The crowd-sourced review site Yelp unveiled a new feature that uses AI and customer reviews to rate common facets of nightlife and food-related business. The new Review Insights feature is available now on the iOS version of the Yelp app, according to the company’s official blog.
Review Insights aggregates customer reviews and feeds them into a large language model (LLM), which will assign specific aspects — like the vibe or service time — a rating out of 100. Supposedly it will be able to infer customer sentiment about these parts of a business “even when a review doesn’t explicitly mention one of the topics.” Yelp will also be adding an AI-powered homepage in the coming weeks.
Yelp has been implementing new AI features over the past year. The business review site added an auto-generated summary feature in January and an AI-powered Yelp Assistant in April.
This article originally appeared on Engadget at https://www.engadget.com/ai/yelp-adds-ai-powered-scores-to-business-pages-195131103.html?src=rss
Apple Music just announced that it’s expanding its live radio offerings and adding three new stations to the lineup. These channels are hosted by actual people and are available to everyone, even those without a paid Apple Music subscription.
First up, there’s Apple Música Uno, which celebrates the “wealth of stylistic diversity in Latin music around the world.” The station will play music from a wide variety of genres, including Música Mexicana, reggaetón, tropical, Latin pop and more. It’s being hosted by superstars like Becky G, Rauw Alejandro and Grupo Frontera, along with radio personalities Evelyn Sicairos and Lechero. It airs every weekday, though weekends will feature special programming.
Apple
Apple Music Club kicks things up a notch, with an emphasis on dance and electronic music. The show will be guided by Tim Sweeney, the host of WNYU’s Beats in Space and not the guy who runs Epic Games, along with DJ and artist NAINA. Apple says each playlist will be “thoughtfully curated into a set that is fully alive.” These playlists will be curated by a mix of luminaries, including Honey Dijon, Jamie xx and FKA twigs. Once aired, each broadcast will be available for revists via DJ Mixes on the platform.
Apple
Finally, there’s Apple Music Chill, which is described as “an escape, a refuge” and a “sanctuary in sound.” It’s something nice to have on in the background as you go about your day. This reads to me like it’s a version of the famous lo-fi girl playlists. Apple says that “programming will be a continuous flow of chill highlights across genres.” It all kicks off with a brand-new Beck song, a cover of the George Harrison classic “Be Here Now.” One of the hosts is Brian Eno, who is an absolute master of chill (among other things.)
All of these stations are available right now. They join pre-existing channels like Apple Music 1, Apple Music Hits and Apple Music Country.
This article originally appeared on Engadget at https://www.engadget.com/audio/apple-music-expands-its-live-radio-offerings-with-three-new-stations-184912171.html?src=rss
The Federal Trade Commission (FTC) is sending out 629,344 payments worth more than $72 million to Fortnite players as part of a settlement deal with Epic Games, according to an FTC announcement. The $72 million is intended to compensate Fortnite players who were “tricked” into making unauthorized purchases.
Epic Games was ordered to pay $520 million just under two years ago to settle allegations that the gamemaker “used design tactics known as dark patterns” to deceive customers into making unwanted purchases and allowed children to rack up charges without parental involvement. Epic Games was also accused of blocking users from their purchased content when they disputed the unauthorized charges. About half that money was paid as penalties to the FTC directly. The rest is earmarked for player refunds, and today’s $72 million covers a little under a third of the total amount, with the rest to be distributed “as a later date,” according to the announcement.
Fortnite players can still submit claims for unauthorized charges online at ftc.gov/fortnite.
This article originally appeared on Engadget at https://www.engadget.com/gaming/ftc-paying-out-first-round-of-fortnite-refunds-181158920.html?src=rss
The Thanksgiving holiday might have come and gone, but one of the best pair of wireless headphones you can buy right now are back to their Black Friday price. Amazon has discounted Sony’s excellent WH-1000XM5 headphones. All four colorways — black, midnight blue, silver and smoky pink — are currently $298, or 25 percent off their usual $400 price.
At this point, the WH-1000XM5 likely need no introduction, but for the uninitiated, they strike a nearly perfect balance between features, performance and price; in fact, they’re the Bluetooth headphones Billy Steele, Engadget’s resident audio guru, recommends for most people.
