Tales of Kenzera: Zau’s linear 2D exploration is lacking, but its emotional story about grief makes up for those shortcomings.
Originally appeared here:
Tales of Kenzera: Zau review: emotional Metroidvania is a spiritual journey
Originally appeared here:
Tales of Kenzera: Zau review: emotional Metroidvania is a spiritual journey
Go Here to Read this Fast! This LG TV has a bendable OLED screen (really) and it’s $999 off
Originally appeared here:
This LG TV has a bendable OLED screen (really) and it’s $999 off
Anker’s Soundcore Space A40 is the top recommendation in our guide to the best budget wireless earbuds, as it offers enjoyable sound and a meaty set of features for well under $100. If you’re looking to buy a set on the cheap, take note: A new sale on Amazon has dropped the earbuds down to $49, which matches the lowest price we’ve seen. The earbuds technically have a list price of $100, but they’ve sold for $59 for most of 2024, so you’re saving about $10 here. We last saw this discount about a month ago.
In an amusing bug, Amazon’s product page currently lists the earbuds as a “Gildan Unisex-adult Fleece Hoodie Sweatshirt.” Why? We have no idea. The correct name appears when you add the pair to your cart, however, so this shouldn’t be any cause for alarm. (Unless you really want a new hoodie.) The deal itself is sold by Anker directly and applies to the black model; the blue and white versions are also on sale for $1 more.
We recommend the Space A40 because it has the kind of feature set we expect from much more expensive earbuds. Its adaptive active noise cancellation (ANC) isn’t quite on par with the absolute best from Sony or Bose — particularly when it comes to voices and higher-pitched sounds — but it’s still superb for $50, and more than capable of muting the hum of an office or daily commute. The earpieces are small, comfortable and IPX4-rated, so they should hold up for all but the sweatiest gym-goers. Battery life comes in around eight hours per charge, with another 40 or so available through its case, which is easy to pocket and supports wireless charging. The pair can connect to two devices simultaneously, and there’s a usable (if not superlative) transparency mode for letting in outside noise.
The Space A40 has a warm sound profile out of the box, with a noticeable but not overwhelming boost in the upper-bass region. The highs are a bit underemphasized, so some tracks won’t sound as crisply detailed as they might on more expensive pairs. But it should be pleasant for most, and Anker’s companion app includes an EQ for tweaking the sound if needed. The main downsides here are the mediocre mic, which isn’t the clearest for phone calls, and the lack of in-ear detection, which means the earbuds won’t automatically pause when you take them out of your ears.
If all of this sounds appealing but you’d prefer an AirPods-style shape with easy-to-grab “stems,” Anker’s Soundcore Liberty 4 NC is the runner up in our guide, and it’s also on sale for $74.50. That’s about $5 more than the pair’s all-time low but $25 less than its usual going rate. This model sounds more bass-heavy by default, but it has just about all the same features, with slightly more extensive touch controls.
Follow @EngadgetDeals on Twitter and subscribe to the Engadget Deals newsletter for the latest tech deals and buying advice.
This article originally appeared on Engadget at https://www.engadget.com/ankers-soundcore-space-a40-wireless-earbuds-are-back-down-to-49-right-now-150758191.html?src=rss
Grindr has been sued for allegedly sharing personal information with advertising companies without users’ consent. A lawsuit filed in London claims that the data included HIV statuses and test dates, ethnicity and sexual orientation, Bloomberg reports.
According to the class action-style suit, the alleged data sharing involved adtech companies Localytics and Apptimize. Grindr is said to have supplied the companies with user info before April 2018 and then between May 2018 and April 2020. Engadget has asked Grindr for comment.
In April 2018, Grindr admitted it had shared HIV data with Apptimize and Localytics following an investigation by BuzzFeed News and Norwegian non-profit SINTEF. It said it would stop the practice.
