With the Eras Tour still under way and The Tortured Poets Department dropping today, you can’t shake off Taylor Swift these days. She’s everywhere — in the news, on streaming services and on social media, which now includes Threads. Taylor’s Threads account, and her first post, are going live around midnight. And if you’re one of the first people to share her post, you’ll get a custom badge based on her new album’s artwork that you can display on your Threads profile.
Meta has been dropping hints and releasing easter eggs for Swifties over the past week as part of a countdown for her album release today. You may have even seen its call to pre-follow Swift on Threads, along with the shimmer effect that’s been showing up on conversations on the social network with Taylor-related hashtags. Celebratory hearts pop up when you like relevant posts, as well.
On Instagram, you’ll be able to change the background in your DMs with one that’s inspired by TPD’s artwork. The company told Engadget that the countdown on Taylor’s Instagram profile will also reset, and you can apparently expect yet another surprise in-app experience to go live at 2AM ET.
This article originally appeared on Engadget at https://www.engadget.com/surprise-taylor-swift-is-joining-threads-on-the-day-her-new-album-drops-040026147.html?src=rss
Your iPhone can play retro games originally released for the Gameboy, Nintendo 64, and more, thanks to the Delta app. Here’s how to get started.
Emulate old game consoles without needing the hardware with Delta
Delta is a spiritual successor to the GBA4iOS app that originated as a project built by then-high school student Riley Testut. Apple never allowed emulation on iOS until regulations forced its hand, so now Delta has arrived officially on the App Store.
Emulation software runs on the iPhone’s CPU to simulate a game console so it can run game ROMs. These ROMs, the Read Only Memory found in cartridges and discs, can only be legally obtained by pulling them from physical hardware.
The story of TikTok’s start highlights how visionary ideas, much like those of Steve Jobs, can have unexpected paths that profoundly impact global technology and culture.
TikTok might not have existed without Steve Jobs
A recent examination of court documents and business transactions reveals a complex web of investments and technological pivots that trace back to an obscure Chinese real estate venture.
In 2009, Susquehanna International Group, a firm well-known for its strategic market placements, invested in a promising Chinese real estate start-up named 99Fang, which boasted a sophisticated search algorithm. The venture didn’t meet its commercial expectations but set the stage for what would later become ByteDance, the parent company of TikTok.
Apple has removed Meta-owned apps WhatsApp and Threads from the China App Store after government officials claimed national security concerns.
China dictates what it allows on its country’s internet and App Store
The App Store culling continues in China after 30,000 games, then an additional 94,000 games, 44,000 apps, then 100 ChatGPT-like apps were removed over the past four years. The government in China is the driving force behind these app removals, but a more significant App Store removal took place on Thursday night.
According to a report from the Wall Street Journal, Apple was given orders by the government in China to remove WhatsApp and Threads from the App Store. China’s cyberspace officials claim the apps needed to be removed based on national security concerns.
How to constrain your model to output defined formats
In this post I will explain and demonstrate the concept of “structured generative AI”: generative AI constrained to defined formats. By the end of the post, you will understand where and when it can be used and how to implement it whether you’re crafting a transformer model from scratch or utilizing Hugging Face’s models. Additionally, we will cover an important tip for tokenization that is especially relevant for structured languages.
One of the many uses of generative AI is as a translation tool. This often involves translating between two human languages but can also include computer languages or formats. For example, your application may need to translate natural (human) language to SQL:
Natural language: “Get customer names and emails of customers from the US”
SQL: "SELECT name, email FROM customers WHERE country = 'USA'"
Or to convert text data into a JSON format:
Natural language: “I am John Doe, phone number is 555–123–4567, my friends are Anna and Sara”
Naturally, many more applications are possible, for other structured languages. The training process for such tasks involves feeding examples of natural language alongside structured formats to an encoder-decoder model. Alternatively, leveraging a pre-trained Language Model (LLM) can suffice.
While achieving 100% accuracy is unattainable, there is one class of errors that we can eliminate: syntax errors. These are violations of the format of the language, like replacing commas with dots, using table names that are not present in the SQL schema, or omitting bracket closures, which render SQL or JSON non-executable.