With the Sony WH-1000XM5, Sony redesigned its already excellent 1000X line to make the new model more comfortable. The company also improved the XM4’s already superb active noise cancelation capabilities, adding four additional ANC mics. That enhancement makes the WH5 even better at blocking out background noise, including human voices.
Other notable features include 30-hour battery life, clear and crisp sound and a combination of handy physical and touch controls. The one downside of the XM5 are that they cost more than Sony’s previous flagship Bluetooth headphones. Thankfully, this sale addresses that fault nicely.
Follow @EngadgetDeals on Twitter and subscribe to the Engadget Deals newsletter for the latest tech deals and buying advice.
This article originally appeared on Engadget at https://www.engadget.com/deals/sonys-wh-1000xm5-headphones-are-back-on-sale-for-100-off-174551119.html?src=rss
Still Wakes The Deepis one of this year’s standout horror games. It’s a narrative-heavy survival title that pits you — an electrician stuck on an oil rig — against eldritch terrors from the briny depths of the North Sea. Not only that, but because you’re off the coast of Scotland, there’s some harsh weather to contend with too. If that all sounds overly cheery for you, there’s a new option to add to the gloominess, thanks to a black-and-white mode.
After you’ve installed the game’s latest update, you can toggle this so-called Silver Screen filter at any time during your playthrough via the video section in the settings. Developer The Chinese Room (Dear Esther and Everybody’s Gone to the Rapture) has also added a chapter select feature, so you can now relive your favorite moments from this dark tale in monochrome if you choose.
Engadget Senior Editor Jessica Conditt described Still Wakes The Deep as a modern horror classic in her review and called it one of this generation’s most beautiful games. It sounds great too — having actual Scottish actors voicing the characters certainly helps add authenticity.
Still Wakes The Deep is available on PC, PS5 and Xbox Series X/S. It’s included in Game Pass Ultimate, PC Game Pass and Game Pass for Console.
This article originally appeared on Engadget at https://www.engadget.com/gaming/still-wakes-the-deeps-eldritch-terrors-are-now-available-in-a-black-and-white-mode-173209350.html?src=rss
Analog AI chip startup wants to achieve 1 POPS per Watt: 1000 TOPS/W is ‘within reach’ says firm co-founder as he looks to analog-first Gigabit-sized SLMs
Originally appeared here:
Analog AI chip startup wants to achieve 1 POPS per Watt: 1000 TOPS/W is ‘within reach’ says firm co-founder as he looks to analog-first Gigabit-sized SLMs
Disclosure: I am a maintainer of Opik, one of the open source projects used later in this article.
For the past few months, I’ve been working on LLM-based evaluations (“LLM-as-a-Judge” metrics) for language models. The results have so far been extremely encouraging, particularly for evaluations like hallucination detection or content moderation, which are hard to quantify with heuristic methods.
Engineering LLM-based metrics, however, has been surprisingly challenging. Evaluations and unit tests, especially those with more complex logic, require you to know the structure of your data. And with LLMs and their probabilistic outputs, it’s difficult to reliably output specific formats and structures. Some hosted model providers now offer structured outputs modes, but these still come with limitations, and if you’re using open source or local models, those modes won’t do you much good.
The solution to this problem is to use structured generation. Beyond its ability to make LLM-based evaluations more reliable, it also unlocks an entirely new category of complex, powerful multi-stage evaluations.
In this piece, I want to introduce structured generation and some of the big ideas behind it, before diving into specific examples of hallucination detection with an LLM judge. All of the code samples below can be run from within this Colab notebook, so feel free to run the samples as you follow along.
A Brief Introduction to Structured Generation with Context-Free Grammars
Structured generation is a subfield of machine learning focused on guiding the outputs of generative models by constraining the outputs to fit some particular schema. As an example, instead of fine-tuning a model to output valid JSON, you might constrain a more generalized model’s output to only match valid JSON schemas.
You can constrain the outputs of a model through different strategies, but the most common is to interfere directly in the sampling phase, using some external schema to prevent “incorrect” tokens from being sampled.
At this point, structured generation has become a fairly common feature in LLM servers. vLLM, NVIDIA NIM, llama.cpp, and Ollama all support it. If you’re not working with a model server, libraries like Outlines make it trivial to implement for any model. OpenAI also provides a “Structured Output” mode, which similarly allows you to specify a response schema from their API.
