What happens when you combine the satiric spirit of filmmaker Mel Brooks and cram into a parody of the galaxy exploring No Man’s Sky? You get something like Journey to the Savage Planet, a funny, world conquering blaster fest that proves Ian Malcolm’s chaos theory of colonization while also providing a healthy dose of good, ol’ fashioned fart jokes.
Unfortunately, the game’s original studio Typhoon Studios got swallowed up and spat out when Google closed down its Stadia Games and Entertainment division and all of its studios in 2019. Fortunately for us, some of those developers got back together, formed a new outfit called Raccoon Logic, raised some investment money from Tencent and took back the rights to their game for a brand new adventure.
A sequel called Revenge of the Savage Planet is on its way to PC, Xbox Series X/S and PS5 in May of next year and a trailer just popped up during the PC Gaming Show.
Revenge of the Savage Planet appears to be sticking to its roots as a comedy adventure game about ruthless corporations battling the forces of nature across the galaxy for more territory it can call its own. The trailer features the return of Martin Tweed, the ruthless CEO of Kindred Technologies. There’s also a new FMV character in the trailer called Gunther Harrison, another ruthless CEO from a rival corporation called Alta Interglobal, who looks like a cross between Megamind and Morbo from Futurama.
The new game can be played in solo or co-op mode. There are chances to uncover secrets, battle alien beasts and build your own colony on these worlds. There’s also a lot of flying slime, silly violence and savage attacks on corporate colonization thrown into the mix. If that’s what you liked about the first version, then it looks like there’s plenty more where that came from with Revenge of the Savage Planet.
This article originally appeared on Engadget at https://www.engadget.com/gaming/new-trailer-for-revenge-of-the-savage-planet-crash-lands-on-youtube-221409561.html?src=rss
New Mexico is joining states like California and Ohio in supporting digital driver’s licenses and state IDs in Apple Wallet and Google Wallet. New Mexico residents are still required by law to carry their physical IDs for law enforcement and age-verification use, but at businesses and TSA checkpoints that have adopted New Mexico’s NM Verifier app, you’ll be able to tap your smartphone rather than pull out a card.
Digital licenses can be added to Apple and Google’s apps now by scanning the front and back of your physical ID, capturing a scan of your face and submitting your digital application to be verified. Once added, digital IDs can be pulled up and used in the same way you’d pay with a digital payment card. Google has published a video on how to add your card to Google Wallet and Apple has a detailed support article on how to add IDs to Apple Wallet, if you’re looking for tips.
The New Mexico Motor Vehicle Division first proposed legislation to “offer electronic credentials to customers at no additional cost” in January 2024. The rollout of digital IDs continues to be a complex process, with the TSA listing 12 states currently offering some form of digital identification, but only Arizona, California, Colorado, Georgia, Maryland, and New Mexico currently offering IDs for both Google and Apple’s apps. To make things more confusing, some states like Ohio, Hawaii, and Iowa offer IDs for Apple Wallet but not Google’s app.
The shift to an exclusively digital wallet isn’t without potential risks, as well. The American Civil Liberties Union has criticized states’ quick adoption of digital driver’s licenses without putting in place additional protections for cardholders. Those include things like preventing ID issuers and verifiers from tracking the usage of digital cards and preserving the right to not use a digital card for anyone who doesn’t own or can’t afford a smartphone. Apple and Google’s solutions offer privacy protections in terms of encrypting information and keeping your device locked even after you’ve presented your ID, but they don’t totally account for how state or federal governments could access these new digital systems.
This article originally appeared on Engadget at https://www.engadget.com/apps/new-mexico-state-ids-can-now-be-added-to-digital-wallets-211549853.html?src=rss
Brendan Greene is largely credited with making the iconicPlayerUnknown’s Battlegrounds, also known as PUBG, and inventing the entire battle royale genre. We knew he left PUBG’s publisher to form an independent studio back in 2021, but now we know what he’s been working on the past few years.
His studio, PlayerUnknown Productions, is prepping a handful of titles, which it refers to as “an ambitious three-game plan.” First up, there’s Prologue: Go Wayback!, which is described as “a single-player open-world emergent game within the survival genre.” It uses the developer’s “in-house machine-learning-driven terrain generation technology” to create “millions of maps.” These maps are also easy on the eyes, as seen below.
