Understanding the power of Lifelong Machine Learning through Q-Learning and Explanation-Based Neural Networks
How does Machine Learning progress from here? Many, if not most, of the greatest innovations in ML have been inspired by Neuroscience. The invention of neural networks and attention-based models serve as prime examples. Similarly, the next revolution in ML will take inspiration from the brain: Lifelong Machine Learning.
Modern ML still lacks humans’ ability to use past information when learning new domains. A reinforcement learning agent who has learned to walk, for example, will learn how to climb from ground zero. Yet, the agent can instead use continual learning: it can apply the knowledge gained from walking to its process of learning to climb, just like how a human would.
Inspired by this property, Lifelong Machine Learning (LLML) uses past knowledge to learn new tasks more efficiently. By approximating continual learning in ML, we can greatly increase the time efficiency of our learners.
To understand the incredible power of LLML, we can start from its origins and build up to modern LLML. In Part 1, we examine Q-Learning and Explanation-Based Neural Networks. In Part 2, we explore the Efficient Lifelong Learning Algorithm and Voyager! I encourage you to read Part 1 before Part 2, though feel free to skip to Part 2 if you prefer!
The Origins of Lifelong Machine Learning
Sebastian Thrun and Tom Mitchell, the fathers of LLML, began their LLML journey by examining reinforcement learning as applied to robots. If the reader has ever seen a visualized reinforcement learner (like this agent learning to play Pokemon), they’ll realize that to achieve any training results in a reasonable human timescale, the agent must be able to iterate through millions of actions (if not much more) over their training period. Robots, though, take multiple seconds to perform each action. As a result, moving typical online reinforcement learning methods to robots results in a significant loss of both the efficiency and capability of the final robot model.
What makes humans so good at real-world learning, where ML in robots is currently failing?
Thrun and Mitchell identified potentially the largest gap in the capabilities of modern ML: its inability to apply past information to new tasks. To solve this issue, they created the first Explanation-Based Neural Network (EBNN), which was the first use of LLML!
To understand how it works, we first can understand how typical reinforcement learning (RL) operates. In RL, our ML model decides the actions of our agent, which we can think of as the ‘body’ that interacts with whatever environment we chose. Our agent exists in environment W with state Z, and when agent takes action A, it receives sensation S (feedback from its environment, for example the position of objects or the temperature). Our environment is a mapping Z x A -> Z (for every action, the environment changes in a specified way). We want to maximize the reward function R: S -> R in our model F: S -> A (in other words we want to choose the action that reaches the best outcome, and our model takes sensation as input and outputs an action). If the agent has multiple tasks to learn, each task has its own reward function, and we want to maximize each function.
We could train each individual task independently. However, Thrun and Michael realized that each task occurs in the same environment with the same possible actions and sensations for our agent (just with different reward functions per task). Thus, they created EBNN to use information from previous problems to solve the current task (LLML)! For example, a robot can use what it’s learned from a cup-flipping task to perform a cup-moving task, since in cup-flipping it has learned how to grab the cup.
To see how EBNN works, we now need to understand the concept of the Q function.
Q* and Q-Learning
Q: S x A -> r is an evaluation function where r represents the expected future total reward after action A in state S. If our model learns an accurate Q, it can simply select the action at any given point that maximizes Q.
Now, our problem reduces to learning an accurate Q, which we call Q*. One such scheme is called Q-Learning, which some think is the inspiration behind OpenAI’s Q* (though the naming might be a complete coincidence).
In Q-learning, we define our action policy as function π which outputs an action for each state, and the value of state X as function
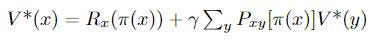
Which we can think of as the immediate reward for action π(x) plus the sum of the probabilities of all possible future actions multiplied by their values (which we compute recursively). We want to find the optimal policy (set of actions) π* such that

(at every state, the policy chooses the action that maximizes V*). As the process repeats Q will become more accurate, improving the agent’s selected actions. Now, we define Q* values as the true expected reward for performing action a:
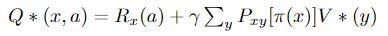
In Q-learning, we reduce the problem of learning π* to the problem of learning the Q*-values of π*. Clearly, we want to choose the actions with the greatest Q-values.
We divide training into episodes. In the nth episode, we get state x_n, select and perform action a_n, observe y_n, receive reward r_n, and adjust Q values using constant α according to:
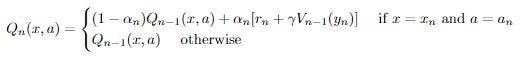
Where