But, I find it helps me develop my intuition for a concept to try a simple implementation from scratch, and so that’s what we’re going to do here.
There are two main components to structured generation:
Defining a schema
Parsing the output
For the schema, I’m going to use a context-free grammar (CFG). If you’re unfamiliar, a grammar is a schema for parsing a language. Loosely, it defines what is and isn’t considered “valid” in a language. If you’re in the mood for an excellent rabbit hole, context-free languages are a part of Chomsky’s hierarchy of languages. The amazing Kay Lack has a fantastic introductory video to grammars and parsing here, if you’re interested in learning more.
The most popular library for parsing and constructing CFGs is Lark. In the below code, I’ve written out a simple JSON grammar using the library:
If you’re not familiar with CFGs or Lark, the above might seem a little intimidating, but it’s actually pretty straightforward. The ?start line indicates that we begin with a value. We then define a value to be either an object, an array, an escaped string, a signed number, a boolean, or a null value. The -> symbols indicate that we map these string values to literal values. We then further specify what we mean by array , object, and pair, before finally instructing our parser to ignore inline whitespace. Try to think of it as if we are constantly “expanding” each high level concept, like a start or a value, into composite parts, until we reach such a low level of abstraction that we can no longer expand. In the parlance of grammars, these “too low level to be expanded” symbols are called “terminals.”
One immediate issue you’ll run into with this above code is that it only determines if a string is valid or invalid JSON. Since we’re using a language model and generating one token at a time, we’re going to have a lot of intermediary strings that are technically invalid. There are more elegant ways of handling this, but for the sake of speed, I’m just going to define a simple function to check if we’re in the middle of generating a string or not:
With all of this defined, let’s run a little test to see if our parser can accurately differentiate between valid, invalid, and incomplete JSON strings:
from lark import UnexpectedCharacters, UnexpectedToken
# We will use this method later in constraining our model output def try_and_recover(json_string): try: parser.parse(json_string) return {"status": "valid", "message": "The JSON is valid."} except UnexpectedToken as e: return {"status": "incomplete", "message": f"Incomplete JSON. Error: {str(e)}"} except UnexpectedCharacters as e: if is_incomplete_string(json_string): return {"status": "incomplete", "message": "Incomplete string detected."} return {"status": "invalid", "message": f"Invalid JSON. Error: {str(e)}"} except Exception as e: return {"status": "invalid", "message": f"Unknown error. JSON is invalid. Error: {str(e)}"}
As a final test, let’s use this try_and_recover() function to guide our decoding process with a relatively smaller model. In the below code, we’ll use an instruction-tuned Qwen 2.5 model with 3 billion parameters, and we’ll ask it a simple question. First, let’s initialize the model and tokenizer:
from transformers import AutoModelForCausalLM, AutoTokenizer model_name = "Qwen/Qwen2.5-3B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
Now, we want to define a function to recursively sample from the model, using our try_and_recover() function to constrain the outputs. Below, I’ve defined the function, which works by recursively sampling the top 20 most likely next tokens, and selecting the first one which satisfies a valid or incomplete JSON string:
import torch
def sample_with_guidance(initial_text): """ Generates a structured response from the model, guided by a validation function.
Args: initial_text (str): The initial input text to the model.
Returns: str: The structured response generated by the model. """ response = "" # Accumulate the response string here next_token = None # Placeholder for the next token
while next_token != tokenizer.eos_token: # Continue until the end-of-sequence token is generated # Encode the current input (initial_text + response) for the model input_ids = tokenizer.encode(initial_text + response, return_tensors="pt").to(device)
with torch.no_grad(): # Disable gradients for inference outputs = model(input_ids)
# Get the top 20 most likely next tokens top_tokens = torch.topk(outputs.logits[0, -1, :], 20, dim=-1).indices candidate_tokens = tokenizer.batch_decode(top_tokens)
for token in candidate_tokens: # Check if the token is the end-of-sequence token if token == tokenizer.eos_token: # Validate the current response to decide if we should finish validation_result = try_and_recover(response) if validation_result['status'] == 'valid': # Finish if the response is valid next_token = token break else: continue # Skip to the next token if invalid
# Simulate appending the token to the response extended_response = response + token
# Validate the extended response validation_result = try_and_recover(extended_response) if validation_result['status'] in {'valid', 'incomplete'}: # Update the response and set the token as the next token response = extended_response next_token = token print(response) # Just to see our intermediate outputs break
With the following code, we can test the performance of this structured generation function:
import json
messages = [ { "role": "user", "content": "What is the capital of France? Please only answer using the following JSON schema: { \"answer\": str }." } ]
# Format the text for our particular model input_text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
This particular approach will obviously add some computational overhead to your code, but some of the more optimized implementations are actually capable of structuring the output of a model with minimal latency impact. Below is a side-by-side comparison of unstructured generation versus structured generation using llama.cpp’s grammar-structured generation feature:
This comparison was recorded by Brandon Willard from .txt (the company behind Outlines), as part of his fantastic article on latency in structured generation. I’d highly recommend giving it a read, if you’re interested in diving deeper into the field.