This isn’t the only time Grindr has been accused of sharing users’ personal information. A 2022 report from The Wall Street Journal indicated that precise location data on Grindr users was up for sale for at least three years. In addition, Norway’s data protection agency fined Grindr $6 million in 2021 for violating the European Union’s General Data Protection Regulation. The agency said Grindr had unlawfully shared “personal data with third parties for marketing purposes.”
This article originally appeared on Engadget at https://www.engadget.com/grindr-sued-for-allegedly-sharing-users-hiv-status-and-other-info-with-ad-companies-141748725.html?src=rss

It’s no secret that much of the success of LLMs still depends on our ability to prompt them with the right instructions and examples. As newer generation LLMs become more and more powerful, prompts have become complex enough to be considered programs themselves. These prompt programs are a lot like recipes — both have a set of instructions to follow and transform raw materials, be it data or ingredients.
Prompt engineering is thus similar to improving a recipe. Home chefs will often stick to the overall recipe but make some small changes — for example leaving out garlic or adding parsley in a pasta dish. Frameworks like DSPy are following this overall paradigm when they optimize the in-context examples. Pro-level chefs, however, use the recipe as inspiration, and often re-interpret components of the dish completely. For example, they might see spaghetti in pasta dish as the starchy component and might swap it for freshly made gnocchi to achieve a similar composition.
What is it that allows pro-level chefs to work so creatively? It’s that they think about recipes in an abstract way, like in the pasta example above. Manual prompt engineering is similar to pro-level cooking. It can get impressive results but requires a lot of time and knowledge. What we really want is the creativity of manual prompt engineering but without the effort.
Let’s say we want to improve a prompt for labeling speaker responses. We’ll eventually run it with many different inputs, but plug in a concrete one for now:
Instructions: Does Speaker 2's answer mean yes or no?
Output labels: no, yes
Input: Speaker 1: "You do this often?" Speaker 2: "It's my first time."
Output:
Assume, for a moment, that we had an abstract representation of this prompt that pulls out its separate components and is easy to manipulate. Maybe something like this:

With this, you could automate a lot of the (semi)-manual tinkering you have to do during prompt prototyping. Making small edits such as paraphrasing would be just the start. Want to try out Chain-of-Thought reasoning? Add a paragraph that says “Let’s think step-by-step.” How about changing the data formatting to JSON? Simply change the formatattribute of the InputData parameters. You can also explore
Essentially, plug in your favorite prompt engineering heuristic. This abstract representation of prompts allows us to truly get creative and automatically explore a large space of possible prompts. But how can we represent prompts as abstract and modifiable programs in Python? Read on.
“Any problem in computer science can be solved by another layer of indirection.”
To represent abstract prompts, let’s first convert it into a non-symbolic prompt program by breaking them into individual components, implemented as Python classes:
class Component:
def __init__(self, **kwargs): pass
class Metaprompt(Component): pass
class Paragraph(Component): pass
class InputData(Component): pass
prompt = Metaprompt(
children=[
Paragraph(text="Instructions: "),
Paragraph(
id="instructions",
text="Does Speaker 2's answer mean yes or no?",
),
Paragraph(id="labels", text="Output labels: yes, no"),
InputData(),
Paragraph(text="Output: "),
]
)
So far, so good. It’s similar to what DSpy does, albeit more general as we also represent the internal structure of a prompt.
Next, we turn it into a symbolic prompt program so that we can make arbitrary changes (this is also beyond static DSPy programs). This can be done with pyGlove, a library for symbolic object-oriented programming (SOOP). pyGlove turns Python classes into manipulable, symbolic objects whose properties remain fully editable after instantiation.
