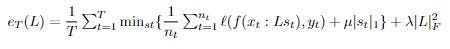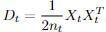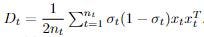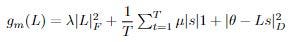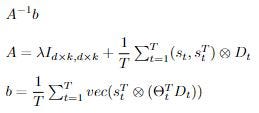With so many Fallout 4 mods available to download, it can be a little overwhelming to know where to start. Here are the best Fallout 4 mods you can check out.
Ready to battle beyond the Underworld and take on the Titan of Time in Hades 2? The game isn’t here quite yet but here’s how you could join the playtest.
The speaker on the PS5’s DualSense controller can be immersive in some cases, but if it’s becoming an annoyance for you, just turn it off using these steps.
The Xbox Series X has many new games to choose from, but internal storage may be a hassle. Here are a few compatible external hard drives to expand storage.
Nearly 11 years after it first showed off its current humanoid robot, Boston Dynamics is retiring Atlas. The DARPA-funded robot was designed with search and rescue missions in mind, with the idea that it would be able to enter areas that were unsafe for humans to carry out a range of tasks. However, Atlas became a bit of a star thanks to videos showing off its slick dance moves and impressive feats of strength, agility and balance. Fittingly, Atlas is trotting off into the sunset with one final YouTube video.
“For almost a decade, Atlas has sparked our imagination, inspired the next generations of roboticists, and leapt over technical barriers in the field,” the YouTube description reads. “Now it’s time for our hydraulic Atlas robot to kick back and relax.”
Boston Dynamics’ farewell to Atlas doesn’t just show some of the cool things the robot can do. It’s a bit of a blooper reel as well. Along with hurling a toolbag and leaping between platforms, Atlas slips, trips and falls a bunch of times in the clip — oddly enough, that makes it seem more human.
Boston Dynamics of course has more commercially successful robots in its lineup, including Spot. It’s likely not the end of the line for the company’s humanoid robots entirely, though. “Take a look back at everything we’ve accomplished with the Atlas platform to date,” reads the description on the farewell video. Those last two words suggest Boston Dynamics isn’t quite done with that side of robotics yet.
Engadget has contacted the company for details about its future humanoid robot development plans. For now, it seems Atlas could be looking for a Wednesday afternoon dance partner at a robot retirement home.
This article originally appeared on Engadget at https://www.engadget.com/boston-dynamics-sends-atlas-to-the-robot-retirement-home-184157729.html?src=rss
Whether they’re designed to be used indoors or outside, a lot of the best pizza ovens that you can currently buy can only cook a 13-inch pie. That’s great for most situations, especially if you’re keen on hosting a party where everyone can choose their toppings. However, there are times when you need more space, either for larger pizzas or to bake or roast other foods. Ooni is filling the void with its latest model, the Koda 2 Max, which is the company’s largest pizza oven so far. The 24-inch, gas-burning unit can bake pizzas up to 20 inches while still achieving the high-heat cook quality Ooni ovens are known for.
In addition to being the biggest option in Ooni’s lineup, the Koda 2 Max has several additional features that make it an upgrade over some of the company’s other models. First, it offers dual-zone cooking with independent controls for both burners. This will allow you to cook two things at different temperatures simultaneously, or to simply have a hot and cold side of the oven when needed. To facilitate this, Ooni positioned the two burners on the sides of the Koda 2 Max rather than having one at the rear of the oven. The company says its G2 gas technology includes burners with tapered flames for more efficient heat distribution and more consistent cooking stone temps.
Another update is the color digital temperature display mounted on the front. While this isn’t the first Ooni oven to show you the temp inside, it is the first to do so in color and it’s the first to send those stats to your phone. The Koda 2 Max retains the overall look of previous gas-burning Koda products, including the folding legs for transport. It will also connect to a propane tank like previous models in order to provide fuss-free cooking where you don’t have to manage a fire while you’re making pizza and other dishes.
The Ooni Koda 2 Max will be available in May for $999, making it the most expensive outdoor-only option in the company’s pizza oven range. The all-electric Volt was the same price at launch, but it currently goes for $899. If you can do without all of the fancy new features and extra cooking space, the Koda 16 ($599) and Koda 12 ($399) are hundreds of dollars cheaper, baking 16- and 12-inch pizzas as the names imply.