Alright, with that bit of introduction out of the way, let’s look at applying structured generation to an LLM-as-a-judge metric, like hallucination.
How to detect hallucinations with structured generation
Hallucination detection is one of the “classic” applications of LLM-based evaluation. Traditional heuristic methods struggle with the subtlety of hallucination-in no small part due to the fact that there is no universally agreed upon definition of “hallucination.” For the purposes of this article, we’re going to use a definition from a recent paper out of the University of Illinois Champagne-Urbana, which I find to be descriptive and usable:
A hallucination is a generated output from a model that conflicts with constraints or deviates from desired behavior in actual deployment, or is completely irrelevant to the task at hand, but could be deemed syntactically plausible under the circumstances.
In other words, a hallucination is an output that seems plausible. It is grammatically correct, it makes reference to its surrounding context, and it seems to fit the “flow” of the task. It also, however, contradicts some basic instruction of the task. This could mean drawing incorrect conclusions, citing nonexistent data, or completely ignoring the actual instructions of the task.
Obviously, encoding a discrete system of rules to parse outputs for something as ambiguous as hallucinations is a challenge. LLMs, however, are very well suited towards this kind of complex task.
Using an LLM to perform hallucination analysis isn’t too difficult to setup. All we need to do is prompt the model to analyze the output text for hallucinations. In Opik’s built-in Hallucination() metric, we use the following prompt:
context_hallucination_template = """You are an expert judge tasked with evaluating the faithfulness of an AI-generated answer to the given context. Analyze the provided INPUT, CONTEXT, and OUTPUT to determine if the OUTPUT contains any hallucinations or unfaithful information.
Guidelines: 1. The OUTPUT must not introduce new information beyond what's provided in the CONTEXT. 2. The OUTPUT must not contradict any information given in the CONTEXT. 2. The OUTPUT should not contradict well-established facts or general knowledge. 3. Ignore the INPUT when evaluating faithfulness; it's provided for context only. 4. Consider partial hallucinations where some information is correct but other parts are not. 5. Pay close attention to the subject of statements. Ensure that attributes, actions, or dates are correctly associated with the right entities (e.g., a person vs. a TV show they star in). 6. Be vigilant for subtle misattributions or conflations of information, even if the date or other details are correct. 7. Check that the OUTPUT doesn't oversimplify or generalize information in a way that changes its meaning or accuracy.
Analyze the text thoroughly and assign a hallucination score between 0 and 1, where: - 0.0: The OUTPUT is entirely faithful to the CONTEXT - 1.0: The OUTPUT is entirely unfaithful to the CONTEXT
INPUT (for context only, not to be used for faithfulness evaluation): {input}
CONTEXT: {context}
OUTPUT: {output}
Provide your verdict in JSON format: {{ "score": <your score between 0.0 and 1.0>, "reason": [ <list your reasoning as bullet points> ] }}"""
The difficult part, however, is performing this analysis programatically. In a real world setting, we’ll want to automatically parse the output of our model and collect the hallucination scores, either as part of our model evaluation or as part of our inference pipeline. Doing this will require us to write code that acts on the model outputs, and if the LLM responds with incorrectly formatted output, the evaluation will break.
This is a problem even for state of the art foundation models, but it is greatly exaggerated when working with smaller language models. Their outputs are probabilistic, and no matter how thorough you are in your prompt, there is no guarantee that they will always respond with the correct structure.
Unless, of course, you use structured generation.
