Automating scientific code documentation: a GPT-powered POC for streamlined workflows.
Introduction
Working on scientific papers often involves translating algorithms into scientific formulas, typically formatted in LaTeX. This process can be tedious and time-consuming, especially in large projects, as it requires constant back-and-forth between the code repository and the LaTeX document.
While working on a large repository of algorithms, I began exploring ways to streamline this workflow. My motivation arose from the inefficiency of manually converting complex algorithms into LaTeX-compatible formulas. A particular challenge was ensuring consistency across multiple documents, especially in projects where formulas required frequent updates. This led me to explore how automation could streamline repetitive tasks while improving accuracy.
For the remainder of this document, I will use both the term “algorithm” and “scientific code.” All images in this article, except for the cover image, were created by the author.
Goal
My goal was to transition from scientific code to a comprehensive document that introduces the purpose of the code, defines variables, presents scientific formulas, includes a generated example plot, and demonstrates the calculations for a specific example. The document would follow a predefined framework, combining static and dynamic elements to ensure both consistency and adaptability.
The framework I designed included the following structure:
- Front Page
A visually appealing cover with key details such as the title and author. - Table of Contents
Automatically generated to provide an overview of the document’s content. - Brief Description of the Document
An introduction outlining the purpose and scope of the document. - Algorithms
A section dedicated to documenting each algorithm in detail. For each algorithm, the following subsections would be included:
– Introduction: A brief overview of the algorithm’s purpose and context.
– Variables: A clear definition of all variables used in the algorithm.
– Formulas: A presentation of the key formulas derived from the algorithm.
– Example: A worked example to illustrate the algorithm’s application, complete with a generated plot.
– Code: The corresponding code snippet to support reproducibility.
This structure was designed to dynamically adapt based on the number of algorithms being documented, ensuring a consistent and professional presentation regardless of the document’s size or complexity.
Structuring the Repository
To achieve this goal, a well-organized repository was essential for enabling a scalable and efficient solution. The algorithm calculations were grouped into a dedicated folder, with files named using a consistent snake_case convention that matched the algorithm names.
To ensure clarity and support reuse, initial values for examples and the generated plots were stored in separate folders. These folders followed the same naming convention as the algorithms but with distinct suffixes to differentiate their purpose. This structure ensured that all components were easy to find and consistent with the overall framework of the project.
Leveraging GPT for Automation
At the core of this project is the use of GPT models to automate the conversion of algorithms into LaTeX. GPT’s strength lies in its ability to interpret the structure of generic, variable-rich code and transform it into human-readable explanations and precisely formatted scientific formulas. This automation significantly reduces the manual effort required, ensuring both accuracy and consistency across documents.
For this project, I will leverage OpenAI’s ChatGPT-4o model, renowned for its advanced ability to comprehend and generate structured content. To interact with OpenAI’s API, you must have an OPENAI_KEY set in your environment. Below is a simple Python function I use to fetch responses from the GPT model:
import os
from openai import OpenAI
from dotenv import load_dotenv
def ask_chat_gpt(prompt):
load_dotenv()
api_key = os.getenv("OPENAI_KEY") or exit("API key missing")
client = OpenAI(api_key=api_key)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
Workflow
Overview of What the Code Does
This code automates the generation of structured LaTeX documentation for Python algorithms, complete with examples, plots, and Python code listings. Here’s an overview:
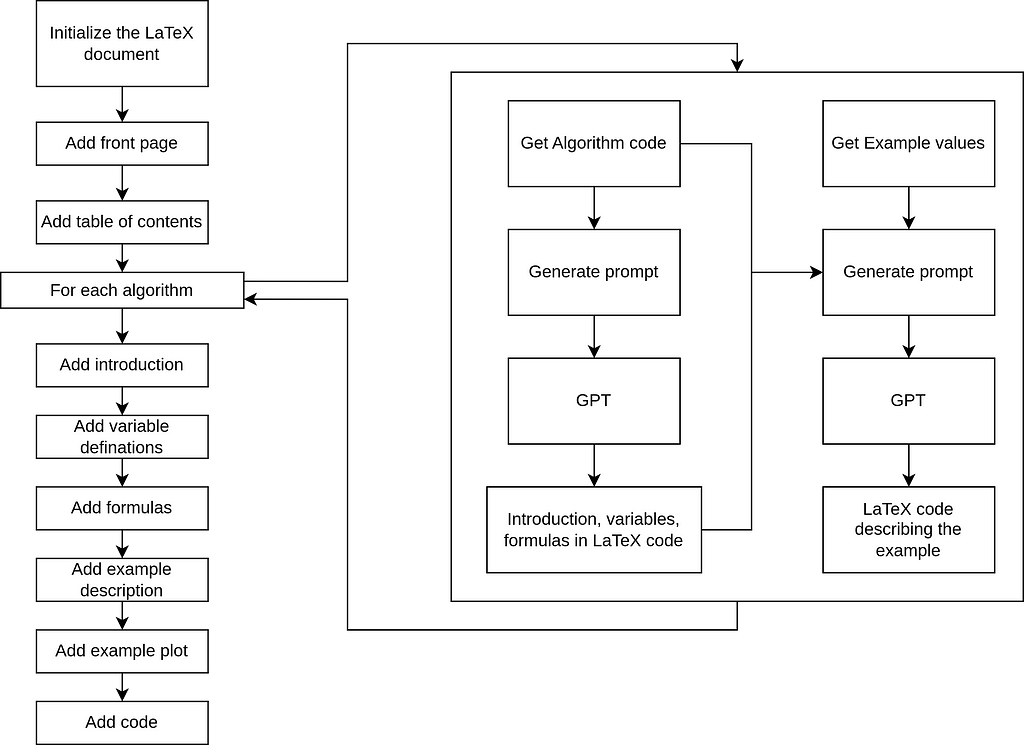
Prompt Creation for GPT
This section describes custom functions designed to generate detailed prompts for GPT, enabling the automated creation of LaTeX documentation:
- make_algo_doc_gpt_prompt: A function that creates prompts instructing GPT to generate LaTeX sections, including introductions, variable descriptions, formulas, and example subsections.
