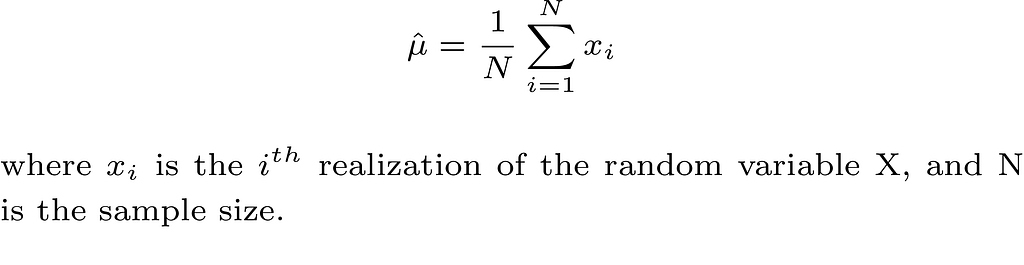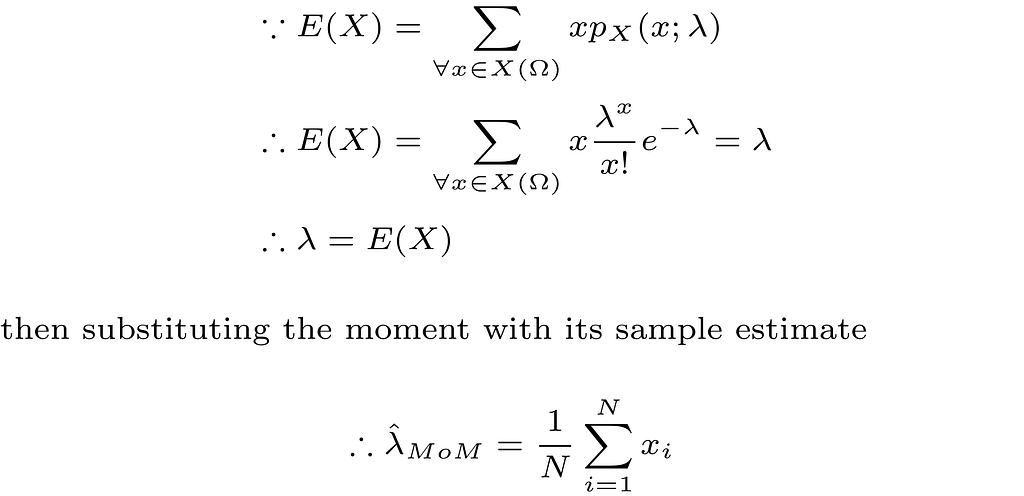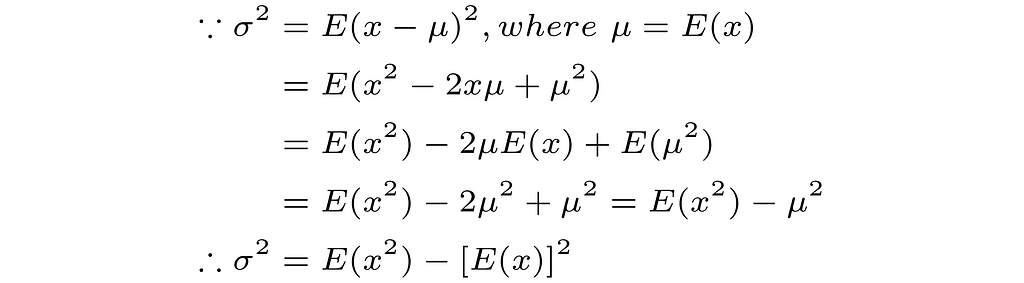WeWalk introduced a new version of its smart cane for people with visual impairments at CES 2025, bringing a redesign that addresses many of the first model’s shortcomings and adds AI features and more advanced sensors from TDK. It’s positioned as an alternative to the traditional foldable white cane. Co-founder Kursat Ceylan, who has been blind since birth, says Smart Cane 2 can make mobility easier and safer, offering features like turn-by-turn navigation and obstacle detection, along with a ChatGPT-powered voice assistant that puts on-demand information in users’ hands without the need for them to also juggle a smartphone.
The WeWalk Smart Cane 2 has a slimmer handle than its predecessor, which should make for a more comfortable grip, and the company says it’s now about as lightweight as a standard white cane. It has tactile buttons to be more user-friendly, doing away with the touchpad of the previous model that some people found to be difficult to use. Ceylan says it can be used in different weather conditions, not just when it’s warm and dry (WeWalk describes the new cane as “rainwater-resistant”).
“You can fold and unfold it when you need it. There’s a speaker, a microphone, obstacle detection technology and a flashlight to make visually impaired people more visible at night. And also it has motion sensors in itself to provide a more accurate navigation experience,” Ceylan explained.
Under the hood, the WeWalk Smart Cane 2 has an ultrasonic time-of-flight sensor, an inertial measurement unit with six-axis motion tracking, a pulse density modulated microphone and a barometric pressure sensor from electronics company TDK. When it detects something ahead, it alerts the user with both haptic and audio feedback, according to Ceylan.
He demonstrated this in the very cramped, noisy environment of the Las Vegas Convention Center, and I was able to hear over the crowd when the cane told him he was approaching an obstacle — in this case, a carpeted step marked with yellow and black tape that I saw multiple CES attendees stumble over during our conversation. It also can connect to headphones via Bluetooth.
Cheyenne MacDonald for Engadget
Paired with your smartphone, it can give navigation instructions and information about your surroundings, as well as public transportation options. “You can hear the names of stores and restaurants you are passing by,” he says. In Starbucks, where he isn’t able to read the menu, he says he might ask the assistant if they sell chocolate croissants.
“You don’t need to hold your smartphone anymore while you are going somewhere,” Ceylan said. “You can put it into your pocket and then you can get all the information through your WeWalk smart cane.” There is a smartphone interface for those who want to use it, though, which he held up through the demo so I could see what was going on on the other end. Unlike the vast majority of products I’ve encountered at CES this year that seem to include AI or ChatGPT for no real reason other than the fact that they can, this actually felt like a situation where it makes sense and could even be pretty beneficial.
Since it’s brand new, we don’t yet know how all of this will translate to real-world use. Pre-orders are now open for the WeWalk Smart Cane 2, and the first wave is expected to start shipping before the end of this month. There are two price models: $850 for the smart cane plus a subscription for the voice assistant that costs $4.99 per month, or $1150 altogether with no additional subscription fee for full use of the AI. WeWalk Smart Cane 2 is available internationally.
