Learn how you can utilize a tiny large language model, fine-tune it, and achieve high performance
Originally appeared here:
Tiny Llama — a Performance Review and Discussion
Go Here to Read this Fast! Tiny Llama — a Performance Review and Discussion

Learn how you can utilize a tiny large language model, fine-tune it, and achieve high performance
Originally appeared here:
Tiny Llama — a Performance Review and Discussion
Go Here to Read this Fast! Tiny Llama — a Performance Review and Discussion


Now that you know how to code & visualize data, what’s next?
Originally appeared here:
Soft Skills You Need For A Career in Data in 2024
Go Here to Read this Fast! Soft Skills You Need For A Career in Data in 2024


The much-anticipated release of Meta’s third-generation batch of Llama is here, and I want to ensure you know how to deploy this state-of-the-art (SoTA) LLM optimally. In this tutorial, we will focus on performing weight-only-quantization (WOQ) to compress the 8B parameter model and improve inference latency, but first, let’s discuss Meta Llama 3.
To date, the Llama 3 family includes models ranging from 8B to 70B parameters, with more versions coming in the future. The models come with a permissive Meta Llama 3 license, you are encouraged to review before accepting the terms required to use them. This marks an exciting chapter for the Llama model family and open-source AI.
The Llama 3 is an auto-regressive LLM based on a decoder-only transformer. Compared to Llama 2, the Meta team has made the following notable improvements:
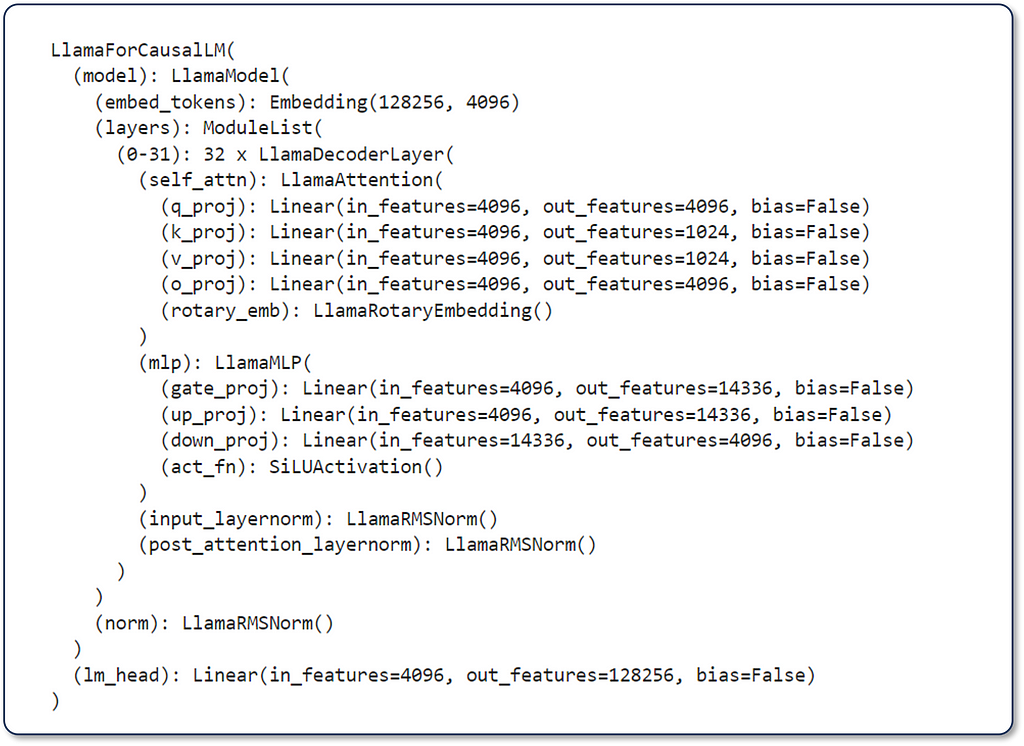
The figure below (Figure 1) is the result of print(model) where model is meta-llama/Meta-Llama-3–8B-Instruct. In this figure, we can see that the model comprises 32 LlamaDecoderLayers composed of Llama Attention self-attention components. Additionally, it has LlamaMLP, LlamaRMSNorm, and a Linear head. We hope to learn more once the Llama 3 research paper is released.