Let’s run through a simple example using Outlines and Opik. First, we want to initialize our model using Outlines. In this example, we’ll be using the 0.5 billion parameter version of Qwen2.5. While this model is impressive for its size, and small enough for us to run quickly in a Colab notebook, you will likely want to use a larger model for more accurate results.
import outlines
model_kwargs = { "device_map": "auto" }
model = outlines.models.transformers("Qwen/Qwen2.5-0.5B-Instruct", model_kwargs=model_kwargs)
When your model finishes downloading, you can then create a generator. In Outlines, a generator is an inference pipeline that combines an output schema with a model. In the below code, we’ll define a schema in Pydantic and initialize our generator:
import pydantic from typing import List
class HallucinationResponse(pydantic.BaseModel): score: int reason: List[str]
Now, if we pass a string into the generator, it will output a properly formatted object.
Next, let’s setup our Hallucination metric in Opik. It’s pretty straightforward to create a metric using Opik’s baseMetric class:
from typing import Optional, List, Any from opik.evaluation.metrics import base_metric
class HallucinationWithOutlines(base_metric.BaseMetric): """ A metric that evaluates whether an LLM's output contains hallucinations based on given input and context. """
def score( self, input: str, output: str, context: Optional[List[str]] = None, **ignored_kwargs: Any, ) -> HallucinationResponse: """ Calculate the hallucination score for the given input, output, and optional context field.
Args: input: The original input/question. output: The LLM's output to evaluate. context: A list of context strings. If not provided, the presence of hallucinations will be evaluated based on the output only. **ignored_kwargs: Additional keyword arguments that are ignored.
Returns: HallucinationResponse: A HallucinationResponse object with a score of 1.0 if hallucination is detected, 0.0 otherwise, along with the reason for the verdict. """ llm_query = context_hallucination_template.format(input=input, output=output, context=context)
with torch.no_grad(): return generator(llm_query)
All we really do in the above is generate our prompt using the previously defined template string, and then pass it into our generator.
Now, let’s try out our metric on an actual hallucination dataset, to get a sense of how it works. We’ll use a split from the HaluEval dataset, which is freely available via HuggingFace and permissively licensed, and we’ll upload it as an Opik Dataset for our experiments. We’ll use a little extra logic to make sure the dataset is balanced between hallucinated and non-hallucinated samples:
# Define the scoring metric check_hallucinated_metric = Equals(name="Correct hallucination score")
res = evaluate( dataset=dataset, task=evaluation_task, scoring_metrics=[check_hallucinated_metric], )
Evaluation: 100%|██████████| 200/200 [09:34<00:00, 2.87s/it] ╭─ HaluEval-qa-samples Balanced (200 samples) ─╮ │ │ │ Total time: 00:09:35 │ │ Number of samples: 200 │ │ │ │ Correct hallucination score: 0.4600 (avg) │ │ │ ╰─────────────────────────────────────────────────╯ Uploading results to Opik ... View the results in your Opik dashboard.
And that’s all it takes! Notice that none of our samples failed because of improperly structured outputs. Let’s try running this same evaluation, but without structured generation. To achieve this, we can switch our generator type:
generator = outlines.generate.text(model)
And modify our metric to parse JSON from the model output:
from typing import Optional, List, Any from opik.evaluation.metrics import base_metric import json
class HallucinationUnstructured(base_metric.BaseMetric): """ A metric that evaluates whether an LLM's output contains hallucinations based on given input and context. """
def score( self, input: str, output: str, context: Optional[List[str]] = None, **ignored_kwargs: Any, ) -> HallucinationResponse: """ Calculate the hallucination score for the given input, output, and optional context field.
Args: input: The original input/question. output: The LLM's output to evaluate. context: A list of context strings. If not provided, the presence of hallucinations will be evaluated based on the output only. **ignored_kwargs: Additional keyword arguments that are ignored.
Returns: HallucinationResponse: A HallucinationResponse object with a score of 1.0 if hallucination is detected, 0.0 otherwise, along with the reason for the verdict. """ llm_query = context_hallucination_template.format(input=input, output=output, context=context)
with torch.no_grad(): return json.loads(generator(llm_query)) # Parse JSON string from response
Keeping the rest of the code the same and running this now results in:
Nearly every string fails to parse correctly. The inference time is also increased dramatically because of the variable length of responses, whereas the structured output helps keep the responses terse.