The London-based startup also has a partnership with the Canadian National Institute for the Blind (CNIB) that kicks off in February, when the organization will start using the WeWalk Smart Cane 2 for its cane training program. The goal is to gather meaningful data for instructors so they can really understand how people are using mobility canes (AI-enabled or otherwise), and help them get the most out of the tools. That, Ceylan says, “is so important, because the better you get around, the better you engage in life.”
This article originally appeared on Engadget at https://www.engadget.com/home/the-wewalk-smart-cane-2-could-be-one-of-ais-few-good-use-cases-at-ces-2025-182020074.html?src=rss
“A Florida man pleaded guilty today,” began a Department of Justice press release published on Tuesday. In this case, the ever-infamous Florida Man is none other than Ted Farnsworth, the former CEO of MoviePass’ parent company. His plea comes fewer than four months after another MoviePass leader, former CEO Mitch Lowe, entered a guilty plea of his own.
Farnsworth pleaded guilty to one count of securities fraud and another of conspiracy to commit securities fraud. He’ll face a maximum of 20 years in prison for the former charge and up to five for the latter. A sentencing hearing will be scheduled later.
The DOJ charged Farnsworth, 62, with scheming to defraud investors in MoviePass’ former parent company, Helios & Matheson Analytics (HMNY). The agency accused him of making false and misleading representations of HMNY’s and MoviePass’ business to artificially inflate stock and woo investors.
If that sounds familiar, it’s because former MoviePass CEO Mitch Lowe pleaded guilty to the same charges in September. Lowe reportedly agreed to cooperate with prosecutors and regulators as part of his plea, a detail one can imagine tightened the vise on Farnsworth leading up to his plea.
MoviePass subscribers paid the company $9.95 monthly for what were supposed to be unlimited movie tickets with no blackout dates. Farnsworth and Lowe told investors the business plan was tested and sustainable and would at least break even — if not turn a profit — from subscription fees alone. On top of that, they used buzzwords like “big data” and “artificial intelligence” to claim they could alchemize subscriber data, transforming it into profit.
But according to the DOJ (and… logic), that was never the case. Instead, it was a marketing gimmick to lure in new subscribers and pump HMNY’s stock price.
Farnsworth falsely claimed that MoviePass’ cost of goods (the number of tickets each subscriber bought with their subscription) naturally declined over time, which was in line with his publicly stated expectations. But the DOJ says that was because the company directed MoviePass employees to throttle subscribers who used the service to buy the most movies, preventing them from getting what was promised from their “unlimited” memberships. That aligns with reports from 2019 that employees were ordered to change the passwords of frequent moviegoers.
Unsurprisingly, the company lost money from the plan. A downward spiral commenced, MoviePass and its parent company declared bankruptcy in 2020 and the pair of Florida men in charge of the too-good-to-be-true scheme have admitted their guilt in a federal court.
This article originally appeared on Engadget at https://www.engadget.com/entertainment/former-moviepass-head-pleads-guilty-to-securities-fraud-180603455.html?src=rss
Broadly speaking, there are two types of e-bikes: Ones with a motor in one of the wheels, and ones with the motor mounted between the pedals. Those in the former group, known as hub motors, are cheap and bountiful, but lack the oomph required to cover rough terrain and high inclines. Those in the latter group, known as mid-drive motors, have all the power, but are heavy on the wallet as well on your arms as you lug them around. Consequently, I’m excited by what Urtopia turned up with to CES 2025: Titanium Zero, a 3D-printed titanium concept e-bike weighing less than 20 pounds packing Quark DM1.2, a custom-designed mid-drive motor that’s small enough to fit inside the bottom bracket and weighs just 2.6 pounds on its own. By its own admission, it’s not as brawny as chonky mid-drive models from Bafang and Bosch, but it might be a perfect alternative for less extreme trails.
Of course, right now it’s just a concept device so we should keep the salt of reasonable skepticism in our left palm at all times. Even so, Urtopia’s Titanium Zero is plenty light enough in the hand, looking a lot more like a regular steel-framed three-speed bike than an e-bike. Hell, if it didn’t have the little controller visible on the crossbar, you could easily mistake this for an old-school racing bike, down to the drop handlebars.
Daniel Cooper for Engadget
And then there’s the aforementioned Quark DM1.2, which adds another layer of theoretical desirability onto the package. Urtopia says the tiny mid-drive motor can produce 65nm of max torque, which isn’t going to give any of the bigger names any nightmares; a Bafang M560 can output 130Nm. But it’s a rough rule of thumb that a regular rear hub motor can output around 40nm, so there’s a significant performance boost. It’s the sort of hardware I’m quite eager to test on the comically steep hills near to my home, just to see if the claims match the reality.
Sadly, the Titanium Zero and Quark DM1.2 aren’t ready for prime time, and so we’ll have to wait for now.
This article originally appeared on Engadget at https://www.engadget.com/transportation/i-want-urtopias-titanium-zero-concept-e-bike-174539195.html?src=rss
This isn’t just any retro-styled microphone, but an all-in-one tool for music creators looking to record vocals when on the go. It’s the creation of Hisong, a startup looking to build a more elegant alternative to toting around a microphone, mixer and headphones wherever you go. The AirStudio One is a wireless condenser microphone with a few secrets buried inside, like a professional audio interface, a wireless USB-C dongle and a pair of true wireless headphones. The idea being you can record a banging vocal when you’re on the road without any additional hardware.
AirStudio One isn’t just a regular microphone, either, since it’s been engineered with a multi-core Digital Signal Processor to help get the best sound from its slender body. Open the companion app on your phone, and you’ll be able to mix the audio, set the EQ and even apply audio effects in real time. This isn’t the first product we’ve seen this CES that puts more of the meat inside the microphone — Shure’s MV7i carries its own two-channel audio interface.
You could also use this to record sound for your videos, and if you opt for the analog dongle, can even output your sound to any device with a 3.5mm line-in. It’s worth saying the ambient noise at CES made it impossible to test the sound quality of microphone. But this is the sort of gadget that has “intriguing prospect” stamped all over it. We’ll likely give this a deeper prod when it’s available to buy later in the year.
This article originally appeared on Engadget at https://www.engadget.com/audio/airstudio-one-is-a-portable-microphone-thats-full-of-surprises-173019602.html?src=rss
Robot vacuums are having a very weird year at CES 2025. We’ve seen robot vacs that can scoot over stairs and pick up socks. Now, another robot vacuum maker is showing off robot vacuums that can zoom around with air purifiers, tablet stands, security cameras, tabletops and other objects on top.
The SwitchBot K20+ Pro is a robot vacuum that doubles as a modular platform for other household devices. The company describes it as a “multitasking” household assistant that can perform a bunch of tasks while maybe also cleaning your floor.