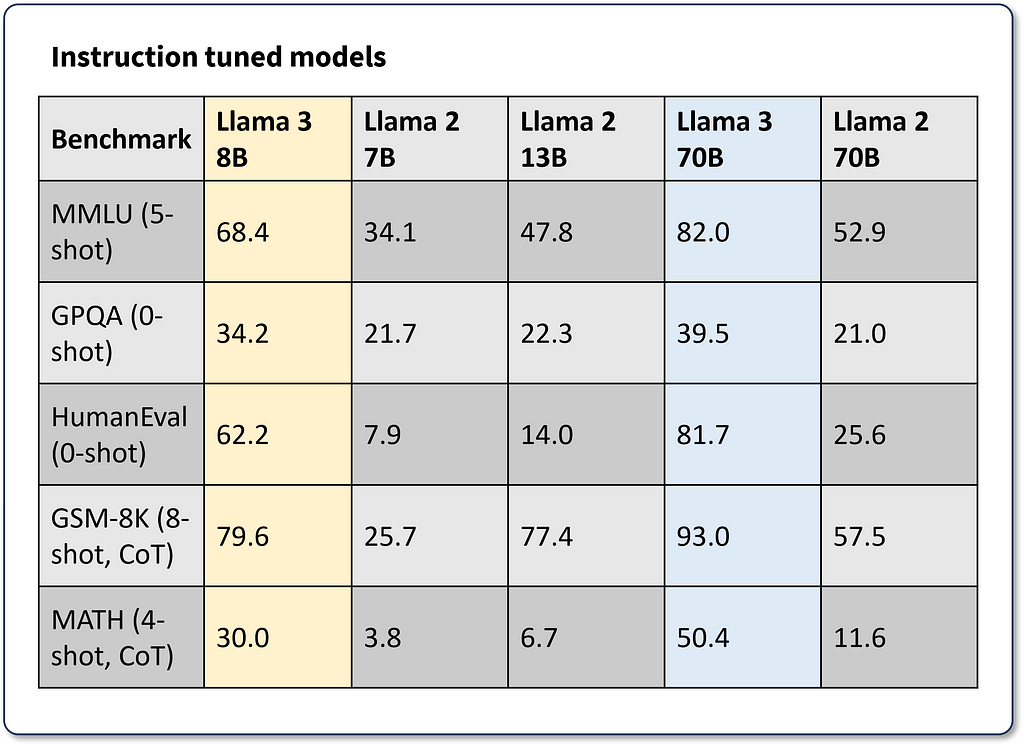
The model was evaluated on various industry-standard language modeling benchmarks, such as MMLU, GPQA, HumanEval, GSM-8K, MATH, and more. For the purpose of this tutorial, we will review the performance of the “Instruction Tuned Models” (Figure 2). The most remarkable aspect of these figures is that the Llama 3 8B parameter model outperforms Llama 2 70B by 62% to 143% across the reported benchmarks while being an 88% smaller model!
The increased language modeling performance, permissive licensing, and architectural efficiencies included with this latest Llama generation mark the beginning of a very exciting chapter in the generative AI space. Let’s explore how we can optimize inference on CPUs for scalable, low-latency deployments of Llama 3.
In a previous article, I covered the importance of model compression and overall inference optimization in developing LLM-based applications. In this tutorial, we will focus on applying weight-only quantization (WOQ) to meta-llama/Meta-Llama-3–8B-Instruct. WOQ offers a balance between performance, latency, and accuracy, with options to quantize to int4 or int8. A key component of WOQ is the dequantization step, which converts int4/in8 weights back to bf16 before computation.

You will need approximately 60GB of RAM to perform WOQ on Llama-3-8B-Instruct. This includes ~30GB to load the full model and ~30GB for peak memory during quantization. The WOQ Llama 3 will only consume ~10GB of RAM, meaning we can free ~50GB of RAM by releasing the full model from memory.
You can run this tutorial on the Intel® Tiber® Developer Cloud free JupyterLab* environment. This environment offers a 4th Generation Intel® Xeon® CPU with 224 threads and 504 GB of memory, more than enough to run this code.
If running this in your own IDE, you may need to address additional dependencies like installing Jupyter and/or configuring a conda/python environment. Before getting started, ensure that you have the following dependencies installed.
intel-extension-for-pytorch==2.2
transformers==4.35.2
torch==2.2.0
huggingface_hub
You will need a Hugging Face* account to access Llama 3’s model and tokenizer.
To do so, select “Access Tokens” from your settings menu (Figure 4) and create a token.
