This is the second article of our GPT series, where we will dive into the development of GPT-2 and GPT-3, with model size increased from 117M to a staggering 175B.
We choose to cover GPT-2 and GPT-3 together not just because they share similar architectures, but also they were developed with a common philosophy aimed at bypassing the finetuning stage in order to make LLMs truly intelligent. Moreover, to achieve that goal, they both explored several key technical elements such as task-agnostic learning, scale hypothesis and in-context learning, etc. Together they demonstrated the power of training large models on large datasets, inspired further research into emergent capabilities, established new evaluation protocols, and sparked discussions on enhancing the safety and ethical aspects of LLMs.
Below are the contents we will cover in this article:
Overview: The paradigm shift towards bypassing finetuning, and the three key elements made this possible: task-agnostic learning, the scaling hypothesis, and in-context learning.
GPT-2: Model architecture, training data, evaluation results, etc.
GPT-3: Core concepts and new findings.
Conclusions.
Overview
The Paradigm Shift Towards Bypassing Finetuning
In our previous article, we revisited the core concepts in GPT-1 as well as what had inspired it. By combining auto-regressive language modeling pre-training with the decoder-only Transformer, GPT-1 had revolutionized the field of NLP and made pre-training plus finetuning a standard paradigm.
But OpenAI didn’t stop there.
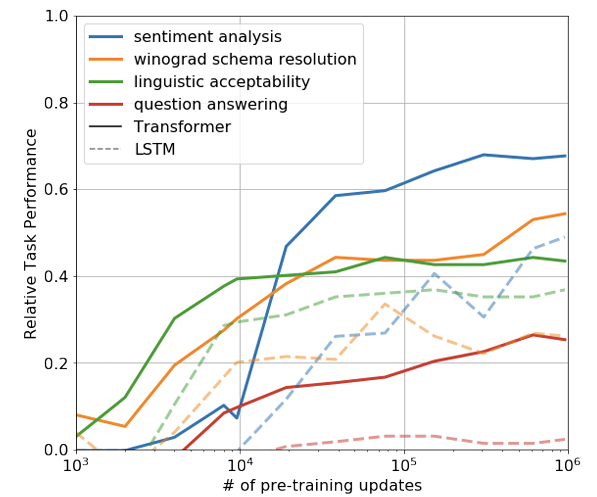
Rather, while they tried to understand why language model pre-training of Transformers is effective, they began to notice the zero-shot behaviors of GPT-1, where as pre-training proceeded, the model was able to steadily improve its performance on tasks that it hadn’t been finetuned on, showing that pre-training could indeed improve its zero-shot capability, as shown in the figure below:
Figure 1. Evolution of zero-shot performance on different tasks as a function of LM pre-training updates. (Image from the GPT-1 paper.)
This motivated the paradigm shift from “pre-training plus finetuning” to “pre-training only”, or in other words, a task-agnostic pre-trained model that can handle different tasks without finetuning.
Both GPT-2 and GPT-3 are designed following this philosophy.
But why, you might ask, isn’t the pre-training plus finetuning magicworking just fine? What are the additional benefits of bypassing the finetuning stage?
Limitations of Finetuning
Finetuning is working fine for some well-defined tasks, but not for all of them, and the problem is that there are numerous tasks in the NLP domain that we have never got a chance to experiment on yet.
For those tasks, the requirement of a finetuning stage means we will need to collect a finetuning dataset of meaningful size for each individual new task, which is clearly not ideal if we want our models to be truly intelligent someday.
Meanwhile, in some works, researchers have observed that there is an increasing risk of exploiting spurious correlations in the finetuning data as the models we are using become larger and larger. This creates a paradox: the model needs to be large enough so that it can absorb as much information as possible during training, but finetuning such a large model on a small, narrowly distributed dataset will make it struggle when generalize to out-of-distribution samples.
Another reason is that, as humans we do not require large supervised datasets to learn most language tasks, and if we want our models to be useful someday, we would like them to have such fluidity and generality as well.
Now perhaps the real question is that, what can we do to achieve that goal and bypass finetuning?
Before diving into the details of GPT-2 and GPT-3, let’s first take a look at the three key elements that have influenced their model design: task-agnostic learning, the scale hypothesis, and in-context learning.
Task-agnostic Learning
Task-agnostic learning, also known as Meta-Learning or Learning to Learn, refers to a new paradigm in machine learning where the model develops a broad set of skills at training time, and then uses these skills at inference time to rapidly adapt to a new task.
For example, in MAML (Model-Agnostic Meta-Learning), the authors showed that the models could adapt to new tasks with very few examples. More specifically, during each inner loop (highlighted in blue), the model firstly samples a task from a bunch of tasks and performs a few gradient descent steps, resulting in an adapted model. This adapted model will be evaluated on the same task in the outer loop (highlighted in orange), and then the loss will be used to update the model parameters.
