Connections is the new puzzle game from the New York Times, and it can be quite difficult. If you need a hand with solving today’s puzzle, we’re here to help.
It’s been a great year for smartphone competition, and a new season of phone launches is just weeks away. Here are 5 things that could change phones in 2025.
Reflective generative AI software components as a development paradigm
Nowhere has the proliferation of generative AI tooling been more aggressive than in the world of software development. It began with GitHub Copilot’s supercharged autocomplete, then exploded into direct code-along integrated tools like Aider and Cursor that allow software engineers to dictate instructions and have the generated changes applied live, in-editor. Now tools like Devin.ai aim to build autonomous software generating platforms which can independently consume feature requests or bug tickets and produce ready-to-review code.
The grand aspiration of these AI tools is, in actuality, no different from the aspirations of all the software that has ever written by humans: to automate human work. When you scheduled that daily CSV parsing script for your employer back in 2005, you were offloading a tiny bit of the labor owned by our species to some combination of silicon and electricity. Where generative AI tools differ is that they aim to automate the work of automation. Setting this goal as our north star enables more abstract thinking about the inherit challenges and possible solutions of generative AI software development.
⭐ Our North Star: Automate the process of automation
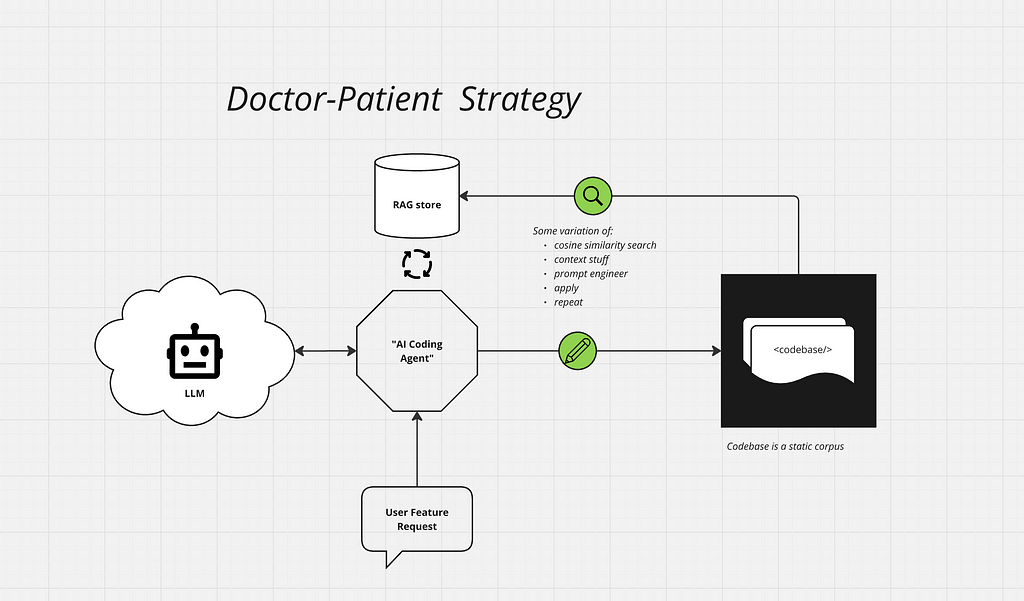
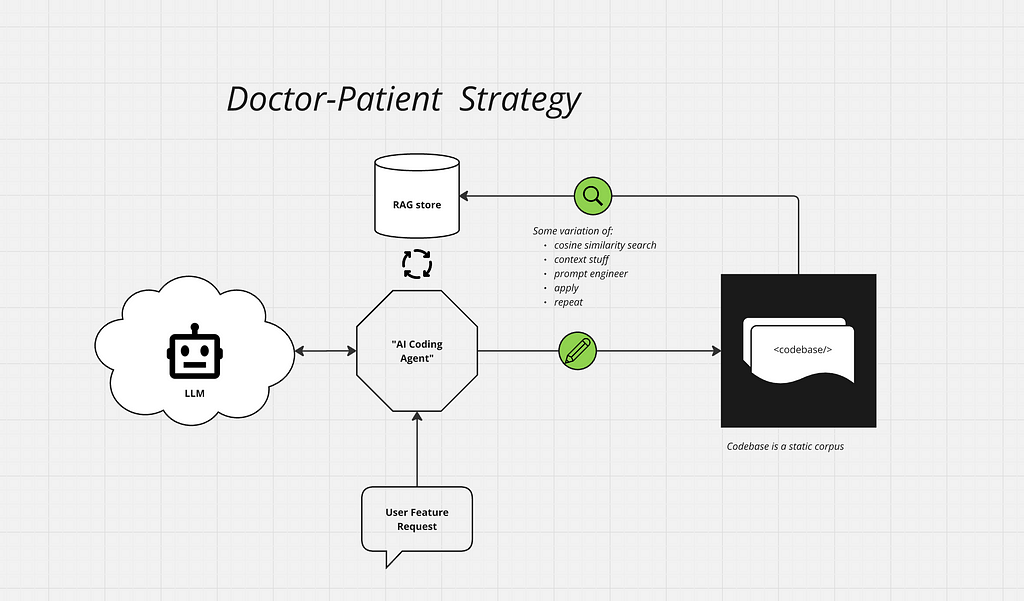
The Doctor-Patient strategy
Most contemporary tools approach our automation goal by building stand-alone “coding bots.” The evolution of these bots represents an increasing success at converting natural language instructions into subject codebase modifications. Under the hood, these bots are platforms with agentic mechanics (mostly search, RAG, and prompt chains). As such, evolution focuses on improving the agentic elements — refining RAG chunking, prompt tuning etc.
This strategy establishes the GenAI tool and the subject codebase as two distinct entities, with a unidirectional relationship between them. This relationship is similar to how a doctor operates on a patient, but never the other way around — hence the Doctor-Patient strategy.
The Doctor-Patient strategy of agentic coding approaches code as an external corpus. Image by [email protected]
A few reasons come to mind that explain why this Doctor-Patient strategy has been the first (and seemingly only) approach towards automating software automation via GenAI:
Novel Integration: Software codebases have been around for decades, while using agentic platforms to modify codebases is an extremely recent concept. So it makes sense that the first tools would be designed to act on existing, independent codebases.