This article originally appeared on Engadget at https://www.engadget.com/oonis-largest-pizza-oven-yet-offers-dual-zone-heat-control-and-temperature-tracking-on-your-phone-181537924.html?src=rss
Examining Longterm Machine Learning through ELLA and Voyager: Part 2 of Why LLML is the Next Game-changer of AI
Understanding the power of Lifelong Learning through the Efficient Lifelong Learning Algorithm (ELLA) and VOYAGER
AI Robot Piloting Space Vessel, Generated with GPT-4
I encourage you to read Part 1: The Origins of LLML if you haven’t already, where we saw the use of LLML in reinforcement learning. Now that we’ve covered where LLML came from, we can apply it to other areas, specifically supervised multi-task learning, to see some of LLML’s true power.
Supervised LLML: The Efficient Lifelong Learning Algorithm
The Efficient Lifelong Learning Algorithm aims to train a model that will excel at multiple tasks at once. ELLA operates in the multi-task supervised learning setting, with multiple tasks T_1..T_n, with features X_1..X_n and y_1…y_n corresponding to each task(the dimensions of which likely vary between tasks). Our goal is to learn functions f_1,.., f_n where f_1: X_1 -> y_1. Essentially, each task has a function that takes as input the task’s corresponding features and outputs its y values.
On a high level, ELLA maintains a shared basis of ‘knowledge’ vectors for all tasks, and as new tasks are encountered, ELLA uses knowledge from the basis refined with the data from the new task. Moreover, in learning this new task, more information is added to the basis, improving learning for all future tasks!
Ruvolo and Eaton used ELLA in three settings: landmine detection, facial expression recognition, and exam score predictions! As a little taste to get you excited about ELLA’s power, it achieved up to a 1,000x more time-efficient algorithm on these datasets, sacrificing next to no performance capabilities!
Now, let’s dive into the technical details of ELLA! The first question that might arise when trying to derive such an algorithm is
How exactly do we find what information in our knowledge base is relevant to each task?
ELLA does so by modifying our f functions for each t. Instead of being a function f(x) = y, we now have f(x, θ_t) = y where θ_t is unique to task t, and can be represented by a linear combination of the knowledge base vectors. With this system, we now have all tasks mapped out in the same basis dimension, and can measure similarity using simple linear distance!
Now, how do we derive θ_t for each task?
This question is the core insight of the ELLA algorithm, so let’s take a detailed look at it. We represent knowledge basis vectors as matrix L. Given weight vectors s_t, we represent each θ_t as Ls_t, the linear combination of basis vectors.
Our goal is to minimize the loss for each task while maximizing the shared information used between tasks. We do so with the objective function e_T we are trying to minimize:
Where ℓ is our chosen loss function.
Essentially, the first clause accounts for our task-specific loss, the second tries to minimize our weight vectors and make them sparse, and our last clause tries to minimize our basis vectors.
**This equation carries two inefficiencies (see if you can figure out what)! Our first is that our equation depends on all previous training data, (specifically the inner sum), which we can imagine is incredibly cumbersome. We alleviate this first inefficiency using a Taylor sum of approximation of the equation. Our second inefficiency is that we need to recompute every s_t to evaluate one instance of L. We eliminate this inefficiency by removing our minimization over z and instead computing s when t is last interacted with. I encourage you to read the original paper for a more detailed explanation!**
Now that we have our objective function, we want to create a method to optimize it!
In training, we’re going to treat each iteration as a unit where we receive a batch of training data from a single task, then compute s_t, and finally update L. At the start of our algorithm, we set T (our number-of-tasks counter), A, b, and L to zeros. Now, for each batch of data, we case based on the data is from a seen or unseen task.
If we encounter data from a new task, we will add 1 to T, and initialize X_t and y_t for this new task, setting them equal to our current batch of X and y..
If we encounter data we’ve already seen, our process gets more complex. We again add our new X and y to add our new X and y to our current memory of X_t and y_t (by running through all data, we will have a complete set of X and y for each task!). We also incrementally update our A and b values negatively (I’ll explain this later, just remember this for now!).
Now we check if we want to end our training loop. We set our (θ_t, D_t) equal to the output of our regular learner for our batch data.
We then check to end the loop (if we have seen all training data). If we haven’t ended, we move on to computing s and updating L.
To compute s, we first compute optimal model theta_t using only the batched data, which will depend on our specific task and loss function.
We then compute D_t, and either randomly or to one of the θ_ts initialize any all-zero columns of L (which occurs if a certain basis vector is unused). In linear regression,
and in logistic regression
Then, we compute s_t using L by solving an L1-regularized regression problem:
For our final step of updating L, we take
, find where the gradient is 0, then solve for L. By doing so, we increase the sparsity of L! We then output the updated columnwise-vectorization of L as
so as not to sum over all tasks to compute A and b, we construct them incrementally as each task arrives.
Once we’ve iterated through all batch data, we’ve learned all tasks properly and have finished!