PlayerUnknown Productions
We don’t know much about the gameplay, beyond the description and the aforementioned terrain generation technology. However, it’s available to wishlist right now on Steam. The company says it’ll launch as an early access title sometime in the first half of next year, following a series of playtests.
There’s also a nifty-looking tech demo called Preface: Undiscovered World. It’s free and available to download right now. This demo is being released to showcase the company’s in-house game engine, called Melba. Preface allows players to explore an “Earth-scale world generated in real-time.”
PlayerUnknown Productions
Greene says that this “digital planet is still quite empty for now, but every person who enters it and shares their feedback, contributes to its future development.” To that end, the Melba engine will be used to develop other games in the future.
One such future game is called Artemis, which is described as a “massive multiplayer sandbox experience.” We don’t know a whole lot about the title, except that it’s likely years away. Greene says that his company will be releasing two unannounced games after Prologue: Go Wayback! that will each address “critical technical challenges” that will help with the development of the more ambitious Artemis. In any event, it looks like PlayerUnknown Productions is certainly off to a promising start.
This article originally appeared on Engadget at https://www.engadget.com/gaming/pc/pubg-creator-brendan-greene-just-announced-a-handful-of-new-games-210053256.html?src=rss
Get ready to have that Will Smith song stuck in your head for the rest of the day because the autonomous taxi company Waymo is going to Miami. Yeah, sorry about that.
Waymo announced its plans to Miami on its official Waypoint blog. The expansion will start early next year as the company gets its fleet of self-driving Jaguar I-PACE EVs familiar with Miami’s streets and intersections. Then in 2026, Waymo plans to start offering rides to customers through the Waymo One app.
Waymo is also partnering with the African startup Moove as part of its expansion plans. Moove provides vehicles for ride-sharing services. Waymo wants Moove to manage its “fleet operations, facilities and charging infrastructure” first in Phoenix and eventually in Miami.
The Waymo One app currently operates in parts of San Francisco, Phoenix, Los Angeles and Austin, according to Google support. Waymo secured $5.6 billion in funding in October to expand to Austin and Atlanta by the early part of next year.
This article originally appeared on Engadget at https://www.engadget.com/transportation/waymo-announces-its-expanding-to-miami-204504533.html?src=rss
Threads’ latest test could help creators and others understand more about how their posts are performing on the platform. The company is testing an expanded version of its analytics feature, which will show users stats for specific posts, Adam Mosseri said in an update.
Up to now, Threads has had an “insights” feature, but it showed aggregated stats for all posts, so it was hard to discern which posts were performing well. Now, insights will be able to surface detailed metrics around specific posts, including views and interactions. It will also break down performance among followers and non-followers.
“Now that your posts will be shown to more people who follow you, it’s especially important to understand what’s resonating with your existing audience,” Mosseri wrote. Threads recently updated its highly criticized “for you” algorithm to surface more posts from accounts you follow, rather than random unconnected accounts.
The change could also address criticism from creators on Threads, who have said they often don’t understand how the app’s algorithm works. More detailed analytics could also help Meta entice more brands to the app as the company reportedly is gearing up to begin running ads on the service as soon as next month.
This article originally appeared on Engadget at https://www.engadget.com/social-media/threads-is-testing-post-analytics-203548697.html?src=rss
It’s embarrassing how much time I spend thinking about my fantasy football team.
Managing a squad means processing a firehose of information — injury reports, expert projections, upcoming bye weeks, and favorable matchups. And it’s not just the volume of data, but the ephermerality— if your star RB tweaks a hamstring during Wednesday practice, you better not be basing lineup decisions off of Tuesday’s report.
This is why general-purpose chatbots like Anthropic’s Claude and OpenAI’s ChatGPT are essentially useless for fantasy football recommendations, as they are limited to a static training corpus that cuts off months, even years ago.