Monetization: The Doctor-Patient strategy has a clear path to revenue. A seller has a GenAI agent platform/code bot, a buyer has a codebase, the seller’s platform operates on buyers’ codebase for a fee.
Social Analog: To a non-developer, the relationship in the Doctor-Patient strategy resembles one they already understand between users and Software Developers. A Developer knows how to code, a user asks for a feature, the developer changes the code to make the feature happen. In this strategy, an agent “knows how to code” and can be swapped directly into that mental model.
False Extrapolation: At a small enough scale, the Doctor-Patient model can produce impressive results. It is easy to make the incorrect assumption that simply adding resources will allow those same results to scale to an entire codebase.
The independent and unidirectional relationship between agentic platform/tool and codebase that defines the Doctor-Patient strategy is also the greatest limiting factor of this strategy, and the severity of this limitation has begun to present itself as a dead end. Two years of agentic tool use in the software development space have surfaced antipatterns that are increasingly recognizable as “bot rot” — indications of poorly applied and problematic generated code.
Bot Rot: the degradation of codebase subjected to generative AI alteration. AI generated image created by Midjourney v6.1
Bot rot stems from agentic tools’ inability to account for, and interact with, the macro architectural design of a project. These tools pepper prompts with lines of context from semantically similar code snippets, which are utterly useless in conveying architecture without a high-level abstraction. Just as a chatbot can manifest a sensible paragraph in a new mystery novel but is unable to thread accurate clues as to “who did it”, isolated code generations pepper the codebase with duplicated business logic and cluttered namespaces. With each generation, bot rot reduces RAG effectiveness and increases the need for human intervention.
Because bot rotted code requires a greater cognitive load to modify, developers tend to double down on agentic assistance when working with it, and in turn rapidly accelerate additional bot rotting. The codebase balloons, and bot rot becomes obvious: duplicated and often conflicting business logic, colliding, generic and non-descriptive names for modules, objects, and variables, swamps of dead code and boilerplate commentary, a littering of conflicting singleton elements like loggers, settings objects, and configurations. Ironically, sure signs of bot rot are an upward trend in cycle time and an increased need for human direction/intervention in agentic coding.
A practical example of bot rot
This example uses Python to illustrate the concept of bot rot, however a similar example could be made in any programming language. Agentic platforms operate on all programming languages in largely the same way and should demonstrate similar results.