The fact that we’re translating into a structured language means that the list of legitimate tokens at every generation step is limited, and pre-determined. If we could insert this knowledge into the generative AI process we can avoid a wide range of incorrect results. This is the idea behind structured generative AI: constrain it to a list of legitimate tokens.
A quick reminder on how tokens are generated
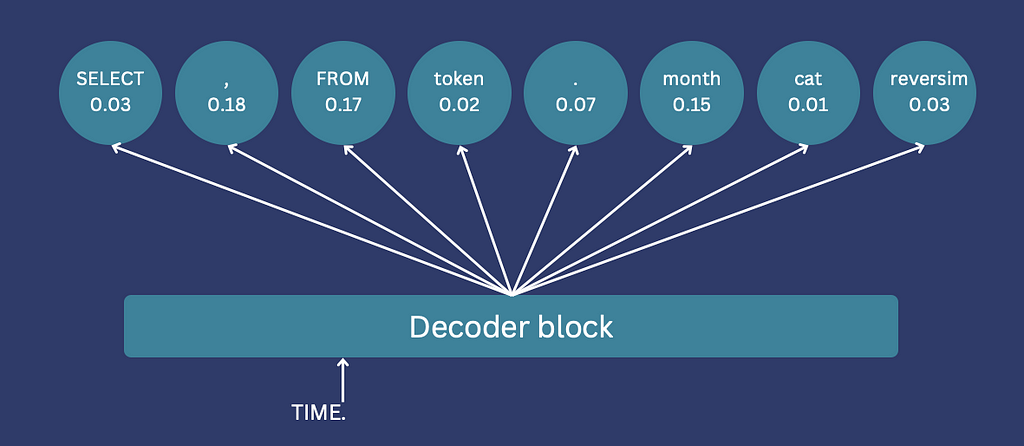
Whether employing an encoder-decoder or GPT architecture, token generation operates sequentially. Each token’s selection relies on both the input and previously generated tokens, continuing until a <end> token is generated, signifying the completion of the sequence. At each step, a classifier assigns logit values to all tokens in the vocabulary, representing the probability of each token as the next selection. The next token is sampled based on those logits.
The decoder classifier assigns a logit to every token in the vocabulary (Image by author)
Limiting token generation
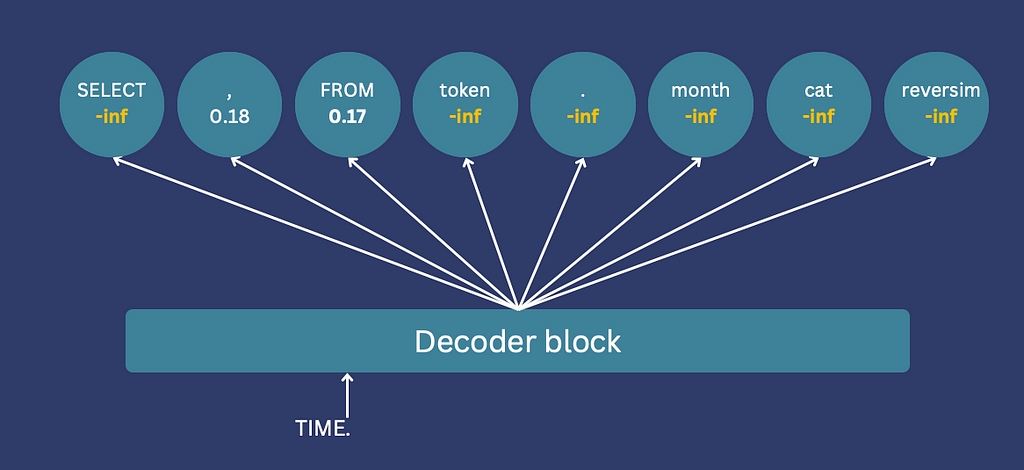
To constrain token generation, we incorporate knowledge of the output language’s structure. Illegitimate tokens have their logits set to -inf, ensuring their exclusion from selection. For instance, if only a comma or “FROM” is valid after “Select name,” all other token logits are set to -inf.