With pyGlove, all we need to do is add the pg.symbolize decorator:
import pyglove as pg
@pg.symbolize
class Component:
def __init__(self, **kwargs): pass
We can now query and modify prompt programs via a whole host of specifiers, similar to working with a DOM tree. Let’s say we’d like to transform our program above into the following:
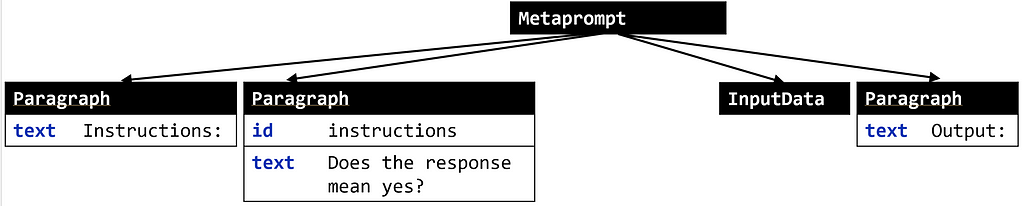
Note that we’re now asking “Does the response mean yes?” and not providing output labels of yes and no. To get there, we need to (i) change the instruction text and (ii) delete the third node. With pyGlove, this is very easy:
prompt.rebind({'children[1].text': 'Does the response mean yes?'})
prompt.rebind({'children[2]': pg.MISSING_VALUE})
print(prompt)
The printout confirms that we’re successful:
Metaprompt(
children = [
0 : Paragraph(
text = 'Instructions: '
),
1 : Paragraph(
id = 'instructions',
text = 'Does the response mean yes?'
),
2 : InputData(),
3 : Paragraph(
text = 'Output: '
)
]
)
Voilà! Essentially, pyGlove gives us a way to work with Python classes (and functions) as if they were still source code with little overhead. Now that we have flexible and easily manipulable representations, let’s put them to use.
Wait a minute. We might have a way to represent and modify prompts now, but we’re still missing a process to optimize them automatically.
Once chefs understand the abstraction and components of a recipe, they’ll try out many variants, refining the taste, cost, or presentation, until it feels right. To do the same with prompt abstractions, we need a search algorithm, an objective as well as set of labeled samples to know that we’re making progress.
Sounds like a lot to implement yourself? Meet SAMMO, a Python library for building and optimizing symbolic prompt programs.
To illustrate SAMMO’s core workflow, we’ll now show how to tune the instructions part of our prompt example from above. Once we’ve worked through this toy example, we’ll be ready to discuss more advanced applications, like RAG optimization or compression.
The key steps are
We’ve pretty much already done this above. SAMMO expects a function, so we’ll have to wrap it in one. If you’d like to store extra information, wrap it in a Callable instead. We’ll also wrap it in an Output component to run it.
def starting_prompt():
instructions = MetaPrompt(
Paragraph(text="Instructions: "),
Paragraph(
id="instructions",
text="Does Speaker 2's answer mean yes or no?",
),
Paragraph(id="labels", text="Output labels: yes, no"),
InputData(),
Paragraph(text="Output: "),
)
return Output(instructions.with_extractor())
SAMMO uses a simple data structure called DataTable to pair inputs with outputs (labels). This will help us with evaluation and bookkeeping.
mydata = DataTable.from_records(
records, # list of {"input": <>, "output": <>}
constants={"instructions": default_instructions},
)
We’re interested in optimizing the accuracy, so that’s what we’re implementing below:
def accuracy(y_true: DataTable, y_pred: DataTable) -> EvaluationScore:
y_true = y_true.outputs.normalized_values()
y_pred = y_pred.outputs.normalized_values()
n_correct = sum([y_p == y_t for y_p, y_t in zip(y_pred, y_true)])
return EvaluationScore(n_correct / len(y_true))
Here is where you can be as creative as you’d like. You can implement your own operators that generate new prompt variants, or simply rely on the pre-built mutation operators that SAMMO offers.
