Thisis the first in a two-part series on using SQLite for machine learning. In this article, I dive into why SQLite is rapidly becoming a production-ready database. In the second article, I will discuss how to perform retrieval-augmented-generation using SQLite.
If you’d like a custom web application with generative AI integration, visit losangelesaiapps.com
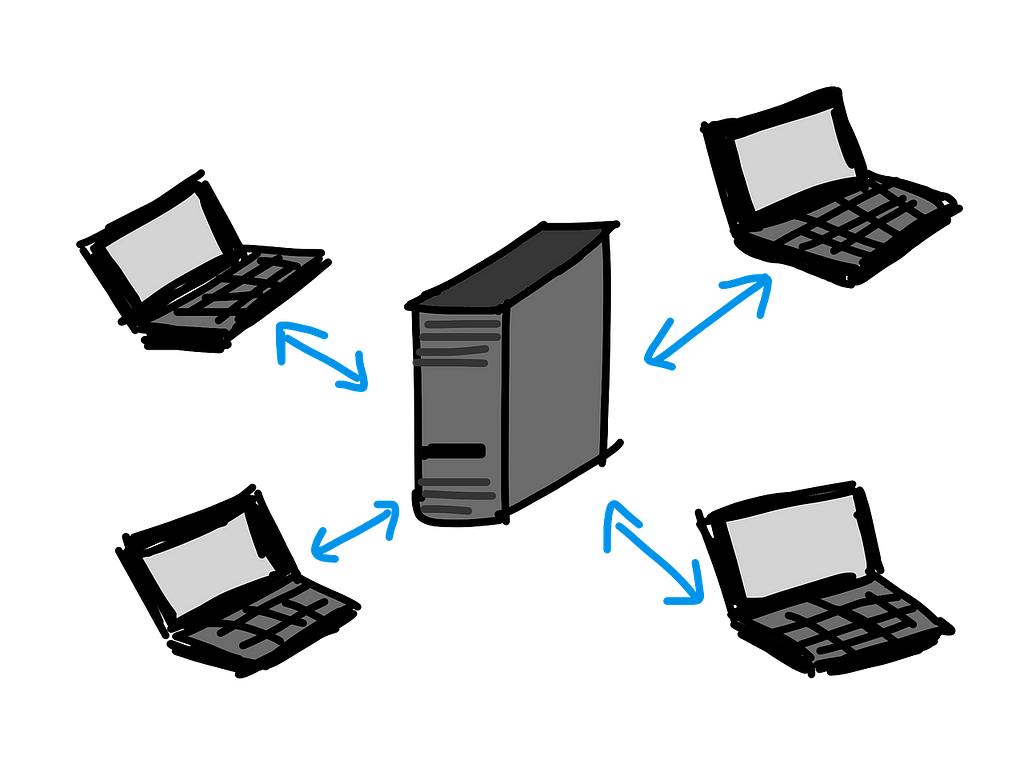
Most databases running software today operate on a client-server architecture. In this architecture, the server is the central system that manages data. It processes requests from and sends responses to clients. Clients here refer to users or applications that interact with the database through the server.
The client-server architecture. From pixabay.
A simple way to understand this architecture is to use the analogy of libraries. The server is the library, each piece of data is a book, and the client is a visitor. In this world, visitors don’t pick books out directly from the shelves. They instead must go through the librarian, who has meticulously organized their library to make it easy to find a book. In this world, a visitor’s access to the library is mediated entirely through the library’s staff (server-side).
This is a pretty neat architecture. However, for smaller, lightweight applications it is engineering overkill. If you only have a few books, why do you need to build multiple shelves, let alone multiple rooms? The alternative to the client-server architecture is the single-file architecture used by the SQLite database.
For the uninitiated, SQLite is the Platonic ideal of databases. As opposed to running an entire server to manage the access to data, this database is housed entirely within a single file. Your application is then able to create, read, update, and destroy data by simply modifying this one file. When you deploy a web application backed by a client-server database, you are deploying not one service but two services: one for your application and one for your database. With SQLite, you only have to deploy a single service: your application with the SQLite file included. This means less complexity and less cost.
Returning to our analogy, using SQLite is like having a single notebook in which all of your data is stored. No shelves, no libraries, no librarians. You just open the book and add, delete, or update your data. Perhaps you can get fancy, and add an index in the back of your book to speed up search. You can imagine how much simpler this would be.
However, as they say in economics: there are no solutions, there are only trade-offs. SQLite is not perfect, and there are valid reasons for why it has rarely seen usage in production. In this article, I will highlight some of the issues that have dogged SQLite and how recent advancements have removed these barriers.
Issue #1: Concurrency
The primary issue in SQLite has traditionally been concurrency related. SQLite uses a write lock to ensure that only one write operation occurs at a time. We don’t want transactions interfering with each other. If you attempt to send concurrent write requests, you will often get a SQLITE_BUSY error, and one of the transactions will have been lost. In the case of concurrent requests, we want the transactions to queue up and play nice with each other.