In this example, an application processes TPS reports. Currently, the TPS ID value is parsed by several different methods, in different modules, to extract different elements:
# src/ingestion/report_consumer.py
def parse_department_code(self, report_id:str) -> int: """returns the parsed department code from the TPS report id""" dep_id = report_id.split(“-”)[-3] return get_dep_codes()[dep_id]
# src/reporter/tps.py
def get_reporting_date(report_id:str) -> datetime.datetime: """converts the encoded date from the tps report id""" stamp = int(report_id.split(“ts=”)[1].split(“&”)[0]) return datetime.fromtimestamp(stamp)
A new feature requires parsing the same department code in a different part of the codebase, as well as parsing several new elements from the TPS ID in other locations. A skilled human developer would recognize that TPS ID parsing was becoming cluttered, and abstract all references to the TPS ID into a first-class object:
# src/ingestion/report_consumer.py from models.tps_report import TPSReport
def parse_department_code(self, report_id:str) -> int: """Deprecated: just access the code on the TPS object in the future""" report = TPSReport(report_id) return report.department_code
This abstraction DRYs out the codebase, reducing duplication and shrinking cognitive load. Not surprisingly, what makes code easier for humans to work with also makes it more “GenAI-able” by consolidating the context into an abstracted model. This reduces noise in RAG, improving the quality of resources available for the next generation.
An agentic tool must complete this same task without architectural insight, or the agency required to implement the above refactor. Given the same task, a code bot will generate additional, duplicated parsing methods or, worse, generate a partial abstraction within one module and not propagate that abstraction. The pattern created is one of a poorer quality codebase, which in turn elicits poorer quality future generations from the tool. Frequency distortion from the repetitive code further damages the effectiveness of RAG. This bot rot spiral will continue until a human hopefully intervenes with a git reset before the codebase devolves into complete anarchy.
An inversion of thinking
The fundamental flaw in the Doctor-Patient strategy is that it approaches the codebase as a single-layer corpus, serialized documentation from which to generate completions. In reality, software is non-linear and multidimensional — less like a research paper and more like our aforementioned mystery novel. No matter how large the context window or effective the embedding model, agentic tools disambiguated from the architectural design of a codebase will always devolve into bot rot.
How can GenAI powered workflows be equipped with the context and agency required to automate the process of automation? The answer stems from ideas found in two well-established concepts in software engineering.
TDD
Test Driven Development is a cornerstone of modern software engineering process. More than just a mandate to “write the tests first,” TDD is a mindset manifested into a process. For our purposes, the pillars of TDD look something like this:
A complete codebase consists of application code that performs desired processes, and test code that ensures the application code works as intended.
Test code is written to define what “done” will look like, and application code is then written to satisfy that test code.
TDD implicitly requires that application code be written in a way that is highly testable. Overly complex, nested business logic must be broken into units that can be directly accessed by test methods. Hooks need to be baked into object signatures, dependencies must be injected, all to facilitate the ability of test code to assure functionality in the application. Herein is the first part of our answer: for agentic processes to be more successful at automating our codebase, we need to write code that is highly GenAI-able.
Another important element of TDD in this context is that testing must be an implicit part of the software we build. In TDD, there is no option to scratch out a pile of application code with no tests, then apply a third party bot to “test it.” This is the second part of our answer: Codebase automation must be an element of the software itself, not an external function of a ‘code bot’.
Refactoring
The earlier Python TPS report example demonstrates a code refactor, one of the most important higher-level functions in healthy software evolution. Kent Beck describes the process of refactoring as
“for each desired change, make the change easy (warning: this may be hard), then make the easy change.” ~ Kent Beck
This is how a codebase improves for human needs over time, reducing cognitive load and, as a result, cycle times. Refactoring is also exactly how a codebase is continually optimized for GenAI automation! Refactoring means removing duplication, decoupling and creating semantic “distance” between domains, and simplifying the logical flow of a program — all things that will have a huge positive impact on both RAG and generative processes. The final part of our answer is that codebase architecture (and subsequently, refactoring) must be a first class citizen as part of any codebase automation process.
Generative Driven Development
Given these borrowed pillars:
For agentic processes to be more successful at automating our codebase, we need to write code that is highly GenAI-able.
Codebase automation must be an element of the software itself, not an external function of a ‘code bot’.
Codebase architecture (and subsequently, refactoring) must be a first class citizen as part of any codebase automation process.