Below, we do the latter and go for a mix of paraphrasing and inducing instructions from a few labeled examples, essentially implementing Automatic Prompt Engineering (APE).
mutation_operators = BagOfMutators(
starting_prompt=StartingPrompt(d_train),
InduceInstructions({"id": "instructions"}, d_train),
Paraphrase({"id": "instructions"}),
)
runner = OpenAIChat(
model_id="gpt-3.5-turbo-16k",
api_config={"api_key": YOUR_KEY},
cache="cache.tsv",
)
prompt_optimizer = BeamSearch(runner, mutation_operators, accuracy, depth=6)
transformed = prompt_optimizer.fit_transform(d_train)
The introductory example prompt was actually taken from the BigBench implicatures task which we’ll use to run this experiment. If you run the optimization with 100 samples for training and testing and a budget of 48 candidates evaluations, you’ll see that SAMMO improves the starting prompt accuracy from 0.56 to 0.77 — a 37.5% improvement. What instructions worked best?
...
Paragraph(
"Consider the dialogue, context, and background "
"information provided to determine the most suitable output label",
id="instructions",
)
...
Interestingly, different LLMs prefer quite different instructions. GPT-3.5 liked generic instructions the best as seen above. Llama-2’s best prompt selected by SAMMO with the same training and budget setup used an empty string in the instructions part:
...
Paragraph(
"",
id="instructions",
)
...
We’ll now show how to convert a RAG pipeline into a symbolic program and tune it with SAMMO. We’ll use semantic parsing as our application task where we want to translate user queries into domain-specific language (DSL) constructs, for example, to query some database or call an external API.
To create the starting prompt, we include a list of all operators, use an embedding-based retriever to get five fewshot examples and then instruct the LLM to output its answer in the same format as the examples.
class RagStartingPrompt:
def __init__(self, dtrain, examples, embedding_runner):
self._examples = examples
self._dtrain = dtrain
self._embedding_runner = embedding_runner
def __call__(self, return_raw=False):
structure = [
Section("Syntax", self._dtrain.constants["list_of_operators"]),
Section(
"Examples",
EmbeddingFewshotExamples(
self._embedding_runner, self._examples, 5
),
),
Section(
"Complete and output in the same format as above",
InputData(),
),
]
instructions = MetaPrompt(
structure,
render_as="markdown",
data_formatter=JSONDataFormatter(),
)
return Output(
instructions.with_extractor(),
on_error="empty_result",
)
Now that we have a symbolic program, let’s get creative. For the mutations, we explore
Running SAMMO with these and a total budget of 24 candidates to try out, we can see a clear trend. Below are test set accuracies for three different datasets across four different LLMs. In the overwhelming majority of cases, we can see that SAMMO can lift performance substantially, even for the highest-performing LLMs.

Converting your prompts into symbolic programs is a really powerful idea to explore a large design space of possible prompts and settings. Just as a pro-level chef deconstructs and reinterprets recipes to create culinary innovations, symbolic programming lets us apply the same level of creativity and experimentation to automatic prompt engineering.
SAMMO implements symbolic program search through a set of mutation operators and search routine. Empirically, this can translate into large improvements in accuracy for both instruction tuning and RAG tuning, independent of the backend LLM.
You can extend SAMMO with custom mutation operators to include your favorite prompt engineering techniques or implement objectives to go beyond accuracy (e.g., cost). Happy prompt cooking!
Disclaimer: I am the author of SAMMO.
Supercharging Prompt Engineering via Symbolic Program Search was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally appeared here:
Supercharging Prompt Engineering via Symbolic Program Search
Go Here to Read this Fast! Supercharging Prompt Engineering via Symbolic Program Search


This story continues at The Next Web
Originally appeared here:
Brits to issue their own sick notes via algorithm under plan to save GP time
Originally appeared here:
Google rolls out a second Pixel April 2024 update to fix phone call glitches
Go Here to Read this Fast! The best business internet providers of 2024
Originally appeared here:
The best business internet providers of 2024
Go Here to Read this Fast! 10 best 2010s sci-fi movies, ranked
Originally appeared here:
10 best 2010s sci-fi movies, ranked
Originally appeared here:
The Narwal Freo X Plus is an entry-level robot vacuum loaded with premium features