Figure 2. Model-Agnostic Meta-Learning. (Image from the MAML paper)
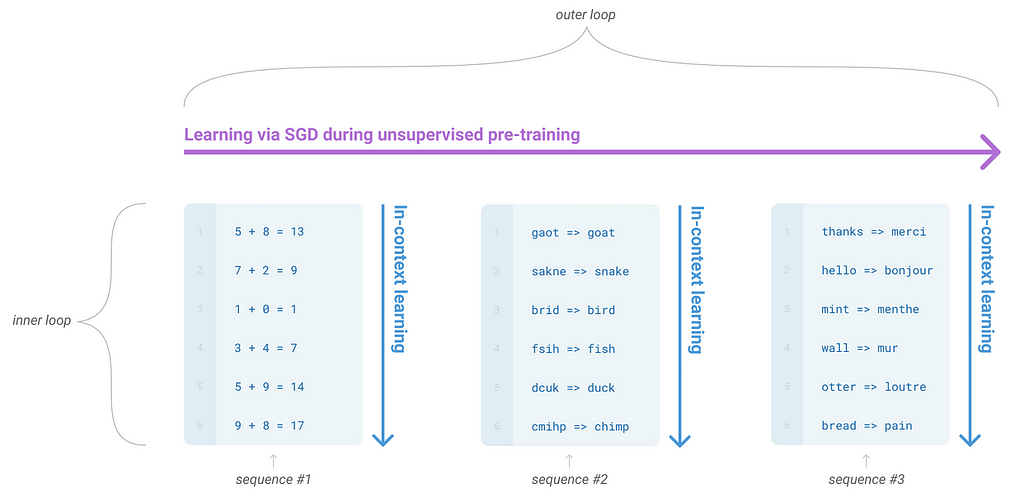
MAML shows that learning could be more general and more flexible, which aligns with the direction of bypassing finetuning on each individual task. In the follow figure the authors of GPT-3 explained how this idea can be extended into learning language models when combined with in-context learning, with the outer loop iterates through different tasks, while the inner loop is described using in-context learning, which will be explained in more detail in later sections.
Figure 3. Language model meta-learning. (Image from GPT-3 paper)
The Scale Hypothesis
As perhaps the most influential idea behind the development of GPT-2 and GPT-3, the scale hypothesis refers to the observations that when training with larger data, large models could somehow develop new capabilities automatically without explicit supervision, or in other words, emergent abilities could occur when scaling up, just as what we saw in the zero-shot abilities of the pre-trained GPT-1.
Both GPT-2 and GPT-3 can be considered as experiments to test this hypothesis, with GPT-2 set to test whether a larger model pre-trained on a larger dataset could be directly used to solve down-stream tasks, and GPT-3 set to test whether in-context learning could bring improvements over GPT-2 when further scaled up.
We will discuss more details on how they implemented this idea in later sections.
In-Context Learning
As we show in Figure 3, under the context of language models, in-context learning refers to the inner loop of the meta-learning process, where the model is given a natural language instruction and a few demonstrations of the task at inference time, and is then expected to complete that task by automatically discovering the patterns in the given demonstrations.
Note that in-context learning happens in the testing phase with no gradient updates performed, which is completely different from traditional finetuning and is more similar to how humans perform new tasks.
In case you are not familiar with the terminology, demonstrations usually means exemplary input-output pairs associated with a particular task, as we show in the “examples” part in the figure below:
Figure 4. Example of few-shot in-context learning. (Image from GPT-3 paper)
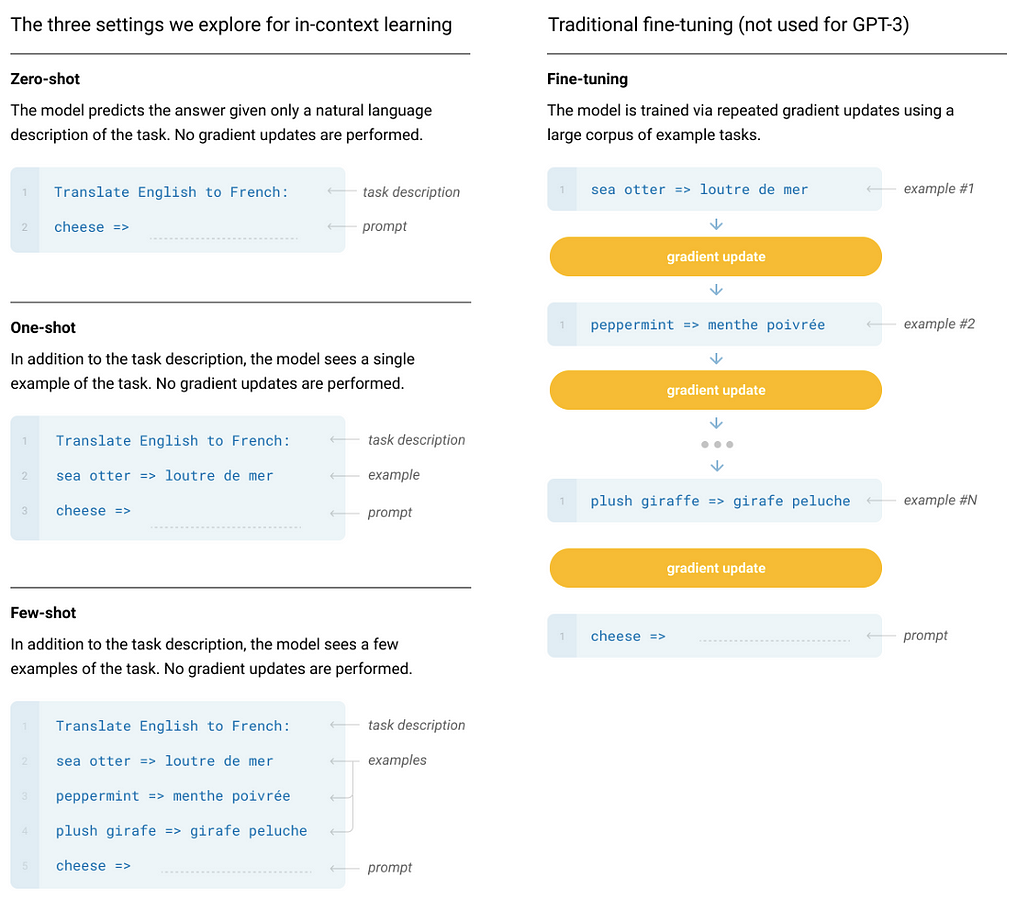
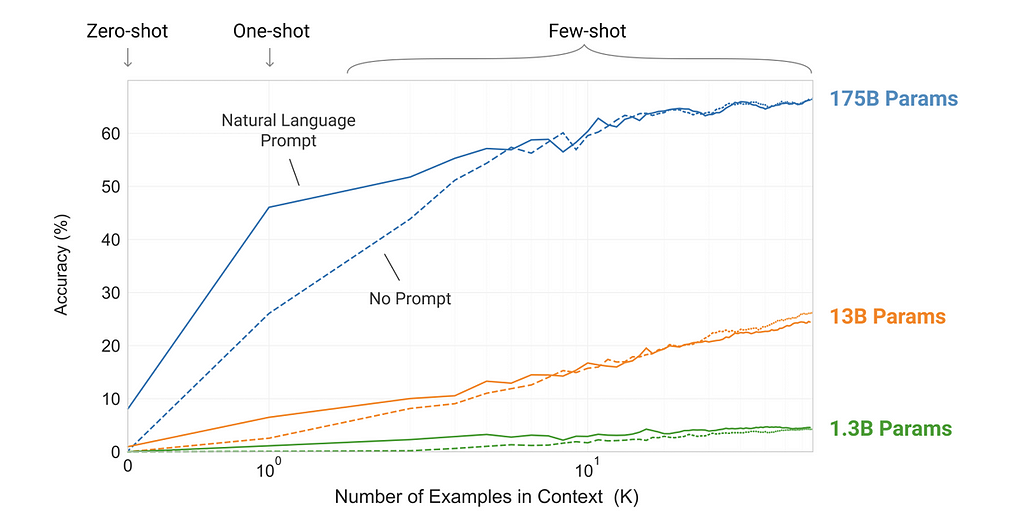