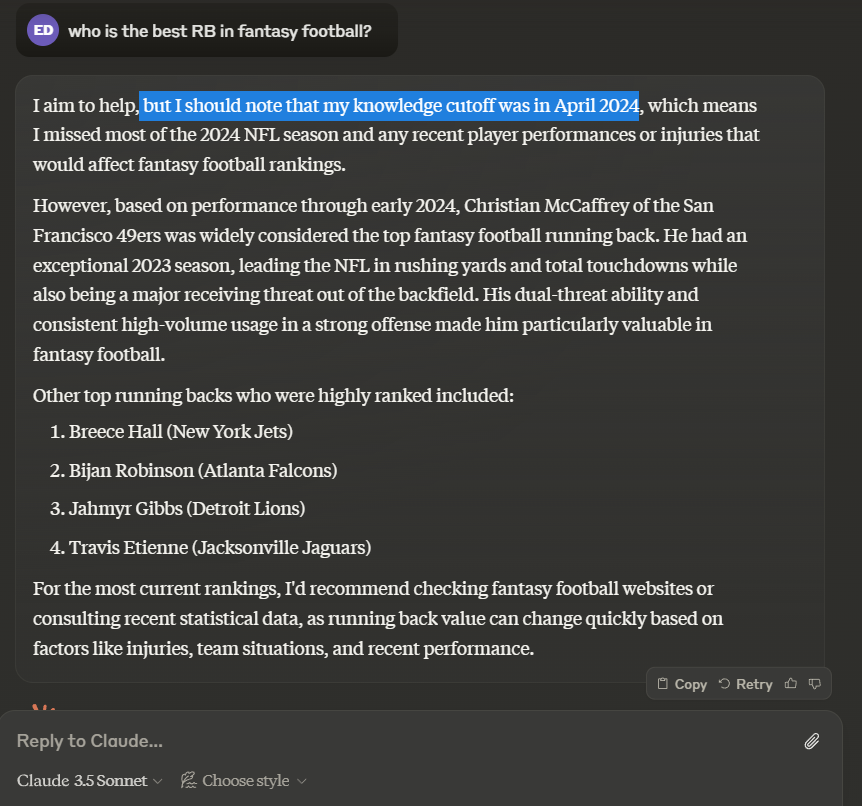
For instance, if we ask Claude Sonnet 3.5 who the current best running back is, we see names like Christian McCaffrey, Breece Hall, and Travis Etienne, who have had injury-ridden or otherwise disappointing seasons thus far in 2024. There is no mention of Saquon Barkley or Derrick Henry, the obvious frontrunners at this stage. (Though to Claude’s credit, it discloses its limitations.)
Apps like Perplexity are more accurate because they do access a search engine with up-to-date information. However, it of course has no knowledge of my entire roster situation, the state of our league’s playoff picture, or the nuances of our keeper rules.
There is an opportunity to tailor a fantasy football-focused Agent with tools and personalized context for each user.
Let’s dig into the implementation.
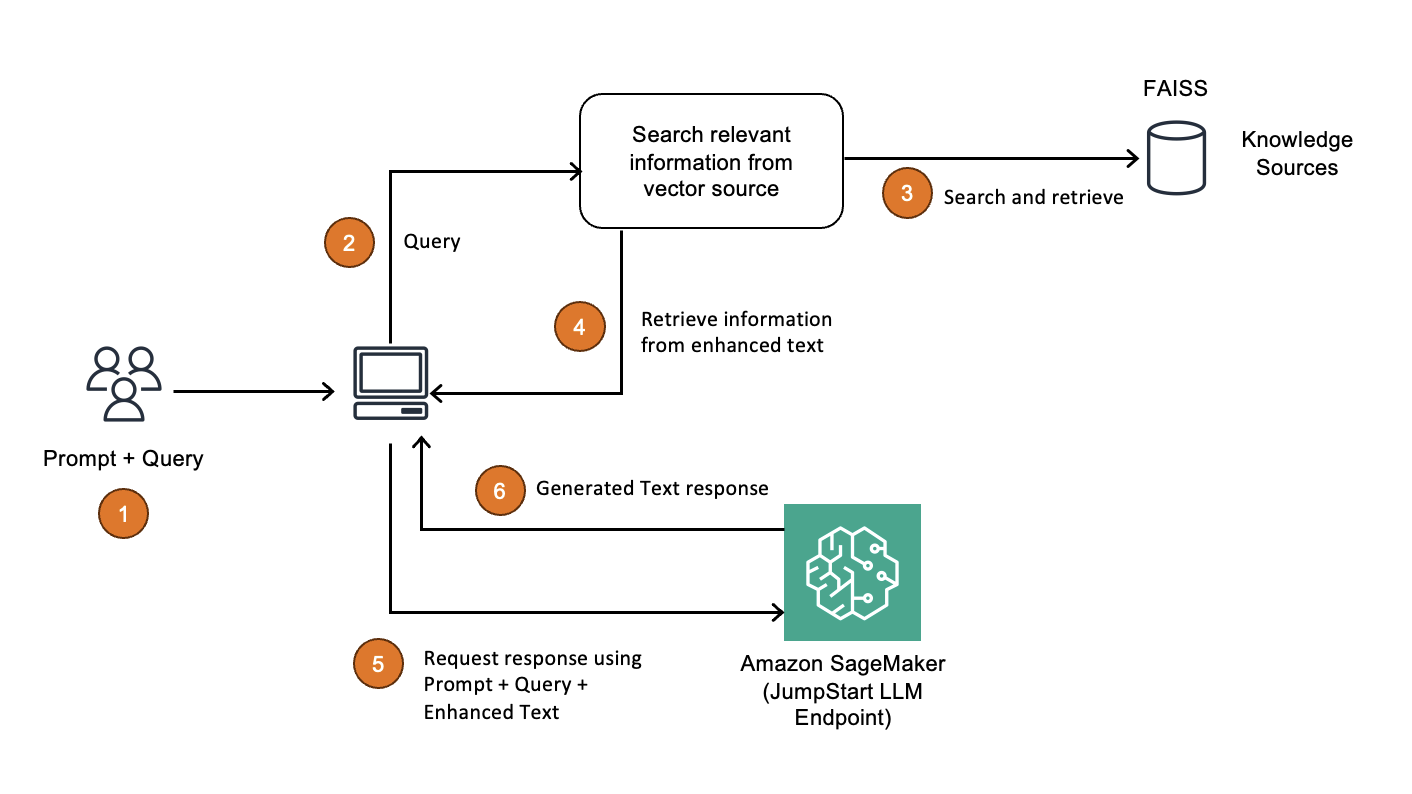
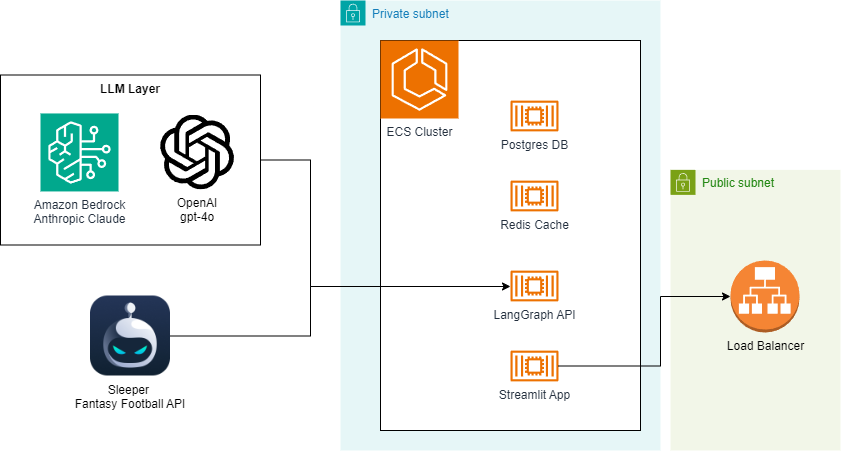
Architecture Overview
The heart of the chatbot will be a LangGraph Agent based on the ReAct framework. We’ll give it access to tools that integrate with the Sleeper API for common operations like checking the league standings, rosters, player stats, expert analysis, and more.
In addition to the LangGraph API server, our backend will include a small Postgres database and Redis cache, which are used to manage state and route requests. We’ll use Streamlit for a simple, but effective UI.
For development, we can run all of these components locally via Docker Compose, but I’ll also show the infrastructure-as-code (IaC) to deploy a scalable stack with AWS CDK.
Sleeper API Integration
Sleeper graciously exposes a public, read-only API that we can tap into for user & league details, including a full list of players, rosters, and draft information. Though it’s not documented explicitly, I also found some GraphQL endpoints that provide critical statistics, projections, and — perhaps most valuable of all — recent expert analysis by NFL reporters.
I created a simple API client to access the various methods, which you can find here. The one trick that I wanted to highlight is the requests-cache library. I don’t want to be a greedy client of Sleeper’s freely-available datasets, so I cache responses in a local Sqlite database with a basic TTL mechanism.
Not only does this lessen the amount redundant API traffic bombarding Sleeper’s servers (reducing the chance that they blacklist my IP address), but it significantly reduces latency for my clients, making for a better UX.
Setting up and using the cache is dead simple, as you can see in this snippet —
import requests_cache from urllib.parse import urljoin from typing import Union, Optional from pathlib import Path
class SleeperClient: def __init__(self, cache_path: str = '../.cache'):
first checks the local Sqlite cache for an unexpired response that particular request. If it’s found, we can skip the API call and just read from the database.