Essentially, we leave all previous Q values the same except for the Q value corresponding to the previous state x and the selected action a. For that Q value, we update it by weighing the previous episode’s Q value by (1 — α) and adding to it our payoff plus the max of the previous episode’s value for the current state y, both weighted by α.
Remember that this algorithm is trying to approximate an accurate Q for each possible action in each possible state. So when we update Q, we update the value for Q corresponding to the old state and the action we took on that episode, since we
The smaller α is, the less we change Q each episode (1 – α will be very large). The larger α is, the less we care about the old value of Q (at α = 1 it is completely irrelevant) and the more we care about what we’ve discovered to be the expected value of our new state.
Let’s consider two cases to gain an intuition for this algorithm and how it updates Q(x, a) after we take action a from state x to reach state y:
- We go from state x through action a to state y, and are at an ‘end path’ where no more actions are possible. Then, Q(x, a), the expected value for this action and the state before it, should simply be the immediate reward for a (think about why!). Moreover, the higher the reward for a, the more likely we are to choose it in our next episode. Our largest Q value in the previous episode at this state is 0 since no actions are possible, so we are only adding the reward for this action to Q, as intended!
- Now, our correct Q*s recurse backward from the end! Let’s consider the action b that led from state w to state x, and let’s say we’re now 1 episode later. Now, when we update Q*(w, b), we will add the reward for b to the value for Q*(x, a), since it must be the highest Q value if we chose it before. Thus, our Q(w, b) is now correct as well (think about why)!
Great! Now that you have intuition for Q-learning, we can return to our original goal of understanding:
The Explanation Based Neural Network (EBNN)
We can see that with simple Q-learning, we have no LL property: that previous knowledge is used to learn new tasks. Thrun and Mitchell originated the Explanation Based Neural Network Learning Algorithm, which applies LL to Q-learning! We divide the algorithm into 3 steps.
(1) After performing a sequence of actions, the agent predicts the states that will follow up to a final state s_n, at which no other actions are possible. These predictions will differ from the true observed states since our predictor is currently imperfect (otherwise we’d have finished already)!
(2) The algorithm extracts partial derivatives of the Q function with respect to the observed states. By initially computing the partial derivative of the final reward with respect to the final state s_n, (by the way, we assume the agent is given the reward function R(s)), and we compute slopes backward from the final state using the already computer derivatives using chain rule:

Where M: S x A -> S is our model and R is our final reward.
(3) Now, we’ve estimated the slopes of our Q*s, and we use these in backpropagation to update our Q-values! For those that don’t know, backpropagation is the method through which neural networks learn, where they calculate how the final output of the network changes when each node in the network is changed using this same backward-calculated slope method, and then they adjust the weights and biases of these nodes in the direction that makes the network’s output more desirable (however this is defined by the cost function of the network, which serves the same purpose as our reward function)!
We can think of (1) as the Explaining step (hence the name!), where we look at past actions and try to predict what actions would arise. With (2), we then Analyze these predictions to try to understand how our reward changes with different actions. In (3), we apply this understanding to Learn how to improve our action selection through changing our Qs.
This algorithm increases our efficiency by using the difference between past actions and estimations of past actions as a boost to estimate the efficiency of a certain action path. The next question you might ask is:
How does EBNN help one task’s learning transfer to another?
When we use EBNN applied to multiple tasks, we represent information common between tasks as NN action models, which gives us a boost in learning (a productive bias) through the explanation and analysis process. It uses previously learned, task-independent knowledge when learning new tasks. Our key insight is that we have generalizable knowledge because every task shares the same agent, environment, possible actions, and possible states. The only dependent on each task is our reward function! So by starting from the explanation step with our task-specific reward function, we can use previously discovered states from old tasks as training examples and simply replace the reward function with our current task’s reward function, accelerating the learning process by many fold! The LML fathers discovered a 3 to 4-fold increase in time efficiency for a robot cup-grasping task, and this was only the beginning!
If we repeat this explanation and analysis process, we can replace some of the need for real-world exploration of the agent’s environment required by naive Q-learning! And the more we use it, the more productive it becomes, since (abstractly) there is more knowledge for it to pull from, increasing the likelihood that the knowledge is relevant to the task at hand.
Ever since the fathers of LLML sparked the idea of using task-independent information to learn new tasks, LLML has expanded past not only reinforcement learning in robots but also to the more general ML setting we know today: supervised learning. Paul Ruvolo and Eric Eatons’ Efficient Lifelong Learning Algorithm (ELLA) will get us much closer to understanding the power of LLML!
Please read Part 2: Examining LLML through ELLA and Voyager to see how it works!
Thank you for reading Part 1! Feel free to check out my website anandmaj.com which has my other writing, projects, and art, and follow me on Twitter.
Original Papers and other Sources:
Thrun and Mitchel: Lifelong Robot Learning
Watkins: Q-Learning
Chen and Liu, Lifelong Machine Learning (Inspired me to write this!): https://www.cs.uic.edu/~liub/lifelong-machine-learning-draft.pdf
Unsupervised LL with Curricula: https://par.nsf.gov/servlets/purl/10310051
Neuro-inspired AI: https://www.cell.com/neuron/pdf/S0896-6273(17)30509-3.pdf
Embodied LL: https://lis.csail.mit.edu/embodied-lifelong-learning-for-decision-making/
EfficientLLA (ELLA): https://www.seas.upenn.edu/~eeaton/papers/Ruvolo2013ELLA.pdf
LL for sentiment classification: https://arxiv.org/abs/1801.02808
Knowledge Basis Idea: https://arxiv.org/ftp/arxiv/papers/1206/1206.6417.pdf
AGI LLLM LLMs: https://towardsdatascience.com/towards-agi-llms-and-foundational-models-roles-in-the-lifelong-learning-revolution-f8e56c17fa66
DEPS: https://arxiv.org/pdf/2302.01560.pdf
Voyager: https://arxiv.org/pdf/2305.16291.pdf
Meta Reinforcement Learning Survey: https://arxiv.org/abs/2301.08028
The Origins of Lifelong ML: Part 1 of Why LLML is the Next Game-changer of AI was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
The Origins of Lifelong ML: Part 1 of Why LLML is the Next Game-changer of AI