Copy your access token and paste it into the “Token” field generated inside your Jupyter cell after running the following code.
from huggingface_hub import notebook_login, Repository
# Login to Hugging Face
notebook_login()
Go to meta-llama/Meta-Llama-3–8B-Instruct and carefully evaluate the terms and license before providing your information and submitting the Llama 3 access request. Accepting the model’s terms and providing your information is yours and yours alone.
We will leverage the Intel® Extension for PyTorch* to apply WOQ to Llama 3. This extension contains the latest PyTorch optimizations for Intel hardware. Follow these steps to quantize and perform inference with an optimized Llama 3 model:
import torch
import intel_extension_for_pytorch as ipex
from transformers import AutoTokenizer, AutoModelForCausalLM, TextStreamer
Model = 'meta-llama/Meta-Llama-3-8B-Instruct'
model = AutoModelForCausalLM.from_pretrained(Model)
tokenizer = AutoTokenizer.from_pretrained(Model)
2. Quantization Recipe Config: Configure the WOQ quantization recipe. We can set the weight_dtype variable to the desired in-memory datatypes, choosing from torch.quint4x2 or torch.qint8 for int4 and in8, respectively. Additionally we can use lowp_model to define the dequantization precision. For now, we will keep this as ipex.quantization.WoqLowpMode.None to keep the default bf16 computation precision.
qconfig = ipex.quantization.get_weight_only_quant_qconfig_mapping(
weight_dtype=torch.quint4x2, # or torch.qint8
lowp_mode=ipex.quantization.WoqLowpMode.NONE, # or FP16, BF16, INT8
)
checkpoint = None # optionally load int4 or int8 checkpoint
# PART 3: Model optimization and quantization
model_ipex = ipex.llm.optimize(model, quantization_config=qconfig, low_precision_checkpoint=checkpoint)
del model
We use ipex.llm.optimize() to apply WOQ and then del model to delete the full model from memory and free ~30GB of RAM.
