning. Imagine we have n training examples (x₁,y₁)…(xₙ,yₙ), and we want to predict y_{n+1} for a new input x_{n+1}.
Source: Image by Author
This looks very similar to what we got with gradient descent, except in linear attention we have an extra term ‘W’. What linear attention is implementing is something known as preconditioned gradient descent (PGD), where instead of the standard gradient step, we modify the gradient with a preconditioning matrix W,
Source: Image by Author
What we have shown here is that we can construct a weight matrix such that one layer of linear attention will do one step of PGD.
Conclusion
We saw how attention can implement “learning algorithms”, these are algorithms where basically if we provide lots of demonstrations (x,y) then the model learns from these demonstrations to predict the output of any new query. While the exact mechanisms involving multiple attention layers and MLPs are complex, researchers have made progress in understanding how in-context learning works mechanistically. This article provides an intuitive, high-level introduction to help readers understand the inner workings of this emergent ability of transformers.
To read more on this topic, I would suggest the following papers:
This blog post was inspired by coursework from my graduate studies during Fall 2024 at University of Michigan. While the courses provided the foundational knowledge and motivation to explore these topics, any errors or misinterpretations in this article are entirely my own. This represents my personal understanding and exploration of the material.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.