The idea of in-context learning was explored implicitly in GPT-2 and then more formally in GPT-3, where the authors defined three different settings: zero-shot, one-shot, and few-shot, depending on how many demonstrations are given to the model.
Figure 5. zero-shot, one-shot and few-shot in-context learning, contrasted with traditional finetuning. (Image from GPT-3 paper)
In short, task-agnostic learning highlights the potential of bypassing finetuning, while the scale hypothesis and in-context learning suggest a practical path to achieve that.
In the following sections, we will walk through more details for GPT-2 and GPT-3, respectively.
GPT-2
Model Architecture
The GPT-2 model architecture is largely designed following GPT-1, with a few modifications:
Moving LayerNorm to the input of each sub-block and adding an additional LayerNorm after the final self-attention block to make the training more stable.
Scaling the weights of the residual layers by a factor of 1/sqrt(N), where N is the number of residual layers.
Expanding the vocabulary to 50257, and also using a modified BPE vocabulary.
Increasing context size from 512 to 1024 tokens and using a larger batch size of 512.
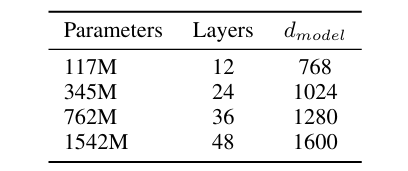
In the GPT-2 paper, the authors trained four models with approximately log-uniformly spaced sizes, with number of parameter ranging from 117M to 1.5B:
Table 1. Architecture hyperparameters for 4 GPT-2 models. (Image from GPT-2 paper)
Training Data
As we scale up the model we also need to use a larger dataset for training, and that is why in GPT-2 the authors created a new dataset called WebText, which contains about 45M links and is much larger than that used in pre-training GPT-1. They also mentioned lots of techniques to cleanup the data to improve its quality.
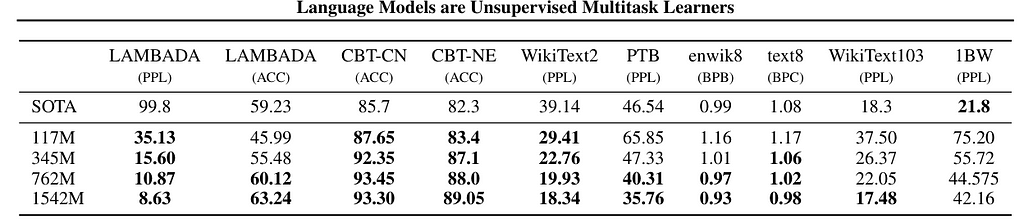
Evaluation Results
Overall, GPT-2 achieved good results on many tasks, especially for language modeling related ones. However, for tasks like reading comprehension, translation and QA, it still performed worse than the respective SOTA models, which partly motivates the development of GPT-3.
Table 2. GPT-2 zero-shot performance. (Image from GPT-2 paper)
GPT-3
Model Architecture
GPT-3 adopted a very similar model architecture to that of GPT-2, and the only difference is that GPT-3 used an alternating dense and locally banded sparse attention patterns in Transformer.