Without structured generation, it just isn’t feasible to run this kind of evaluation, especially with a model this small. As an experiment, try running this same code with a bigger model and see how the average accuracy score improves.
Can we build more complex LLM judges with structured generation?
The above example of hallucination detection is pretty straightforward. The real value that structured generation brings to LLM judges, however, is that it enables us to build more complex, multi-turn evaluations.
To give an extreme example of what a multi-step evaluation might look like, one recent paper found success in LLM evals by constructing multiple “personas” for different LLM agents, and having the agents debate in an actual courtroom structure:
Forcing different agents to advocate for different positions and examine each other’s arguments, all while having yet another agent act as a “judge” to emit a final decision, significantly increased the accuracy of evaluations.
In order for such a system to work, the handoffs between different agents must go smoothly. If an agent needs to pick between 5 possible actions, we need to be 100% sure that the model will only output one of those 5 valid actions. With structured generation, we can achieve that level of reliability.
Let’s try a worked example, extending our hallucination metric from earlier. We’ll try the following improvement:
On first pass, the model will generate 3 candidate hallucinations, with reasoning for each.
For each candidate, the model will evaluate them individually and assess if they are a hallucination, with expanded reasoning.
If the model finds any candidate to be a hallucination, it will return 1.0 for the entire sample.
By giving the model the ability to generate longer chains of context, we give it space for more “intermediary computation,” and hopefully, a more accurate final output.
First, let’s define a series of prompts for this task:
generate_candidates_prompt = """ You are an expert judge tasked with evaluating the faithfulness of an AI-generated answer to a given context. Your goal is to determine if the provided output contains any hallucinations or unfaithful information when compared to the given context.
Here are the key elements you'll be working with:
1. <context>{context}</context> This is the factual information against which you must evaluate the output. All judgments of faithfulness must be based solely on this context.
2. <output>{output}</output> This is the AI-generated answer that you need to evaluate for faithfulness.
3. <input>{input}</input> This is the original question or prompt. It's provided for context only and should not be used in your faithfulness evaluation.
Evaluation Process: 1. Carefully read the CONTEXT and OUTPUT. 2. Analyze the OUTPUT for any discrepancies or additions when compared to the CONTEXT. 3. Consider the following aspects: - Does the OUTPUT introduce any new information not present in the CONTEXT? - Does the OUTPUT contradict any information given in the CONTEXT? - Does the OUTPUT contradict well-established facts or general knowledge? - Are there any partial hallucinations where some information is correct but other parts are not? - Is the subject of statements correct? Ensure that attributes, actions, or dates are correctly associated with the right entities. - Are there any subtle misattributions or conflations of information, even if dates or other details are correct? - Does the OUTPUT oversimplify or generalize information in a way that changes its meaning or accuracy?
4. Based on your analysis, create a list of 3 statements in the OUTPUT which are potentially hallucinations or unfaithful. For each potentially hallucinated or unfaithful statement from the OUTPUT, explain why you think it violates any of the aspects from step 3.
5. Return your list of statements and associated reasons in the following structured format:
Here is an example output structure (do not use these specific values, this is just to illustrate the format):
{{ "potential_hallucinations": [ {{ "output_statement": "The company was founded in 1995", "reasoning": "There is no mention of a founding date in the CONTEXT. The OUTPUT introduces new information not present in the CONTEXT. }}, {{ "output_statement": "The product costs $49.99.", "reasoning": "The CONTEXT lists the flagship product price at $39.99. The OUTPUT directly contradicts the price given in the CONTEXT." }}, {{ "output_statement": "The flagship product was their most expensive item.", "reasoning": "The CONTEXT lists mentions another product which is more expensive than the flagship product. The OUTPUT directly contradicts information given in the CONTEXT." }} ] }}
Now, please proceed with your analysis and evaluation of the provided INPUT, CONTEXT, and OUTPUT. """
evaluate_candidate_prompt = """ Please examine the following potential hallucination you detected in the OUTPUT:
{candidate}
You explained your reasons for flagging the statement like so:
{reason}
As a reminder, the CONTEXT you are evaluating the statement against is:
{context}
Based on the above, could you answer "yes" to any of the following questions? - Does the OUTPUT introduce any new information not present in the CONTEXT? - Does the OUTPUT contradict any information given in the CONTEXT? - Does the OUTPUT contradict well-established facts or general knowledge? - Are there any partial hallucinations where some information is correct but other parts are not? - Is the subject of statements correct? Ensure that attributes, actions, or dates are correctly associated with the right entities. - Are there any subtle misattributions or conflations of information, even if dates or other details are correct? - Does the OUTPUT oversimplify or generalize information in a way that changes its meaning or accuracy?