The vacuum itself mostly resembles a typical robot vac, if a bit larger. It also has a connector on top that supports a wide array of attachments or even appliances. The company says it can support up to 8 kg — nearly 18 lbs — and will connect seamlessly to other SwitchBot appliances like an air purifier or home security cam. The SwitchBot vac can then be programmed to follow you around or stay in one spot.
Karissa Bell for Engadget
At SwitchBot’s booth, I saw vacuums that had a tablet stand, an air purifier with an attached tabletop and a security cam. But the company’s promotional materials also show a vacuum with a fan and a laundry basket on top. It also suggests that the K20+ Pro can deliver drinks and carry small packages around the house.
A SwitchBot rep at the booth said the company wants to allow people to 3D print their own custom parts for the K20+ Pro so that anyone can come up with their own use case for a vacuum-enabled small appliance. A video posted to the company’s YouTube channel even shows a vacuum with an arm that can pick up trash and deposit it in a wastebasket. (Yes, another robot vacuum with an arm.)
If all of this sounds a bit ridiculous, that’s because it is. While I can kind of understand the appeal of a robot vacuum that doubles as a phone or tablet stand, I can’t imagine many scenarios when I’d want a floor-level fan or air purifier zooming around my house.
I didn’t get to see any of SwitchBot’s vacuums actually moving around at its booth, so I have no idea how well any of this might work. It’s also not clear how much the K20+ Pro will cost when it goes on sale later this year, though the company is already selling some of its attachments, like the $270 air purifier/tabletop combo.
This article originally appeared on Engadget at https://www.engadget.com/home/smart-home/one-robot-vacuum-is-trying-way-too-hard-to-outdo-the-competition-at-ces-2025-171554433.html?src=rss
CES 2025 is ongoing, but if you’re wondering if some of the products showcased there are available, you’re in luck. Many of them are up for pre-order, if not already on store shelves. This year, there are wireless headphones, smart glasses and even a baby bouncer and bassinet combo.
This article originally appeared on Engadget at https://www.engadget.com/15-ces-gadgets-you-can-actually-buy-right-now-170544358.html?src=rss
Why Bayesian A/B testing can lead to misunderstandings, inflated false positive rates, introduce bias and complicate results
(Image generated by the author using Midjourney)
Over the past decade, I’ve engaged in countless discussions about Bayesian A/B testing versus Frequentist A/B testing. In nearly every conversation, I’ve maintained the same viewpoint: there’s a significant disconnect between the industry’s enthusiasm for Bayesian testing and its actual contribution, validity, and effectiveness. While the hype around Bayesian testing may have peaked, it remains widely popular.
My first exposure to Bayesian statistics was during my master’s studies, where my thesis focused on Thompson Sampling. Professionally, I encountered Bayesian A/B testing during my tenure at Wix.com, where I played a key role in transitioning from the classical method to the Bayesian method. My perspective, as described here, has been informed by both my academic background and my professional experience at Wix and beyond, where I’ve helped many companies enhance their A/B testing capabilities.
When referring to “Bayesian A/B testing”, I’m specifically talking about the methods promoted by VWO and similar approaches used in some current experimentation platforms as alternatives to the classic (Frequentist) method. There are other implementations of Bayesian statistics in A/B testing, such as Thompson sampling in Multi-armed-bandit experiments, which can be highly effective but are rare outside marketing platforms like Google Ads and Facebook Ads.
In this post, I’ll explain what Bayesian tests entail, outline the most common arguments in favor of Bayesian tests, and address each argument. I’ll then discuss the major drawbacks of the Bayesian method and, finally, cover when to use Bayesian methods in experiments.
So grab a cup of coffee, and let’s dive in.
What Do Bayesian Tests Mean?
Bayesian statistics and Frequentist statistics differ fundamentally. Bayesian statistics incorporates prior knowledge or beliefs, updating this prior information with new data to produce a posterior distribution. This allows for a dynamic and iterative process of probability assessment. In contrast, Frequentist statistics relies solely on the data at hand, using long-run frequency properties to make inferences without incorporating prior beliefs. Frequentist statistics focuses on the likelihood of observing the data given a null hypothesis and uses concepts like p-values and confidence intervals to make decisions.
In Bayesian A/B testing, we design the test in a way that after short time, and based on the data gathered so far, we could calculate the probability that the treatment variant (B) is better than the control variant (A), noted as P(B>A| Data). Another metric used is risk, or expected loss, which helps us understand the risk of making a decision based on the data collected.
Bayesian A/B testing typically involves running a test, computing P(B>A|Data) and/or the expected loss (Risk), and making a decision based on these metrics. The decision can be arbitrary or involve a stopping rule, such as:
The probability B is better than A is larger than X%. For example: P(B>A| Data) > 95%
The expected loss (Risk) is less than Y%. For example: expected loss < 1%
Arguments for Bayesian Tests
Throughout my career, I’ve encountered three common arguments in favor of Bayesian tests:
The early stopping argument — the ability to stop the experiment whenever you want (or based on a stopping rule), unlike the classic t-test / z-test that requires planning your sample size and analyzing the results only once the predefined sample size is reached. This is useful in cases where the sample size is small or when there is a very big effect and you would like to stop the test based on the results.
The prior argument — The use of prior knowledge or business knowledge to enrich data and make better decisions.
The language and terminology argument — bayesian metrics are more intuitive and suited to everyday business language compared to Frequentist metrics like p-value. Thus, “Probability B is better then A” is much more intuitive and well understood compared to “the probability of obtaining test results at least as extreme as the result actually observed, under the assumption that the null hypothesis is true” — which is the p-value definition.
Let’s tackle each argument one by one.
You Can Stop Whenever You Want
In the online industry, data is collected automatically and often displayed in real-time dashboards that include various statistical metrics. Simple classical tests, like the t-test and z-test, do not permit peeking at the results, requiring a predefined sample size and only allowing analysis once that sample size is reached.
Anyone who has ever run an A/B test knows that this is not practical. The easy accessibility of information makes it hard to ignore, especially when a product manager notices significant results, whether positive or negative, and insists on stopping the experiment to move on to the next task. This highlights the clear need for a method that allows peeking at the data and stopping early. Thus, the argument for early stopping is perhaps the strongest for Bayesian A/B tests — if only it were true.
Bayesian statistics, when considered superficially as “subjective understanding incorporating prior beliefs to the data,” allows stopping whenever. However, if you expect guarantees like “controlling the false positive rate” (as in the Frequentist approach), this is problematic.