Defining the Tools
I want to turn the Sleeper API client into a handful of key functions that the Agent can use to inform its responses. Because these functions will effectively be invoked by the LLM, I find it important to annotate them clearly and ask for simple, flexible arguments.
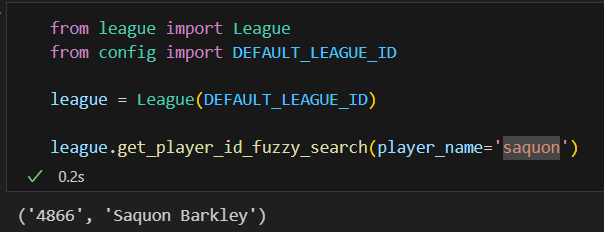
For example, Sleeper’s API’s generally ask for numeric player id’s, which makes sense for a programmatic interface. However, I want to abstract that concept away from the LLM and just have it input player names for these functions. To ensure some additional flexibility and allow for things like typos, I implemented a basic “fuzzy search” method to map player name searches to their associated player id.
# file: fantasy_chatbot/league.py
def get_player_id_fuzzy_search(self, player_name: str) -> tuple[str, str]: # will need a simple search engine to go from player name to player id without needing exact matches. returns the player_id and matched player name as a tuple nearest_name = process.extract(query=player_name, choices=self.player_names, scorer=fuzz.WRatio, limit=1)[0] return self.player_name_to_id[nearest_name[0]], self.player_names[nearest_name[2]]
# example usage in a tool def get_player_news(self, player_name: Annotated[str, "The player's name."]) -> str: """ Get recent news about a player for the most up-to-date analysis and injury status. Use this whenever naming a player in a potential deal, as you should always have the right context for a recommendation. If sources are provided, include markdown-based link(s) (e.g. [Rotoballer](https://www.rotoballer.com/player-news/saquon-barkley-has-historic-night-sunday/1502955) ) at the bottom of your response to provide proper attribution and allow the user to learn more. """ player_id, player_name = self.get_player_id_fuzzy_search(player_name) # news news = self.client.get_player_news(player_id, limit=3) player_news = f"Recent News about {player_name}nn" for n in news: player_news += f"**{n['metadata']['title']}**n{n['metadata']['description']}" if analysis := n['metadata'].get('analysis'): player_news += f"nnAnalysis:n{analysis}" if url := n['metadata'].get('url'): # markdown link to source player_news += f"n[{n['source'].capitalize()}]({url})nn"
return player_news
This is better than a simple map of name to player id because it allows for misspellings and other typos, e.g. saquon → Saquon Barkley
I created a number of useful tools based on these principles:
Get League Status (standings, current week, no. playoff teams, etc.)
Get Roster for Team Owner
Get Player News (up-to-date articles / analysis about the player)
Get Player Stats (weekly points scored this season with matchups)
Get Player Current Owner (critical for proposing trades)
Get Best Available at Position (the waiver wire)
Get Player Rankings (performance so far, broken down by position)
You can probably think of a few more functions that would be useful to add, like details about recent transactions, league head-to-heads, and draft information.
LangGraph Agent
The impetus for this entire project was an opportunity to learn the LangGraph ecosystem, which may be becoming the de facto standard for constructing agentic workflows.
I’ve hacked together agents from scratch in the past, and I wish I had known about LangGraph at the time. It’s not just a thin wrapper around the various LLM providers, it provides immense utility for building, deploying, & monitoring complex workflows. I’d encourage you to check out the Introduction to LangGraph course by LangChain Academy if you’re interested in diving deeper.
As mentioned before, the graph itself is based on the ReAct framework, which is a popular and effective way to get LLM’s to interact with external tools like those defined above.
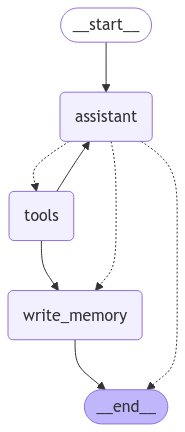
I’ve also added a node to persist long-term memories about each user, so that information can be persisted across sessions. I want our agent to “remember” things like users’ concerns, preferences, and previously-recommended trades, as this is not a feature that is implemented particularly well in the chatbots I’ve seen. In graph form, it looks like this:
Pretty simple right? Again, you can checkout the full graph definition in the code, but I’ll highlight the write_memory node, which is responsible for writing & updating a profile for each user. This allows us to track key interactions while being efficient about token use.
def write_memory(state: MessagesState, config: RunnableConfig, store: BaseStore): """Reflect on the chat history and save a memory to the store."""