- make_algo_example_gpt_prompt: A function that generates prompts for creating LaTeX example sections, incorporating plots and example calculations.
Document Generation
These functions are responsible for processing the GPT-generated content and saving it as LaTeX files:
- make_algo_doc: A function that uses GPT outputs to generate LaTeX documentation for each algorithm and saves it as a .tex file.
- make_algo_example: A function that creates .tex files for example sections, including plots and example calculations.
LaTeX Assembly
- Uses the pylatex library to programmatically create a full LaTeX document.
- Adds a title page, metadata, and a table of contents.
- Includes an introduction section with an overview of the algorithms and their purpose.
- Creates a chapter for each algorithm with sections from make_algo_doc and make_algo_example, example plots, and Python code listings.
# Create and structure the LaTeX document programmatically
doc = Document(documentclass="report")
# Include preamble and metadata
doc.preamble.append(NoEscape(r'input{algo_docs/init.tex}')) # Custom preamble
doc.append(NoEscape(r'input{algo_docs/title_page.tex}')) # Title page
doc.append(NoEscape(r'tableofcontents')) # Table of contents
# Add Introduction Chapter
with doc.create(Chapter('Introduction')):
doc.append(
'This document provides an overview of various algorithms, exploring their design, analysis, and application in computational problem-solving. '
'The aim is to facilitate understanding of their mechanisms and significance across different domains.'
)
# Add Algorithms Chapter
with doc.create(Chapter('Algorithms')):
doc.append(
'This chapter presents detailed analyses of various algorithms, highlighting their theoretical foundations, use cases, and practical insights. '
'Each algorithm is accompanied by examples and visualizations to illustrate its functionality and potential limitations.'
)
# Process each Python file in the 'python_code' directory
python_code_dir = "python_code/"
output_folder = "algo_docs/"
plot_folder = "plots/"
for filename in os.listdir(python_code_dir):
if filename.endswith(".py"): # Process only Python files
algorithm_name = filename.replace(".py", "")
formatted_name = algorithm_name.replace("_", " ").title()
# Define paths for documentation files and plots
document_path = os.path.join(output_folder, f"{algorithm_name}_doc.tex")
example_path = os.path.join(output_folder, f"{algorithm_name}_example.tex")
plot_path = os.path.join(plot_folder, f"{algorithm_name}_plot.png")
python_code_path = os.path.join(python_code_dir, filename)
print(f"Processing: {filename}")
# Start a new page for each algorithm
doc.append(NoEscape(r'newpage'))
# Generate documentation and example files with GPT
make_algo_doc(algorithm_name)
make_algo_example(algorithm_name)
# Insert generated LaTeX sections
doc.append(NoEscape(rf'input{{{document_path}}}'))
doc.append(NoEscape(rf'input{{{example_path}}}'))
# Insert plot directly after example subsection
if os.path.exists(plot_path):
with doc.create(Figure(position='H')) as figure:
figure.add_image(plot_path, width=NoEscape(r'textwidth'))
figure.add_caption(f'Example plot for {formatted_name}.')
# Add a subsection for the Python code listing
with doc.create(Subsection('Code Listing')):
doc.append(NoEscape(rf'lstinputlisting[language=Python]{{{python_code_path}}}'))
# Add a page break for clarity
doc.append(NoEscape(r'clearpage'))
# Generate the LaTeX file
tex_file = "programmatic_report"
doc.generate_tex(tex_file)
# Compile the LaTeX file to a PDF
subprocess.run(["pdflatex", f"{tex_file}.tex"])
PDF Compilation
- The assembled document is saved and compiled into a polished PDF using pdflatex.