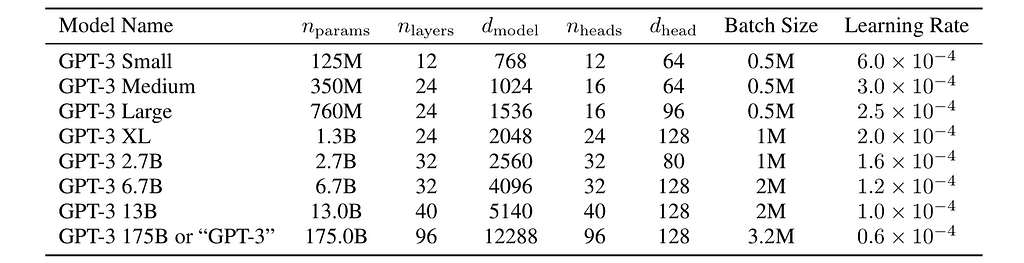
GPT-3 trained 8 models with different sizes, with number of parameters ranging from 125M to 175B:
Table 3. Architecture hyperparameters for 8 GPT-3 models. (Image from GPT-3 paper)
Training Data
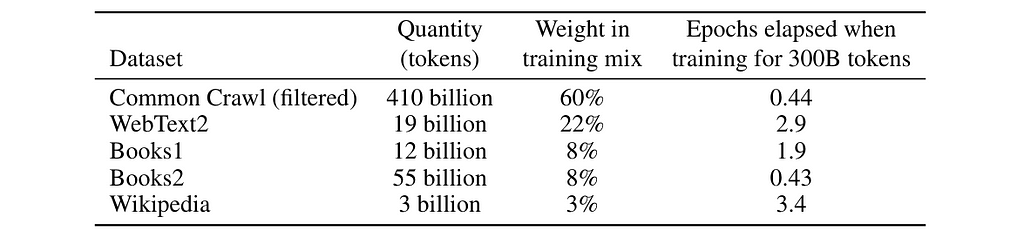
GPT-3 model was trained on even larger datasets, as listed in the table below, and again the authors did some cleanup work to improve data quality. Meanwhile, training datasets were not sampled in proportion to their size, but rather according to their quality, with high-quality dataset sampled more frequently during training.
Table 4. Datasets used in GPT-3 training. (Image from GPT-3 paper)
Evaluation Results
By combining larger model with in-context learning, GPT-3 achieved strong performance on many NLP datasets including translation, question-answering, cloze tasks, as well as tasks require on-the-fly reasoning or domain adaptation. The authors presented very detailed evaluation results in the original paper.
A few findings that we want to highlight in this article:
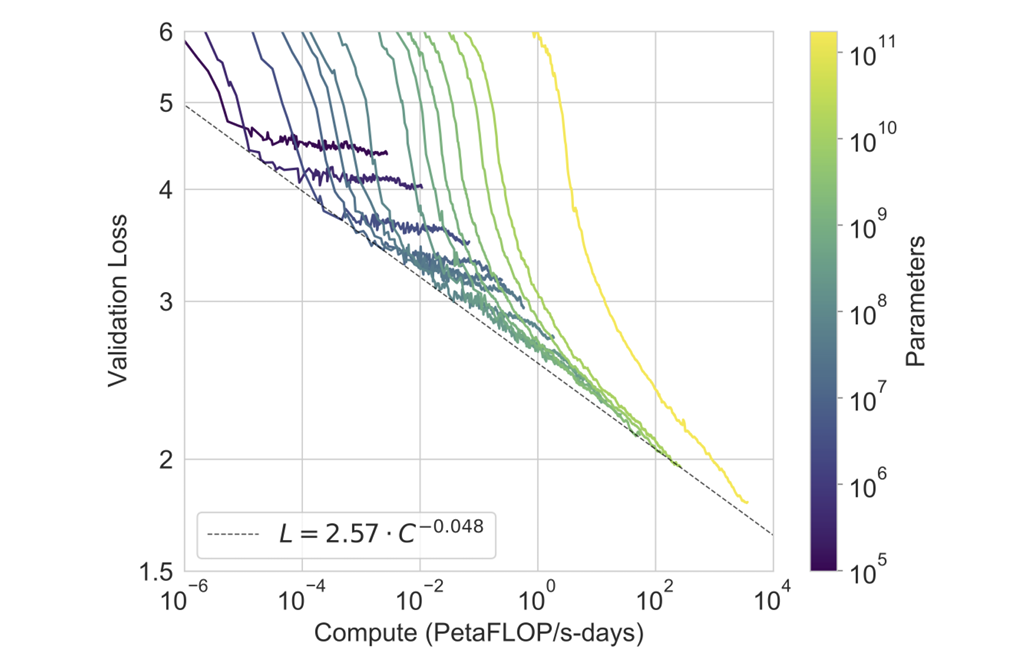
Firstly, during training of GPT-3 they observed a smooth scaling trend of performance with compute, as shown in the figure below, where the validation loss decreases linearly as compute increasing exponentially.