Bayesian A/B testing is not inherently immune to the pitfalls of peeking at the data. For those looking for a good statistical explanation, please take a look at Georgry’s excellent blog post. For now, let’s address Greorgry’s point, but from a different perspective:
In the case of two variants, control and treatment, and when the number of users is large enough, the one-tailed p-value is almost identical to the Bayesian probability the control is better than the treatment, noted as P(A>B| Data) =1-P(B>A| Data). In an A/B test, a low one-tailed p-value and low P(A>B| Data) (which is equivalent to high P(B>A| Data)) indicates that the treatment is better than the control. The fact that these two measures are almost identical means that technically, early stopping based on P(B>A | Data) is equivalent to early stopping based on the p-value failing to maintain the type I error rate (false positive rate).
Although the Bayesian method does not commit to maintaining the false positive rate (aka type I error), practitioners would likely not want to see false “significant” results frequently. The notion of “stop whenever you want” is usually interpreted by practitioners as “we’re safe to draw valid conclusions at any point because we’re doing Bayesian analysis” rather than “we’re safe to draw conclusions at any point because Bayesian A/B testing doesn’t guarantee to maintain something similar to false positive rate”. We now understand that Bayesian A/B testing, in the popular way it is practiced, means the latter.
Sequential testing in the Frequentist approach, on the other hand, allows for peeking and early stopping while maintaining control over the false positive rate. Various frameworks, such as Group Sequential Testing (GSP) and the Sequential Probability Ratio Test (SPRT), enable this and are widely implemented in experimentation platforms like Optimizely, Statsig, Eppo, and A/B Smartly.
In summary, both Frequentist and Bayesian methods are not immune to the issues of peeking, but sequential testing frameworks can help mitigate these issues while making sure they do not inflate the false positive rate.
Use of Prior
The second argument in favor of Bayesian A/B testing is the use of prior knowledge. Throughout the web and conversations with practitioners, I’ve encountered comments regarding prior such as “Using prior allows you to incorporate existing and relevant business knowledge into the experiment and thereby improve performance”. These statements sound very appealing because they play on a very correct sentiment — usually using additional data is better. The more, the merrier. But anyone who understands a bit how the concept of priors in Bayesian probability works will understand that the use of priors in A/B testing is at least risky, and can lead to incorrect results.
The basic idea in Bayesian statistics is to combine any prior knowledge we have, aka prior, with the data to produce posterior distributions — knowledge that combines our prior knowledge with the data. Seemingly, there is something here that does not exist in the classical method. We are not just using the data; we are also adding more knowledge and business information that exists in our organization!
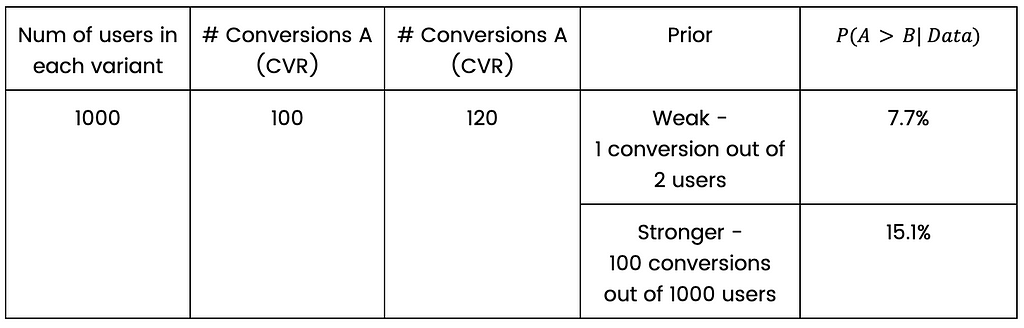
In the case of comparing two proportions — the meaning of prior is actually very simple. It is simply an addition of a virtual # of success and # of users to the data. Suppose we did such a test, and out of 1000 users in the control group, and we have 100 conversions.
Assuming my prior is “10 successes out of 100 users”, it means that my posterior knowledge is the sum of successes and users of the prior and the data. In our example: 110 “conversions” out of 1100 “users”. This is not the exact statistical definition, but it captures the idea very well.
A prior can be weak (1 success out of 10 users) or strong (1000 successes out of 10000 users for example). Both represent a knowledge that the conversion rate is 10%. In any case, when we accumulate a lot of data, the prior weight naturally decreases.
How should we incorporate prior knowledge in a two proportions A/B test? There are two options:
We incorporate, based on historical data, the general conversion rate in the population and add it to each variant. This is common practice.
We incorporate, based on historical data, which variant, control or treatment, usually show better results and give that variant an advantage based on this knowledge.
How will the prior manifest in the first option? Let’s stick to the example of 1000 users in each variant, 100 conversions to control variant and 120 conversions to treatment variant.
Suppose we know that the CVR is 10%, so an appropriate prior could be to add 100 successes and 1000 users to the existing data and then perform a statistical test as if we have 2000 users in each group, 200 conversions in control and 220 conversions in treatment. What’s described here is exactly what happens; it’s not approximately or as if — that’s the technical meaning of the prior in the case of two proportions bayesian test (assuming beta prior, for the statisticians reading this article).
A simple calculation shows that using a stronger prior in our example will increase P(A>B| Data), which means less indication for difference between variants — compared to the weak prior. That is what happens when you add the same amount of successes and users to each variant. This practice goes against our motivation to stop as early as possible, so why on earth would we want to do such a thing?
A common argument is that the Bayesian method is very liberal in choosing a winner, and the priors are a restraining factor. That’s true, the Bayesian method as I represented is very liberal, and priors are a restraining factor. So why not choose a more conservative approach (hmmm hmmm Frequentist) to begin with?
Moreover, if that is the argument, then it is clear to everyone that the glorified claim about priors that “add business information to the experiment” is misleading. If the business information is just a restraining factor, then the idea of using strong prior does not seem appealing at all.
The second option for incorporating a prior, giving one version an advantage over the other version based on historical data, is even worse. Why would anyone want to do this? Why should one experiment be influenced by the successes or failures of previous experiments? Each experiment should be a clean slate, a new opportunity to try something new without bias. Adding 200 successes to one version and 100 to the other sounds absurd and unreasonable in any way.
Language and Terminology
The third argument in favor of Bayesian A/B testing is the more intuitive language and terminology. A/B testing results are often consumed by people without strong statistical backgrounds. Frequentist metrics like p-values and confidence intervals can be unintuitive and misunderstood, even by statisticians. Many articles have been written about people’s misunderstanding of these metrics, even people with a background in statistics. I admit that it was only a considerable time after my master’s degree in statistics that I understood the exact definition of a classical CI. There is no doubt that this is a real pain point and an important one.