Unfortunately, the default transaction mode in SQLite does not facilitate this. Some important background: a transaction typically involves a series of database statements, such as reads and writes, that are executed together.
-- An example transaction BEGIN DEFERRED TRANSACTION; SELECT * FROM inventory WHERE id = 1; -- Statement 1 UPDATE inventory SET stock = stock + 1 WHERE id = 1; -- Statement 2
The default transaction mode in SQLite is the deferred transaction mode. In this mode:
No lock is acquired at the start of the transaction.
A read-only statement doesn’t trigger a write lock; it only requires a shared read lock, which allows concurrent reads. Think SELECT statements.
A write statement requires an exclusive write lock, which blocks all other reads and writes until the transaction is complete. Think INSERT, UPDATE, or DELETE statements.
As an example, take a look at the following two transactions. Suppose they were to run at the same time:
-- Transaction 1 BEGIN DEFERRED TRANSACTION; SELECT * FROM inventory WHERE id = 1; UPDATE inventory SET stock = stock + 1 WHERE id = 1;
-- Transcation 2 BEGIN DEFERRED TRANSACTION; UPDATE inventory SET stock = stock - 1 WHERE id = 1;
-- Example sequence of events: -- Transaction 1 begins -- SELECT statement: No lock is acquired yet. -- Transaction 2 begins -- Acquires a write lock (UPDATE statement). -- Transcation 1 continues -- Tries to acquire a write lock (UPDATE statement). -- Fails because Transaction 2 already committed and released the lock. -- SQLite throws SQLITE_BUSY. -- Transaction 2 commits successfully. Transaction 1 has failed.
In this scenario, because Transaction 1 was mid-transaction when the SQLITE_BUSY exception was thrown, it will not be re-queued after Transaction 2 is finished with the write lock; it will just be cancelled. SQLite doesn’t want to risk inconsistent results should another transaction modify overlapping data during the lock wait, so it just tells the interrupted transaction to buzz off.
Think of it this way: imagine you and your friend are sharing a notebook. You start reading a half-finished story in the notebook, planning to write the next part. But before you can pick up your pen, your friend snatches the notebook. “You weren’t writing anything anyway!” they exclaim. What if they change something crucial in your story? Frustrated and unable to continue, you give up in a huff, abandoning your attempt to finish the story. Turns out, your friend isn’t as nice as you thought!
How can we fix this issue? What if you establish the following rule: when one of you grabs the notebook, regardless of if you are reading or writing, that person gets to use the notebook until they are done? Issue solved!
This transaction mode in SQLite is known as immediate. Now, when one transaction begins, regardless of whether it is writing or reading, it claims the write lock. If a concurrent transaction attempts to claim the write lock, it will now queue up nicely behind the current one instead of throwing the SQLITE_BUSY .
Using the immediate transaction mode goes a long way towards solving the concurrency issue in SQLite. To continue improving concurrency, we can also change the journal mode. The default here is a rollback journal. In this paradigm, the original content of a database page is copied before modification. This way, if the transaction fails or if you so desire, you can always go back to the journal to restore the database to its original state. This is great for reproducibility, but bad for concurrency. Copying an entire page in a database is slow and grabs the write lock, delaying any read operations.
To fix this issue we can instead use write-ahead logging (WAL). Rather than writing changes directly to the main database file, the changes are first recorded in a separate log file (the “write-ahead log”) before being applied to the database at regular intervals. Readers can still access the most recently committed write operations, as SQLite checks the WAL file in addition to the main database file on read. This separates write and read operations, easing concurrency issues that can come as a result of scaling.
To continue our analogy, write-ahead logging is like grabbing a post-it-note every time a change to the shared notebook needs to occur. If anyone wants to read a section of the notebook, they can check if there are any post-its attached to that section to get the latest updates. You can have many people simultaneously reading the notebook at the same time with this method. Once a lot of post-its start to accumulate, you can then edit the actual notebook itself, tossing the post-its once the edits have finished.
These configuration options in SQLite have been around for decades (write-ahead-logging was introduced in 2010). Given this, why hasn’t SQLite been used in production for decades? That leads us to our next issue.
Issue #2: Slow hardware
Hard disk drives (HDD) are notoriously slow compared to solid state drives (SSD) on a variety of operations that are important to database management. For example, SSDs are about 100 times faster than HDDs when it comes to latency (time it takes for a single I/O operation). In random I/O operations per second (IOPS), SSDs are about 50–1000 times faster than HDDs. SSDs are so much faster than HDDs because of the lack of moving parts. HDDs use spinning disks and moving parts to read and write data, much like an old turntable, whereas SDDs use only electronic components, much like a giant USB stick.