Figure 6. Smooth scaling of performance with compute. (Image from GPT-3 paper)
Secondly, when comparing the three in-context learning settings (zero-shot, one-shot and few-shot), they observed that larger models appeared more efficient in all the three settings:
Figure 7. Larger models are more efficient in in-context learning. (Image from GPT-3 paper)
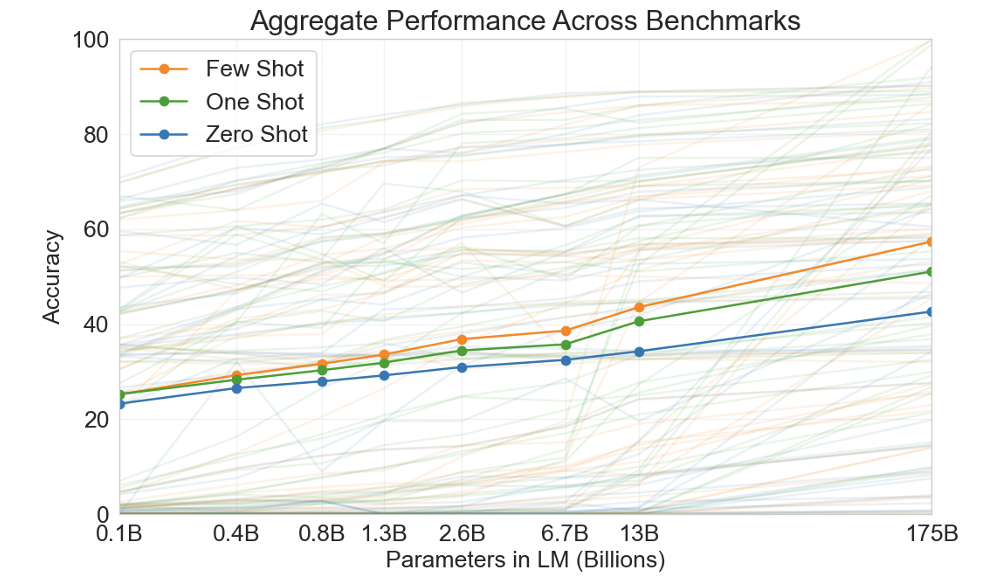
Following that, they plotted the aggregate performance for all the three settings, which further demonstrated that larger models are more effective, and few-shot performance increased more rapidly than the other two settings.
Figure 8. Aggregate performance for all 42 accuracy-denominated benchmarks. (Image from GPT-3 paper)
Conclusions
The development of GPT-2 and GPT-3 bridges the gap between the original GPT-1 with more advanced versions like InstructGPT, reflecting the ongoing refinement of OpenAI’s methodology in training useful LLMs.
Their success also paves the way for new research directions in both NLP and the broader ML community, with many subsequent works focusing on understanding emergent capabilities, developing new training paradigms, exploring more effective data cleaning strategies, and proposing effective evaluation protocols for aspects like safety, fairness, and ethical considerations, etc.
In the next article, we will continue our exploration and walk you through the key elements of GPT-3.5 and InstructGPT.
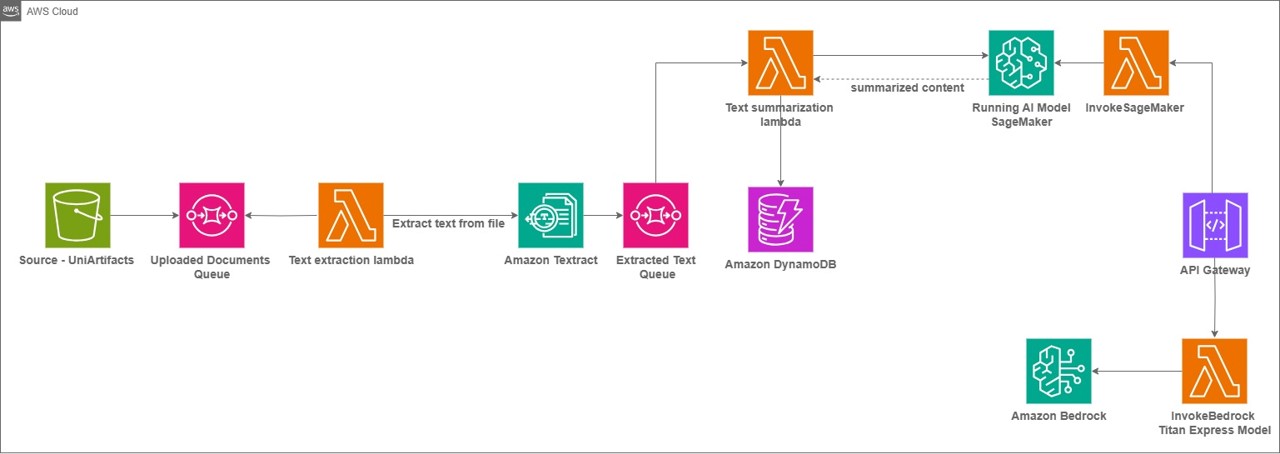
The Education and Training Quality Authority (BQA) plays a critical role in improving the quality of education and training services in the Kingdom Bahrain. BQA reviews the performance of all education and training institutions, including schools, universities, and vocational institutes, thereby promoting the professional advancement of the nation’s human capital. In this post, we explore how BQA used the power of Amazon Bedrock, Amazon SageMaker JumpStart, and other AWS services to streamline the overall reporting workflow.
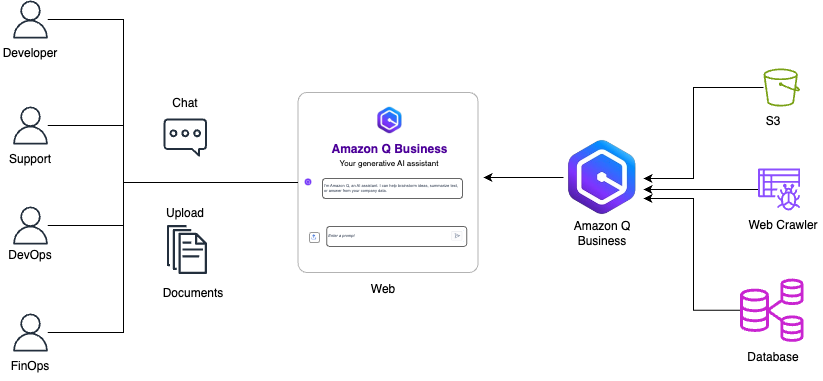
This post shows how MuleSoft introduced a generative AI-powered assistant using Amazon Q Business to enhance their internal Cloud Central dashboard. This individualized portal shows assets owned, costs and usage, and well-architected recommendations to over 100 engineers.