An alternative strategy to the unidirectional Doctor-Patient takes shape. This strategy, where application code development itself is driven by the goal of generative self-automation, could be called Generative Driven Development, or GDD(1).
GDD is an evolution that moves optimization for agentic self-improvement to the center stage, much in the same way as TDD promoted testing in the development process. In fact, TDD becomes a subset of GDD, in that highly GenAI-able code is both highly testable and, as part of GDD evolution, well tested.
To dissect what a GDD workflow could look like, we can start with a closer look at those pillars:
1. Writing code that is highly GenAI-able
In a highly GenAI-able codebase, it is easy to build highly effective embeddings and assemble low-noise context, side effects and coupling are rare, and abstraction is clear and consistent. When it comes to understanding a codebase, the needs of a human developer and those of an agentic process have significant overlap. In fact, many elements of highly GenAI-able code will look familiar in practice to a human-focused code refactor. However, the driver behind these principles is to improve the ability of agentic processes to correctly generate code iterations. Some of these principles include:
High cardinality in entity naming: Variables, methods, classes must be as unique as possible to minimize RAG context collisions.
Appropriate semantic correlation in naming: A Dog class will have a greater embedded similarity to the Cat class than a top-level walk function. Naming needs to form intentional, logical semantic relationships and avoid semantic collisions.
Granular (highly chunkable) documentation: Every callable, method and object in the codebase must ship with comprehensive, accurate heredocs to facilitate intelligent RAG and the best possible completions.
Full pathing of resources: Code should remove as much guesswork and assumed context as possible. In a Python project, this would mean fully qualified import paths (no relative imports) and avoiding unconventional aliases.
Extremely predictable architectural patterns: Consistent use of singular/plural case, past/present tense, and documented rules for module nesting enable generations based on demonstrated patterns (generating an import of SaleSchema based not on RAG but inferred by the presence of OrderSchema and ReturnSchema)
DRY code: duplicated business logic balloons both the context and generated token count, and will increase generated mistakes when a higher presence penalty is applied.
2. Tooling as an aspect of the software
Every commercially viable programming language has at least one accompanying test framework; Python has pytest, Ruby has RSpec, Java has JUnit etc. In comparison, many other aspects of the SDLC evolved into stand-alone tools – like feature management done in Jira or Linear, or monitoring via Datadog. Why, then, are testing code part of the codebase, and testing tools part of development dependencies?
Tests are an integral part of the software circuit, tightly coupled to the application code they cover. Tests require the ability to account for, and interact with, the macro architectural design of a project (sound familiar?) and must evolve in sync with the whole of the codebase.
For effective GDD, we will need to see similar purpose-built packages that can support an evolved, generative-first development process. At the core will be a system for building and maintaining an intentional meta-catalog of semantic project architecture. This might be something that is parsed and evolved via the AST, or driven by a ULM-like data structure that both humans and code modify over time — similar to a .pytest.ini or plugin configs in a pom.xml file in TDD.
This semantic structure will enable our package to run stepped processes that account for macro architecture, in a way that is both bespoke to and evolving with the project itself. Architectural rules for the application such as naming conventions, responsibilities of different classes, modules, services etc. will compile applicable semantics into agentic pipeline executions, and guide generations to meet them.
Similar to the current crop of test frameworks, GDD tooling will abstract boilerplate generative functionality while offering a heavily customizable API for developers (and the agentic processes) to fine-tune. Like your test specs, generative specs could define architectural directives and external context — like the sunsetting of a service, or a team pivot to a new design pattern — and inform the agentic generations.
GDD linting will look for patterns that make code less GenAI-able (see Writing code that is highly GenAI-able) and correct them when possible, raise them to human attention when not.
3. Architecture as a first-class citizen
Consider the problem of bot rot through the lens of a TDD iteration. Traditional TDD operates in three steps: red, green, and refactor.
Red: write a test for the new feature that fails (because you haven’t written the feature yet)
Green: write the feature as quickly as possible to make the test pass
Refactor: align the now-passing code with the project architecture by abstracting, renaming etc.
With bot rot only the “green” step is present. Unless explicitly instructed, agentic frameworks will not write a failing test first, and without an understanding of the macro architectural design they cannot effectively refactor a codebase to accommodate the generated code. This is why codebases subject to the current crop of agentic tools degrade rather quickly — the executed TDD cycles are incomplete. By elevating these missing “bookends” of the TDD cycle in the agentic process and integrating a semantic map of the codebase architecture to make refactoring possible, bot rot will be effectively alleviated. Over time, a GDD codebase will become increasingly easier to traverse for both human and bot, cycle times will decrease, error rates will fall, and the application will become increasingly self-automating.