# get the username from the config username = config["configurable"]["username"]
# retrieve existing memory if available namespace = ("memory", username) existing_memory = store.get(namespace, "user_memory")
# format the memories for the instruction if existing_memory and existing_memory.value: memory_dict = existing_memory.value formatted_memory = ( f"Team Name: {memory_dict.get('team_name', 'Unknown')}n" f"Current Concerns: {memory_dict.get('current_concerns', 'Unknown')}" f"Other Details: {memory_dict.get('other_details', 'Unknown')}" ) else: formatted_memory = None
# invoke the model to produce structured output that matches the schema new_memory = llm_with_structure.invoke([SystemMessage(content=system_msg)] + state['messages'])
# overwrite the existing user profile key = "user_memory" store.put(namespace, key, new_memory)
These memories are surfaced in the system prompt, where I also gave the LLM basic details about our league and how I want it to handle common user requests.
Streamlit UI and Demo
I’m not a frontend developer, so the UI leans heavily on Streamlit’s components and familiar chatbot patterns. Users input their Sleeper username, which is used to lookup their available leagues and persist memories across threads.
I also added a couple of bells and whistles, like implementing token streaming so that users get instant feedback from the LLM. The other important piece is a “research pane”, which surfaces the results of the Agent’s tool calls so that user can inspect the raw data that informs each response.
Here’s a quick demo.
Deployment
For development, I recommend deploying the components locally via the provided docker-compose.yml file. This will expose the API locally at http://localhost:8123 , so you can rapidly test changes and connect to it from a local Streamlit app.
I have also included IaC for an AWS CDK-based deployment that I use to host the app on the internet. Most of the resources are defined here. Notice the parallels between the docker-compose.yml and the CDK code related to the ECS setup:
Snippet from docker-compose.yml for the LangGraph API container:
Aside from some subtle differences, it’s effectively a 1:1 translation, which is always something I look for when comparing local environments to “prod” deployments. The DockerImageAsset is a particularly useful resource, as it handles building and deploying (to ECR) the Docker image during synthesis.
Note: Deploying the stack to your AWS account via npm run cdk deploy WILL incur charges. In this demo code I have not included any password protection on the Streamlit app, meaning anyone who has the URL can use the chatbot! I highly recommend adding some additional security if you plan to deploy it yourself.
Takeaways
You want to keep your tools simple. This app does a lot, but is still missing some key functionality, and it will start to break down if I simply add more tools. In the future, I want to break up the graph into task-specific sub-components, e.g. a “News Analyst” Agent and a “Statistician” Agent.
Traceability and debugging are more important with Agent-based apps than traditional software. Despite significant advancements in models’ ability to produce structured outputs, LLM-based function calling is still inherently less reliable than conventional programs. I used LangSmith extensively for debugging.
In an age of commoditized language models, there is no replacement for reliable reporters. We’re at a point where you can put together a reasonable chatbot in a weekend, so how do products differentiate themselves and build moats? This app (or any other like it) would be useless without access to high-quality reporting from analysts and experts. In other words, the Ian Rapaport’s and Matthew Berry’s of the world are more valuable than ever.
It’s embarrassing how much time I spend thinking about my fantasy football team.
Managing a squad means processing a firehose of information — injury reports, expert projections, upcoming bye weeks, and favorable matchups. And it’s not just the volume of data, but the ephermerality— if your star RB tweaks a hamstring during Wednesday practice, you better not be basing lineup decisions off of Tuesday’s report.
This is why general-purpose chatbots like Anthropic’s Claude and OpenAI’s ChatGPT are essentially useless for fantasy football recommendations, as they are limited to a static training corpus that cuts off months, even years ago.
For instance, if we ask Claude Sonnet 3.5 who the current best running back is, we see names like Christian McCaffrey, Breece Hall, and Travis Etienne, who have had injury-ridden or otherwise disappointing seasons thus far in 2024. There is no mention of Saquon Barkley or Derrick Henry, the obvious frontrunners at this stage. (Though to Claude’s credit, it discloses its limitations.)