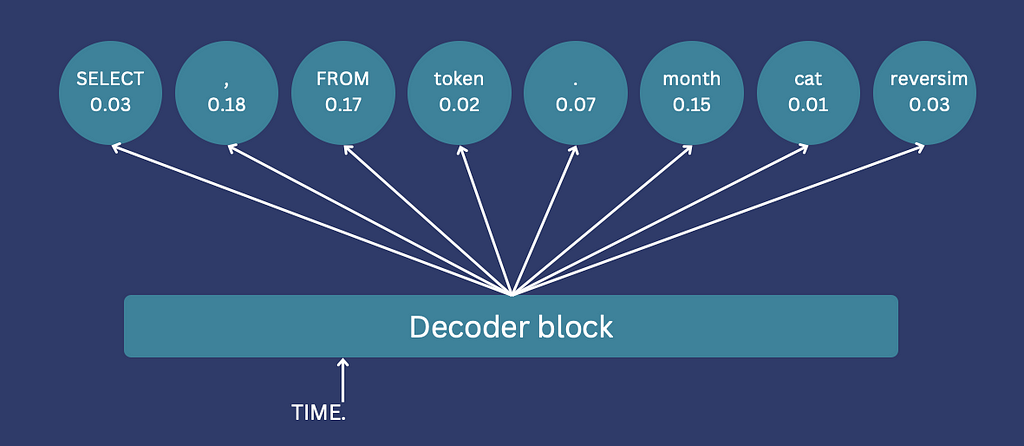
If you’re using Hugging Face, this can be implemented using a “logits processor”. To use it you need to implement a class with a __call__ method, which will be called after the logits are calculated, but before the sampling. This method receives all token logits and generated input IDs, returning modified logits for all tokens.
The logits returned from the logits processor: all illegitimate tokens get a value of -inf (Image by author)
I’ll demonstrate the code with a simplified example. First, we initialize the model, we will use Bart in this case, but this can work with any model.
from transformers import BartForConditionalGeneration, BartTokenizerFast, PreTrainedTokenizer from transformers.generation.logits_process import LogitsProcessorList, LogitsProcessor import torch
name = 'facebook/bart-large' tokenizer = BartTokenizerFast.from_pretrained(name, add_prefix_space=True) pretrained_model = BartForConditionalGeneration.from_pretrained(name)
If we want to generate a translation from the natural language to SQL, we can run:
to_translate = 'customers emails from the us' words = to_translate.split() tokenized_text = tokenizer([words], is_split_into_words=True)
out = pretrained_model.generate( torch.tensor(tokenized_text["input_ids"]), max_new_tokens=20, ) print(tokenizer.convert_tokens_to_string( tokenizer.convert_ids_to_tokens( out[0], skip_special_tokens=True)))
Returning
'More emails from the us'
Since we did not fine-tune the model for text-to-SQL tasks, the output does not resemble SQL. We will not train the model in this tutorial, but we will guide it to generate an SQL query. We will achieve this by employing a function that maps each generated token to a list of permissible next tokens. For simplicity, we’ll focus only on the immediate preceding token, but more complicated mechanisms are easy to implement. We will use a dictionary defining for each token, which tokens are allowed to follow it. E.g. The query must begin with “SELECT” or “DELETE”, and after “SELECT” only “name”, “email”, or ”id” are allowed since those are the columns in our schema.
rules = {'<s>': ['SELECT', 'DELETE'], # beginning of the generation 'SELECT': ['name', 'email', 'id'], # names of columns in our schema 'DELETE': ['name', 'email', 'id'], 'name': [',', 'FROM'], 'email': [',', 'FROM'], 'id': [',', 'FROM'], ',': ['name', 'email', 'id'], 'FROM': ['customers', 'vendors'], # names of tables in our schema 'customers': ['</s>'], 'vendors': ['</s>'], # end of the generation }
Now we need to convert these tokens to the IDs used by the model. This will happen inside a class inheriting from LogitsProcessor.
class SQLLogitsProcessor(LogitsProcessor): def __init__(self, tokenizer: PreTrainedTokenizer): self.tokenizer = tokenizer self.rules = {convert_token_to_id(k): [convert_token_to_id(v0) for v0 in v] for k,v in rules.items()}
Finally, we will implement the __call__ function, which is called after the logits are calculated. The function creates a new tensor of -infs, checks which IDs are legitimate according to the rules (the dictionary), and places their scores in the new tensor. The result is a tensor that only has valid values for the valid tokens.