If you ask someone without a background in statistics to compare two versions with partial performance data for each version and ask them to formulate a question, they are likely to ask, “What is the probability that this version is better than the other version?” The same is true for confidence intervals. Most likely, when you explain the definition of a Frequentist confidence interval to someone, they will understand it in a Bayesian way.
This argument is actually true. I agree that Bayesian statistical metrics are much more intuitive to the common practitioner, and I agree that it is preferred that the statistical language will be as simple as possible and well understood, since A/B testing is mostly being conducted and consumed by non-statisticians. However, I don’t think it’s a disaster that practitioners don’t fully understand the statistical terms and results. Most of them are thinking in terms of “winning” and “losing” and it’s okay.
I recall, when I was at Wix, showing our new Bayesian A/B testing dashboard to a product manager as part of a usability test, to learn how he reads it and what he understands. His approach was very simple — searching for “greens” and “reds” KPIs and ignoring the “grays” KPIs. He didn’t really care if it was a p-value or probability B is better than A, a confidence interval or a credible interval. I bet that if he knew, it would rarely change his decision about the test.
Major Drawbacks of the Bayesian Method
So far, we have discussed the alleged advantages of using the popular Bayesian method for A/B testing and why some of them are not correct or meaningful enough. There are also very considerable disadvantages to using the Bayesian method:
The lack of maximum sample size
The lack of guidelines and framework to make a decision regarding the test when the results are inconclusive.
These drawbacks are significant, especially since most experiments do not show a significant effect.
Let’s assume we run an experiment which does not affect the KPI we are interested in at all. In most cases, the data will indicate indecision, and we will not be sure what to do next. Should we continue the experiment and collect more data? Or go with the more probable variant even if the results are not conclusive?
One can argue that predefined sample size is a limiting factor, but it also provides an important framework for decision-making. We decide upon a sample size, and we know that we will be able, with high probability (known as statistical power), detect a predefined effect size. If we are smart enough, we will use a sequential testing method that will allow us to stop before we reach the maximum predefined sample size.
It is true that when using one of the Bayesian stopping rules mentioned before, the test will eventually end even if there is no effect. For example, the risk will gradually, and slowly, decrease and eventually will reach the predefined threshold. The problem is it will take a very long time when there is no difference between the variants. So long that in reality practitioners will likely won’t have the patience to wait. They will stop the experiment once they feel there is no point in continuing.
When to Use Bayesian Methods in Experiments
In Multi-Armed Bandit (MAB) experiments, Bayesian statistics flourish and are considered best practice. In these types of experiments, there are usually several variants (for example several ads creative) and we want to quickly decide which ads are performing the best. When the experiment begins, users are allocated equally to all variants, but after some data is gathered, the allocation changes and more users are allocated to the better performing variant (ad). Eventually, (almost) all users are allocated to the best performing variant (ad).
I also came across an interesting Bayesian A/B testing framework in an article published by Microsoft, but I never met any organization using the suggested methodology, and it still lacks a maximum sample size which should be very important to practitioners.
Conclusion
While Bayesian A/B testing offers a more intuitive framework and the ability to incorporate prior knowledge, it falls short in critical areas. The promises of early stopping and better decision-making are not inherently guaranteed by Bayesian methods and can lead to misunderstandings and inflated false positive rates if not carefully managed. Additionally, the use of priors can introduce bias and complicate results rather than clarify them. The Frequentist approach, with its structured methodology and sequential testing options, provides more reliable and transparent results, especially in environments where rigorous decision-making is essential.
Let’s say you are in a customer care center, and you would like to know the probability distribution of the number of calls per minute, or in other words, you want to answer the question: what is the probability of receiving zero, one, two, … etc., calls per minute? You need this distribution in order to predict the probability of receiving different number of calls based on which you can plan how many employees are needed, whether or not an expansion is required, etc.
In order to let our decision ‘data informed’ we start by collecting data from which we try to infer this distribution, or in other words, we want to generalize from the sample data to the unseen data which is also known as the population in statistical terms. This is the essence of statistical inference.
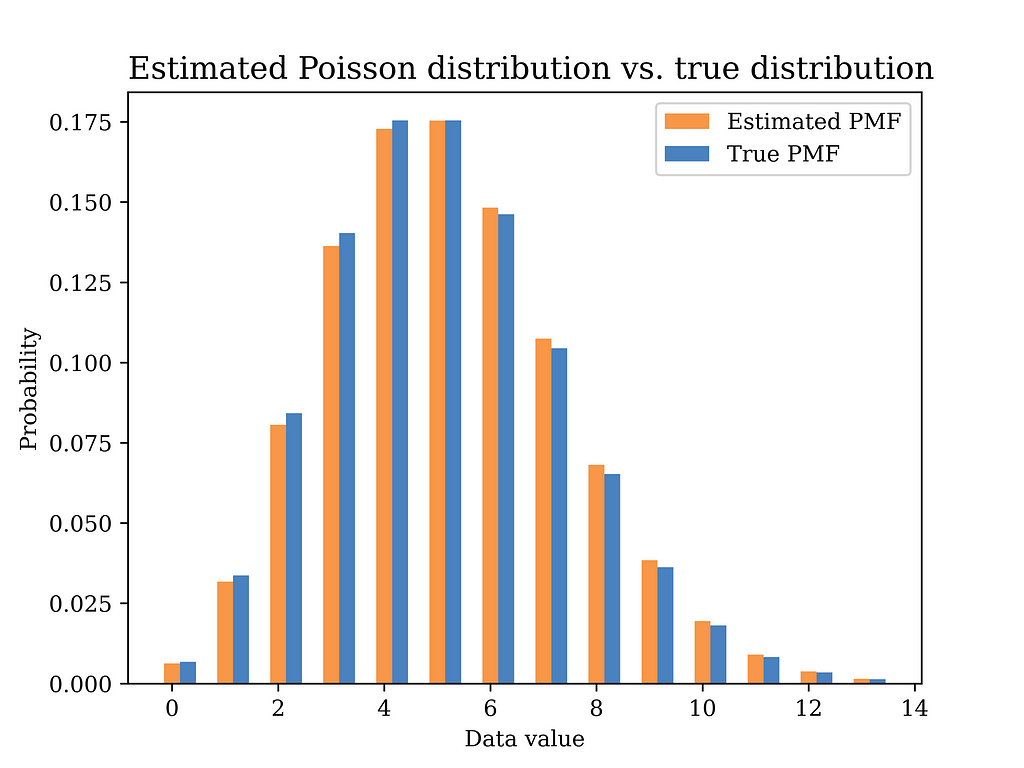
From the collected data we can compute the relative frequency of each value of calls per minute. For example, if the collected data over time looks something like this: 2, 2, 3, 5, 4, 5, 5, 3, 6, 3, 4, … etc. This data is obtained by counting the number of calls received every minute. In order to compute the relative frequency of each value you can count the number of occurrences of each value divided by the total number of occurrences. This way you will end up with something like the grey curve in the below figure, which is equivalent to the histogram of the data in this example.