A day in the GDD life
what could GDD development look like?
A GDD Engineer opens their laptop to start the day, cds into our infamous TPS report repo and opens a terminal. Let’s say the Python GDD equivalent of pytest is a (currently fictional) package named py-gdd.
First, they need to pick some work from the backlog. Scanning over the tickets in Jira they decide on “TPS-122: account for underscores in the new TPS ID format.” They start work in the terminal with:
>> git checkout -b feature/TPS-122/id-underscores && py-gdd begin TPS-122
A terminal spinner appears while py-gdd processes. What is py-gdd doing?
Reading the jira ticket content
Reviewing current semantic architecture to select smart RAG context
Reviewing the project directives to adjust context and set boundaries
Constructing a plan, which is persisted into a gitignored .pygdd folder
py-gdd responds with a developer-peer level statement about the execution plan, something to the effect of:
“I am going to parameterize all the tests that use TPS IDs with both dashes and underscores, I don’t think we need a stand-alone test for this then. And then I will abstract all the TPS ID parsing to a single TPS model.”
Notice how this wasn’t an unreadable wall of code + unimportant context + comment noise?
The Engineer scans the plan, which consists of more granular steps:
Updating 12 tests to parameterized dash and underscore TPS IDs
Ensuring only the new tests fail
Updating 8 locations in the code where TPS IDs are parsed
Ensuring all tests pass
Abstracting the test parameterization to a single test fixture
Migrating all 12 tests to the new fixture, confirming that they pass with each migration
Creating a new TPS model
Duplicating all the TPS model logic from the application in the new model
Confirming tests all still pass
Swapping in the new model at each of the 8 locations, confirming the tests pass with each
Updating the semantic architecture to be aware of the new TPS model and edges in the graph that associate with it
Updating method names in 2 of the locations to be more semantically distinct
On confirmation, the terminal spinner appears again. Text appears in red:
Problem in step 3 - I am unable to get all tests to pass after 2 attempts
The Engineer looks at the test code and sees that the database test factory is hard-coded to the old ID type and cannot accept overrides — this explains why the py-gdd process cannot get the updates to pass. The Engineer explains this via in-terminal chat to py-gdd, and a new sub-plan is created:
Roll back main plain step 1
Modify database test factory to accept an override for TPS ID
Confirm that all tests now pass
Update main plan step 1 to include overriding database test factory with parameterized value
Re-apply main plan step 1
In addition, back in the main plan the step “update semantics for database test factory” is added. The Engineer confirms again, and this time the plan completes successfully, and a Pull Request is created in GitHub.
py-gdd follows up with a list of concerns it developed during the plan execution:
concerns: - there are several lower-level modules simply named “server” and this is semantically confusing. - the tps_loader module aliases pandas as “pand” which is non-standard and may hinder generation. - there are no test hooks in the highly complex “persist_schema” method of the InnatechDB class. This is makes both testing and generation difficult. ...
The Engineer instructs py-gdd to create tickets for each concern. On to the next ticket!
The CI/CD of GDD
In this vision, an Engineer is still very heavily involved in the mechanical processes of GDD. But it is reasonable to assume that as a codebase grows and evolves to become increasingly GenAI-able due to GDD practice, less human interaction will become necessary. In the ultimate expression of Continuous Delivery, GDD could be primarily practiced via a perpetual “GDD server.” Work will be sourced from project management tools like Jira and GitHub Issues, error logs from Datadog and CloudWatch needing investigation, and most importantly generated by the GDD tooling itself. Hundreds of PRs could be opened, reviewed, and merged every day, with experienced human engineers guiding the architectural development of the project over time. In this way, GDD can become a realization of the goal to automate automation.
yes, this really is a clear form of machine learning, but that term has been so painfully overloaded that I hesitate to associate any new idea with those words.
originally published on pirate.baby, my tech and tech-adjacent blog
Regardless of how 2024 went for you, 2025 is another chance for all of us to make the new year better than the one that came before it. New Year’s resolutions are usually set with the best intentions, but it’s no secret many people fail after just a few weeks — old habits die hard. It’s important to have a support group, people who can cheer you on during those particularly hard days. But it’s also important to have the right tools to make achieving your goals easier. Whether you’re trying to get healthy, be more organized, read more or anything in between, there are tech tools that can make your journey smoother and more enjoyable.