Despite their inferiority, HDDs have historically dominated the storage market primarily due to low cost. However, SDDs have quickly been catching up. In 2011, SSDs were roughly 32 times more expensive per GB than HDDs (source). By 2023, the price gap narrowed, with SSDs now being about 3 to 5 times more expensive per GB compared to HDDs (source). In the past year, SSD prices have increased due to cuts from manufacturers like Samsung and increasing demand in data centers. In the long run however, we can expect SSDs to continue to decrease in price. Even if parity is never reached with HDDs, the low absolute price is enough to ensure widespread adoption. In 2020, SSDs outsold HDDs, with 333 million units shipped compared to 260 million HDDs, marking a turning point in the storage market (source).
As of December 2024, you can rent a dedicated vCPU with 80 GB of SSD storage for about $16 USD per month on a service like Hetzner. 240 GB can be had for about $61. You can get even cheaper prices with a shared vCPU. For many smaller applications this storage is more than enough. The use of cheap SSDs has removed a significant bottleneck when using SQLite in production-grade applications. But there is still one more important issue to deal with.
Issue #3: Backups
It goes without saying that having a backup to your database is critical in production. The last thing any startup wants is to have their primary database get corrupted and all user data lost.
The first option for creating a backup is the simplest. Since the SQLite database is just a file, you can essentially copy and paste your database into a folder on your computer, or upload it to a cloud service like AWS S3 buckets for more reliability. For small databases with infrequent writes this is a great option. As a simple example (taken from the Litestream docs), here is a bash script creating a backup:
#!/bin/bash
# Ensure script stops when commands fail. set -e
# Backup our database to the temp directory. sqlite3 /path/to/db "VACUUM INTO '/path/to/backup'"
# Compress the backup file for more efficient storage gzip /tmp/db
# Upload backup to S3 using a rolling daily naming scheme. aws s3 cp /tmp/db.gz s3://mybucket/db-`date +%d`.gz
A few notes:
The -e option inset -e stands for “exit immediately”. This makes sure that the script will be stopped if any command fails.
SQLite’s VACUUM INTO command creates a compact backup of the SQLite database. It reduces fragmentation in the database and the file size. Think of it as a neat and tidy version of your database. However you don’t have to use VACUUM INTO ; you can replace it with .backup . This copies the entire database file, including all its data and structure as-is to another file.
SQLite databases compress well, and the gzip command facilitates this.
Finally, you can upload the copy of the file to your cloud storage provider of choice. Here we are uploading to S3.
If you want to have your backups run automatically, you can configure crontab to run this job on a regular basis. Here we are running the script daily at midnight:
# Edit your cron jobs crontab -e
# Add this to the end of the crontab 0 0 * * * /path/to/my_backup_script.sh
For write-heavy databases, where you would want to capture the state of the database at any given moment, you can use Litestream. This is an open-source tool designed to provide real-time replication for SQLite databases by streaming changes to a remote storage backend.
Litestream is able to track changes to SQLite’s WAL file. Remember the post-it notes? Whenever a new transaction is recorded to the WAL file, Litestream is able to replicate these incrementally to your cloud storage provider of choice. This allows us to maintain a near real-time backup of the database without creating full copies each time.
To get started with Litestream, you first have to install it. On MacOS this means using Homebrew. Then, you need to setup a litestream.yml configuration file:
Here, we are going to be streaming transactions to our database to an S3 bucket. Then we can run the following command to begin replication:
litestream replicate -config /etc/litestream.yml
In this case, we are setting any transactions in your.db to be replicated in an S3 bucket. That’s it! You are then able to restore a SQLite database to any previous state by replaying WAL changes. As an example, if you want to create a copy of your db called restored.db from a timestamp of 15:00 UTC dated 2024–12–10, you can run the following command:
To get a backup of the latest version of your database, just omit the -timestamp flag .
Conclusion
I encourage you to watch this recent talk at Rails World 2024 to see how SQLite is rapidly becoming production-ready. They have implemented some of the changes we have discussed here to their SQLite adapter. I also recommend reading Stephen Margheim’s article detailing his work on SQLite in Rails if you want to dive deeper. You better believe these sorts of improvement are coming soon to Django, Laravel, etc.
The improvements to SQLite for production are not finished. David Heinemeier Hansson, creator of Rails, wants to push SQLite to be able to run a mid-size SaaS company off of. Exciting times!
Our guiding principle is that it’s never a bad time to learn new things, but we also know that different moments call for different types of learning. Here at TDS, we’ve traditionally published lots of hands-on, roll-up-your-sleeves guides and tutorials as soon as we kick off a new year—and we’re sure that will be the case come January 2025, too.
For now, as we enter the peak of the holiday season, we wanted to highlight some of our best recent articles that call for a bit more reflection and a slower pace of processing: stories you can savor as you lounge on a comfy armchair, say, rather than while typing code away on your laptop (though you can do that too, of course; we won’t hold it against you!).