Image generated by the Author
Another option is to assume that each data point from our data is a realization of a random variable (X) that follows a certain probability distribution. This probability distribution represents all the possible values that are generated if we were to collect this data long into the future, or in other words, we can say that it represents the population from which our sample data was collected. Furthermore, we can assume that all the data points come from the same probability distribution, i.e., the data points are identically distributed. Moreover, we assume that the data points are independent, i.e., the value of one data point in the sample is not affected by the values of the other data points. The independence and identical distribution (iid) assumption of the sample data points allows us to proceed mathematically with our statistical inference problem in a systematic and straightforward way. In more formal terms, we assume that a generative probabilistic model is responsible for generating the iid data as shown below.
Image generated by the Author
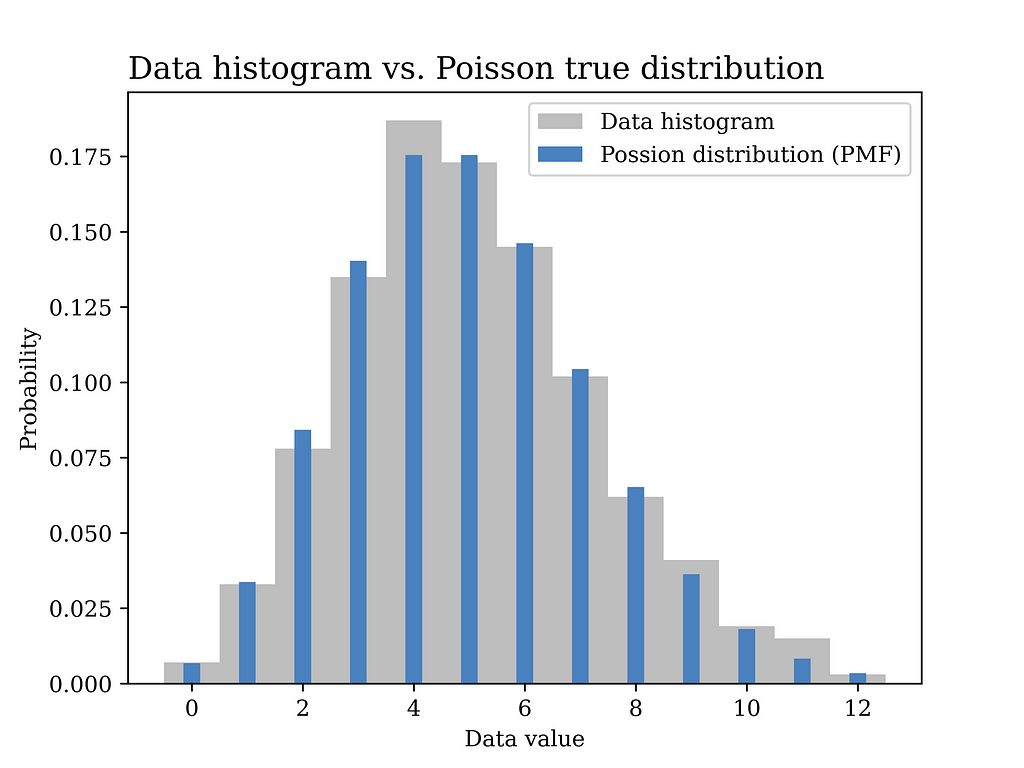
In this particular example, a Poisson distribution with mean value λ = 5 is assumed to have generated the data as shown in the blue curve in the below figure. In other words, we assume here that we know the true value of λ which is generally not known and needs to be estimated from the data.
Image generated by the Author
As opposed to the previous method in which we had to compute the relative frequency of each value of calls per minute (e.g., 12 values to be estimated in this example as shown in the grey figure above), now we only have one parameter that we aim at finding which is λ. Another advantage of this generative model approach is that it is better in terms of generalization from sample to population. The assumed probability distribution can be said to have summarized the data in an elegant way that follows the Occam’s razor principle.
Before proceeding further into how we aim at finding this parameter λ, let’s show some Python code first that was used to generate the above figure.
# Import the Python libraries that we will need in this article import pandas as pd import matplotlib.pyplot as plt import numpy as np import seaborn as sns import math from scipy import stats
# Poisson distribution example lambda_ = 5 sample_size = 1000 data_poisson = stats.poisson.rvs(lambda_,size= sample_size) # generate data
# Plot the data histogram vs the PMF x1 = np.arange(data_poisson.min(), data_poisson.max(), 1) fig1, ax = plt.subplots() plt.bar(x1, stats.poisson.pmf(x1,lambda_), label="Possion distribution (PMF)",color = BLUE2,linewidth=3.0,width=0.3,zorder=2) ax.hist(data_poisson, bins=x1.size, density=True, label="Data histogram",color = GRAY9, width=1,zorder=1,align='left')
Our problem now is about estimating the value of the unknown parameter λ using the data we collected. This is where we will use the method of moments (MoM) approach that appears in the title of this article.
First, we need to define what is meant by the moment of a random variable. Mathematically, the kth moment of a discrete random variable (X) is defined as follows
Take the first moment E(X) as an example, which is also the mean μ of the random variable, and assuming that we collect our data which is modeled as N iid realizations of the random variable X. A reasonable estimate of μ is the sample mean which is defined as follows
Thus, in order to obtain a MoM estimate of a model parameter that parametrizes the probability distribution of the random variable X, we first write the unknown parameter as a function of one or more of the kth moments of the random variable, then we replace the kth moment with its sample estimate. The more unknown parameters we have in our models, the more moments we need.
In our Poisson model example, this is very simple as shown below
In the next part, we test our MoM estimator on the simulated data we had earlier. The Python code for obtaining the estimator and plotting the corresponding probability distribution using the estimated parameter is shown below.
# Method of moments estimator using the data (Poisson Dist) lambda_hat = sum(data_poisson) / len(data_poisson)
ax.set_title("Estimated Poisson distribution vs. true distribution", fontsize=14, loc='left') ax.set_xlabel('Data value') ax.set_ylabel('Probability') ax.legend() #ax.grid() plt.savefig("Possion_true_vs_est.png", format="png", dpi=800)
The below figure shows the estimated distribution versus the true distribution. The distributions are quite close indicating that the MoM estimator is a reasonable estimator for our problem. In fact, replacing expectations with averages in the MoM estimator implies that the estimator is a consistent estimator by the law of large numbers, which is a good justification for using such estimator.