Crafting Effective Prompts: The Core Challenge
One of the most challenging aspects of this project was designing and refining the prompts used to interact with GPT. The success of the entire process depended on the quality of the GPT-generated output, making the creation of effective prompts a critical task that required extensive time and experimentation.
The prompts needed to strike a delicate balance:
- Clarity: Precisely guiding GPT to produce structured LaTeX content, including sections, subsections, and mathematical equations, while leaving no ambiguity about the desired format.
- Adaptability: Ensuring the prompts could handle a wide variety of algorithms, ranging from simple calculations to complex implementations.
- Consistency: Achieving reliable, well-formatted, and accurate output, even for edge cases or unconventional code structures.
To address these challenges, I implemented dynamic prompting. This approach involved programmatically generating prompts tailored to the contents of each file. By providing GPT with relevant context and specific instructions, dynamic prompting ensured the output was both accurate and contextually appropriate for the given algorithm.
Through numerous iterations, the prompts evolved to become precise and flexible, forming the foundation of the automation process.
Example of a prompt for generating LaTeX code from a algorithm:
Generate LaTeX code from the provided Python code. Follow these guidelines:
1. **Document Structure**:
- Start with `\section{}` for the algorithm title.
- Add a `\subsection{Introduction}` for a brief overview of the algorithm.
- Include a `\subsection{Variables}` section that lists all variables with descriptions, using subscript notation (e.g., `v_{\text{earth}}`).
- Add a `\subsection{Formulas}` section presenting the code's logic as LaTeX formulas. Use subscripted symbols for variable names instead of copying Python variable names directly.
2. **Formatting Rules**:
- Ensure that the output includes **only** the LaTeX content, without `\documentclass`, `\usepackage`, `\begin{document}`, `\end{document}`, or any unrelated text.
- Do **not** include the triple backticks (e.g., ```latex or ```).
- Properly close all LaTeX environments (e.g., `\begin{align*}...\end{align*}`).
- Ensure all brackets, parentheses, and braces are matched correctly.
- Maintain consistent subscript notation for all variables.
3. **Important Notes**:
- **Do not** include any text or explanations outside the LaTeX code.
- Only the relevant LaTeX content for the `\section`, `\subsection`, `\begin{align*}`, and `\end{align*}` parts should be generated.
- Ensure no extra or unrelated LaTeX sections are added.
Example: Hohmann Transfer Orbit Calculation
The following demonstrates how the Hohmann Transfer Orbit Calculation algorithm is documented using GPT-generated LaTeX code. This algorithm calculates the velocity changes (delta-v) required to transfer a spacecraft from Earth’s orbit to Mars’s orbit. Below is the Python implementation of the algorithm:
def calculate_hohmann_transfer(earth_orbit_radius, mars_orbit_radius):
# Gravitational constant for the Sun
mu_sun = 1.32712440018e20
# Orbital velocities of Earth and Mars
v_earth = np.sqrt(mu_sun / earth_orbit_radius)
v_mars = np.sqrt(mu_sun / mars_orbit_radius)
# Semi-major axis of the transfer orbit
transfer_orbit_semi_major_axis = (earth_orbit_radius + mars_orbit_radius) / 2
# Transfer orbit velocities at Earth and Mars
v_transfer_at_earth = np.sqrt(2 * mu_sun / earth_orbit_radius - mu_sun / transfer_orbit_semi_major_axis)
v_transfer_at_mars = np.sqrt(2 * mu_sun / mars_orbit_radius - mu_sun / transfer_orbit_semi_major_axis)
# Delta-v at Earth and Mars
delta_v_earth = v_transfer_at_earth - v_earth
delta_v_mars = v_mars - v_transfer_at_mars
# Total delta-v for the transfer
total_delta_v = abs(delta_v_earth) + abs(delta_v_mars)
return delta_v_earth, delta_v_mars, total_delta_v
Using the GPT prompt with this code, I generated LaTeX subsections for the documentation. Below are the components created:
Introduction to the Algorithm
GPT generated a LaTeX explanation of the algorithm’s purpose, detailing how it calculates velocity changes for an efficient interplanetary transfer.

Variable Definitions
GPT provided a clear explanation of all variables used in the algorithm.

Formulas
The key formulas used in the algorithm were formatted into LaTeX by GPT.

Example Section
Using example values, GPT generated LaTeX code for a worked example.