class SQLLogitsProcessor(LogitsProcessor): def __init__(self, tokenizer: PreTrainedTokenizer): self.tokenizer = tokenizer self.rules = {convert_token_to_id(k): [convert_token_to_id(v0) for v0 in v] for k,v in rules.items()}
def __call__(self, input_ids: torch.LongTensor, scores: torch.LongTensor): if not (input_ids == self.tokenizer.bos_token_id).any(): # we must allow the start token to appear before we start processing return scores # create a new tensor of -inf new_scores = torch.full((1, self.tokenizer.vocab_size), float('-inf')) # ids of legitimate tokens legit_ids = self.rules[int(input_ids[0, -1])] # place their values in the new tensor new_scores[:, legit_ids] = scores[0, legit_ids] return new_scores
And that’s it! We can now run a generation with the logits-processor:
to_translate = 'customers emails from the us' words = to_translate.split() tokenized_text = tokenizer([words], is_split_into_words=True, return_offsets_mapping=True)
The outcome is a little strange, but remember: we didn’t even train the model! We only enforced token generation based on specific rules. Notably, constraining generation doesn’t interfere with training; constraints only apply during generation post-training. Thus, when appropriately implemented, these constraints can only enhance generation accuracy.
Our simplistic implementation falls short of covering all the SQL syntax. A real implementation must support more syntax, potentially considering not just the last token but several, and enable batch generation. Once these enhancements are in place, our trained model can reliably generate executable SQL queries, constrained to valid table and column names from the schema. A Similar approach can enforce constraints in generating JSON, ensuring key presence and bracket closure.
Be careful of tokenization
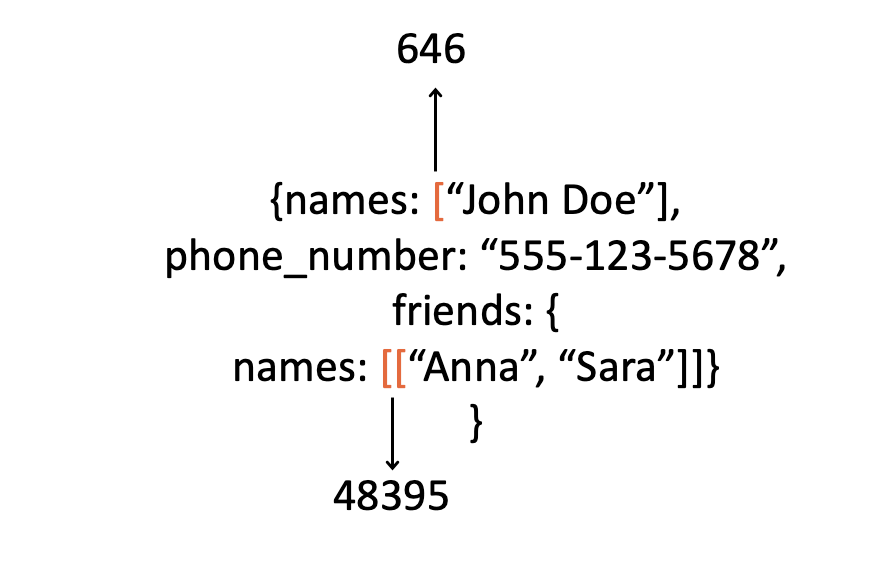
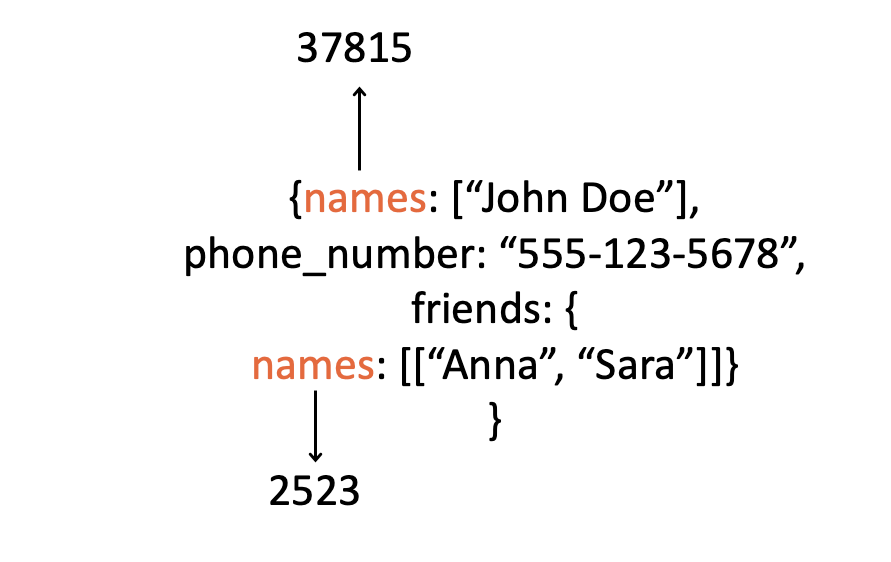
Tokenization is often overlooked but correct tokenization is crucial when using generative AI for structured output. However, under the hood, tokenization can make an impact on the training of your model. For example, you may fine-tune a model to translate text into a JSON. As part of the fine-tuning process, you provide the model with examples of text-JSON pairs, which it tokenizes. What will this tokenization look like?