Please score the potentially hallucinated statement using the following scale:
- 1.0 if you answered "yes" to any of the previous questions, and you believe the statement is hallucinated or unfaithful to the CONTEXT. - 0.0 if you answered "no" to all of the previous questions, and after further reflection, you believe the statement is not hallucinated or unfaithful to the CONTEXT.
Before responding, please structure your response with the following format
{{ "score": float, "reason": string
}}
Here is an example output structure (do not use these specific values, this is just to illustrate the format):
{{ "score": 1.0, "reason": "The CONTEXT and OUTPUT list different prices for the same product. This leads me to answer 'yes' to the question, 'Does the OUTPUT contradict any information given in the CONTEXT?'" }}
Now, please proceed with your analysis and evaluation.
"""
And now, we can define some Pydantic models for our different model outputs:
# Generated by generate_candidates_prompt class PotentialHallucination(pydantic.BaseModel): output_statement: str reasoning: str
class HallucinationCandidates(pydantic.BaseModel): potential_hallucinations: List[PotentialHallucination]
# Generated by evaluate_candidate_prompt class HallucinationScore(pydantic.BaseModel): score: float reason: str
With all of this, we can put together two generators, one for generating candidate hallucinations, and one for scoring individual candidates:
import outlines
model_kwargs = { "device_map": "auto" }
model = outlines.models.transformers("Qwen/Qwen2.5-0.5B-Instruct", model_kwargs=model_kwargs)
Finally, we can construct an Opik metric. We’ll keep the code for this simple:
class HallucinationMultistep(base_metric.BaseMetric): """ A metric that evaluates whether an LLM's output contains hallucinations using a multi-step appraoch. """
# Initialize to zero, in case the model simply finds no candidates for hallucination score = HallucinationScore(score=0.0, reason="Found no candidates for hallucination")
for candidate in output.potential_hallucinations: followup_query = evaluate_candidate_prompt.format(candidate=candidate.output_statement, reason=candidate.reasoning, context=context) new_score = generator(followup_query) score = new_score if new_score.score > 0.0: # Early return if we find a hallucination return new_score
return score
All we do here is generate the first prompt, which should produce several hallucination candidates when fed to the candidate generator. Then, we pass each candidate (formatted with the candidate evaluation prompt) into the candidate evaluation generator.
If we run it using the same code as before, with slight modifications to use the new metric:
# Define the evaluation task def evaluation_task(x: Dict): # Use new metric metric = HallucinationMultistep() try: metric_score = metric.score( input=x["input"], context=x["context"], output=x["output"] ) hallucination_score = metric_score.score hallucination_reason = metric_score.reason except Exception as e: print(e) hallucination_score = None hallucination_reason = str(e)
# Define the scoring metric check_hallucinated_metric = Equals(name="Correct hallucination score")
res = evaluate( dataset=dataset, task=evaluation_task, scoring_metrics=[check_hallucinated_metric], )
Evaluation: 100%|██████████| 200/200 [19:02<00:00, 5.71s/it] ╭─ HaluEval-qa-samples Balanced (200 samples) ─╮ │ │ │ Total time: 00:19:03 │ │ Number of samples: 200 │ │ │ │ Correct hallucination score: 0.5200 (avg) │ │ │ ╰─────────────────────────────────────────────────╯ Uploading results to Opik ... View the results in your Opik dashboard.
We see a great improvement. Remember that running this same model, with a very similar initial prompt, on this same dataset, resulted in a score of 0.46. By simply adding this additional candidate evaluation step, we immediately increased the score to 0.52. For such a small model, this is great!
Structured generation’s role in the future of LLM evaluations
Most foundation model providers, like OpenAI and Anthropic, offer some kind of structured output mode which will respond to your queries with a predefined schema. However, the world of LLM evaluations extends well beyond the closed ecosystems of these providers’ APIs.