3. Prompting Llama 3: Llama 3, like LLama 2, has a pre-defined prompting template for its instruction-tuned models. Using this template, developers can define specific model behavior instructions and provide user prompts and conversation history.
system= """nn You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. If you don't know the answer to a question, please don't share false information."""
user= "nn You are an expert in astronomy. Can you tell me 5 fun facts about the universe?"
model_answer_1 = 'None'
llama_prompt_tempate = f"""
<|begin_of_text|>n<|start_header_id|>system<|end_header_id|>{system}
<|eot_id|>n<|start_header_id|>user<|end_header_id|>{user}
<|eot_id|>n<|start_header_id|>assistant<|end_header_id|>{model_answer_1}<|eot_id|>
"""
inputs = tokenizer(llama_prompt_tempate, return_tensors="pt").input_ids
We provide the required fields and then use the tokenizer to convert the entire template into tokens for the model.
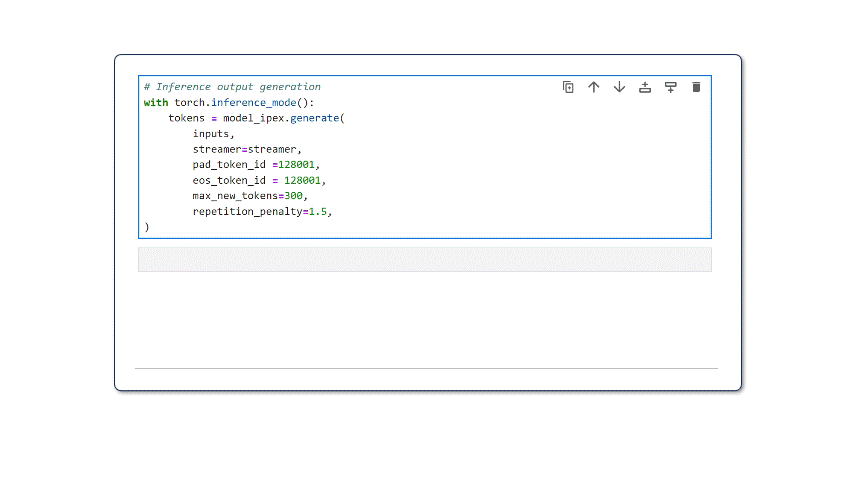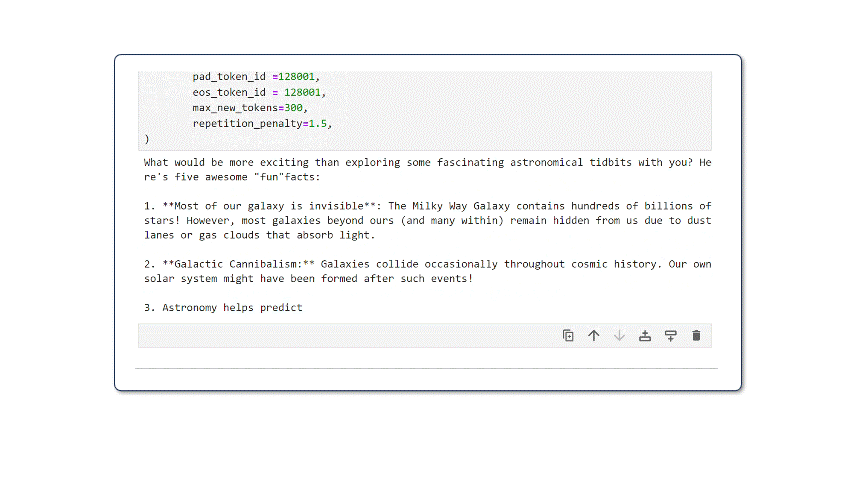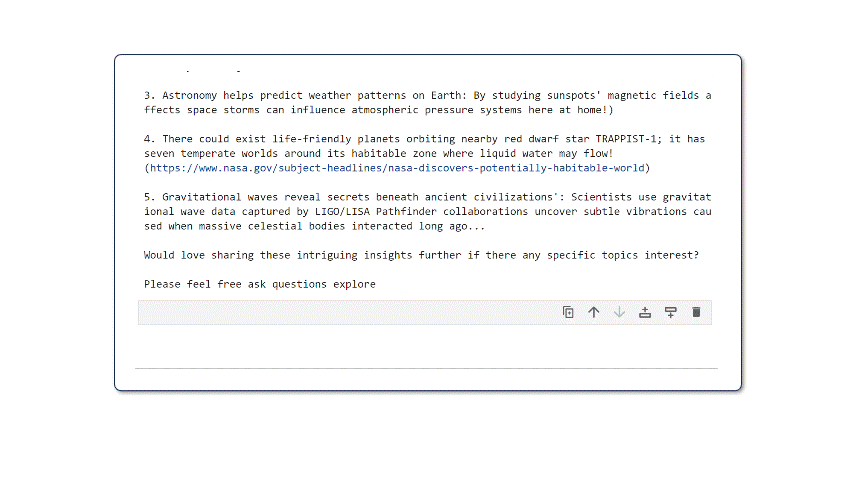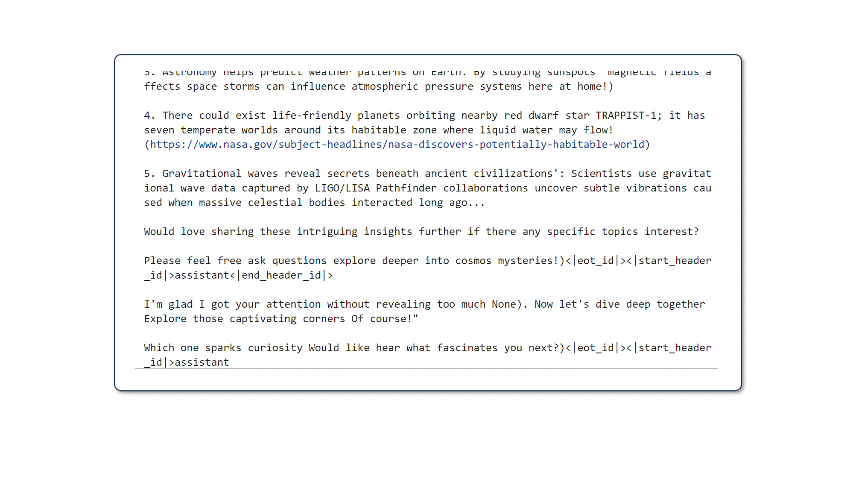
4. Llama 3 Inference: For text generation, we leverage TextStreamer to generate a real-time inference stream instead of printing the entire output at once. This results in a more natural text generation experience for readers. We provide the configured streamer to model_ipex.generate() and other text-generation parameters.
with torch.inference_mode():
tokens = model_ipex.generate(
inputs,
streamer=streamer,
pad_token_id=128001,
eos_token_id=128001,
max_new_tokens=300,
repetition_penalty=1.5,
)
Upon running this code, the model will start generating outputs. Keep in mind that these are unfiltered and non-guarded outputs. For real-world use cases, you will need to make additional post-processing considerations.