(Image by author)
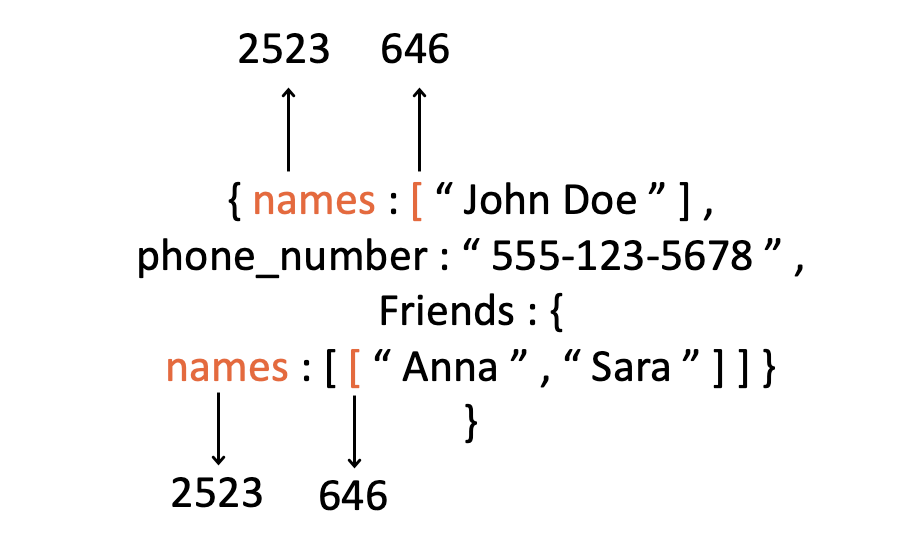
While you read “[[“ as two square brackets, the tokenizer converts them into a single ID, which will be treated as a completely distinct class from the single bracket by the token classifier. This makes the entire logic that the model must learn — more complicated (for example, remembering how many brackets to close). Similarly, adding a space before words may change their tokenization and their class ID. For instance:
(Image by author)
Again, this complicates the logic the model will have to learn since the weights connected to each of these IDs will have to be learned separately, for slightly different cases.
For simpler learning, ensure each concept and punctuation is consistently converted to the same token, by adding spaces before words and characters.
Spaced-out words lead to more consistent tokenization (Image by author)
Inputting spaced examples during fine-tuning simplifies the patterns the model has to learn, enhancing model accuracy. During prediction, the model will output the JSON with spaces, which you can then remove before parsing.
Summary
Generative AI offers a valuable approach for translating into a formatted language. By leveraging the knowledge of the output structure, we can constrain the generative process, eliminating a class of errors and ensuring the executability of queries and parse-ability of data structures.
Additionally, these formats may use punctuation and keywords to signify certain meanings. Making sure that the tokenization of these keywords is consistent can dramatically reduce the complexity of the patterns that the model has to learn, thus reducing the required size of the model and its training time, while increasing its accuracy.
Structured generative AI can effectively translate natural language into any structured format. These translations enable information extraction from text or query generation, which is a powerful tool for numerous applications.
A new app from Best Buy lets folks with a Vision Pro shop at its online store, with AR features allowing customers to see how products would look in the home.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.