From the cultural impact of AI-generated content to a Bayesian analysis of dogs’ pooping habits (yes, you’ve read that right), we hope you enjoy this lineup of thought-provoking, engaging articles. And stay tuned: we can’t wait to share our 2024 highlights with you in next week’s final-edition-of-the-year Variable.
The Economics of Artificial Intelligence — What Does Automation Mean for Workers? In his comprehensive analysis of AI’s effect on the workforce, Isaac Tham introduces a powerful framework: “AI augments or automates labor based on its performance relative to workers in a given task. If AI is better than labour, labour is automated, but if labour is better than AI, AI augments labour.” He goes on to unpack the stakes, risks, and potential benefits of AI’s rapidly growing footprint.
The Cultural Impact of AI Generated Content: Part 1 Business implications take up much of the space in conversations around AI, but as Stephanie Kirmer stresses, we shouldn’t ignore the potentially seismic shifts AI-generated content causes in the cultural sphere, too: “It would be silly to expect our ways of thinking to not change as a result of these experiences, and I worry very much that the change we’re undergoing is not for the better.”
ChatGPT: Two Years Later November 2022, when OpenAI launched the chatbot that would change everything (or at least… a lot of things), feels at once like two days and two decades ago. To help us make sense of our post-ChatGPT world, Julián Peller presents a panoramic overview of the past two years, a period of monumental transition within the “generative-AI revolution.”
The Name That Broke ChatGPT: Who is David Mayer? For anyone who enjoys their explorations of AI’s inner workings with a generous dose of intrigue and mystery, Cassie Kozyrkov’s latest article fits the bill: it tackles some of the thorniest questions around LLM-based tools (privacy, bias, and prompt hacking, to name a few) through the example of one elusive name.
Understanding DDPG: The Algorithm That Solves Continuous Action Control Challenges Why not take the time this holiday season to expand your knowledge of deep reinforcement learning algorithms? Sirine Bhouri’s debut TDS article walks us through the theory and architecture behind the Deep Deterministic Policy Gradient (DDPG) algorithm, tests its performance, and examines its potential applications in bioengineering.
LLM Routing — Intuitively and Exhaustively Explained With thousands of large language models to choose from, how should practitioners decide which ones to choose for a given task? Daniel Warfield’s accessible deep dive into LLM routing explains how this “advanced inferencing technique” streamlines this process and how the different components it relies on complement each other.
The Intuition behind Concordance Index — Survival Analysis Understanding and preventing churn remains one of the most common goals for industry-embedded data scientists. Antonieta Mastrogiuseppe provides a thorough primer on the underlying math of survival analysis, and the key role the concordance index plays in assessing a model’s accuracy.
Dog Poop Compass Can a 5-year-old Cavalier King Charles Spaniel teach us important lessons in Bayesian statistics? It turns out the answer is yes — as long as you follow along Dima Sergeev’s gripping account of his attempts to detect patterns in his dog’s “bathroom” rituals.
Causality — Mental Hygiene for Data Science To round out our lineup this week, we invite you to dig into Eyal Kazin’s thoughtful reflection on causal tools—and when (and whether) to use them. Based on his recent PyData Global conference lecture, this article balances a big-picture analysis of causal inference with the nitty-gritty factors that shape the ways we apply causal thinking in day-to-day workflows.
Thank you for supporting the work of our authors! As we mentioned above, we love publishing articles from new authors, so if you’ve recently written an interesting project walkthrough, tutorial, or theoretical reflection on any of our core topics, don’t hesitate to share it with us.
Rome-based venture capital firm Scientifica has launched a €200mn fund to support startups in quantum computing, artificial intelligence, and other frontier technologies. The fund, set to launch early next year, will provide early-stage companies with both financial backing and access to advanced lab spaces. Scientifica’s fund is based on a “Zero CapEx” model. Startups can use Scientifica’s 4,000 m² of laboratories and a network of 70 certified labs in Italy without incurring upfront costs. The aim is to reduce barriers to innovation by giving early-stage access to cutting-edge tools and facilities. The model reflects a growing trend of venture capital firms supporting…
If you live in Europe and you use a neobank, you’ve likely been interacting with Upvest’s investment products without even knowing it. The Berlin-based startup runs a stock-trading API that integrates into some of the biggest fintechs in Europe — Revolut, N26, Bunq, Plum, Raisin, Shares and Vivid. Through these banks, some 50 million users have access use the company’s investment products, it said. Amid a broader neobank boom, Upvest today announced it has raised €100M in a Series C funding round led by Hedosophia and joined by Sapphire Ventures. Existing investors, Bessemer Venture Partners, BlackRock, Earlybird, HV Capital, Motive Ventures, and Notion Capital also chipped…
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.