Eindhoven-based startup Photon IP has raised €4.75mn in seed funding as it looks to scale up its unique method for creating energy-efficient photonic chips. AI systems, data centres, fibre-optic networks, and even some sensors rely on photonic chips to send and receive information using light. These chips are a big deal because they’re faster and use less energy than typical semiconductors, which transfer data through electricity. But to make these high-performance, light-speed chips you need special compounds called III-V materials, such as indium phosphide. “These materials are relatively scarce and expensive though, so the industry has been looking at ways of…
In 2018, after decades of research and tens of millions in funding, Russian astronauts attached a wildlife-tracking receiver to the exterior of the International Space Station (ISS). The device received data from tagged animals across the planet and beamed it to a ground station in Moscow. From there, it went to an open-source database called Movebank. The space tracker was the final piece of the puzzle for the ICARUS project, an international effort led by German biologist Martin Wikelski to track the migratory patterns of wildlife from space. It was a game-changer for conservationists, who could monitor the journeys of…
Several sources report the firewall in macOS Sequoia can sometimes leak data after an update. Here’s how to test and fix it.
macOS Sequoia can sometimes leak data after an update.
The macOS firewall in System Settings allows you to protect your Mac and filter network traffic based on a set of rules.
Several sites, includingmullvad.net have reported that after macOS Sequoia updates, the firewall built into macOS may leak some data, allowing it to avoid firewall rules.
Mobile gamers rejoice, the Abxylute S9 is an affordable controller that can stretch to fit your cased iPhone or iPad mini with a powerful set of customization features.
Abxylute S9 controller review: a controller for your entire Apple ecosystem
A controller manufacturer called Abxylute has finally built the perfect mobile gaming controller for iPhone and iPad mini owners. If all it did was stretch to fit an iPad mini and cost under $100, that would be enough, but it’s so much more than that.
The Abxylute S9 is a wraparound controller that connects to the iPhone or iPad mini over USB-C while gripping it from either side. The end result is a mobile gaming solution similar to a Nintendo Switch or Steam Deck.
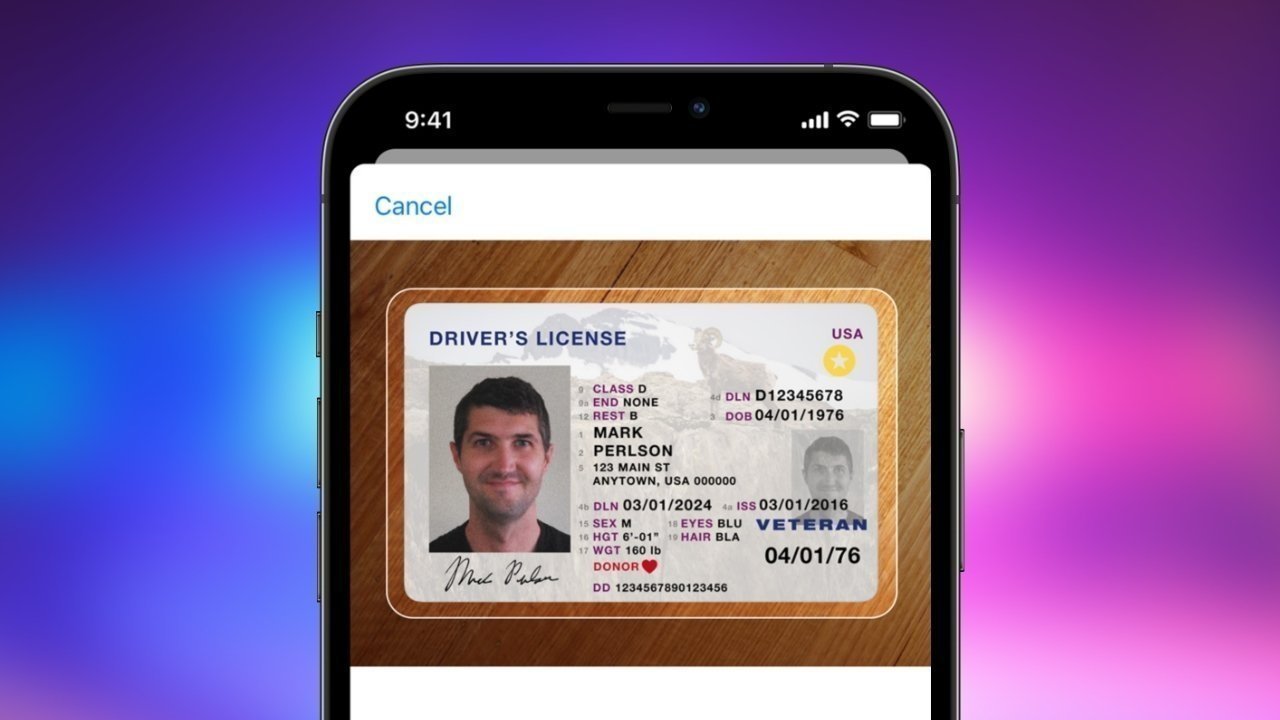
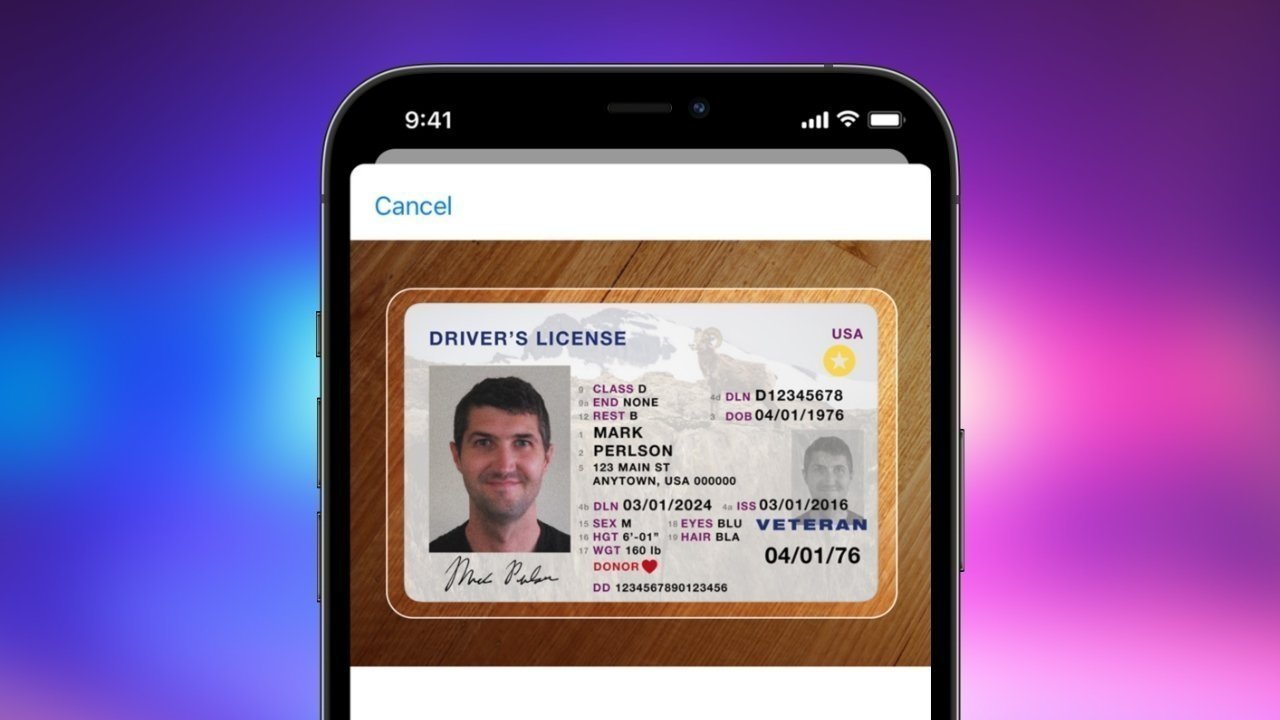
Illinois is the latest state to claim Apple Wallet users will have access to digital IDs and driver’s licenses by the end of 2025.
Illinois will implement digital IDs in the Apple Wallet app by the end of 2025.