Fitness tracker
If you’re attempting to turn over a new, healthier leaf, you’re not alone. Fitness trackers (and their companion apps) are highly sought after this time of year because they can help you stick to those new movement, hydration and sleep habits you’re trying to build. The Xiaomi Mi Band 8 is a good option, not only because it’s affordable at $50, but because it does pretty much everything a beginner needs. It tracks daily steps, calories, sleep and more, and it has a two-week battery life so you can keep it on all the time and rarely have to remember to charge it.
If you’re already a runner or a cyclist (or want to be one), we recommend upgrading to the Fitbit Charge 6 instead. You’ll get all of the basic fitness tracking features you’d expect like daily step, sleep and activity tracking, along with onboard GPS for mapping outdoor workouts and Fitbit Pay for contactless payments. That way you’ll be able to go for a run in the morning and stop to grab a coffee without bringing your phone or your wallet with you.
Smartwatch
If you’d rather invest in an all-purpose wearable that also has serious fitness chops, the Apple Watch SE is a good choice. While it doesn’t include all the bells and whistles that the pricier Series 10 does, it still offers the same core experience. It tracks all-day activity and heart rate, and watchOS finally offers basic sleep tracking, too. In addition to built-in GPS for outdoor workouts, it tracks dozens of exercises and supports fall detection, as well as high and low heart rate alerts. It’s also quite good at automatically recognizing when you’re working out and prompting you to start tracking your efforts. On top of all that, the Apple Watch excels when it comes to table-stakes smartwatch features: You’ll be able to send and receive text messages from the device, as well as control music playback, smart home devices and more.
Android users should consider the Fitbit Versa series of smartwatches. The latest model, the Versa 4, has many of the same features as Apple’s most affordable wearable including all-day activity tracking and heart rate monitoring, built-in GPS and even more advanced sleep tracking capabilities. It also has a lot of features you won’t find on an Apple Watch like Alexa voice control, Google Maps and Wallet integration and a days-long battery life (up to six days to be precise). There are smart alerts as well, so you’ll get notified when your phone receives calls and texts. At $200, the Versa 4 is decently priced on a regular day, but you can often find it on sale for close to $150 — that could make it a good options for anyone on a budget, not just those with Android phones.
Workout classes
Finding exercise classes that you actually enjoy can make working out feel like less of a chore. You may prefer going through your local gym — that push to get out of the house and into a dedicated exercise space can be really effective for some — but there are plenty of on-demand fitness classes as well that you can participate in from the comfort of your living room.
I’ve tried my fair share of these services and my favorite has been Peloton. No, you don’t need one of the company’s expensive bikes or other machinery to take advantage of their classes. Access to the app-only version costs $13 per month and it lets you take HIIT, strength, yoga and even outdoor running classes, many of which require little to no equipment. If Peloton isn’t your speed, Apple Fitness+ is a good alternative, especially now that anyone with an iPhone can subscribe and take classes, regardless of whether they own an Apple Watch. Alo Moves is another good option for those who prefer yoga and pilates workouts.
If you can’t afford another monthly subscription fee, the internet has tons of free exercise resources — you just have to work a little harder to find the ones you jibe with most. I highly recommend Fitness Blender, a free website where you can watch hundreds of workout videos and even set a schedule for yourself, assigning routines to specific days of the week. I like the quality and consistency of their videos, but you may connect more to YouTube workouts if they’re taught by instructors you like; Heather Robertson and Move with Nicole are two personal favorites.
Habit tracker
Accountability is key when you’re trying to build new habits, so keeping track of your progress is crucial. While you could go deep down the bullet-journal rabbit hole, a habit-tracking app is probably the easier option. Done and Strides are two iOS options that let you log when you’ve completed a new habit you’re trying to build or when you avoided a bad habit that you’re trying to break. You can get pretty granular, customizing how often you want to do a task, set reminders to log, review stats and more.
Both apps have paid tiers you’ll be asked to subscribe to after you create a few trackable habits. If you’d rather avoid yet another subscription, consider an app like Streaks, which can be all yours for a one-time fee of $6. As for Android, there’s Habitica, which turns habit tracking to an 8-bit RPG game where you level-up your custom avatar by checking things off your list.