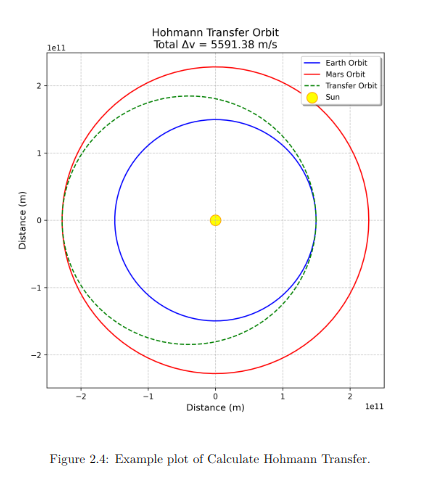
Plot Generation
A plot of the transfer orbit was generated using the example values and included in the LaTeX document.
Code Listing
The algorithm’s source code was appended to the document for completeness at the end.

Results and Challenges
Initial experiments with this system have been promising. Using Python and GPT-4, I successfully automated the conversion of several algorithms into LaTeX documents. The results of this proof of concept (POC) can be explored in my GitHub repository, where all aspects of the project are available for review.
The repository includes the complete Python codebase, showcasing the custom functions used to generate LaTeX documentation and create GPT prompts. It also contains the detailed prompts themselves, illustrating how the system guides GPT in producing structured and accurate LaTeX content. Additionally, the repository features the final outputs, including both the LaTeX source files and the compiled PDF documents.
While the initial results have been promising, the process has not been without its challenges and valuable insights along the way::
- Formatting Challenges: Occasionally, GPT would produce incorrect LaTeX formatting, leading to errors during the PDF conversion process. Although this issue was rare, I experimented with a solution: resubmitting the LaTeX code to GPT and asking it to fix the formatting. While this approach was consistently successful, it was not implemented as part of the workflow.
- Code Comments: Adding clear comments within the code helped GPT understand the context better and generate more accurate LaTeX outputs.
- Inconsistent Results: GPT occasionally produced varying outputs for the same code and prompt, emphasizing its inherent variability and the importance of careful testing.
- Crafting Effective Prompts: Writing effective prompts was challenging. Overloading the prompt with too much detail, like examples, often caused GPT to miss smaller elements such as formatting or structure. I discovered that breaking down instructions step by step and using very small, focused examples helped GPT perform better. Keeping prompts concise and structured with bullet points ensured that each key instruction was clearly understood and executed.
- Domain-Specific Terminology: Fine-tuning GPT for specialized terms is an area requiring further improvement to enhance accuracy.
- Variable Definitions: Keeping LaTeX variable definations in algorithm and examples consistent was challenging. Adding GPT-generated variable definitions to later prompts helped maintain uniformity.
Despite its imperfections, the workflow has drastically reduced the time spent on documentation by automating much of the process. While minor reviews and adjustments are still needed, they represent only a fraction of the effort previously required. This proof of concept demonstrates the potential to generate polished documents without writing LaTeX manually, though further refinement is needed to enhance consistency, scalability, and adaptability. The results so far highlight the significant promise of this approach.
Improvements
- Develop Validation Mechanisms
Implement cross-referencing of generated formulas against known standards or benchmarks to ensure accuracy and consistency. - Expand Use Cases
Test the workflow on larger, more diverse datasets to improve scalability and adaptability for various scientific domains. - Enhance Visual Documentation
Incorporate additional visual elements, such as flowcharts, by using GPT to generate XML documents or similar formats. - Generate Plots and Examples with GPT
Extend GPT’s functionality to create example plots directly, reducing the reliance on external plotting tools. - Experiment with Different GPT Models
Thus far, I have primarily used ChatGPT-4 due to its accessibility, but further research is needed to identify the optimal model for this task. Exploring models tailored for technical content or incorporating a Retrieval-Augmented Generation (RAG) approach with a database of diverse scientific papers could improve accuracy and relevance. - Transition from Proof of Concept (POC) to Minimum Viable Product (MVP)
Evolve the project from a proof of concept to a minimum viable product by adding robust error handling, scalability features, and user-focused refinements.
Conclusion
This project has proven the potential of GPT models to automate the creation of structured LaTeX documentation, significantly reducing the manual effort involved. It successfully generated professional-quality outputs, including formulas, plots, and structured examples. However, challenges such as inconsistent results, formatting issues, and variability in GPT’s output highlighted the need for refinement. Strategies like dynamic prompting, better code commenting, and iterative validation have helped address these issues, but some manual oversight remains necessary.
Despite these challenges, the workflow has shown clear benefits, streamlining the documentation process and saving considerable time. While the solution is not yet perfect, it represents a significant step toward automating complex documentation tasks, paving the way for future improvements in accuracy.
From Code to Paper: Using GPT Models and Python to Generate Scientific LaTeX Documents was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
From Code to Paper: Using GPT Models and Python to Generate Scientific LaTeX Documents