Image generated by the Author
Another MoM estimation example is shown below assuming the iid data is generated by a normal distribution with mean μ and variance σ² as shown below.
Image generated by the Author
In this particular example, a Gaussian (normal) distribution with mean value μ = 10 and σ = 2 is assumed to have generated the data. The histogram of the generated data sample (sample size = 1000) is shown in grey in the below figure, while the true distribution is shown in the blue curve.
Image generated by the Author
The Python code that was used to generate the above figure is shown below.
# Normal distribution example mu = 10 sigma = 2 sample_size = 1000 data_normal = stats.norm.rvs(loc=mu, scale=sigma ,size= sample_size) # generate data
# Plot the data histogram vs the PDF x2 = np.linspace(data_normal.min(), data_normal.max(), sample_size) fig3, ax = plt.subplots() ax.hist(data_normal, bins=50, density=True, label="Data histogram",color = GRAY9) ax.plot(x2, stats.norm(loc=mu, scale=sigma).pdf(x2), label="Normal distribution (PDF)",color = BLUE2,linewidth=3.0)
Now, we would like to use the MoM estimator to find an estimate of the model parameters, i.e., μ and σ² as shown below.
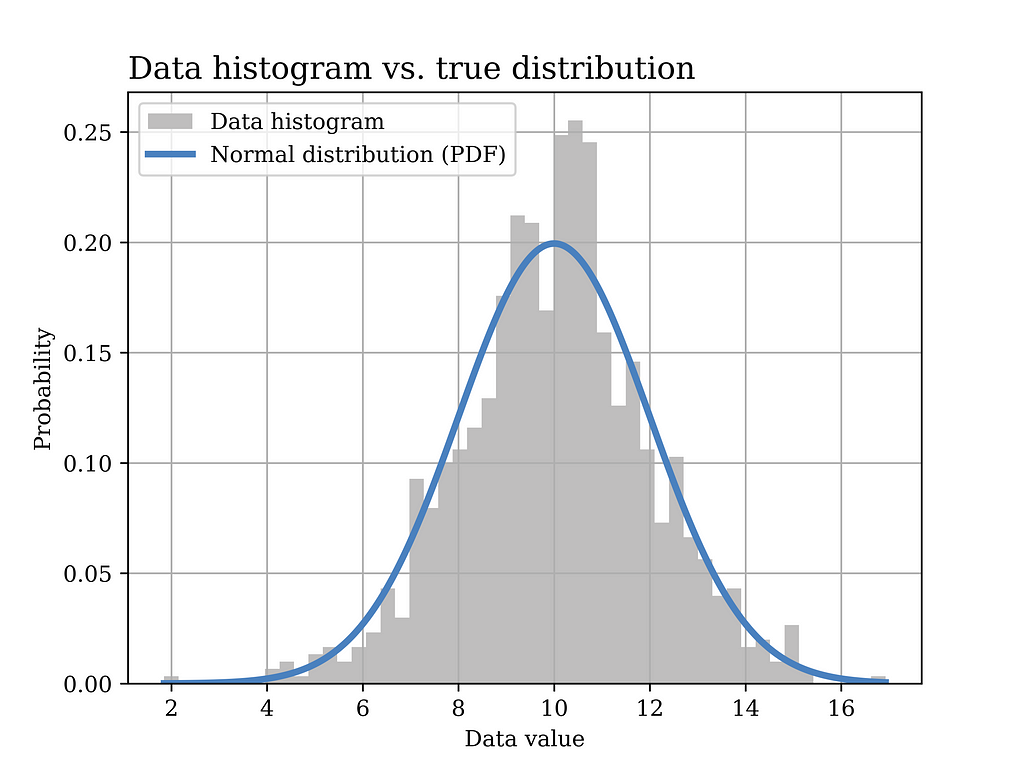
In order to test this estimator using our sample data, we plot the distribution with the estimated parameters (orange) in the below figure, versus the true distribution (blue). Again, it can be shown that the distributions are quite close. Of course, in order to quantify this estimator, we need to test it on multiple realizations of the data and observe properties such as bias, variance, etc. Such important aspects have been discussed in an earlier article Bias Variance Tradeoff in Parameter Estimation with Python Code | by Mahmoud Abdelaziz, PhD | Medium
Image generated by the Author
The Python code that was used to estimate the model parameters using MoM, and to plot the above figure is shown below.
# Method of moments estimator using the data (Normal Dist) mu_hat = sum(data_normal) / len(data_normal) # MoM mean estimator var_hat = sum(pow(x-mu_hat,2) for x in data_normal) / len(data_normal) # variance sigma_hat = math.sqrt(var_hat) # MoM standard deviation estimator
# Plot the MoM estimated PDF vs the true PDF x2 = np.linspace(data_normal.min(), data_normal.max(), sample_size) fig4, ax = plt.subplots() ax.plot(x2, stats.norm(loc=mu_hat, scale=sigma_hat).pdf(x2), label="Estimated PDF",color = ORANGE1,linewidth=3.0) ax.plot(x2, stats.norm(loc=mu, scale=sigma).pdf(x2), label="True PDF",color = BLUE2,linewidth=3.0)
ax.set_title("Estimated Normal distribution vs. true distribution", fontsize=14, loc='left') ax.set_xlabel('Data value') ax.set_ylabel('Probability') ax.legend() ax.grid() plt.savefig("Normal_true_vs_est.png", format="png", dpi=800)
Another useful probability distribution is the Gamma distribution. An example for the application of this distribution in real life was discussed in a previous article. However, in this article, we derive the MoM estimator of the Gamma distribution parameters α and β as shown below, assuming the data is iid.