To-do list apps
The new year provides an opportunity to get back on track, and one way to do that is by finding organizational tools that work for you — and making sure they’re as uncomplicated as possible. The worst thing that could happen is that your to-do list or note-taking system ends up being so cumbersome that you avoid using it. Keeping all of your necessary tasks in your head may work on easy days, but it can quickly get overwhelming when you have a million things to handle in both your personal and professional life. I’m a fan of Todoist and Things (the latter of which is for iOS and macOS only) because both are detailed enough for big work projects, but simple enough for personal tasks. Both also have a Today view, which will show everything across all of your projects that need attention immediately.
While Todoist has a free tier, you’ll pay $80 to get Things for iOS, iPadOS and macOS. Microsoft’s To Do is an alternative that, while less involved than Things, is free and works on almost every platform including Windows, iOS and Android, among others. You can keep it simple and just have a task list and a grocery list, or you can go deeper and add due dates, sub-tasks and even share lists with family members.
If you don’t want to bother with another service, you can always opt for the reminders app that (most likely) came preinstalled on your phone. That would be Reminders for iOS users and Google Keep for Android users. Google Keep also doubles as a note-taking app, which will be a better solution if you’ve been jotting down ideas for new projects on Post-It notes you inevitably lose. Apple Notes is the default option for this on iOS devices, and it’s come a long way in recent years with new features like interlinked notes, inline and annotatable PDFs and native support for scanning documents using the iPhone’s camera.
Password manager
If you’re looking to up your digital security game in the new year, a password manager is a great place to start. I’m partial to 1Password (as are we as a whole at Engadget), but there are plenty of other options including Bitwarden, NordPass and Dashlane. After saving all of your passwords for various accounts, you only need to remember one (hence the name) to log in to your 1Password account and access all of the others. The service has browser extensions Chrome, Edge and others that will let you seamlessly log in with just a few clicks, and 1Password has apps for most platforms including iOS and Android, so you can use it on all of your devices.
The Password Generator feature helps you create a new, secure password whenever one of yours has expired. LastPass has this too, and Dashlane even has a free tool that anyone can use to make more secure passwords. Not only does this take the onus of coming up with a strong key off your shoulders, but it also makes it easy to override old credentials with new ones.
Cable and accessory organizer
One of the consequences of the past few of years is the dual-office life. Many of us now work both from home and from an office, and the last thing you want to do when you arrive in either place is rummage around your backpack only to realize that you’ve left your mouse, charging cable or dongle at your other desk.
An organizer bag can prevent this before it happens — we recommend BagSmart tech organizers thanks to their utilitarian, water-repellent designs and their multiple pockets and dividers. They also come in different sizes, so you can pick the best one for your commuter bag. If you want something a bit more elevated, Bellroy’s Desk Caddy is a good option. It’s pricier but for the money you get a more elegant silhouette, higher-quality materials and a design that sits upright when full and has a front panel that fully folds down to give you a good view of what’s inside.
Computer docking station
It’s all too easy for your work-from-home setup to get really messy really quickly. When you’re going through your busiest times at work, the last thing you’re thinking about is cable management, but dedicating a bit more effort to tidying up your workspace can make your day to day more efficient and more enjoyable.
We recommend some sort of docking station to keep your laptop, monitors, accessories and the like in check. There are plenty of options out there, regardless of if you use a macOS or Windows machine, or even a Chromebook. We like Satechi’s Dual Dock for MacBooks thanks to its unique design that allows it to sit under your laptop, and the fact that it plugs into two USB-C ports at once. This means you can connect to two external displays (provided you have an M2-powered MacBook or later), which will be handy if you have an elaborate workstation on your desk. Kensington’s Thunderbolt 4 dock is a good all-purpose option for other non-macOS laptops.
There are also USB-C hubs and adapters out there that can give you similar organization while on the go, albeit in a less elegant package. UGreen’s Revodok Pro is an affordable solution that includes an HDMI port, microSD and SD card readers, an Ethernet slot, two USB-C connections and three USB-A sockets. It also supports 100W power pass-through, so you can charge your laptop through the hub while using it.