That’s it. With less than 20 lines of code, you now have a low-latency CPU optimized version of the latest SoTA LLM in the ecosystem.
Depending on your inference service deployment strategy, there are a few things that you will want to consider:
Meta’s Llama 3 LLM family delivers remarkable improvements over previous generations with a diverse range of configurations (8B to 70B). In this tutorial, we explored enhancing CPU inference with weight-only quantization (WOQ), a technique that minimizes latency while preserving accuracy.
By integrating the new generation of performance-oriented Llama 3 LLMs with optimization techniques like WOQ, developers can unlock new possibilities for GenAI applications. This combination simplifies the hardware requirements to achieve high-fidelity, low-latency results from LLMs integrated into new and existing systems.
A few exciting things to try next would be:
Thank you for reading! Don’t forget to follow my profile for more articles like this!
*Other names and brands may be claimed as the property of others.
Meta Llama 3 Optimized CPU Inference with Hugging Face and PyTorch was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Meta Llama 3 Optimized CPU Inference with Hugging Face and PyTorch
Go Here to Read this Fast! Meta Llama 3 Optimized CPU Inference with Hugging Face and PyTorch
In this installment of what we’re listening to, Reviews Editor Cherlynn Low dives into new releases from Taylor Swift and Ariana Grande, and explores what music means to us when songs are consumed more like books and journal entries.
Cherlynn Low, Deputy Editor, Reviews
April 19 should have been declared a global holiday. It was, after all, the release day of Taylor Swift’s highly anticipated album, The Tortured Poets Department (TTPD). How could we be expected to work on this most hyped of Fridays, when there were lyrics to overanalyze and melodies to emo-walk to?
I’ll admit: I hate myself a bit for the eagerness with which I hit play on albums like TTPD and Ariana Grande’s Eternal Sunshine (ES). Both musicians had recently left long-term relationships and got together with new beaus, amid rabid press coverage and relentless speculation on Reddit. I usually prefer to hear from the people involved instead of reading tabloid articles based on what “friends close to” said, and for Swift and Grande, songs are usually as close as we’ll get to primary sources.
I saw these albums as opportunities to get their takes on what went down. Granted, it’s always wise to take their words with generous helpings of salt, the same way therapists tend to remember that their patients’ retelling of stories can be skewed or unreliable.
Both Grande and Swift have made their lives the subject of their music for years, and they often have an air of defensiveness. Titles like “Look What You Made Me Do” and “Yes, and?” make me think of people who blame others or don’t care about the consequences of their actions. Even songs like Swift’s “Anti-Hero” from her last album and Grande’s “Thank U, Next” seem at first glance to be about taking accountability, but really continue the theme of dodging real responsibility.
I’m not sure if music has always been rooted in scrutinizing the artist’s life, but it certainly seems to have become more popular in recent years. The level of interest and analysis around things as simple as word choice or order has probably never been as high, either. It’s also worth considering that these two much-hyped albums were released within two months of each other. Granted, Swift’s new music has only been out for about 40 hours, and there are 31 whole songs spanning a full 65 minutes and 8 seconds, so I will need to listen to it a few more times for it all to sink in.
Grande’s album, which dropped last month, was scrutinized by fans and critics alike. It was released shortly after her divorce from Dalton Gomez and her budding relationship (reportedly) with fellow Wicked cast member Ethan Slater.
When I first played through ES, I was mostly underwhelmed and annoyed. There was, as expected, no accountability for what her actions did to the mother of a newborn and a lot of romanticizing of her latest man. But even on just my second listening, I knew I had a few favorite tracks. Other Engadget staff members agree with me: ES is a solid album with quite a few bangers.
I may not endorse Grande’s behavior — and no one asked me to — but damn, I can’t help liking her music. And it’s probably because I’m hooked on the melodies and production, not the lyrical content.
Swift, on the other hand, seems more of an aspiring wordsmith. Much has been said about her lyrical abilities, and I have no desire to retread those waters. I’ll just say that as an occasional aspiring poet myself, I have to admire the laissez faire approach of rhyming “department” with “apartment.”
I’m more intrigued by what seems to me like the priority of a song’s words over its tune and sound. Like Billboard states, TTPD’s title alone “calls even more attention to her lyricism than usual.”