Apps like Perplexity are more accurate because they do access a search engine with up-to-date information. However, it of course has no knowledge of my entire roster situation, the state of our league’s playoff picture, or the nuances of our keeper rules.
There is an opportunity to tailor a fantasy football-focused Agent with tools and personalized context for each user.
Let’s dig into the implementation.
Architecture Overview
The heart of the chatbot will be a LangGraph Agent based on the ReAct framework. We’ll give it access to tools that integrate with the Sleeper API for common operations like checking the league standings, rosters, player stats, expert analysis, and more.
In addition to the LangGraph API server, our backend will include a small Postgres database and Redis cache, which are used to manage state and route requests. We’ll use Streamlit for a simple, but effective UI.
For development, we can run all of these components locally via Docker Compose, but I’ll also show the infrastructure-as-code (IaC) to deploy a scalable stack with AWS CDK.
Sleeper API Integration
Sleeper graciously exposes a public, read-only API that we can tap into for user & league details, including a full list of players, rosters, and draft information. Though it’s not documented explicitly, I also found some GraphQL endpoints that provide critical statistics, projections, and — perhaps most valuable of all — recent expert analysis by NFL reporters.
I created a simple API client to access the various methods, which you can find here. The one trick that I wanted to highlight is the requests-cache library. I don’t want to be a greedy client of Sleeper’s freely-available datasets, so I cache responses in a local Sqlite database with a basic TTL mechanism.
Not only does this lessen the amount redundant API traffic bombarding Sleeper’s servers (reducing the chance that they blacklist my IP address), but it significantly reduces latency for my clients, making for a better UX.
Setting up and using the cache is dead simple, as you can see in this snippet —
import requests_cache from urllib.parse import urljoin from typing import Union, Optional from pathlib import Path
class SleeperClient: def __init__(self, cache_path: str = '../.cache'):
first checks the local Sqlite cache for an unexpired response that particular request. If it’s found, we can skip the API call and just read from the database.
Defining the Tools
I want to turn the Sleeper API client into a handful of key functions that the Agent can use to inform its responses. Because these functions will effectively be invoked by the LLM, I find it important to annotate them clearly and ask for simple, flexible arguments.
For example, Sleeper’s API’s generally ask for numeric player id’s, which makes sense for a programmatic interface. However, I want to abstract that concept away from the LLM and just have it input player names for these functions. To ensure some additional flexibility and allow for things like typos, I implemented a basic “fuzzy search” method to map player name searches to their associated player id.
# file: fantasy_chatbot/league.py
def get_player_id_fuzzy_search(self, player_name: str) -> tuple[str, str]: # will need a simple search engine to go from player name to player id without needing exact matches. returns the player_id and matched player name as a tuple nearest_name = process.extract(query=player_name, choices=self.player_names, scorer=fuzz.WRatio, limit=1)[0] return self.player_name_to_id[nearest_name[0]], self.player_names[nearest_name[2]]
# example usage in a tool def get_player_news(self, player_name: Annotated[str, "The player's name."]) -> str: """ Get recent news about a player for the most up-to-date analysis and injury status. Use this whenever naming a player in a potential deal, as you should always have the right context for a recommendation. If sources are provided, include markdown-based link(s) (e.g. [Rotoballer](https://www.rotoballer.com/player-news/saquon-barkley-has-historic-night-sunday/1502955) ) at the bottom of your response to provide proper attribution and allow the user to learn more. """ player_id, player_name = self.get_player_id_fuzzy_search(player_name) # news news = self.client.get_player_news(player_id, limit=3) player_news = f"Recent News about {player_name}nn" for n in news: player_news += f"**{n['metadata']['title']}**n{n['metadata']['description']}" if analysis := n['metadata'].get('analysis'): player_news += f"nnAnalysis:n{analysis}" if url := n['metadata'].get('url'): # markdown link to source player_news += f"n[{n['source'].capitalize()}]({url})nn"
return player_news
This is better than a simple map of name to player id because it allows for misspellings and other typos, e.g. saquon → Saquon Barkley
I created a number of useful tools based on these principles:
Get League Status (standings, current week, no. playoff teams, etc.)
Get Roster for Team Owner
Get Player News (up-to-date articles / analysis about the player)
Get Player Stats (weekly points scored this season with matchups)
Get Player Current Owner (critical for proposing trades)
Get Best Available at Position (the waiver wire)
Get Player Rankings (performance so far, broken down by position)
You can probably think of a few more functions that would be useful to add, like details about recent transactions, league head-to-heads, and draft information.