Image generated by the Author
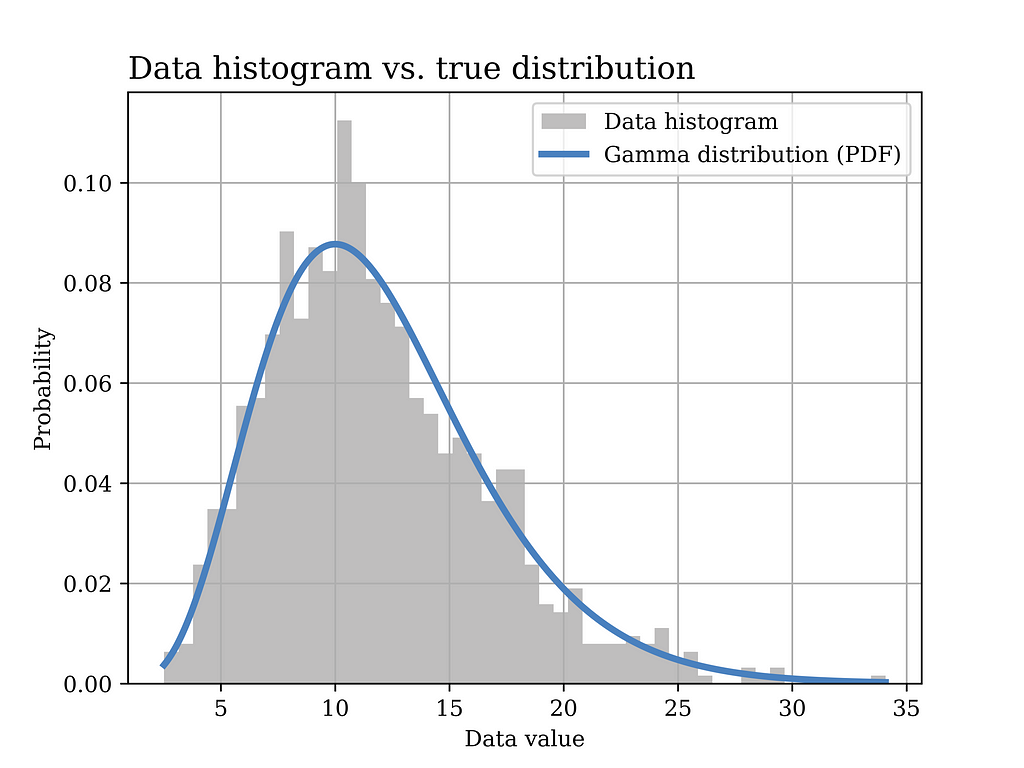
In this particular example, a Gamma distribution with α = 6 and β = 0.5 is assumed to have generated the data. The histogram of the generated data sample (sample size = 1000) is shown in grey in the below figure, while the true distribution is shown in the blue curve.
Image generated by the Author
The Python code that was used to generate the above figure is shown below.
# Gamma distribution example alpha_ = 6 # shape parameter scale_ = 2 # scale paramter (lamda) = 1/beta in gamma dist. sample_size = 1000 data_gamma = stats.gamma.rvs(alpha_,loc=0, scale=scale_ ,size= sample_size) # generate data
# Plot the data histogram vs the PDF x3 = np.linspace(data_gamma.min(), data_gamma.max(), sample_size) fig5, ax = plt.subplots() ax.hist(data_gamma, bins=50, density=True, label="Data histogram",color = GRAY9) ax.plot(x3, stats.gamma(alpha_,loc=0, scale=scale_).pdf(x3), label="Gamma distribution (PDF)",color = BLUE2,linewidth=3.0)
Now, we would like to use the MoM estimator to find an estimate of the model parameters, i.e., α and β, as shown below.
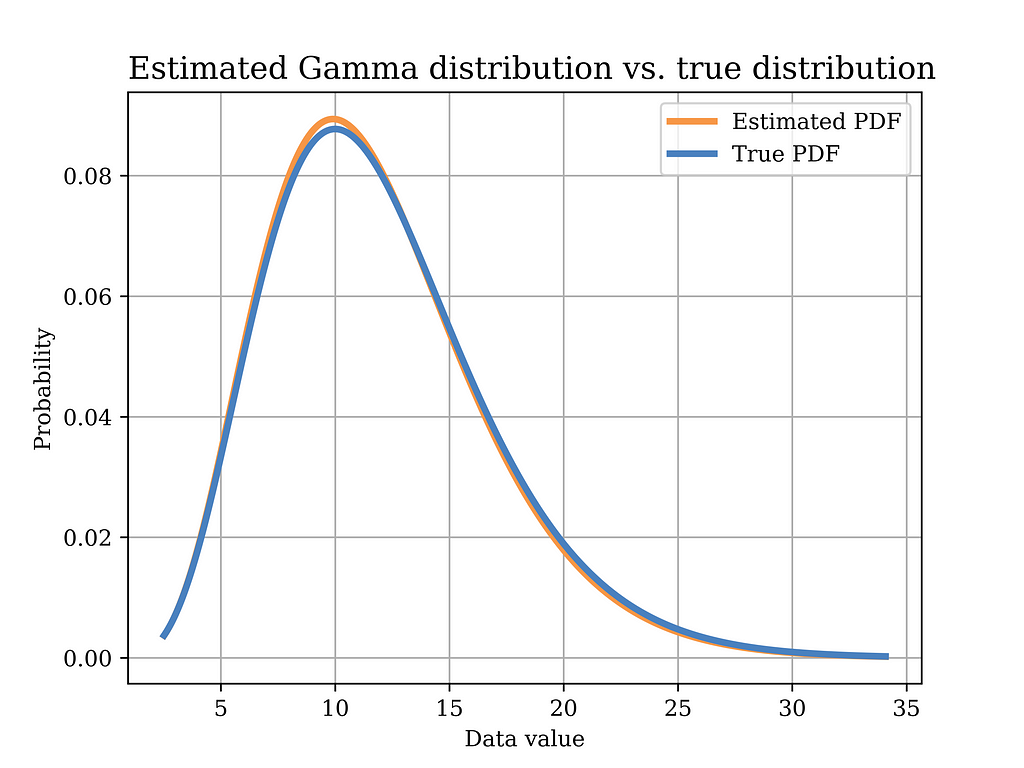
In order to test this estimator using our sample data, we plot the distribution with the estimated parameters (orange) in the below figure, versus the true distribution (blue). Again, it can be shown that the distributions are quite close.
Image generated by the Author
The Python code that was used to estimate the model parameters using MoM, and to plot the above figure is shown below.
# Method of moments estimator using the data (Gamma Dist) sample_mean = data_gamma.mean() sample_var = data_gamma.var() scale_hat = sample_var/sample_mean #scale is equal to 1/beta in gamma dist. alpha_hat = sample_mean**2/sample_var
# Plot the MoM estimated PDF vs the true PDF x4 = np.linspace(data_gamma.min(), data_gamma.max(), sample_size) fig6, ax = plt.subplots()
ax.set_title("Estimated Gamma distribution vs. true distribution", fontsize=14, loc='left') ax.set_xlabel('Data value') ax.set_ylabel('Probability') ax.legend() ax.grid() plt.savefig("Gamma_true_vs_est.png", format="png", dpi=800)
Note that we used the following equivalent ways of writing the variance when deriving the estimators in the cases of Gaussian and Gamma distributions.
Conclusion
In this article, we explored various examples of the method of moments estimator and its applications in different problems in data science. Moreover, detailed Python code that was used to implement the estimators from scratch as well as to plot the different figures is also shown. I hope that you will find this article helpful.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.