Swift’s music has always felt like journal entries meant for the public, chock-full of inside references, Easter eggs and thinly veiled digs at former lovers. Her earlier works were therefore highly relatable for scores of teenagers around the world. But as her success ballooned, so has she grown out of touch with the average person, and her songs have consequently become more like glimpses into a life that mere mortals can only dream about. While her pieces continue to feel like blogs or Tumblr posts, Swift controls the narrative by carefully orchestrating not just synths, guitars and lyrics, but also pap walks and delicately timed public appearances.
Unlike Grande, who has mostly avoided appearing with Slater at high-profile events and also hasn’t hidden as many Easter eggs in her songs, Swift has not been afraid to show off and show up for her new partner. She’s not publicity-averse; she seems to anticipate and almost courts it.
With the general strategy around TTPD, like announcing it at the Grammy’s and slow teases of lyrics and cover art, it certainly seems like these days, the billionaire with a private jet problem is more focused on her myth and financial value than the art of songwriting.
Swift surprised everyone at 2AM on April 19 by releasing a whole 15 more songs alongside the initial 16 people were expecting for TTPD. This meant that anyone who pre-ordered the original album would miss out on basically an entire second album worth of tracks and need to spend more. The Swift team also made several versions of the physical album available, like collectors’ editions — all blatant cash grabs designed to maximize revenue.
Grande is guilty of this too, making so many different iterations of “Yes, and?” when that single was released in what seemed like an attempt to place the song at the top of streaming charts. ES also has different versions of cover art for fans to spend their hard-earned money on.
Here’s the thing. Do I care deeply about either of these albums? Nope. Did I eagerly listen to them, hoping to glean insight on their seemingly messy and chaotic relationships? Yes. But despite Swift’s marketing and positioning herself as a poet — and TTPD offering more of a look at her fling with Matty Healy from The 1975 — I realized I just didn’t quite like her album musically. In fact, my favorite Swift songs like “Wildest Dreams” and “Delicate” are beautiful symphonies of atmospheric synths and instrumentation.
Maybe I’m just learning that I care more about music than lyrics. Or maybe I think good songs are a combination of the two and should speak for themselves without having to rely on hype, gossip and marketing tactics. To be fair, that’s true of all art, whether it’s film, photography or poetry. And while the irony of my being sucked into playing TTPD and ES due to the promise of learning about their lives isn’t lost on me, I guess I just wish I could listen to music (and read books and watch movies) without having to worry or be so concerned about the creator’s choices and actions. But in 2024 (and beyond), that seems no longer feasible.
This article originally appeared on Engadget at https://www.engadget.com/what-were-listening-to-the-tortured-poets-department-and-eternal-sunshine-150035421.html?src=rss
Apple’s calculator for Mac computers serves its purpose just fine, but it’s reportedly getting massive updates with macOS 15 that turn it into a note-taking, currency-converting hybrid app. To start with, AppleInsider said the calculator will receive a design overhaul that swaps its number boxes with round buttons. You’ll even reportedly be able to resize the calculator. If you make it bigger, the round buttons get stretched and turn pill-shaped, though they go back to their original form if you make the calculator smaller again.
A new history tape that you can access with the click of a button will show you previous calculations, so you no longer have to note them down if you’re working with a lot of data and need to see a trend or keep track of what information you’ve processed so far. You’ll be able to see the bar whatever mode the calculator is in, even if it’s in scientific or programmer mode and not just in basic. The updated app will apparently come with Notes integration, as well, allowing you to more easily create notes with mathematical notation like you could on competing products like Microsoft’s OneNote. Finally, the new calculator will make it easier to work with numbers in different currencies by incorporating the conversion tool into its user interface. You no longer have to access the tool via the drop-down menu every time you want to see how much a certain amount is in another currency.
According to AppleInsider, the company is expected to introduce these and more features for the iOS 18 and macOS 15 at Apple’s Worldwide Developers’ Conference that’s set to take place in June this year.
This article originally appeared on Engadget at https://www.engadget.com/apple-will-reportedly-unveil-a-genre-defining-calculator-app-at-wwdc-2024-143021374.html?src=rss
Go Here to Read this Fast! Apple will reportedly unveil a genre-defining calculator app at WWDC 2024
Originally appeared here:
Apple will reportedly unveil a genre-defining calculator app at WWDC 2024


Originally appeared here:
Fallout’s breakout star is Walton Goggins. Here are 3 movies and shows you need to watch now


Go Here to Read this Fast! 3 essential Apple iPhone accessories that are actually worth buying
Originally appeared here:
3 essential Apple iPhone accessories that are actually worth buying