LangGraph Agent
The impetus for this entire project was an opportunity to learn the LangGraph ecosystem, which may be becoming the de facto standard for constructing agentic workflows.
I’ve hacked together agents from scratch in the past, and I wish I had known about LangGraph at the time. It’s not just a thin wrapper around the various LLM providers, it provides immense utility for building, deploying, & monitoring complex workflows. I’d encourage you to check out the Introduction to LangGraph course by LangChain Academy if you’re interested in diving deeper.
As mentioned before, the graph itself is based on the ReAct framework, which is a popular and effective way to get LLM’s to interact with external tools like those defined above.
I’ve also added a node to persist long-term memories about each user, so that information can be persisted across sessions. I want our agent to “remember” things like users’ concerns, preferences, and previously-recommended trades, as this is not a feature that is implemented particularly well in the chatbots I’ve seen. In graph form, it looks like this:
Pretty simple right? Again, you can checkout the full graph definition in the code, but I’ll highlight the write_memory node, which is responsible for writing & updating a profile for each user. This allows us to track key interactions while being efficient about token use.
def write_memory(state: MessagesState, config: RunnableConfig, store: BaseStore): """Reflect on the chat history and save a memory to the store."""
# get the username from the config username = config["configurable"]["username"]
# retrieve existing memory if available namespace = ("memory", username) existing_memory = store.get(namespace, "user_memory")
# format the memories for the instruction if existing_memory and existing_memory.value: memory_dict = existing_memory.value formatted_memory = ( f"Team Name: {memory_dict.get('team_name', 'Unknown')}n" f"Current Concerns: {memory_dict.get('current_concerns', 'Unknown')}" f"Other Details: {memory_dict.get('other_details', 'Unknown')}" ) else: formatted_memory = None
# invoke the model to produce structured output that matches the schema new_memory = llm_with_structure.invoke([SystemMessage(content=system_msg)] + state['messages'])
# overwrite the existing user profile key = "user_memory" store.put(namespace, key, new_memory)
These memories are surfaced in the system prompt, where I also gave the LLM basic details about our league and how I want it to handle common user requests.
Streamlit UI and Demo
I’m not a frontend developer, so the UI leans heavily on Streamlit’s components and familiar chatbot patterns. Users input their Sleeper username, which is used to lookup their available leagues and persist memories across threads.
I also added a couple of bells and whistles, like implementing token streaming so that users get instant feedback from the LLM. The other important piece is a “research pane”, which surfaces the results of the Agent’s tool calls so that user can inspect the raw data that informs each response.
Here’s a quick demo.
Deployment
For development, I recommend deploying the components locally via the provided docker-compose.yml file. This will expose the API locally at http://localhost:8123 , so you can rapidly test changes and connect to it from a local Streamlit app.
I have also included IaC for an AWS CDK-based deployment that I use to host the app on the internet. Most of the resources are defined here. Notice the parallels between the docker-compose.yml and the CDK code related to the ECS setup:
Snippet from docker-compose.yml for the LangGraph API container:
Aside from some subtle differences, it’s effectively a 1:1 translation, which is always something I look for when comparing local environments to “prod” deployments. The DockerImageAsset is a particularly useful resource, as it handles building and deploying (to ECR) the Docker image during synthesis.
Note: Deploying the stack to your AWS account via npm run cdk deploy WILL incur charges. In this demo code I have not included any password protection on the Streamlit app, meaning anyone who has the URL can use the chatbot! I highly recommend adding some additional security if you plan to deploy it yourself.
Takeaways
You want to keep your tools simple. This app does a lot, but is still missing some key functionality, and it will start to break down if I simply add more tools. In the future, I want to break up the graph into task-specific sub-components, e.g. a “News Analyst” Agent and a “Statistician” Agent.
Traceability and debugging are more important with Agent-based apps than traditional software. Despite significant advancements in models’ ability to produce structured outputs, LLM-based function calling is still inherently less reliable than conventional programs. I used LangSmith extensively for debugging.
In an age of commoditized language models, there is no replacement for reliable reporters. We’re at a point where you can put together a reasonable chatbot in a weekend, so how do products differentiate themselves and build moats? This app (or any other like it) would be useless without access to high-quality reporting from analysts and experts. In other words, the Ian Rapaport’s and Matthew Berry’s of the world are more valuable than ever.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.