For example:
So-called “white box” evaluations, which incorporate models’ internal states into the evaluation, are impossible with hosted models like GPT-4o.
Fine-tuning a model for your specific evaluation use-case requires you to use open source models.
If you need to run your evaluation pipeline locally, you obviously cannot use a hosted API.
And that’s without getting into comparisons of particular open source models against popular foundation models.
The future of LLM evaluations involves more complex evaluation suites, combining white box metrics, classic heuristic methods, and LLM judges into robust, multi-turn systems. Open source, or at the very least, locally-available LLMs are a major part of that future—and structured generation is a fundamental part of the infrastructure that is enabling that future.
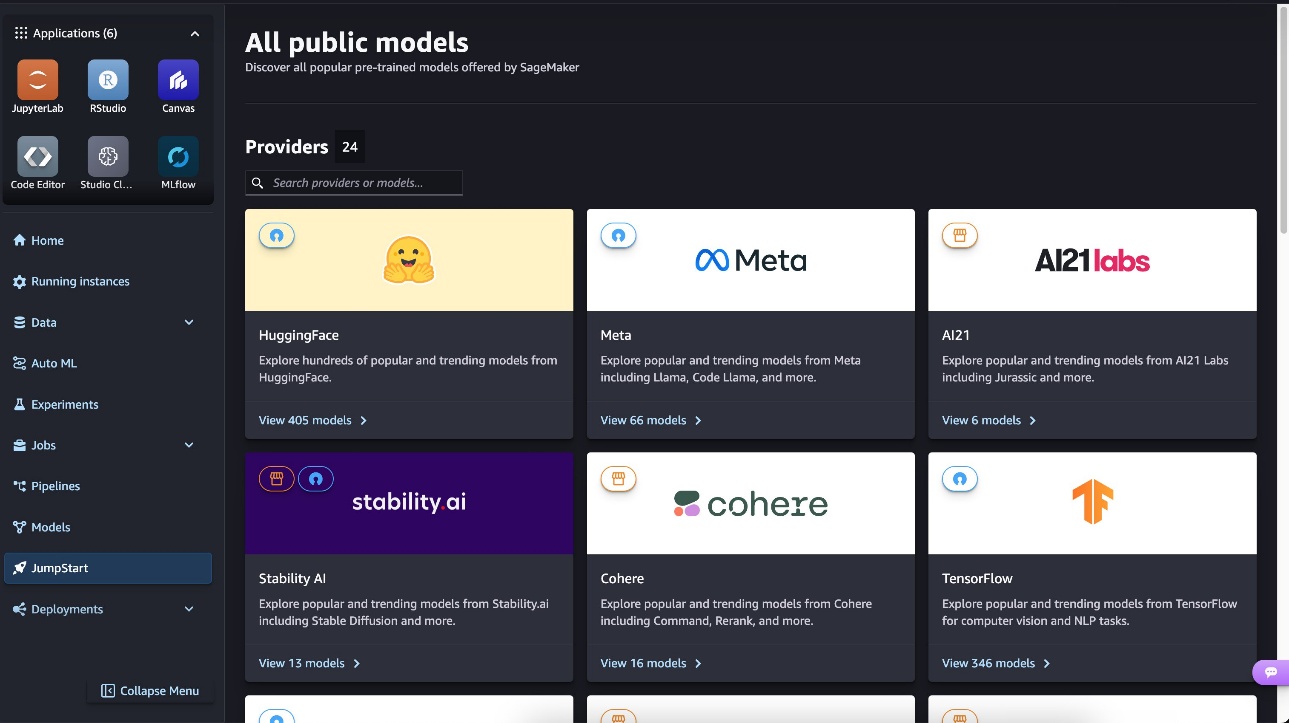
Today, we are excited to announce that Pixtral 12B (pixtral-12b-2409), a state-of-the-art vision language model (VLM) from Mistral AI that excels in both text-only and multimodal tasks, is available for customers through Amazon SageMaker JumpStart. You can try this model with SageMaker JumpStart, a machine learning (ML) hub that provides access to algorithms and models that can be deployed with one click for running inference. In this post, we walk through how to discover, deploy, and use the Pixtral 12B model for a variety of real-world vision use cases.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.