The power of ELLA lies in many of its efficiency optimizations, primarily of which is its method of using θ functions to understand exactly what basis knowledge is useful! If you care about a more in-depth understanding of ELLA, I highly encourage you to check out the pseudocode and explanation in the original paper.
Using ELLA as a base, we can imagine creating a generalizable AI, which can learn any task it’s presented with. We again have the property that the more our knowledge basis grows, the more ‘relevant information’ it contains, which will even further increase the speed of learning new tasks! It seems as if ELLA could be the core of one of the super-intelligent artificial learners of the future!
Voyager
What happens when we integrate the newest leap in AI, LLMs, with Lifelong ML? We get something that can beat Minecraft (This is the setting of the actual paper)!
Guanzhi Wang, Yuqi Xie, and others saw the new opportunity offered by the power of GPT-4, and decided to combine it with ideas from lifelong learning you’ve learned so far to create Voyager.
When it comes to learning games, typical algorithms are given predefined final goals and checkpoints for which they exist solely to pursue. In open-world games like Minecraft, however, there are many possible goals to pursue and an infinite amount of space to explore. What if our goal is to approximate human-like self-motivation combined with increased time efficiency in traditional Minecraft benchmarks, such as getting a diamond? Specifically, let’s say we want our agent to be able to decide on feasible, interesting tasks, learn and remember skills, and continue to explore and seek new goals in a ‘self-motivated’ way.
Towards these goals, Wang, Xie, and others created Voyager, which they called the first LLM-powered embodied lifelong learning agent!
How does Voyager work?
On a large-scale, Voyager uses GPT-4 as its main ‘intelligence function’ and the model itself can be separated into three parts:
Automatic curriculum: This decides which goals to pursue, and can be thought of as the model’s “motivator”. Implemented with GPT-4, they instructed it to optimize for difficult yet feasible goals and to “discover as many diverse things as possible” (read the original paper to see their exact prompts). If we pass four rounds of our iterative prompting mechanism loop without the agent’s environment changing, we simply choose a new task!
Skill library: a collection of executable actions such as craftStoneSword() or getWool() which increase in difficulty as the learner explores. This skill library is represented as a vector database, where keys are embedding vectors of GPT-3.5-generated skill descriptions, and executable skills in code form. GPT-4 generated the code for the skills, optimized for generalizability and refined by feedback from the use of the skill in the agent’s environment!
Iterative prompting mechanism: This is the element that interacts with the Minecraft environment. It first executes its’ interface of Minecraft to gain information about its current environment, for example, the items in its inventory and the surrounding creatures it can observe. It then prompts GPT-4 and performs the actions specified in the output, also offering feedback about whether the actions specified are impossible. This repeats until the current task (as decided by the automatic curriculum) is completed. At completion, we add the learned skill to the skill library. For example, if our task was create a stone sword, we now put the skill craftStoneSword() into our skill library. Finally, we ask the automatic curriculum for a new goal.
Now, where does Lifelong Learning fit into all this?
When we encounter a new task, we query our skill database to find the top 5 most relevant skills to the task at hand (for example, relevant skills for the task getDiamonds() would be craftIronPickaxe() and findCave().
Thus, we’ve used previous tasks to learn our new task more efficiently: the essence of lifelong learning! Through this method, Voyager continuously explores and grows, learning new skills that increase its frontier of possibilities, increasing the scale of ambition of its goals, thus increasing the powers of its newly learned skills, continuously!
Compared with other models like AutoGPT, ReAct, and Reflexion, Voyager discovered 3.3x as many new items as these others, navigated distances 2.3x longer, unlocked wooden level 15.3x faster per prompt iteration, and was the only one to unlock the diamond level of the tech tree! Moreover, after training, when dropped in a completely new environment with no items, Voyager consistently solved prior-unseen tasks, while others could not solve any within 50 prompts.
As a display of the importance of Lifelong Learning, without the skill library, the model’s progress in learning new tasks plateaued after 125 iterations, whereas with the skill library, it kept rising at the same high rate!
Now imagine this agent applied to the real world! Imagine a learner with infinite time and infinite motivation that could keep increasing its possibility frontier, learning faster and faster the more prior knowledge it has! I hope by now I’ve properly illustrated the power of Lifelong Machine Learning and its capability to prompt the next transformation of AI!
If you’re interested further in LLML, I encourage you to read Zhiyuan Chen and Bing Liu’s book which lays out the potential future paths LLML might take!
Thank you for making it all the way here! If you’re interested, check out my website anandmaj.com which has my other writing, projects, and art, and follow me on Twitter @almondgod.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.