Multicookers and air fryers
Eating healthier, or even just avoiding takeout multiple times a week, can be challenging in part because it usually means cooking more at home. This can be hard to even start if you’re not used to cooking for yourself and don’t have the basic tools to do so. On top of that, cooking takes time — much more time than ordering a meal from an app on your phone. But tools like an Instant Pot can cut your active cooking time down drastically. You can find a plethora of recipes where you simply throw a bunch of ingredients into the pot, set it and forget it until it’s time to eat.
We recommend the Instant Pot Duo for beginners because it’s relatively affordable and combines seven different cooking methods into one appliance, including rice cooking, steaming, pressure cooking, slow cooking and more. If you’re primarily cooking for yourself and a partner, the three-quart model will serve you just fine, but we recommend the six-quart model if you’re routinely cooking for four or more.
Whereas the Instant Pot and multicookers as a whole had their moment a few years ago, air fryers are the big thing now thanks in part to the fact that they let you cook so many different foods quickly and with less oil or other fat. The best air fryers come in all shapes and sizes (and from many companies), but our top pick also comes from Instant Brands. The Instant Vortex Plus air fryer doesn’t take up too much space on a countertop, includes six cooking modes and it comes with an odor-removing filter that prevents too much of that cooking smell from wafting out of the machine as it runs. We also appreciate that, unlike most other air fryers, this one has a window that lets you see into the machine during cooking so you can keep an eye on the doneness of your food.
Recipe organization
One of the best things about cooking at home is finding recipes that you love so much that you want to make over and over again. You’ll want to keep those recipes safe and readily available so you can refer to them when you need a quick weeknight meal or a dish to bring to your next family reunion. Recipe cards are a great way to do this, and you’ll build up your rolodex of delicious meals over time. If you’d rather have a cookbook of sorts that you fill in yourself over time, opt for a recipe book instead.
If you’d rather keep your arsenal of recipes accessible at any time, anywhere from your phone, Paprika’s recipe management app is the best solution I’ve tried. The $5 app basically acts as your digital recipe box, allowing you to enter your own as well as save them from the internet. You know those hundreds of words that precede online recipes, in which the author divulges their entire life story before telling you their secret to making deliciously moist cornbread? Paprika strips all of those unnecessary bits out and only saves the ingredient list and the instructions. You can also make grocery lists and keep track of pantry staples in the app, so don’t be surprised if it quickly becomes one of your most-used kitchen tools.
Reading apps
Don’t take your habit of doom-scrolling into the new year. You could instead use the internet to find other things to read and the free Libby app is a good place to start. Powered by Overdrive, it connects you with your local library’s digital collection, allowing you to borrow and download all kinds of e-books, audiobooks, magazines, graphic novels and more. Libby also has a tag system that you can use to “save” titles for later without actually putting a hold on them (although you can do that in the app, too). If you find a bunch of audiobooks you eventually want to get to, you can give them all a “TBR” tag so you can quickly find them and borrow one when you need new reading/listening material.
As someone who uses Libby on a regular basis, I love how easy it is to borrow from my local library without leaving my home. However, there have been numerous times in which my library doesn’t have a title I’m looking for. If that happens to you often, you may want to consider a subscription service like Kindle Unlimited or Everand (formerly Scribd), both of which give you unlimited access to a wide library of e-books for $10 per month. And for audiobook lovers, your options are Amazon’s Audible or Libro.fm, the latter of which lets you choose the local bookstore you want to support with your purchases.
Ereader
Ereaders are still around because so many people recognize how much better it can be to read e-books on a dedicated device — especially one with an high-contrast, e-paper display. Sure, you could read on your smartphone or a tablet, but staring at those screens all day long can be tiring for your eyes. An ereader like the Kobo Clara Colour or the Amazon Kindle is a better choice not only for its more comfortable display, but also because it focuses your attention on reading. (If you’ve ever picked up your smartphone intending to finish a chapter only to be distracted by email or Facebook, you know how crucial this is.)
The Clara Colour is our current top pick in our best ereader guide, thanks to its 6-inch color E Ink display, adjustable brightness and temperature, weeks-long battery life and handy Overdrive integration for checking out digital library books. But if you already get most of your e-books through Amazon, the latest Kindle is the best option. You can listen to Audible audiobooks, too, if you connect a pair of wireless earbuds to the ereader. Kobo’s device primarily gets books via the Kobo Store, but it also supports various file types like EPUB, PDF and MOBI.
This article originally appeared on Engadget at https://www.engadget.com/tech-to-help-you-stick-to-new-years-resolutions-150034002.html?src=rss
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.