An Illinois state law took effect on January 1, 2025 that will bring digital versions of IDs and driver’s licenses to Apple Wallet. Illinois is already working with Apple to make digital IDs a reality, according to a press release from the Illinois Secretary of State, Alexi Giannoulias, as was originally discovered by 9to5mac.
Residents will be able to access their new digital IDs via Apple Wallet on their iPhone or Apple Watch. Digital IDs will be available at no cost and will be usable alongside existing physical ID cards rather than replacing them entirely.
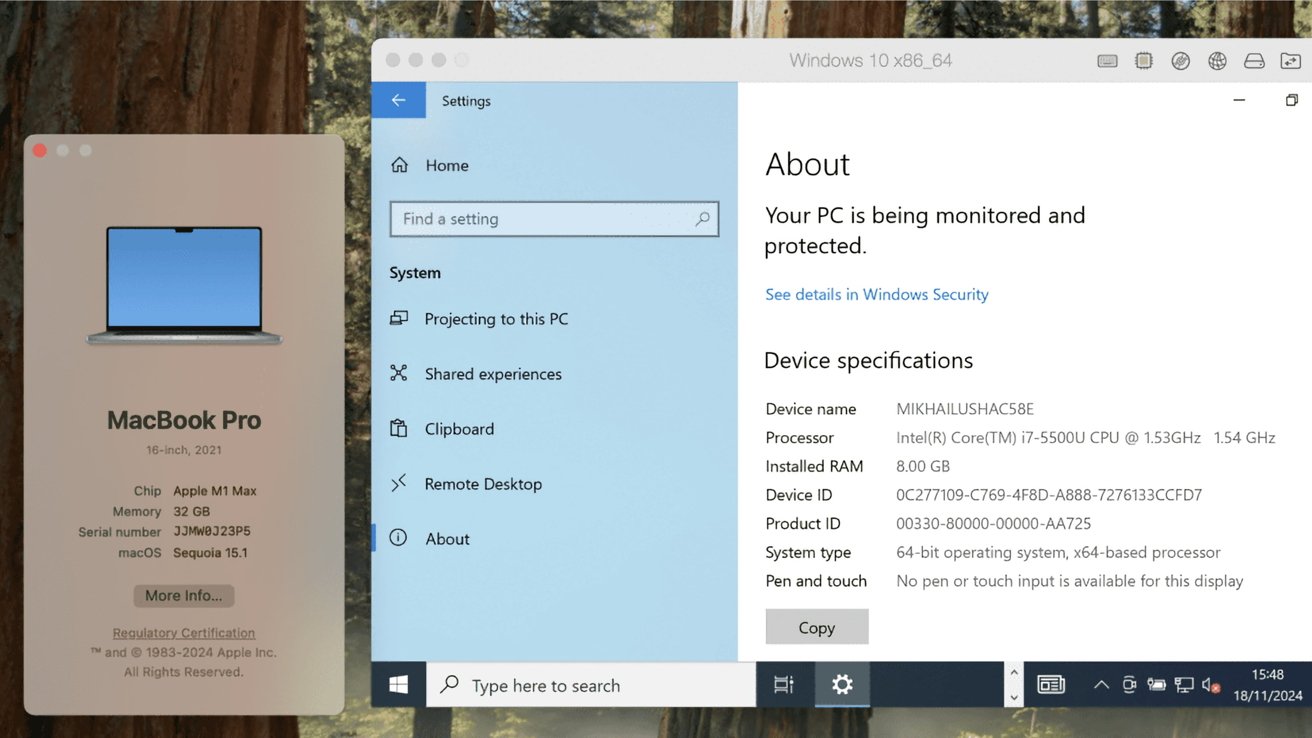
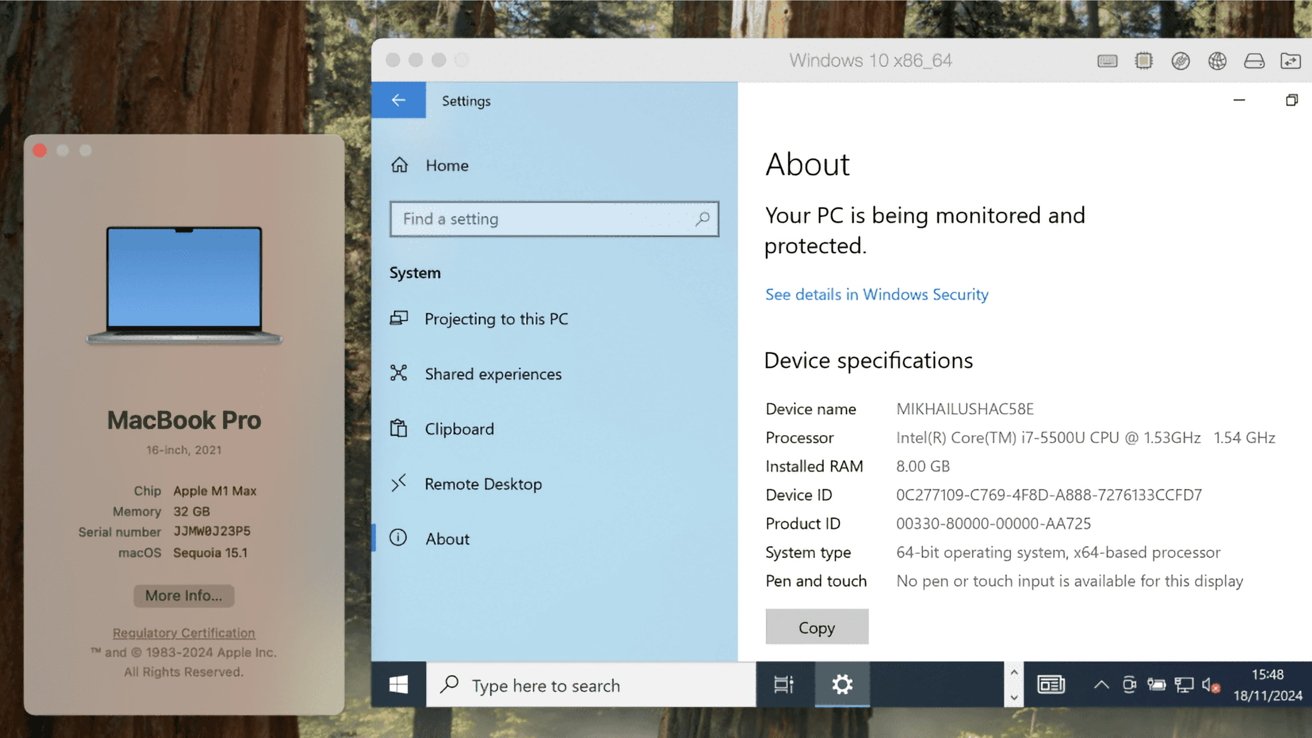
Parallels Desktop 20.2 is out now, with the latest edition including 64-bit x86 emulation for Apple Silicon and more enhancements to make Apple Intelligence Writing Tools work with Windows apps.
Using x64 emulation in Parallels to run Windows – Image Credit: Parallels
January’s update to the popular virtual machine tool Parallels Desktop brings the software up to version 20.2, just under three months after the update to version 20.1. The latest version adds a few more key changes to the virtualization tool.
The big addition is an early technology preview of x86 emulation for Apple Silicon Macs. Using a proprietary emulation engine, it allows Apple Silicon Macs to run x86_64 virtual machines, for Windows 10, Windows 11, and Linux.
New Parallels update trials x86 Linux & Windows VMs on Apple Silicon
Originally appeared here:
New Parallels update trials x86 Linux & Windows VMs on Apple Silicon
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.